6、tcp/ip参考模型
定义
%20(1).jpg)
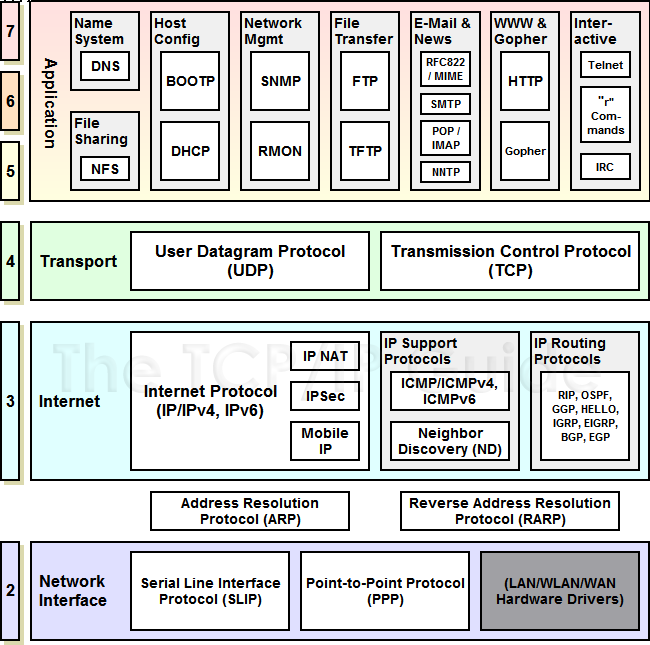
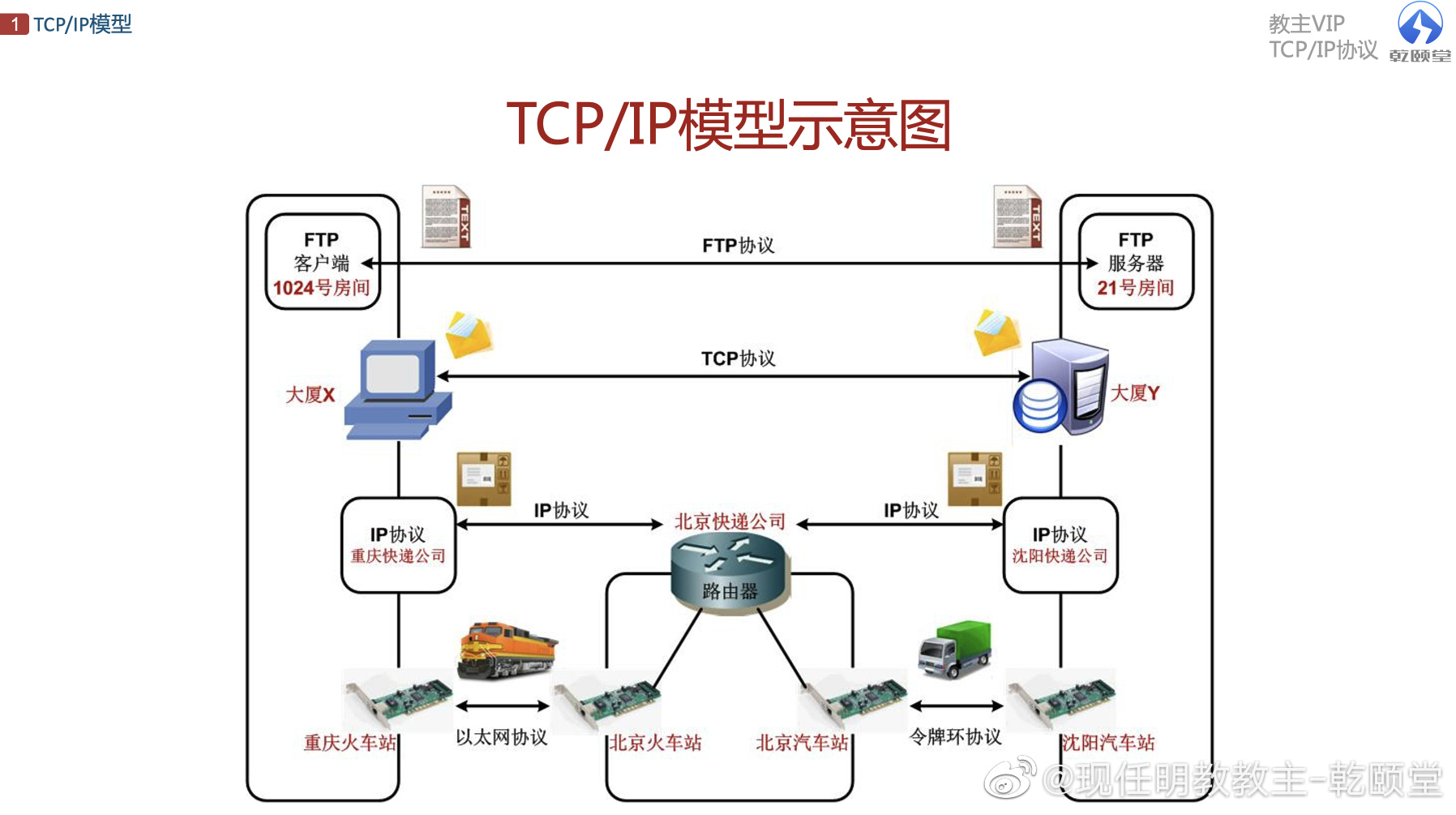
互联网协议套件(英语:Internet Protocol Suite,缩写IPS)是一个网络通信模型,以及一整个网络传输协议家族,为网际网络的基础通信架构。它常被通称为TCP/IP协议族(英语:TCP/IP Protocol Suite,或TCP/IP Protocols),简称TCP/IP。因为该协议家族的两个核心协议:TCP(传输控制协议)和IP(网际协议),为该家族中最早通过的标准。由于在网络通讯协议普遍采用分层的结构,当多个层次的协议共同工作时,类似计算机科学中的堆栈,因此又被称为TCP/IP协议栈(英语:TCP/IP Protocol Stack)。这些协议最早发源于美国国防部(缩写为DoD)的ARPA网<高级研究计划局网络(英语:Advanced Research Projects Agency Network),通称阿帕网(英语:ARPANET)是美国国防高级研究计划局开发的世界上第一个运营的数据包交换网络,是全球互联网的鼻祖。>项目,因此也被称作DoD模型(DoD Model)。这个协议族由互联网工程任务组负责维护。
TCP/IP提供了点对点链接的机制,将数据应该如何封装、定址、传输、路由以及在目的地如何接收,都加以标准化。它将软件通信过程抽象化为四个抽象层,采取协议堆栈的方式,分别实现出不同通信协议。协议族下的各种协议,依其功能不同,被分别归属到这四个层次结构之中,常被视为是简化的七层OSI模型。
TCP/IP和OSI模型对比
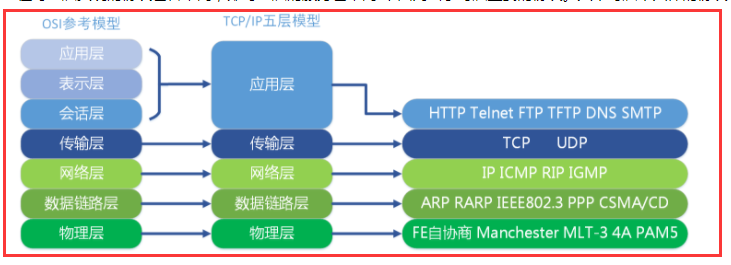
OSI引入了服务、接口、协议、分层的概念,TCP/IP借鉴了OSI的这些概念建立TCP/IP模型。
OSI先有模型,后有协议,先有标准,后进行实践;而TCP/IP则相反,先有协议和应用再提出了模型,且是参照的OSI模型。
OSI是一种理论下的模型,而TCP/IP已被广泛使用,比如现在我们每天都在用的互联网就是用的TCP/IP协议。
OSI 参考模型注重“通信协议必要的功能是什么”,而 TCP/IP 则更强调“在计算机上实现协议应该开发哪种程序”。
简单来说,OSI参考模型和TCP/IP参考模型,其实都是每一层加上本层的报头然后发给其他层这么一个工作模式,不过分层方式有所不同,现在的互联网用的几乎都是TCP/IP,而OSI模型除了IS-IS协议外,几乎都用来教授分层的概念,因为OSI分层太多,有些层没必要,比如表示层、会话层,在TCP/IP模型中应用层都搞定了。
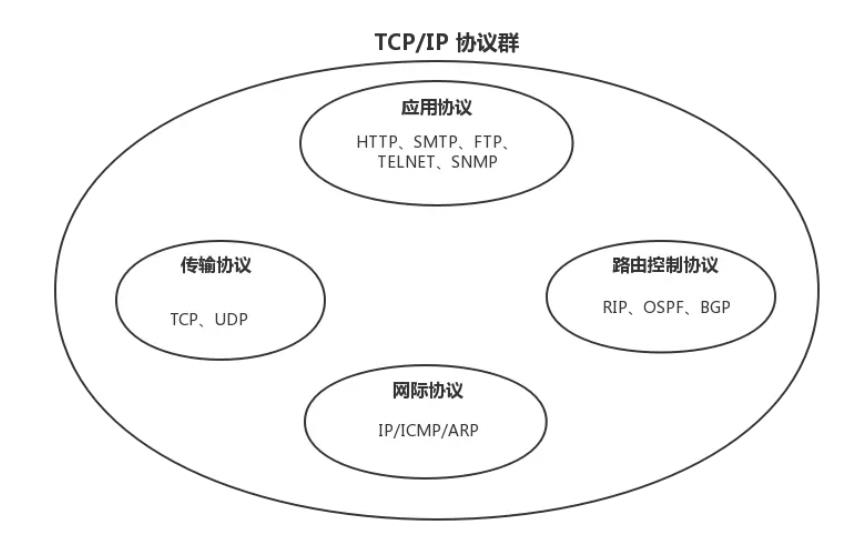
TCP\IP相关概念
TCP/IP 的具体含义
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是指能够在多个不同网络间实现信息传输的协议簇。TCP/IP协议不仅仅指的是TCP 和IP两个协议,而是指一个由FTP、SMTP、TCP、UDP、IP等协议构成的协议簇, 只是因为在TCP/IP协议中TCP协议和IP协议最具代表性,所以被称为TCP/IP协议。
互联网进行通信时,需要相应的网络协议,TCP/IP 原本就是为使用互联网而开发制定的协议族。因此,互联网的协议就是 TCP/IP,TCP/IP 就是互联网的协议。
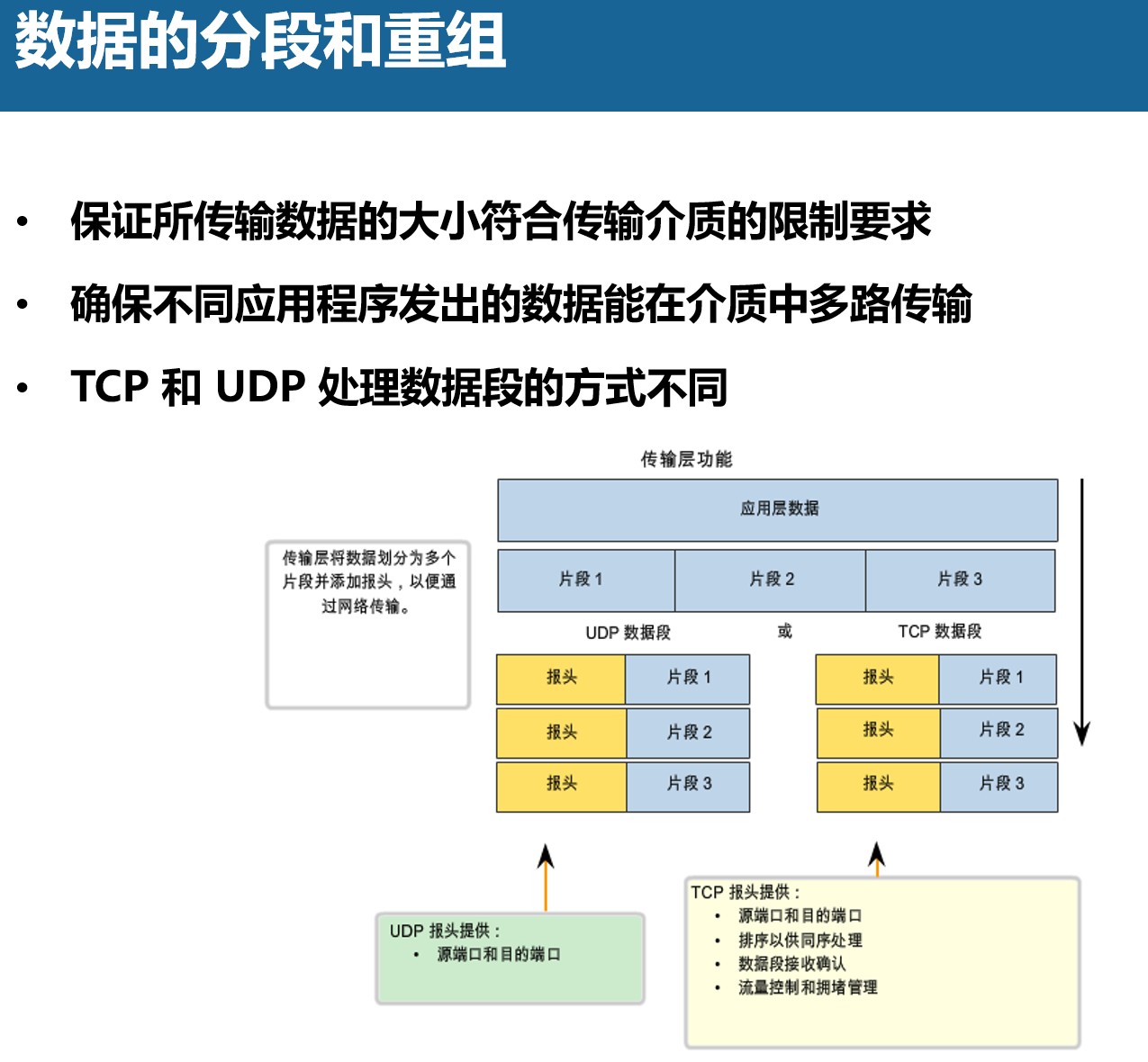
数据的格式
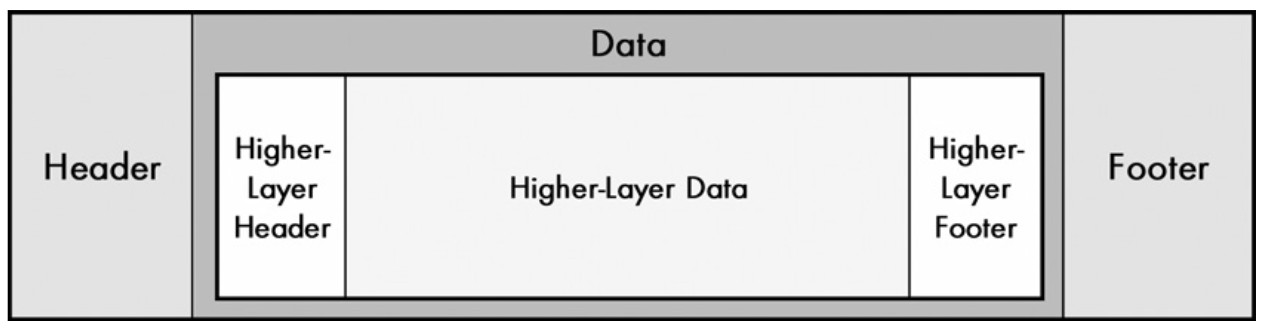
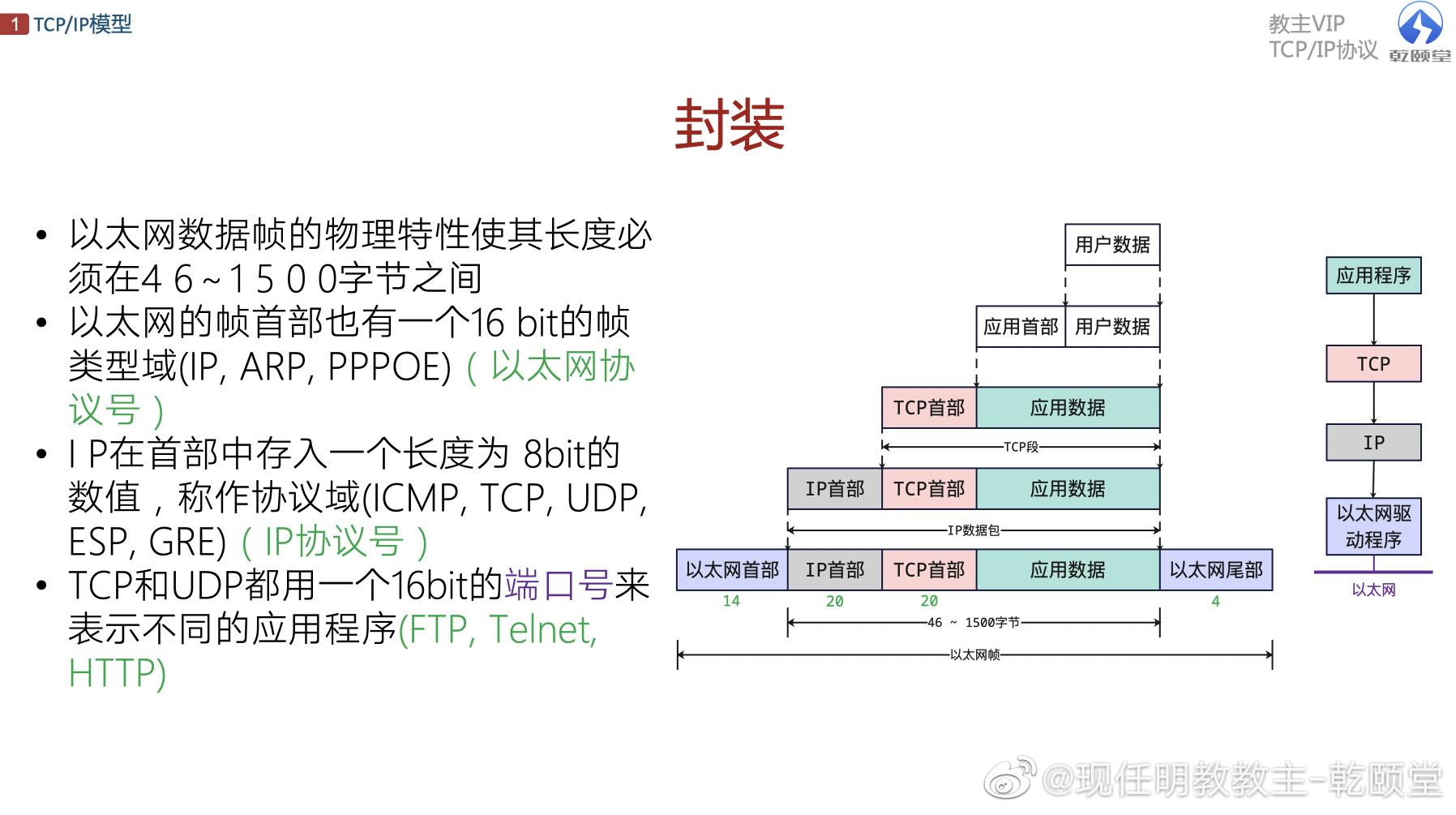
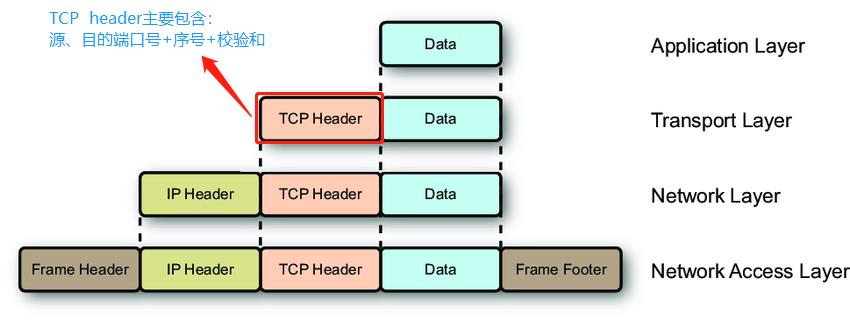
一般而言,数据包含报文头部(报头、header)、数据(Data、载荷、Payload)、报文尾部(Footer、Trailer)。
报文头部:在实际数据部分之前的信息,一般包含少量的控制信息,这些控制信息用于传达有关报文所包含的数据以及如何使用这些数据的信息。例如四层的数据段(Segment)的TCP报头中包含了源目地端口号(用来定位数据交给上层的哪个程序处理)等信息;三层的数据包(Packet)的IP报头中包含了源目地IP地址(用来在互联网上找到通信双方的位置)等信息。
数据:真正需要传递的数据,一般也叫做载荷。有些消息承载了各种各样的数据,有些消息并没有承载任何数据,这种没有承载任何数据的消息是用作控制在和沟通目的的,比如TCP的三次握手和四次分手的过程中的消息是没有承载任何数据的。
报文尾部:哪些在数据后面的信息,报文头部的信息和报文尾部的信息没有真正的区别,他们都包含了特定的控制信息。只在某些情况下使用报文尾部,特别是在字段中的数据是基于要传输的数据的值来计算的情况下。
看完上面你可能会有疑问,为什么要区别出来报文头部和报文尾部呢?两者看上去功能完全相同,为什么不合二为一,非要分个头尾不同的部分?是因为有些类型的控制信息(例如FCS,详见二层部分)是利用数据本身的值来计算的。在某些情况下,在发送数据有效载荷的同时进行这种计算,然后在有效载荷后以页脚的形式传输结果,这样做更有效率。
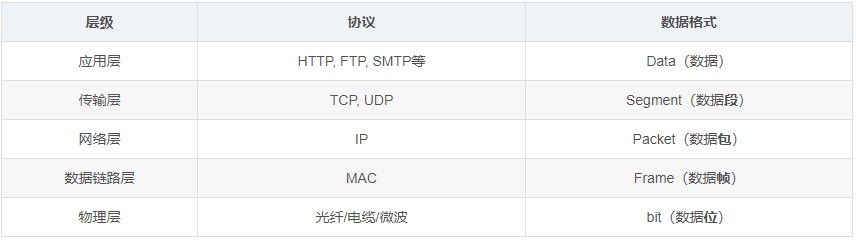
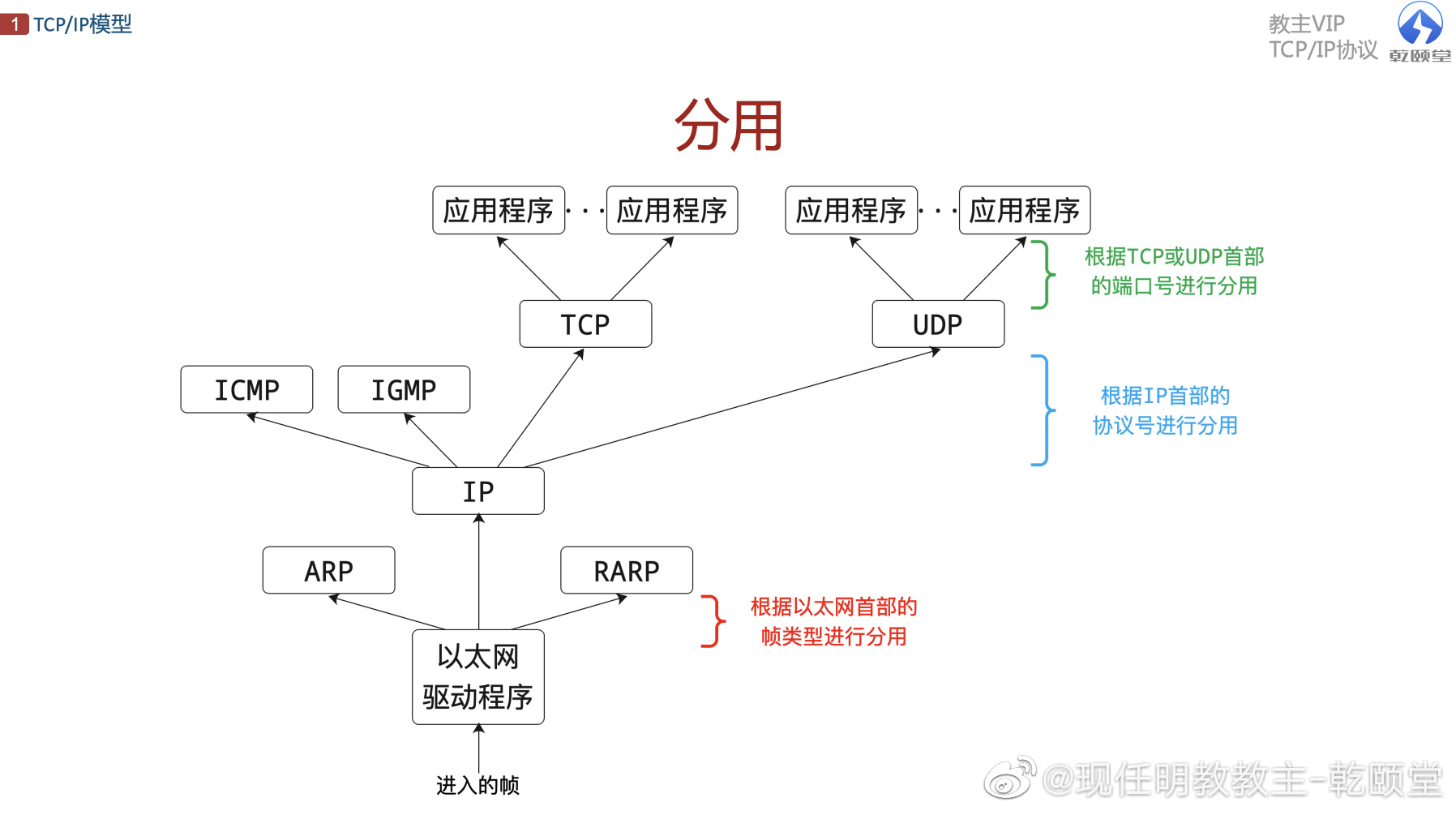
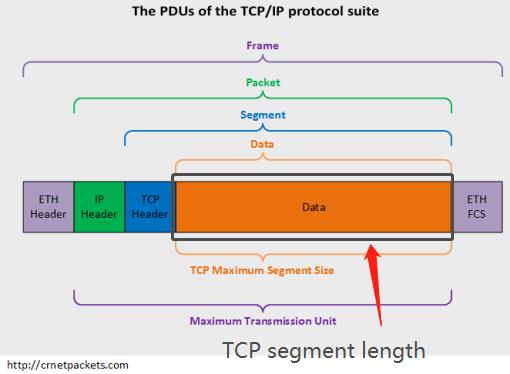
数据段、数据包、数据帧、比特、PDU
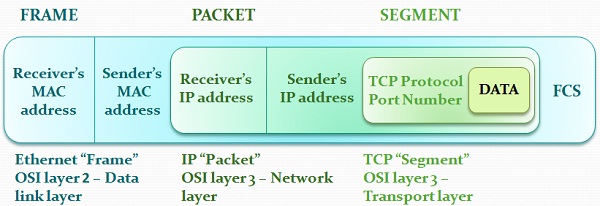
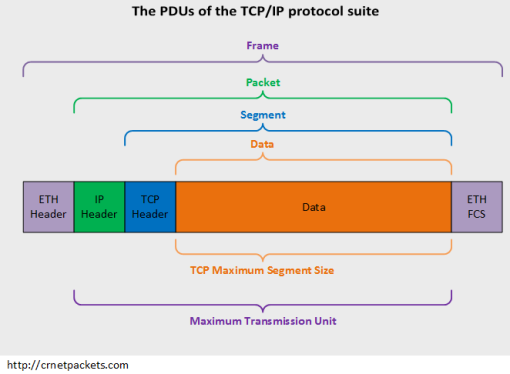
协议数据单元PDU(Protocol Data Unit)是指对等层次之间传递的数据单位。
- 数据链路层的PDU叫做Frame(帧)
- 网络层的PDU叫做Packet(数据包)
- 传输层TCP的PDU叫做Segment(数据段),UDP的PDU叫做Datagram。(数据报)
- 物理层传输的PDU叫Bit(比特)
为什么每层的PDU要有不同的命名呢?
In some cases, the different terms can be very useful, because the name used to refer to a particular message can tell you something about what the message contains, as you will see shortly. In particular, different message names are usually associated with protocols and technologies operating at specific layers of the OSI Reference Model. Thus, the use of these different names can help clarify discussions that involve multiple protocols operating at different layers.
因为在某些情况下,不同的术语可能非常有用,因为用来指代一个特定报文的名称可以告诉你一些关于该报文包含的内容,特别是,不同的报文名称通常与在OSI参考模型的特定层中运行的协议和技术有关。因此,使用这些不同的名称可以帮助澄清涉及在不同层操作的多个协议的讨论。举个例子就是,如果严谨的使用这些术语,一说数据帧,我们就能知道这是封装到二层,数据链路层,的数据,报头中封装的是数据链路层的报头,源、目的MAC地址。但如果不严格使用这些属于就可能传达混淆的信息,当然有些人混用以上这几个术语,有些人则逻辑严谨的使用,必须在与他人交流或学习网络知识的时候注意这些。
什么是TCP的连接
The reliability and flow control mechanisms described above requirethat TCPs initialize and maintain certain status information foreach data stream. The combination of this information, including sockets, sequence numbers, and window sizes, is called a connection.
上面提到的TCP的可靠和流量控制机制,需要TCP为每个信息流数据初始化并维持特定的状态信息。包括sockets、序列号和窗口大小在内的这些信息的集合,叫做连接。
面向连接协议与无连接协议
面向连接(Connection-Oriented):是指发送数据之前必须在两端建立逻辑连接(logical connection)。通常建立连接的方式是通过遵循一系列规则来完成的,这些规则指定了应如何发起,协商,管理以及最终终止连接的方式。 通常,一台设备首先发送打开连接的请求,而另一台则响应。 设备传递控制信息,以确定是否以及如何建立连接。 如果成功,则在设备之间发送数据。 完成后,连接断开。TCP建立逻辑连接的方法是“三次握手”,这样能建立可靠的连接。
无连接(Connection-less):是指发送数据之前不在两端建立连接。即使对端主机关机或不存在,数据包还是会被发送出去。反之,对于一台主机来说,它会何时从哪里收到数据也是不得而知的。通常应该进行网络监控,让主机只接收发给自己的数据包。若没有做好准备很有可能会错过一些该收的包。因此,在面向无连接的方式下可能会有很多冗余的通信。
可靠传输与不可靠传输
Thus, to support these applications, something has to be done to guarantee that the data sent by one end of the application is delivered correctly and completely to the other end of the application. If a protocol provides such a guaranteed data delivery service, it is said to provide reliable data transfer.
分组可能会在网络中丢失、损坏,应用层可能对网络通信有所要求,不允许出现这种差错,必须保证接收方的应用收到了完整且正确的数据,这种服务就是可靠数据传输服务。如果一个协议可以确保发送端发送了怎样的数据,那么接收端就必然能接收到怎样的数据,那么就可以说这个协议提供了可靠数据传输服务,这个协议是可靠(Reliable)的,反之则是不可靠(Unreliable)的。
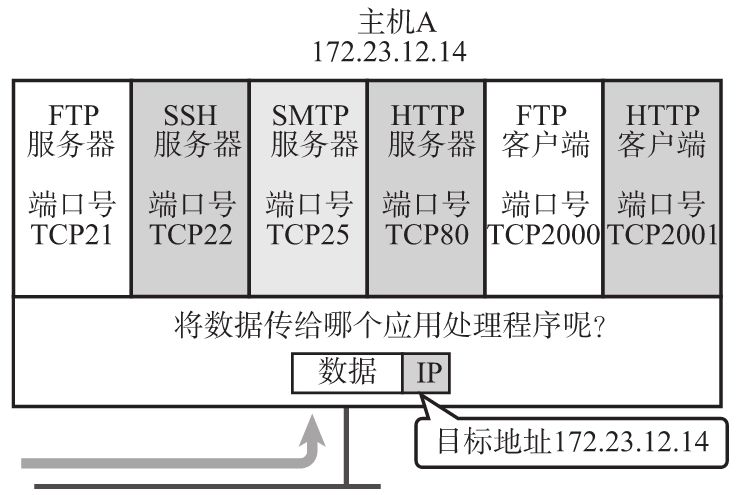
端口号、协议号以及通信如何识别
数据链路和 IP 中的地址,分别指的是 MAC 地址和 IP 地址。前者用来识别同一链路中不同的计算机,后者用来识别 TCP/IP 网络中互连的主机和路由器。在传输层也有这种类似于地址的概念,那就是端口号,端口号用来识别同一台计算机中进行通信的不同应用程序。因此,它也被称为程序地址;在网络层的类似概念就是协议号。
类比到相对熟悉的概念就是流水线上,比如造车的时候先有底盘,然后装传动轴,再装轮胎,不同的车型用的轮胎和轴承不同,底盘生产出来以后就得告诉下一步组装传动轴的,这个底盘要装什么类型的传动轴,传动轴工序完毕以后要告诉装轮胎的,我这个传动轴要配什么轮胎,否则下一步不知道如何处理上一步给过来的零件,数据传输中,这个告诉下一步要如何处理的功能就是由端口号、协议号实现的。

协议号(Protocol)是三层概念,存在于IP头部协议号字段,解封装时,如果上一层是TCP就将IP包首部之后的部分传给TCP处理;如果是UDP则将IP包首部后面的部分传给UDP处理(常见的例如:6=TCP,17=UDP);
端口号是四层概念,存在于TCP或UDP源/目端口号字段,用以识别发送主机跟接收主机上的应用,解封装时会根据端口号的不同,传给由端口号识别的应用程序。常见的例如:TCP80=HTTP, UDP53=DNS,如果目的端口号是80,就交给上层的HTTP协议去处理,如果目的端口号是53就交给DNS协议去处理。
说白了都是“区分上层”用的,就是用来识别同一台计算机中进行通信的不同应用程序。但是所处的层次不一样。一台计算机上同时可以运行多个程序。传输层协议正是利用这些端口号识别本机中正在进行通信的应用程序,并准确地将数据传输。
之所以有如此多的端口号是因为通信并不是由端口号一个字段决定的,识别一个通信是由五元组(源IP地址、目标IP地址、源端口号、目标端口和协议号)一起决定的。源IP地址决定了通信起源设备,目标IP地址决定了通信目的设备,但仅有源、目的IP地址不能识别一个通信,因为一台设备可以同时运行多个程序,下面举个接收端的例子来说明:
设备收到了一个数据后,先通过把物理层的电磁信号还原成二层的数据帧,然后看二层数据帧帧头的目的MAC地址和自己所接收端口的MAC地址是否相一致,如果一致就继续解封装到三层,查看目的IP地址是否是自己的,如果是自己的IP地址,再看协议号中的字段规定使用的是TCP还是UDP协议,然后将这个数据交给相应的四层(应用层)协议去处理,应用层处理以后,怎么知道把该数据交给上层(应用层)的哪个程序去处理呢?这就要通过端口号了,如果端口号是80,说明这是一个http协议,交给http处理,如果有多个http进程,则可以根据通信的五元组中其他不同的部分加以区分,其他的协议以此类推。
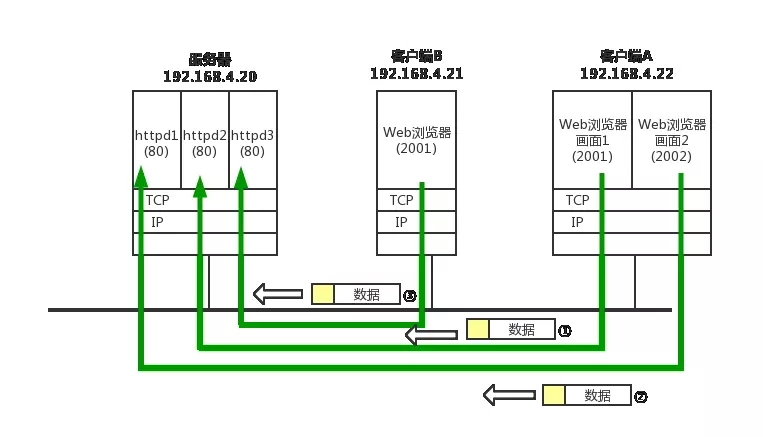
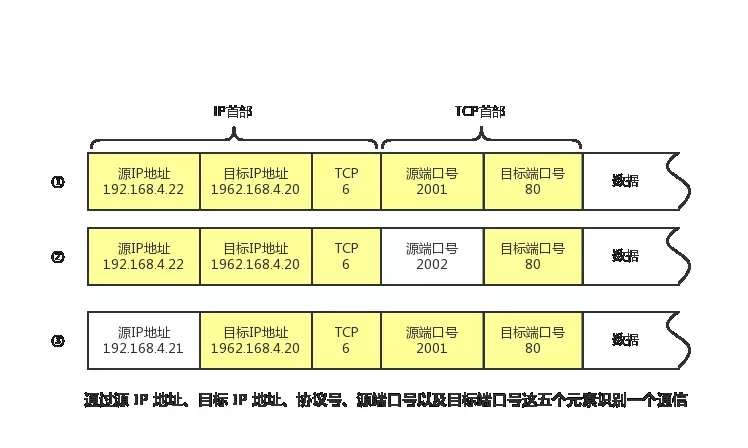
- ① 和② 的通信是在两台计算机上进行的。它们五元组中的源、目的IP(源IP为192.168.4.22,目标地址为192.168.4.20),协议号(TCP6)以及目标端口号(80)均相同。这里可以根据五元组的源端口号加以区分。
- ③ 和 ① 的目标端口号和源端口号完全相同,但它们各自的源 IP 地址不同。
- 此外,当 IP 地址和端口号全都一样时,我们还可以通过协议号来区分(TCP 和 UDP)。
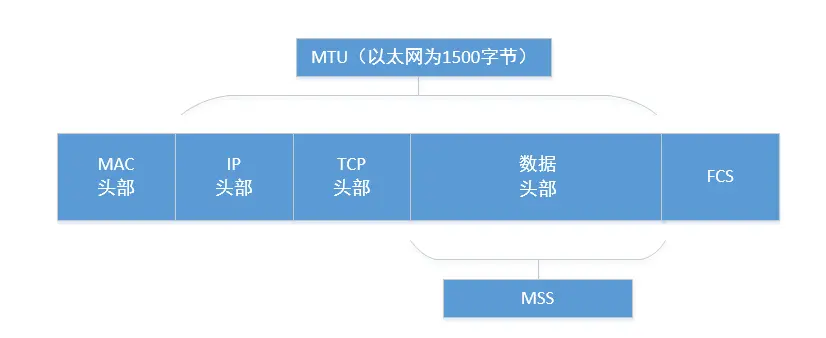
MTU、Default media MTU、Default IP MTU、Protocol MTU
MTU是最大传输单元的英文简写(Maximum Transmission Unit)
the maximum transmission unit (MTU) is the size of the largest protocol data unit (PDU) that can be communicated in a single network layer transaction
最大传输单元(MTU)是可以在单个网络层事务中通信的最大协议数据单元(PDU)的大小,简单来说也就是 TCP 数据段能够携带的数据上限。MTU 的值不是越大越好,更大的 MTU 意味着更低的额外开销,更小的 MTU 意味着更低的网络延迟。每一个物理设备都有自己的 MTU,两个主机之间的 MTU 依赖于底层的网络能力,它由整个链路上 MTU 最小的物理设备决定。
Default media MTU是Juniper的叫法,个人觉得Juniper的命名方式比较清楚,所以以下均采用Juniper的方式。Default IP MTU和Default media MTU(MTU)不是同一个概念。Juniper有个计算公式:
Default media MTU = Default IP MTU + encapsulation overhead
encapsulation overhead 在现网中就是 Ethernet header,因为二层的协议用的都是以太网2封装技术,以太网头部(14字节)但不包括尾部的FCS校验部分(4字节),所以:
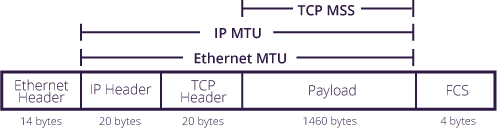
Default media MTU = 1500 (Default IP MTU) + 14(encapsulation overhead,6字节的目的MAC+6字节的源MAC+2字节的帧类型) =1514字节。
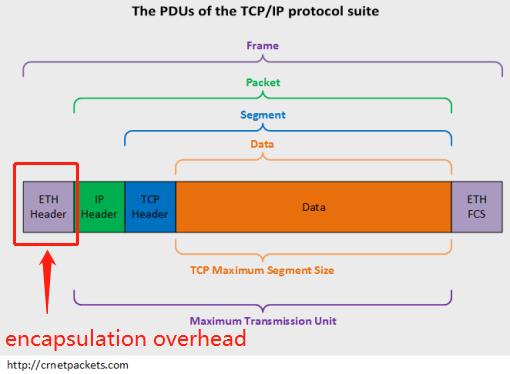
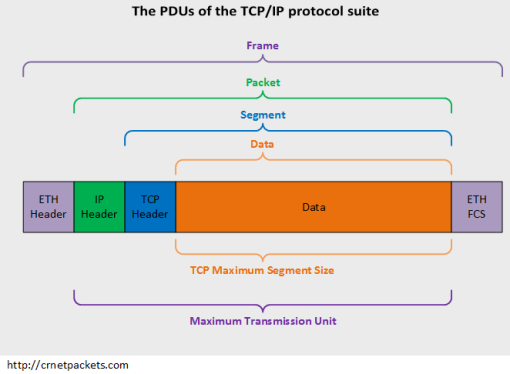
Default IP MTU=TCP header + IP header + TCP segment length(也就是图中的Data部分)
Default IP MTU(1500字节)= TCP header(20字节) + IP header(20字节) + TCP segment length(1460字节)
注1:TCP MSS 、Payload、 DATA 以及 TCP segment length其实是同一个东西
注2:抓包软件抓到的是去掉前导同步码、帧开始分界符、CRC校验之外的数据,其最大值是6+6+2+1500=1514,这个在Juniper这就是Default media MTU
如果IP层有<=1500 byte 需要发送,只需要一个IP包就可以完成发送任务;如果IP层有> 1500 byte 数据需要发送,需要分片才能完成发送,这些分片有一个共同点,即IP Header ID相同。但如果分片的话,会导致网络传输效率降低,所以要尽量避免分片。
Why we ‘ve both of Interface MTU and IP MTU?
IP MTU will only affect IP packets while MTU will affect all ethernet frames. It gives you a bit more granularity to only set the MTU for IP packets.
为什么同时需要Default IP MTU和Default media MTU这两个概念呢?
因为IP MTU仅仅影响IP包,Default media MTU将影响所有以太网帧,这样区分概念可以为网络提供更高的颗粒度,比如可以仅仅设置IP MTU而不影响以太网帧。
当然,上面这个解答是在二层用以太网封装的情况下,如果用PPP或其他方式的话,上文中的Default media MTU影响的就不是所有以太网了。
最大分段大小(MSS)
“最大分段大小”(英语:Maximum Segment Size)。TCP提交给IP层最大分段大小,不包含TCP Header和 TCP Option,只包含TCP Payload ,注意,UDP是没有MSS这个概念的。MSS是TCP用来限制application层最大的发送字节数,是tcp能发送的分组的最大长度。MSS是系统默认的,就是系统TCP/IP栈所能允许的最大包。在建立连接的三次握手时,这个MSS值经过双方协商后已经被确定了,这个值并不是客观的值,而是由tcp/ip的实现确定的,TCP在传送大量数据时,是以MSS的大小将数据进行分割发送。进行重发时也是以MSS为单位。下图中,左右两边的MSS都是1460。

如果两边的MSS值不同,则MSS会使用较小值。通信双方最终的MSS一般情况下 = 双方较小IP MTU - 40。这个40是由20字节的IP Header和20字节的TCP Header构成的,但如果IP Header和TCP Header的大小有变化,比如下图中的MSS就是1448位:
如果Default IP MTU = 1500 byte,则 MSS = 1500- 20(IP Header) -20 (TCP Header) = 1460 byte,如果application 有2000 byte发送,需要两个segment才可以完成发送,第一个TCP segment = 1460,第二个TCP segment = 540。
TCP segment length
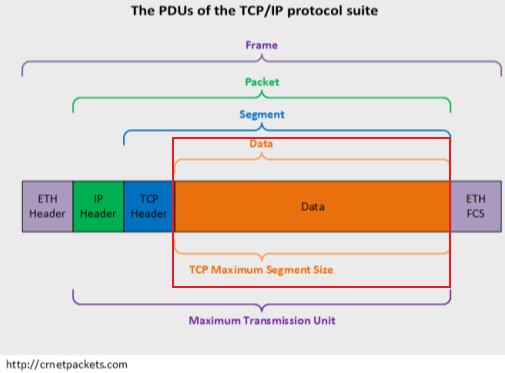
这个TCP segment length就是上图的DATA部分,TCP MSS 、Payload、 DATA 以及 TCP segment length其实是同一个东西,也就是应用层交给传输层的数据。
TCP分段与IP分片
有一篇文章把这两个概念讲的非常好,如果想深入了解请自行访问链接进行查看。
TCP分段的原因是因为TCP报文段的大小受到MSS的限制,当TCP报文段的长度大于MSS时,就要在TCP层面进行分段,MSS 是操作系统内核层面的限制,为的是保证传输的性能;IP分片的原因是IP数据包的大小受到MTU的限制,当所需转发的IP数据报的大于MTU时,就需要在IP层面进行分片,IP层面分片是因为物理设备的限制。这两个分片有点类似于,一辆车上只能装4个人,如果有6个人想坐车就只能坐两辆车分开走,但这个比喻只是方便理解但非常的不准确。
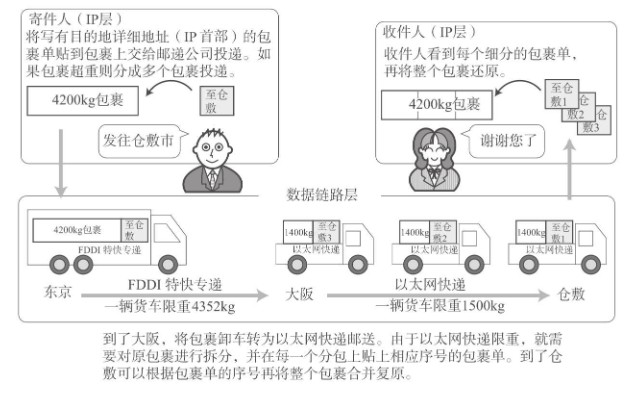
但由于一直有MSS<=MTU,很明显,分段后的每一段TCP报文段再加上IP首部后的长度不可能超过MTU,因此也就不需要在网络层进行IP分片了。因此TCP报文段很少会发生IP分片的情况。
再来看UDP数据报,由于UDP数据报不会自己进行分段,因此当长度超过了MTU时,会在网络层进行IP分片。同样,ICMP(在网络层中)同样会出现IP分片情况。
总结:UDP不会分段,就由IP来分。TCP会分段,当然就不用IP来分了!
TCP分段分析
TCP报文段的每个分段中都有TCP首部,到了端点后根据TCP首部的信息在传输层进行重组。IP数据报分片后,只有到达目的地后才进行重组,而不是向其他网络协议,在下一站就要进行重组。
当来自TCP报文段的某一段(在IP数据报的某一片中)丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报(可能有多个IP分片),没有办法只重传数据报中的一个数据分片。
IP数据分片分析
前面说过,IP分片的原因是IP数据包的大小受到MTU的限制,当所需转发的IP数据报的大于MTU时,就需要在IP层面进行分片。
在分析IP数据分片时,有三个IP报头中的字段需要格外注意:
- Identification - this value identifies a group of fragments. It’s what tells the reassembling device which fragments make up the original packet.
- Fragment offset - once all the fragments have been received, they need to be put back in the correct order. This field tells the reassembling device where in the original packet to place the data from each fragment (after stripping the L2&L3 headers).
the value for the first fragment will be 0- Flags - MF bit - More Fragments means that there are additional packets coming in after this one.
it is set (1) in all but the last fragment (0)
Identification(标识符),这个字段标识该数据为同一组分片的数据,用来告诉重组数据的设备哪些数据分片可以用来重组称为原始数据。
Fragment offset(分段序号),当所有分段数据都被接收后,需要将这些数据根据正确的顺序重组起来,这个字段告诉重组的设备这些分段数据正确的重组顺序。第一个分段数据的Fragment offset值为0。
Flags(标记)-MF位(more fragments),当该位为1时表示后面还有更多的分片数据,当最后一个分片数据的MF位为0,表示没有更多的分片数据了。
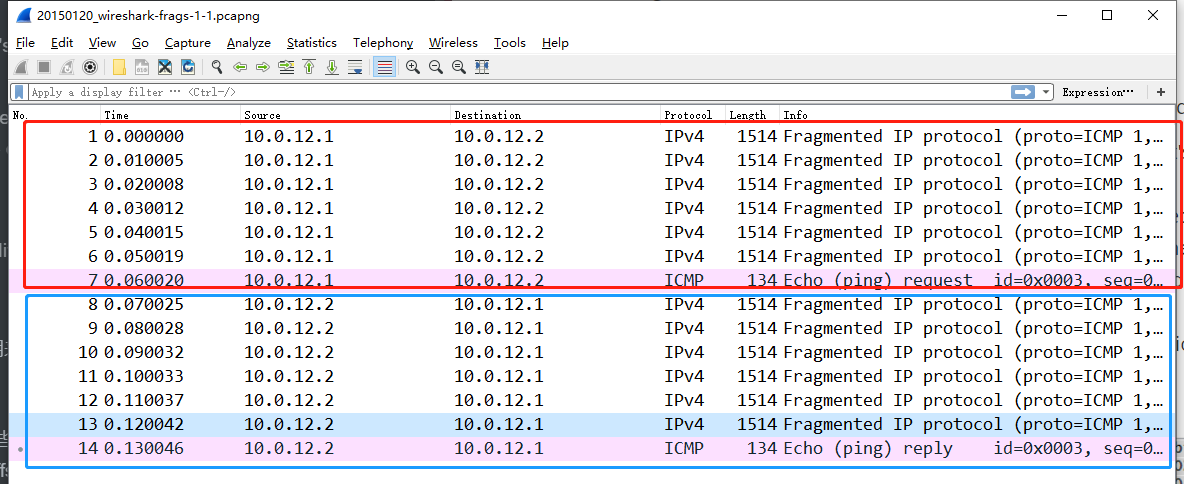
先总体来看看这个抓包,这个抓包工有14个数据,前7个是ping包,也就是红框中的这些,后7个是replay这个ping包的,是蓝色框中的部分。
The most important information is in the last entry (
#7for the request and#14for the reply). It shows a combination of the contents (and size) of the last fragment to arrive (134bytes), but it also shows the reassembled packet in all its glory (8980bytes).They key to that is noticing the tab that appears at the bottom which says
Reassembled IPv4 (8980 bytes).
最重要的信息是在最后的两行中,对于ping包就是第七个数据,对于回复包就是第十四个数据,这两行显示的是最后一个整合了前面所有分片数据信息和大小,也是前面所有分片的整合。
关键是要看到标签按键上的“组合起来是8980位”这个,表示7个数据的ipv4部分加起来是8980位。
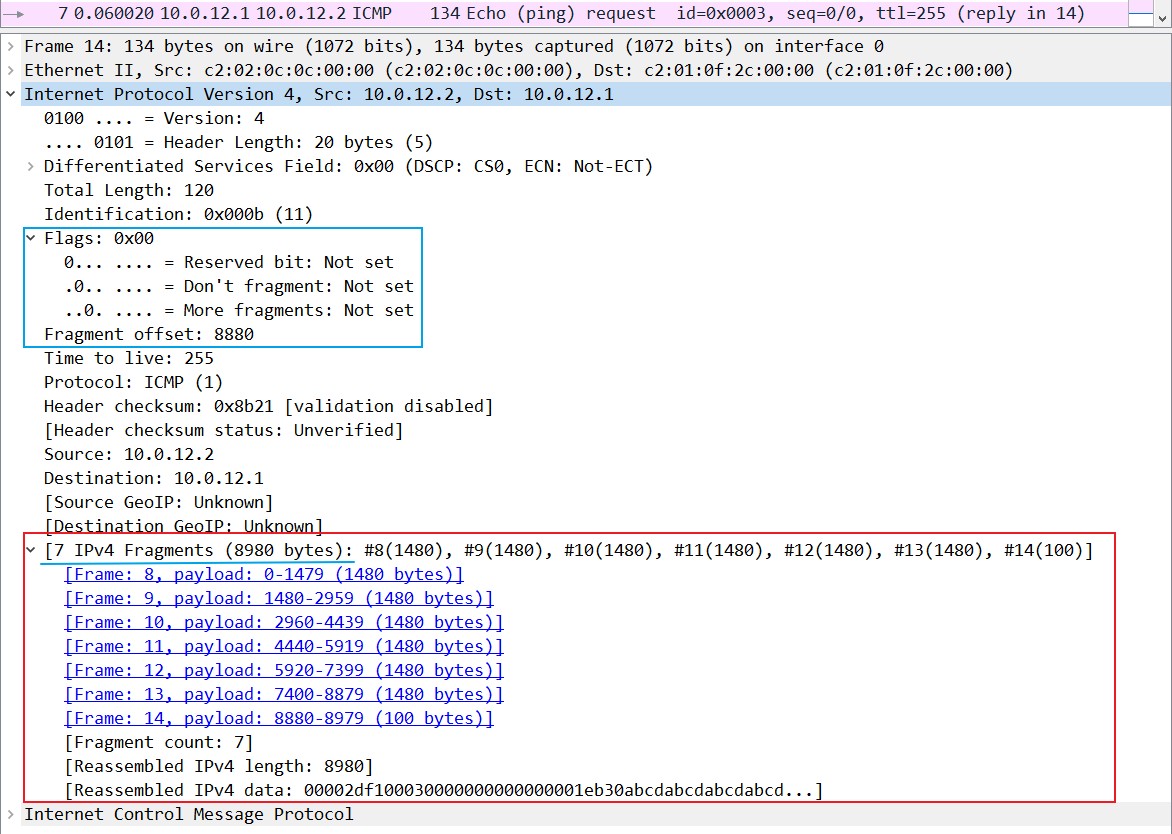
To make matters worse, the IP header shown inside the reassembled packet is the one from the last fragment (notice Fragment offset is
8880and MF is0). On the flip side, it does tell you that the packet has been reassembled from 7 fragments and it gives you the sizes and links to the fragments themselves. Convenient.
让事情变得更糟糕的是,只有分片最后的那片数据带有UDP或ICMP首部,在这个例子中,只有第七和第十四片带有ICMP头部,因为Flag位上的MF位(More Fragments)为0,也就是说没有更多分片了,这两个是他们分片中的最后一个分片了,所以可以把所有分片整合起来了。在7和14上可以看到所有的分片大小以及这些分片的链接。
有些书上写的是只有第一个分片包含UDP或ICMP首部,但通过抓包以及询问原厂工程师,我觉得应该是最后一个分片带有UDP和ICMP首部,因为只有在7和14这两个上才有其他分片的信息以及Flag位中的MF位为0(表示没有更多分片)。在自己的结果和书上查到的资料有差异时,不要简单的就怀疑自己的结果有问题,要多方查证,通过做实验和抓包去证实真正的结果如何。


最后一点,对IP分片的数据报来说,即使只丢失一片数据也要重新传整个数据报(既然有重传,说明运输层使用的是具有重传功能的协议,如TCP协议)。这是因为IP层本身没有超时重传机制——由更高层(比如TCP)来负责超时和重传。当来自TCP报文段的某一段(在IP数据报的某一片中)丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报(可能有多个IP分片),没有办法只重传数据报中的一个数据分片。
FCS和CRC
定义:
FCS - Frame Check Sequence is the process of using an algorithm or many algorithms to check frames
CRC - Cyclical Redunancy Check is a checksum type. It uses a specific algorithm (found below) for checking computation or transmission integrity.
用简单的话来说,FCS是用算法校验数据的过程,而CRC是FCS这个校验过程可以采用的一种校验的方式,以太网用的就是CRC这种校验方式,所以在以太网里可以暂且把两者看成是同一个东西,但从概念上来讲,要知道二者是不同的。
各层功能
应用层(Network Access Layer)
The application layer corresponds to the OSI session, presentation, and application layers. Although some routing protocols such as Border Gateway Protocol (BGP) and routing Information Protocol (RIP) reside at this layer, the most common services of the application layer provide the interfaces by which user applications access the network.
——Routing TCP/IP, Volume I
TCP\IP协议的应用层与OSI协议的会话层、表示层以及应用层相对应。尽管一些路由协议(比如BGP协议和RIP协议)工作在应用层,在用户的应用访问网络时,应用层的服务为它提供接口。
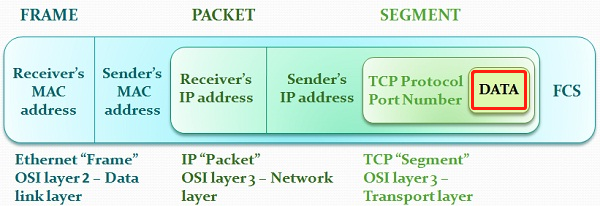
图中的DATA部分可以理解为由应用层产生的,应用层向用户提供一组常用的应用程序,比如电子邮件、文件传输访问、远程登录,常见用的软件所使用的很多协议都在这一层。应用层包含了所有的高层协议:
- HTTP 80 超文本传输协议,提供浏览网页服务
- Telnet 23 远程登陆协议,提供远程管理服务
- FTP 20、21 文件传输协议,提供互联网文件资源共享服务
- SMTP 25 简单邮件传输协议,提供互联网电子邮件服务
- POP3 110 邮局协议,提供互联网电子邮件服务
- TFTP 69 (UDP) 简单文件传输协议,提供简单的文件传输服务
- DNS 53(UDP) 域名解析协议,提供网址和IP地址相互映射服务
关于DNS举个现实中的例子,我们在设备上ping百度网址的时候,其实ping的并不是百度 www.baidu.com 的网址而是ping的61.135.169.125这个IP地址,因为在网络上只有IP地址才是设备的唯一标识,必须通过IP地址数据才能通信,但相比一长串的IP地址,还是网址这个贴近人类记忆习惯的东西比较好记,但机器无法识别这些人类熟悉的网址,所以有了DNS这个映射协议,将网址和IP地址对应起来,当用户输入主机名(域名)时,DNS会自动检索那个注册了主机名和IP地址的数据库,并迅速定位对应的IP地址。
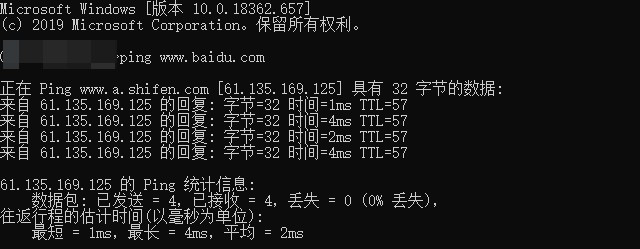
传输层(Transport Layer)
The host-to-host layer, corresponding to the OSI transport layer, specifies the protocols that control the internet layer, much as the data link layer controls the physical layer. Both the host-to-host and data link layers can define such mechanisms as flow and error control. The difference is that while data-link protocols control traffic on the data link the physical medium connecting two devices,the transport layer controls traffic on the logical link,the end-to-end connection of two devices whose logical connection traverses a series of data links.
传输层(TCP\IP路由卷一中把这层叫做host-to-host,也就是主机到主机层),对应着OSI模型中的传输层,规定了那些控制网络层的协议,传输层和数据链路层都能定义诸如数据流和错误控制等机制,这两层的区别在于,数据链路层协议控制数据链路上的流量,也就是连接两个设备的物理介质;而传输层控制逻辑链路上的流量,也就是两个设备的端到端连接,这个连接贯穿一系列的数据链路。个人感觉这短话尤其是后面关于区别的部分,没必要深究。

传输层位于应用层和网络接口层之间,负责在主机之间提供逻辑连接,通常提供如下功能:
流量控制:通过窗口技术
可靠连接:通过序列号和确认号
会话多路复用:通过端口号和IP地址
分段:通过使用数据段的协议数据单元(PDU)
在TCP/IP协议族中,有两个互不相同的传输协议:TCP(传输控制协议)和UDP(用户数据报协议)。图中的TCP协议(也可能是UDP协议)+端口号(Port Number)+应用层的DATA可以理解为整个传输层封装后产生的,在数据由应用层传递给传输层后,TCP提供将应用层发来的数据顺利发送至对端的可靠传输。
为了实现TCP的这一功能,需要在应用层数据的前端附加一个TCP首部。TCP首部中包括源端口号和目标端口号(用以识别发送主机跟接收主机上的应用)、序号(用以发送的包中哪部分是数据)以及校验和(Check Sum,用来检验数据的读取是否正常进行的方法。) (用以判断数据是否被损坏)。随后将附加了TCP首部的包再发送给IP。
TCP 就可以在自己这一层,把用户发送的数据,预先分成多个大小限制在 MTU 里的 TCP 包。每个 TCP 的分片包,都完整了包含了 TCP 头信息,方便在接收方重组。
TCP
TCP(Transmission Control Protocol,传输控制协议)为两台主机提供高可靠性的数据通信,是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC793定义。TCP 是面向连接的、可靠的流协议。流就是指不间断的数据结构,你可以把它想象成排水管中的水流。
TCP的特点:
1、面向连接:是指发送数据之前必须在两端建立连接。TCP建立连接的方法是“三次握手”,这样能建立可靠的连接,所以说TCP是面向连接的协议。建立连接,是为数据的可靠传输打下了基础。
面向连接,是指发送数据之前必须在两端建立连接。TCP建立连接的方法是“三次握手”,这样能建立可靠的连接,所以说TCP是面向连接的协议。
2、可靠传输:TCP协议可以确保发送端发送了怎样的数据,那么接收端就必然能接收到怎样的数据,因为TCP协议中规定了:①如何处理丢失或重复等差错情况。②如何初始化一个数据流传输 ③如何协商结束数据流传输 ④流量控制和拥塞控制机制。
①如何处理丢失或重复等差错情况:靠的是TCP的序列号(Sequence Number)以及确认应答号(Acknowledgement Number、ACK)。TCP在发送数据的时候,为每个字节编号(也就是序列号),接收端收到数据之后,经过校验无误,发回确认应答号,确认应答号为接收端等待接受的写一个字节的序号。并且它会缓存到达的乱序数据,统一排序之后传递给上层。这样就解决了丢包,重复和乱序的问题。
②如何初始化一个数据流传输:TCP的三次握手进行了规定。
③如何协商结束数据流传输:TCP的四次分手进行了规定。
④流量控制和拥塞控制机制:TCP的窗口字段、序列号、确认应答号、Tail drop(尾帧丢弃)和RED(Random early detection)等提供了这些功能。
3、支持流控
TCP连接的每一方都有固定大小的缓冲空间。TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出。具体见下文的窗口大小部分。
4、窗口机制
见下方的窗口机制部分。
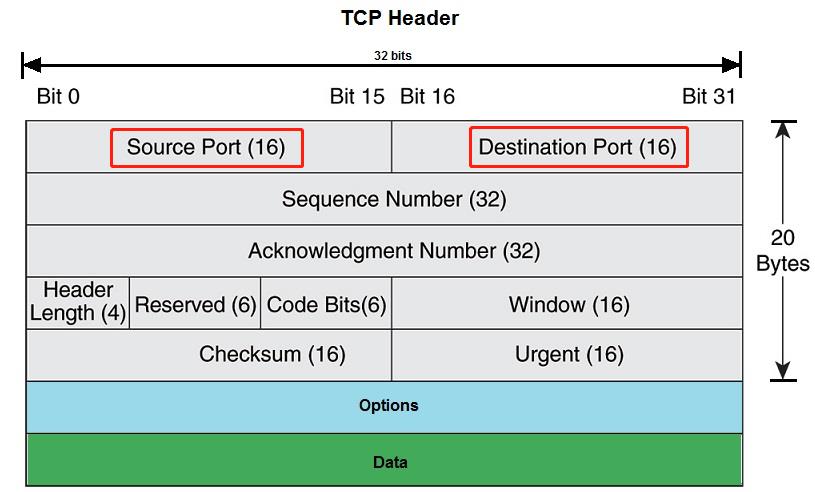
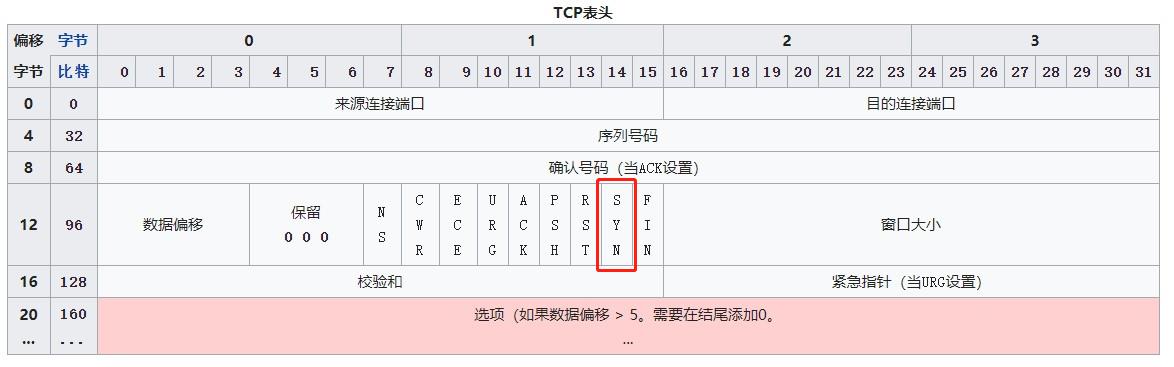
TCP报头格式
每个分层中,都会对所发送的数据附加一个首部,在这个首部中包含了该层必要的信息,如发送的目标地址以及协议相关信息。通常,为协议提供的信息为包首部,所要发送的内容为数据。在下一层的角度看,从上一层收到的包全部都被认为是本层的数据。
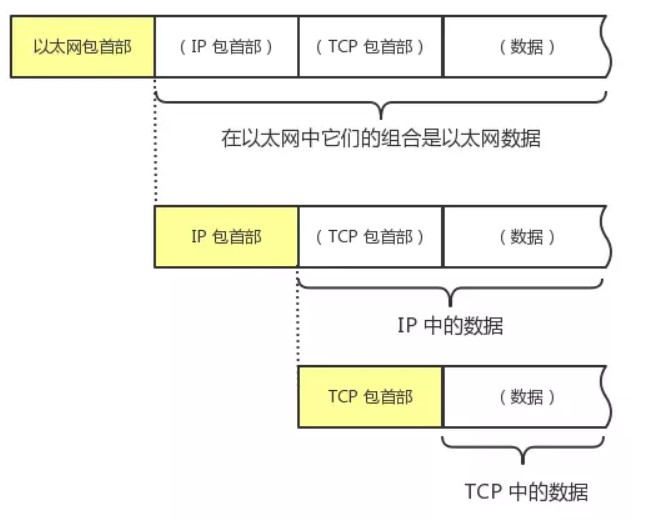
一个 TCP Header 一般有 20 个字节,如果启用了options,header的长度可以达到 60 个字节。图中每一行是 4 个 bytes,32 个 bits。
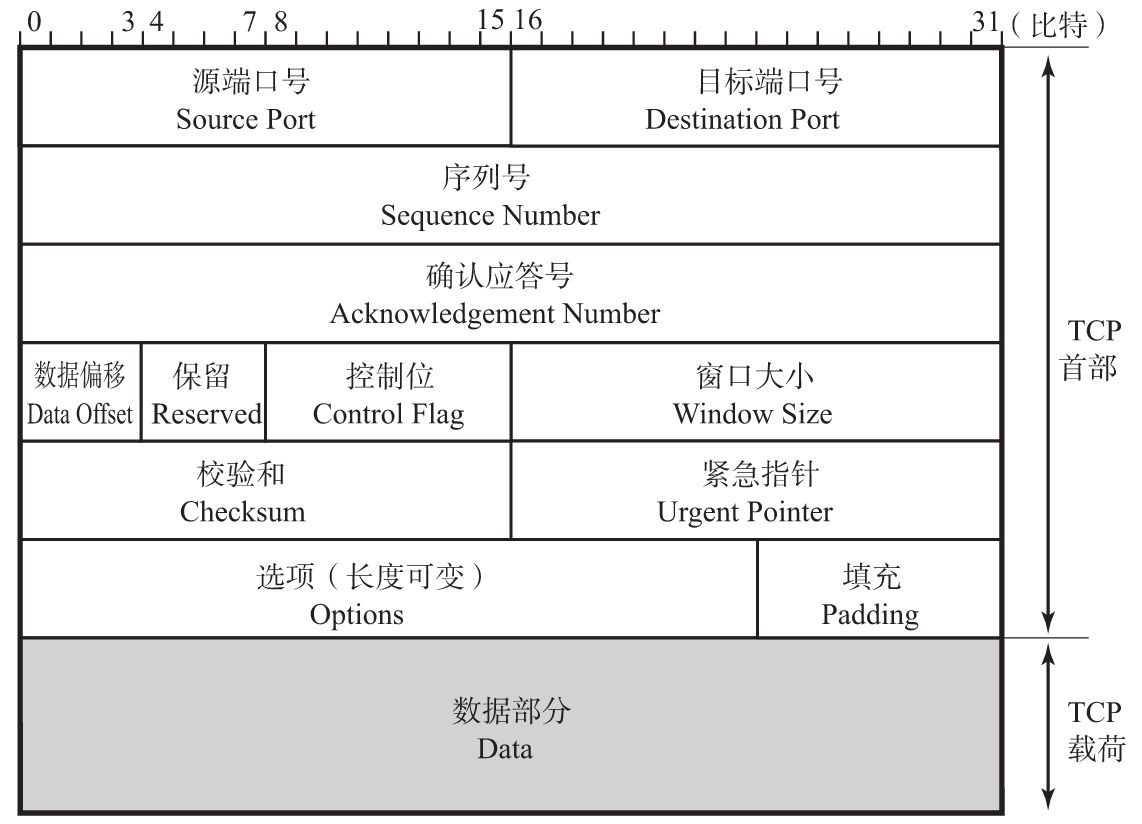

源端口号(Source Port)
表示发送端端口号,字段长16位。
目标端口号(Destination Port)
表示接收端端口号,字段长度16位。
源和目标端口号长度均为16位,即允许一个主机有2的16次方,也就是65535个不同端口,其中:
0——1023为分配给系统的端口号,属于知名端口,不可以乱用,常见的有HTTP的80端口,FTP的21端口以及TELNET的23端口。
1024——49151为登记端口号,第三方可以使用。
应用客户端使用的源端口号一般为系统中未使用的且大于1023的数字。
序列号(Sequence Number)
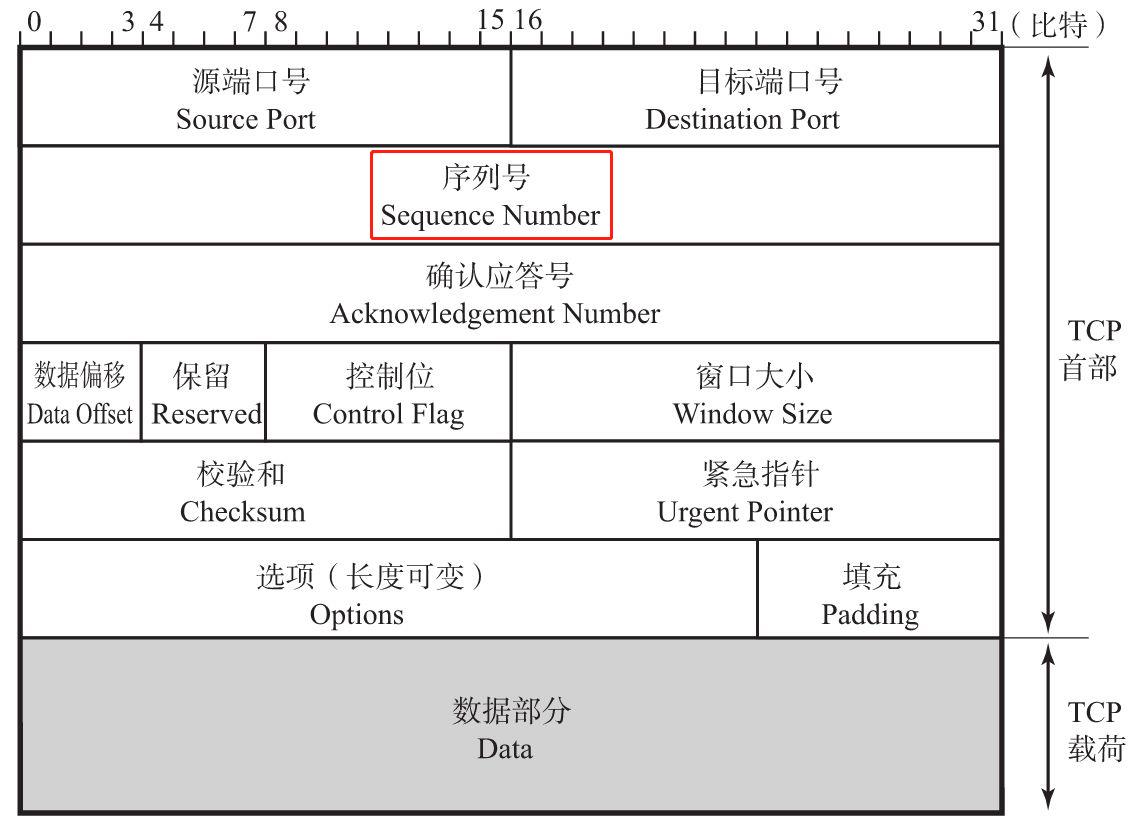
字段长32位。序列号(有时也叫序号)是指发送数据的位置。每发送一次数据,就累加一次该数据字节数的大小。接收方可以通过检查收到的数据分组的序号发现哪些分组没有收到、哪些分组冗余了。发送ACK/NAK反馈时也可以指定Seq表示需要重传哪些分组或者继续往下发送哪些分组。
一个TCP流是有无数个0和1构成,这些0和1以8个bit为单位,可以分割成一个个的byte,TCP是可靠传输协议,每一个byte都是有标号的,因为我们需要追踪每个byte是否被成功传输了,每个byte的标号就是我们这里的sequence number。有了数据包对应的序列号,我们就可以:
- 接收方可以通过序列号对重复的数据包进行去重;
- 发送方会在对应数据包未被 ACK 时进行重复发送;
- 接收方可以根据数据包的序列号对它们进行重新排序;
序列号不会从0或1开始,而是在建立连接时由计算机生成的随机数作为其初始值,通过SYN包传给接收端主机。然后再将每转发过去的字节数累加到初始值上表示数据的位置。此外,在建立连接和断开连接时发送的SYN包和FIN包虽然并不携带数据,但是也会作为一个字节增加对应的序列号。
A TCP header which only consists of the ACK will not increment the SEQ/ACK
一个只包含ACK的TCP报头不会增加序列号和ACK号的数字,也就是说,一个纯ACK确认数据是不会增加序列号和ACK号的数字
确认应答号(Acknowledgement Number、ACK)
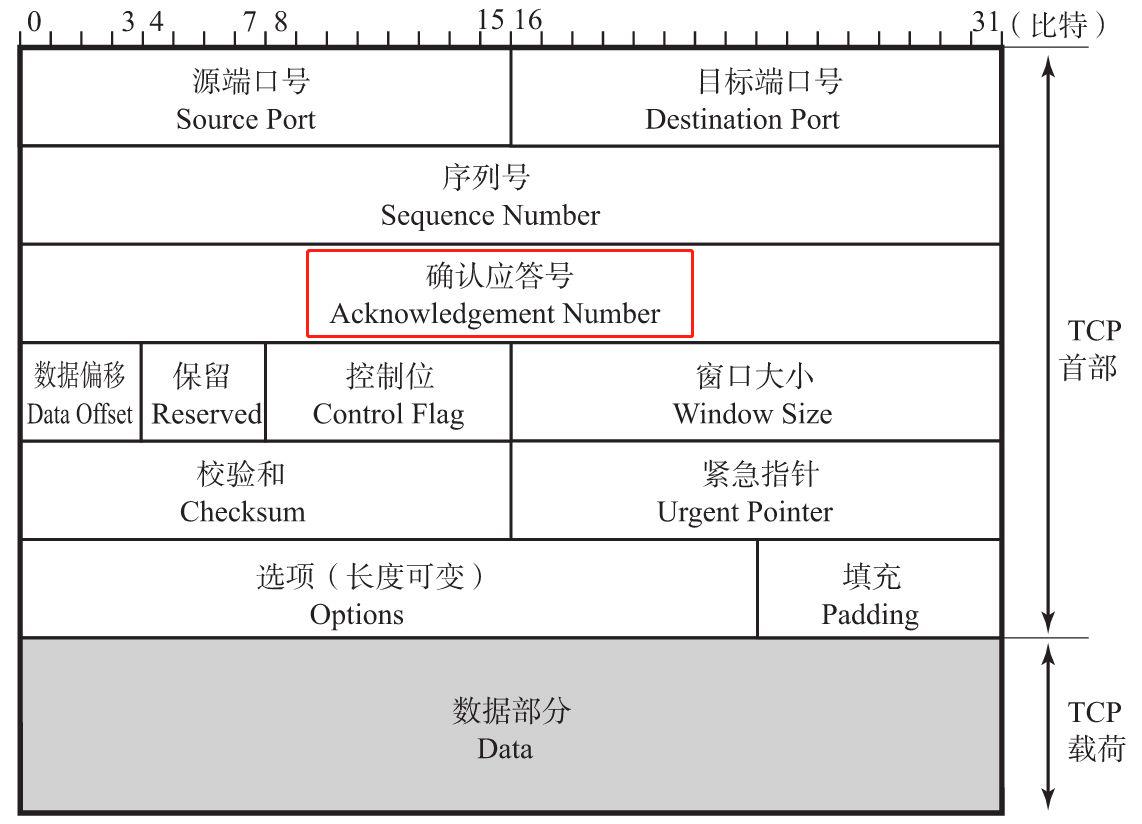
确认应答号字段长度32位。是指表示期望收到对方下一个报文段的序号值。实际上,它是指已收到确认应答号减1为止的数据。当发送端收到确认应答号后,用来确认这个位置以前所有数据都被正常接收,否则将会从新连接发送,这也是TCP是可靠传输的原因,因为有“序列号—确认应答号”这么一个确认机制,可以知道数据是否发送完整。例如下图中,主机A向主机B发送了长度为725的数据,主机B在回复的数据中将应答号设置为726,表示前725个数据都正常接收,下次请发送序列号从726开始的数据。

必须要注意的是,TCP的ACK表达的意思一方面是期望收到对方下一个报文段的序列号,另一方面也是确认当前数据段前面的全部数据段已经被接收和处理,如果说对方发送了5个数据段,数据段1-5,如果后四段成功接收,但第一段未接收的话,接收者是不会发送ACK序列号为6的,因为如果发送了ACK=6就是说明1-5全部接收成功,但事实上数据段1并没有接收到所以是不会发送ACK为6的数据的,由于发送方没有收到 ACK,所有数据段对应的计时器就会超时并重新传输数据。在丢包较为严重的网络下,这种重传机制会造成大量的带宽浪费。
如何解决上面说的这种其中某一个数据段没收到就要重传所有数据段的问题呢?要用到快速重传(Fast Retransmit/Fast Recovery),大概意思是当接收方收到乱序的数据段时,不会等待重传计时器到时再重传,而是会立刻发送两个连续的 ACK 触发发送方的重传,这里就不展开了,详见RFC2581中的3.2 Fast Retransmit/Fast Recovery。
The sequence number is always valid. The acknowledgement number is only valid when the ACK flag is one. The only time the ACK flag is not set, that is, the only time there is not a valid acknowledgement number in the TCP header, is during the first packet of connection set-up.
序列号始终存在。确认编号仅在ACK标志为1时存在。 唯一未设置ACK标志的时间,即TCP头中没有有效确认号的唯一时间是在连接建立的第一个数据包期间。
if ACK flag is 1 , Acknowledgment number is considered by application; if ACK flag is 0, Acknowledgment Number is not considered
如果控制位中的ACK置位为1,则应用程序考虑确认号;如果ACK为0,则不考虑确认编号。关于控制位中的ACK置位问题,请参照后面的控制位部分。
The ACK flag is used to acknowledge past data, but the acknowledgement number is used to say what is expected in the future. Those are two completely different functions.
when a host sees the ACK flag, it knows that all data up to the acknowledgement number has been acknowledged, but the acknowledgement number, itself, is telling the host what the destination is expecting next.
注意ACK置位和ACK 序号的区别,ACK位是在TCP报头控制位里的其中一位,而ACK序号是前面的ACK确认应答号,两者功能是完全不同的,ACK置位为1的时候,表示这个数据是确认之前发送的数据,对端会明白这个数据是用来确认的,确认的是ACK确认应答号之前的那些数字,比如ACK确认应答号是1000,而ACK确认应答号是用来告诉对端下一次发送数据的序列号是多少,所以下次发送数据从1000开始。这两个字段是搭配起来用的。
——关于序列号和确认应答号的相关说明——
序列号和确认号组合起来使用,可以提高可靠性。
When a host initiates a TCP session, its initial sequence number is effectively random; it may be any value between 0 and 4,294,967,295, inclusive. However, protocol analyzers like Wireshark will typically display relative sequence and acknowledgement numbers in place of the actual values. These numbers are relative to the initial sequence number of that stream. This is handy, as it is much easier to keep track of relatively small, predictable numbers rather than the actual numbers sent on the wire.
主机启动TCP会话时,其初始序列号实际上是随机的; 它可以是0到4,294,967,295(含)之间的任何值。因为序列号的大小是32位,2的32次方是4294967296。但是,像Wireshark这样的抓包分析软件通常会显示相对序列和确认号来代替实际值。 这些数字是相对于该流的初始序列号。这很方便,因为跟踪相对较小的可预测数字比在线上发送的实际数字要容易得多。
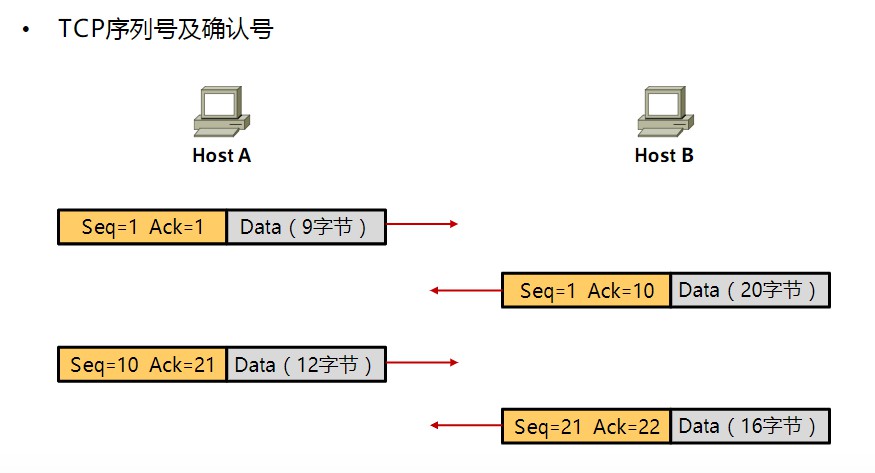
当TCP连接已经建立时,主机A向主机B发送了9个字节的数据后,主机B在回包中用确认号(Acknowledgemt Number)10来回复,这个10就是期望收到对方下一个报文段的序号值,所以对方在下一次发送中发送的12个字节,编号是从10开始的,也就是编号为10-21的数据。
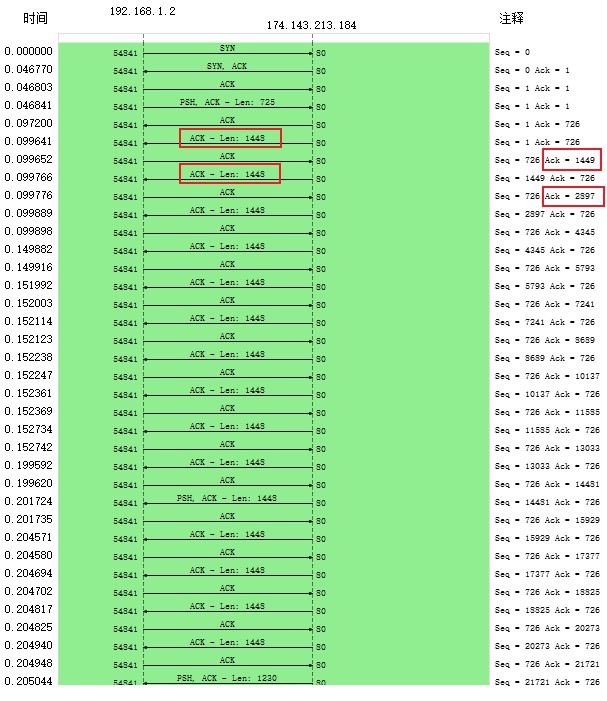
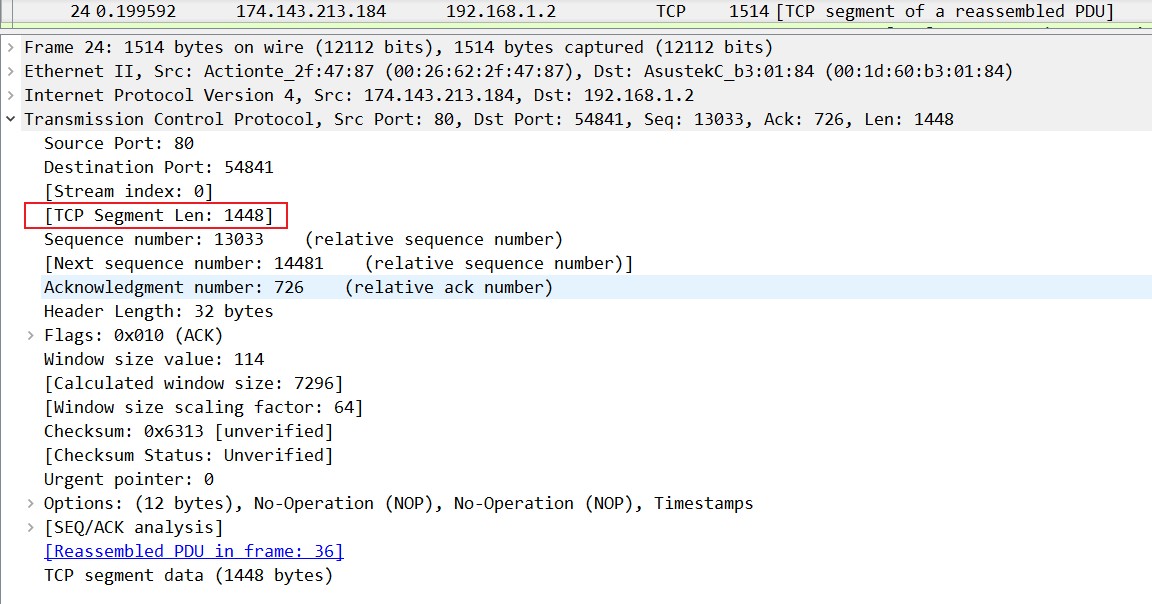
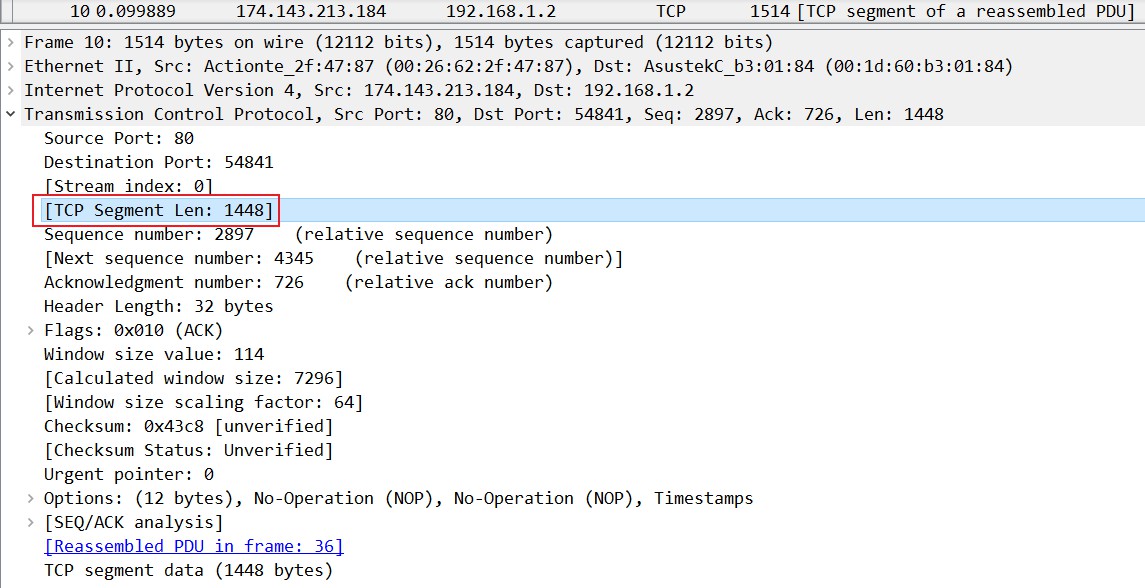
从抓包中能更直观的看出来“期望收到对方下一个报文段的序号值”这个概念:主机2(174.143.213.184)发送了长度为1448的数据给主机1(192.168.1.2),主机1在回复的数据中所带的ACK值是1449,所以下一次主机2发送的数据的序列号从1449开始,长度为1448的数据。
通过序列号和确认应答号,TCP 能够识别是否已经接收数据,又能够判断是否需要接收,从而实现可靠传输。
数据偏移(Data Offset)
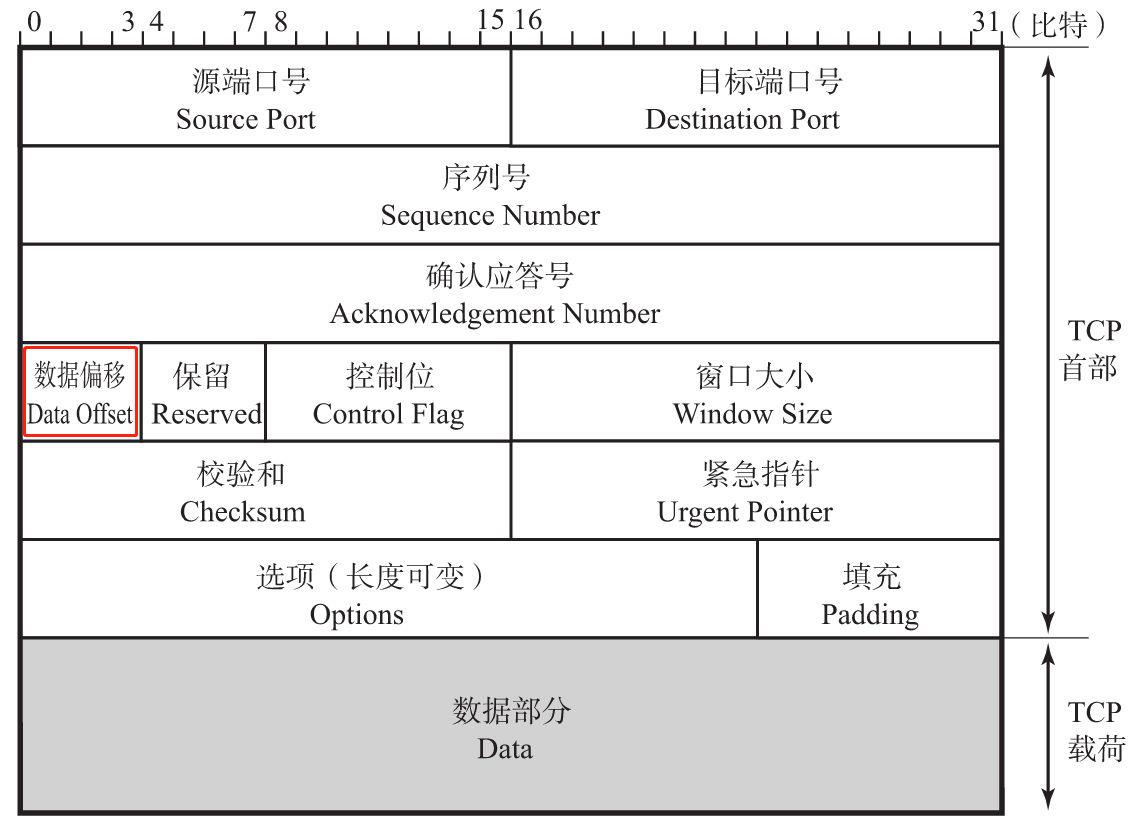
该字段表示TCP所传输的数据部分应该从TCP包的哪个位开始计算,当然也可以把它看作TCP首部的长度(Specifies the size of the TCP header in 32-bit words.)。该字段长4位,单位为4字节(即4X8=32位)。不包括选项字段的话,TCP的首部为20字节长,因此数据偏移字段可以设置为5。反之,如果该字段的值为5,那说明从TCP包的最一开始到20字节为止都是TCP首部,余下的部分为TCP数据。
保留(Reserved)
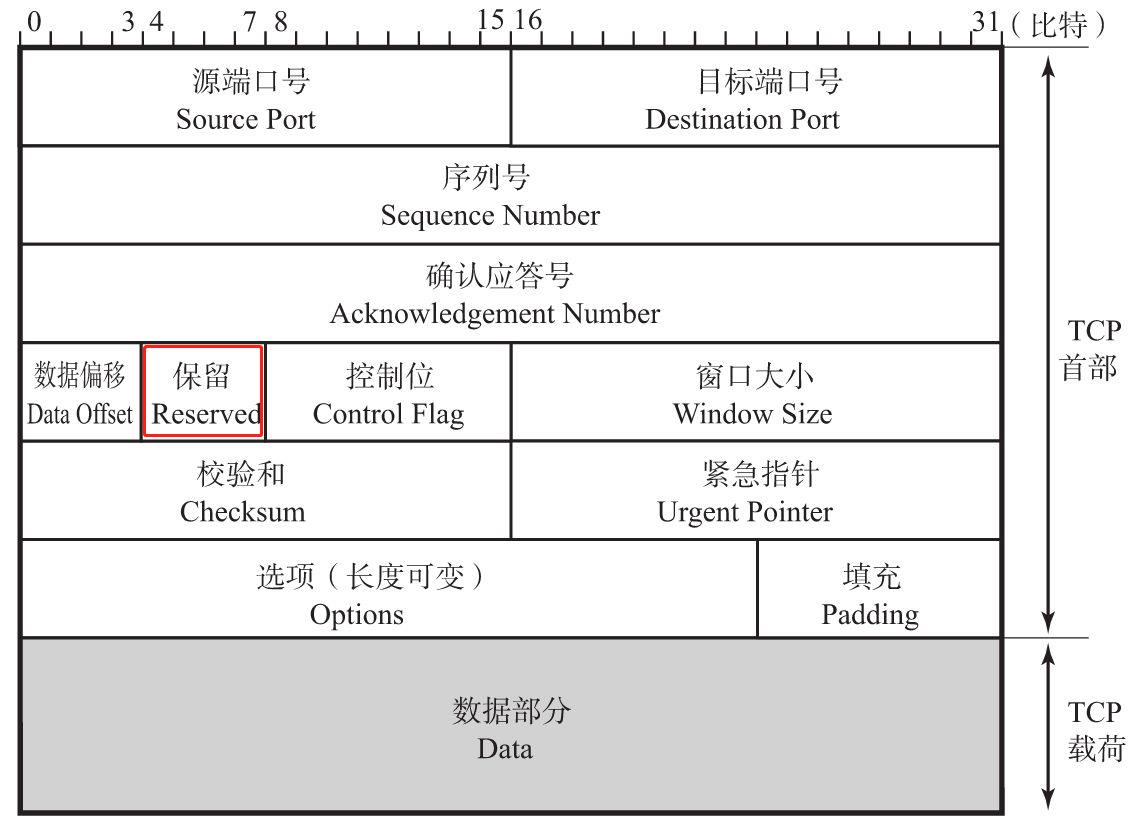
该字段主要是为了以后扩展时使用,其长度为4位。一般设置为0,但即使收到的包在该字段不为0,此包也不会被丢弃(保留字段的第4位(如图中的第7位)用于实验目的,相当于NS(Nonce Sum)标志位。) 。
控制位(Control Flag)
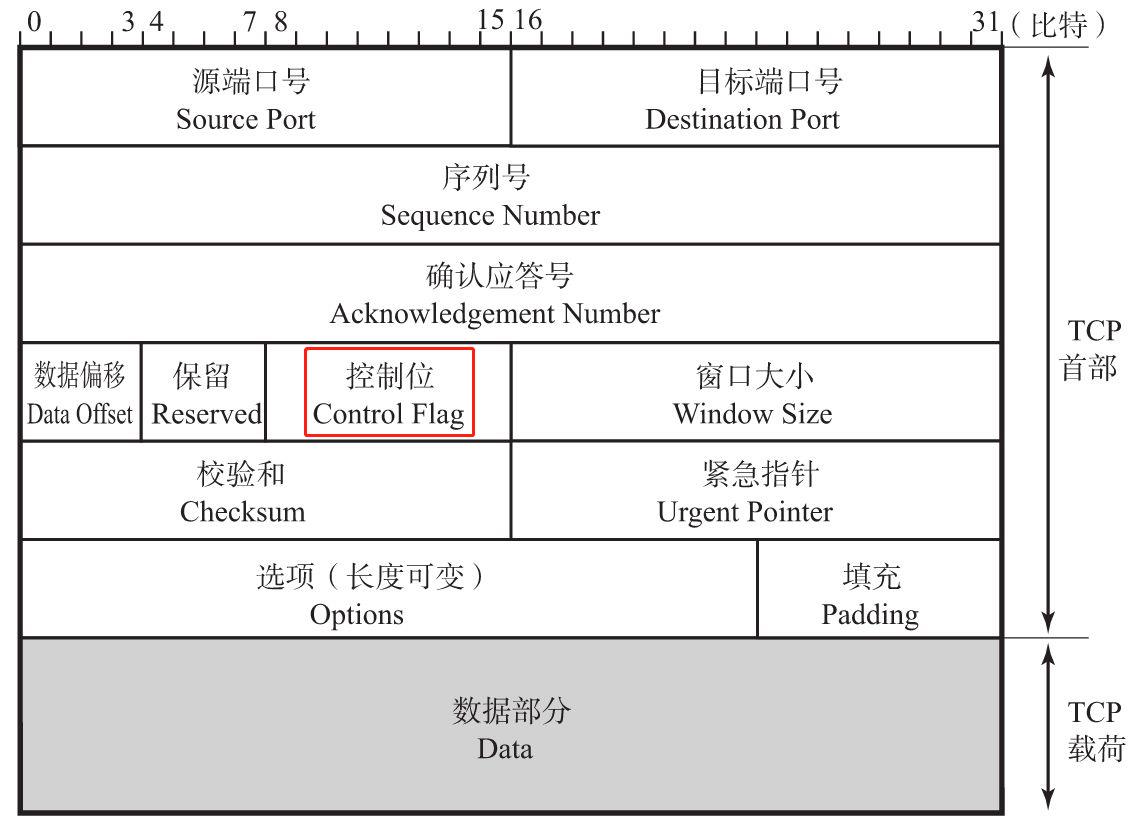
字段长为8位,每一位从左至右分别为CWR、ECE、URG、ACK、PSH、RST、SYN、FIN。这些控制标志也叫做控制位。当它们对应位上的值为1时,具体含义如下:

CWR(Congestion Window Reduced)
CWR标志与后面的ECE标志都用于IP首部的ECN字段。ECE标志为1时,则通知对方已将拥塞窗口缩小。
ECE(ECN-Echo)
ECE标志表示ECN-Echo。置为1会通知通信对方,从对方到这边的网络有拥塞。在收到数据包的IP首部中ECN为1时将TCP首部中的ECE设置为1。
URG(Urgent Flag)
该位为1时,表示包中有需要紧急处理的数据。在目前的协议中很少用到,这个字段的功能需要配合后面的“紧急指针(Urgent Pointer)”一起使用,
ACK(Acknowledgement Flag)
该位为1时,确认应答的字段变为有效,ACK字段用于确认成功接收数据包。
PSH(Push Flag)
该位为1时,表示需要将受到的数据立刻传给上层应用协议。PSH为0时,则不需要立即传而是先进行缓存。
RST(Reset Flag)
该位为1时表示TCP连接中出现异常必须强制断开连接。例如,一个没有被使用的端口即使发来连接请求,也无法进行通信。此时就可以返回一个RST设置为1的包。此外,程序宕掉或切断电源等原因导致主机重启的情况下,由于所有的连接信息将全部被初始化,所以原有的TCP通信也将不能继续进行。这种情况下,如果通信对方发送一个设置为1的RST包,就会使通信强制断开连接。
SYN(Synchronize Flag)
用于建立连接。SYN为1表示希望建立连接,并在其序列号的字段进行序列号初始值的设定(Synchronize本身有同步的意思。也就意味着建立连接的双方,序列号和确认应答号要保持同步) 。
FIN(Fin Flag)
该位为1时,表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双方的主机之间就可以相互交换FIN位置为1的TCP段。每个主机又对对方的FIN包进行确认应答以后就可以断开连接。不过,主机收到FIN设置为1的TCP段以后不必马上回复一个FIN包,而是可以等到缓冲区中的所有数据都因已成功发送而被自动删除之后再发。
窗口大小(Window Size)
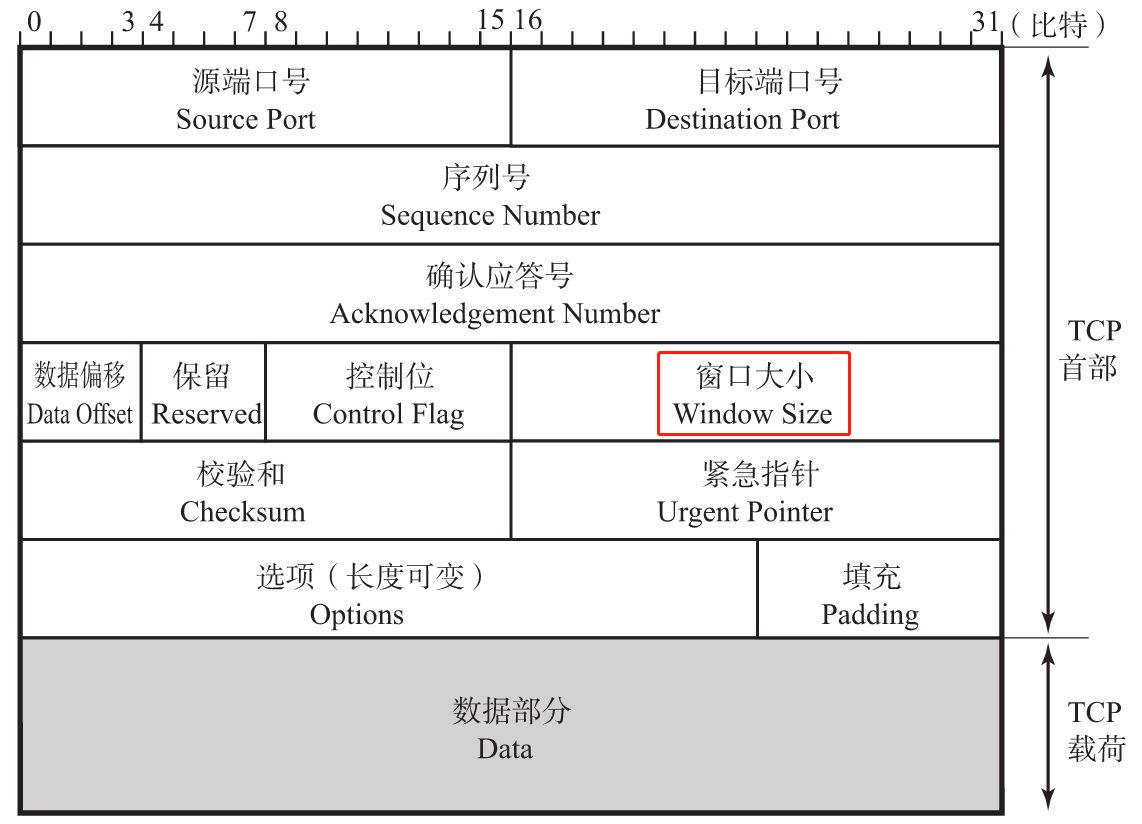
该字段长为16位。用于通知从相同TCP首部的确认应答号所指位置开始能够接收的数据大小(8位字节)。TCP不允许发送超过此处所示大小的数据,换句话说就是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。不过,如果窗口为0,则表示可以发送窗口探测,以了解最新的窗口大小。但这个数据必须是1个字节。
校验和(Checksum)
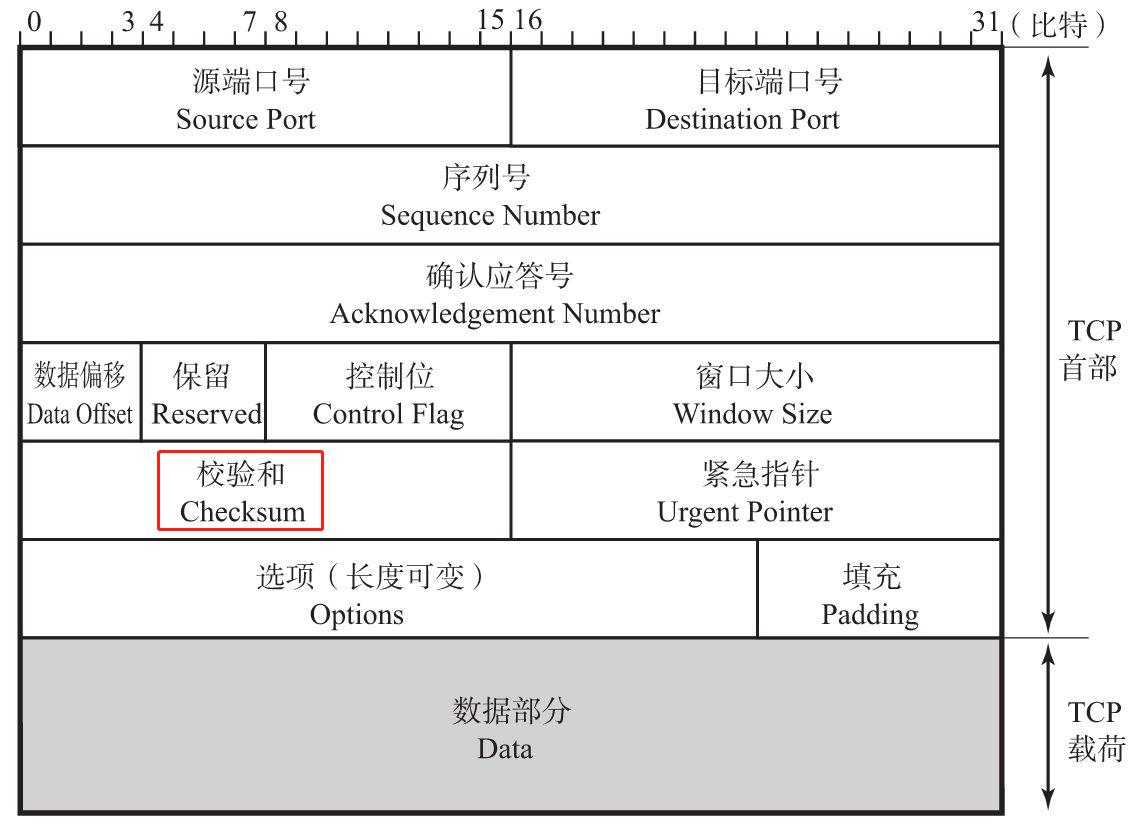
该字段长为16位。由发送端填充,接收端对 TCP 报文段执行 CRC 算法,以检验 TCP 报文段在传输过程中是否损坏,会校验包括IP头部、TCP头部和TCP数据在内的整个序列,确保IP地址、端口号和其他相关信息正确,如果损坏接收方会丢弃该TCP片段。检验范围包括首部和数据两部分,这也是 TCP 可靠传输的一个重要保障。
紧急指针(Urgent Pointer)
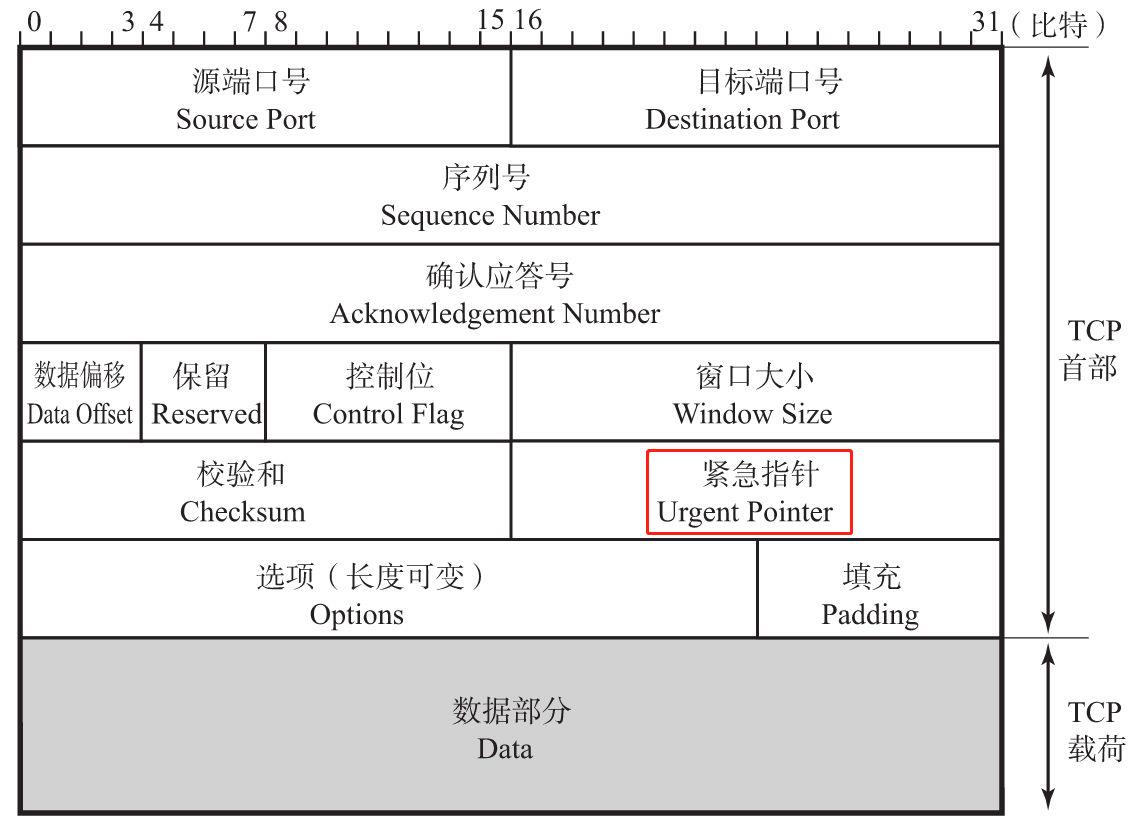
该字段长为16位。仅在 URG = 1 时才有意义,它指出本报文段中的紧急数据的字节数。当 URG = 1 时,发送方 TCP 就把紧急数据插入到本报文段数据的最前面,而在紧急数据后面的数据仍是普通数据。因此,紧急指针指出了紧急数据的末尾在报文段中的位置。
TCP的三次握手
为什么要三次握手
因为想确保彼此告诉对方的东西都被准确无误的听到了,类比到现实生活中就是打电话,你给别人打电话,不可能电话一接通你就啪啦啪啦地说一大通,万一对方接通电话后因为有事还没来得及倾听呢?这不太符合正常人类的交流习惯。一般是电话接通后,双方一般会有个交互的过程,一般是你说一声“你好”,然后对方也回复一声“你好”,双方通过各自一句“你好”明确对方的注意力都放在了电话沟通上,然后你们双方就可以开始交流了,这才是正常的人类交流方式,这个过程体现在计算机网络里就是网络协议!我们通过TCP协议在两台电脑建立网络连接之前要先发数据包进行沟通,沟通后再建立连接,然后才是信息的传输,这个机器沟通的过程和人打电话沟通的过程类似,但因为机器始终是机器,没有人那么智能,必须用一系列机制来确保“双方的注意力都放在了电话沟通上”,在TCP建立连接的过程中,这个机制就是三次握手,这三次握手中的Seq、ACK以及控制字段彼此呼应,完成了建立沟通的过程。
当然,上面这部分完全是为了方便理解所做的比喻,但真实情况和上面的例子还是有一些差别的,如果有兴趣请自行查阅这篇文章,后面我也会结合文章和自己的体会整理一篇单独的笔记,在这里摘要其中一些部分进行说明。
在RFC793 - Transmission Control Protocol 的文档中,清楚的定义了TCP使用三次握手的重要原因——为了阻止历史的重复链接初始化造成的混乱问题,防止使用TCP协议通信的双方建立了错误的连接。
The principle reason for the three-way handshake is to prevent old duplicate connection initiations from causing confusion.
当然,也有另一个原因就是让通信的双方确定初始序列号。
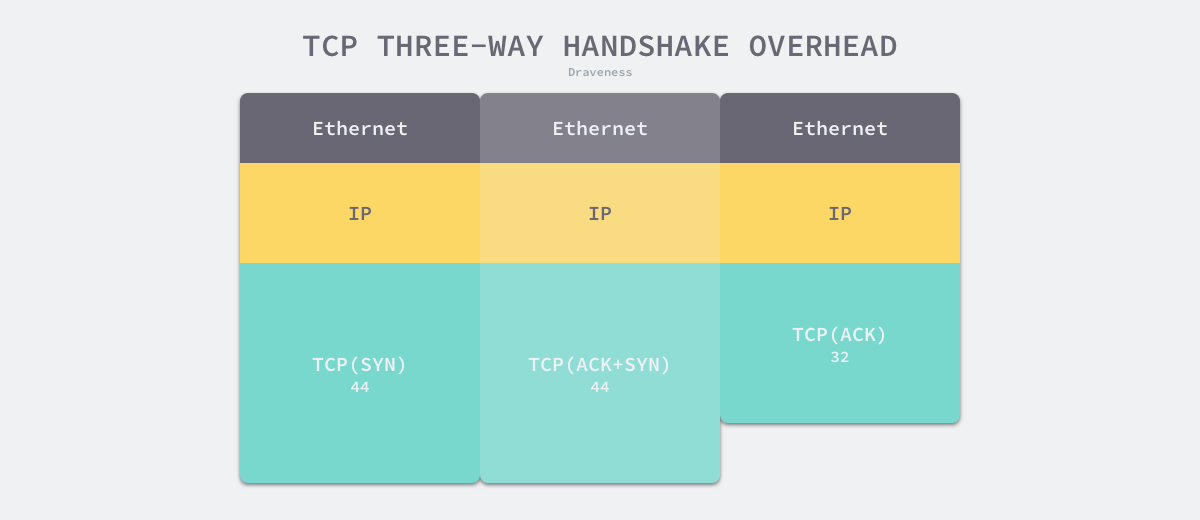
三次握手建立TCP连接的成本相当高,不仅需要额外增加1.5RTT的网络延迟,还要增加222字节的额外开销,以太网数据帧头是3*14=42字节,IP数据帧头占据3 * 20 = 60字节,TCP数据占据3 * 40 =120字节,加起来一共是222字节。所以在弱网环境下,通过三次握手建立TCP连接会加剧TCP的性能问题。
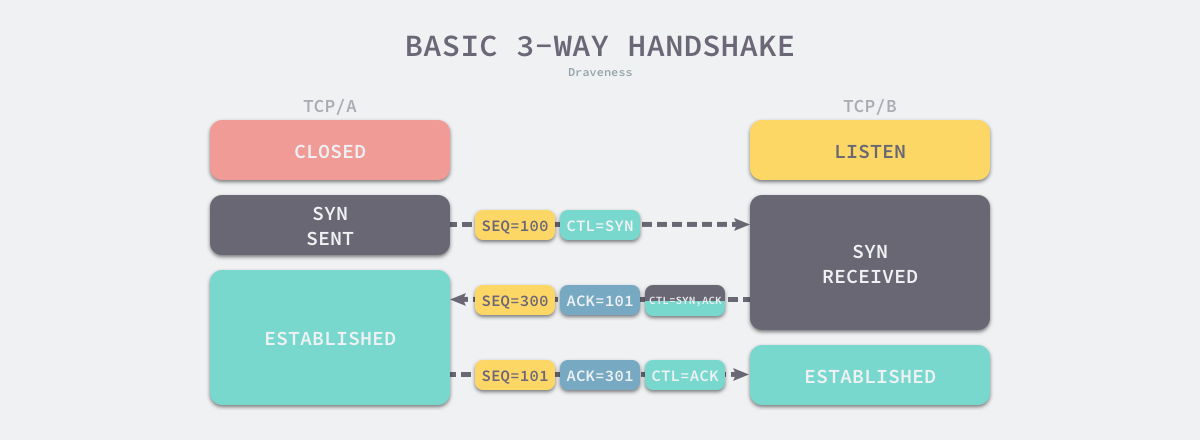

第一次握手:
- 理论分析:
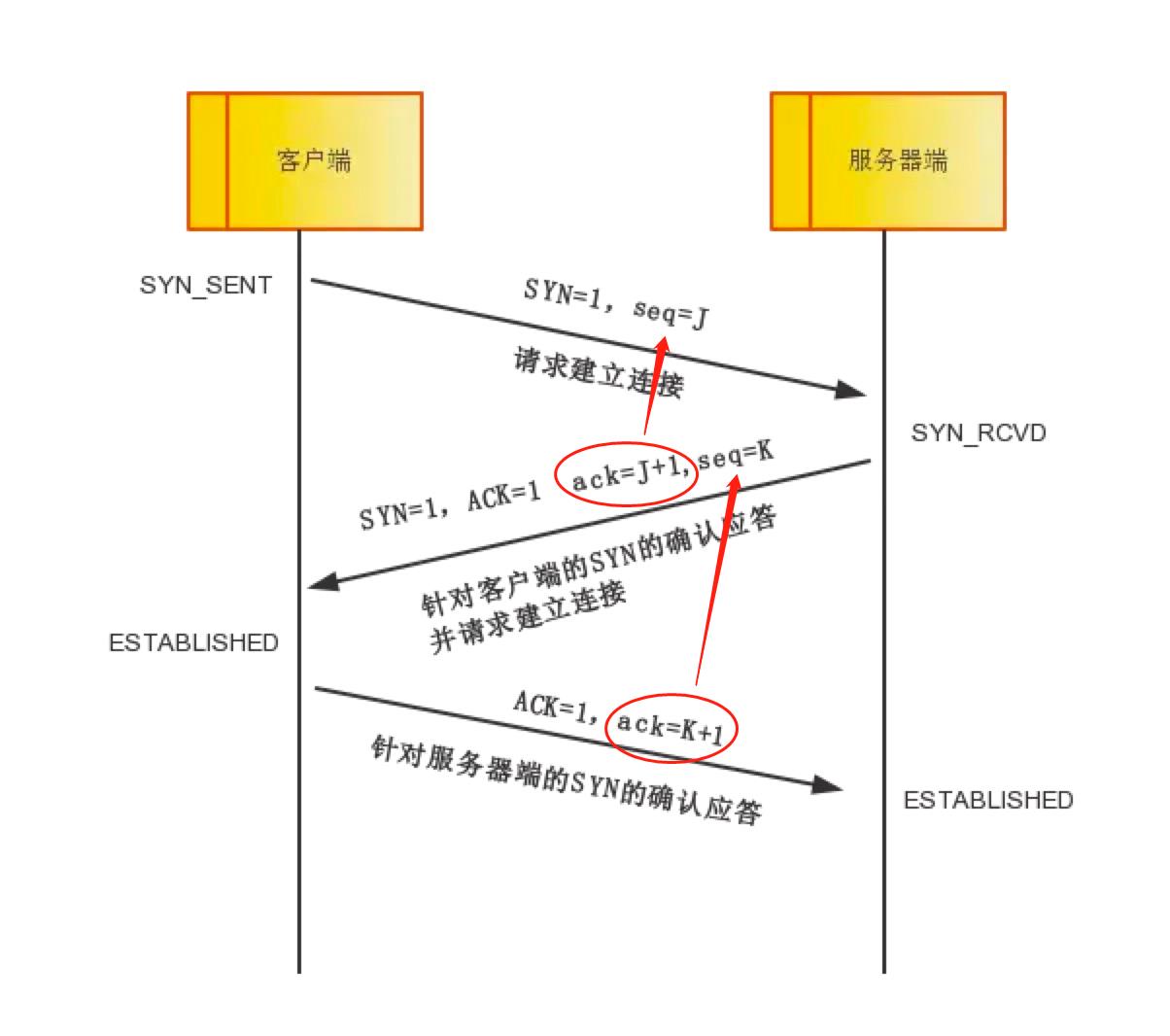
客户端将标志位SYN置为1,表示我要和对方建立TCP连接,现在开始三次握手,并随机产生一个值seq=J,并将该数据包发送给服务器端,客户端进入SYN_SENT状态,等待服务器端确认。
- 实际抓包过程举例:

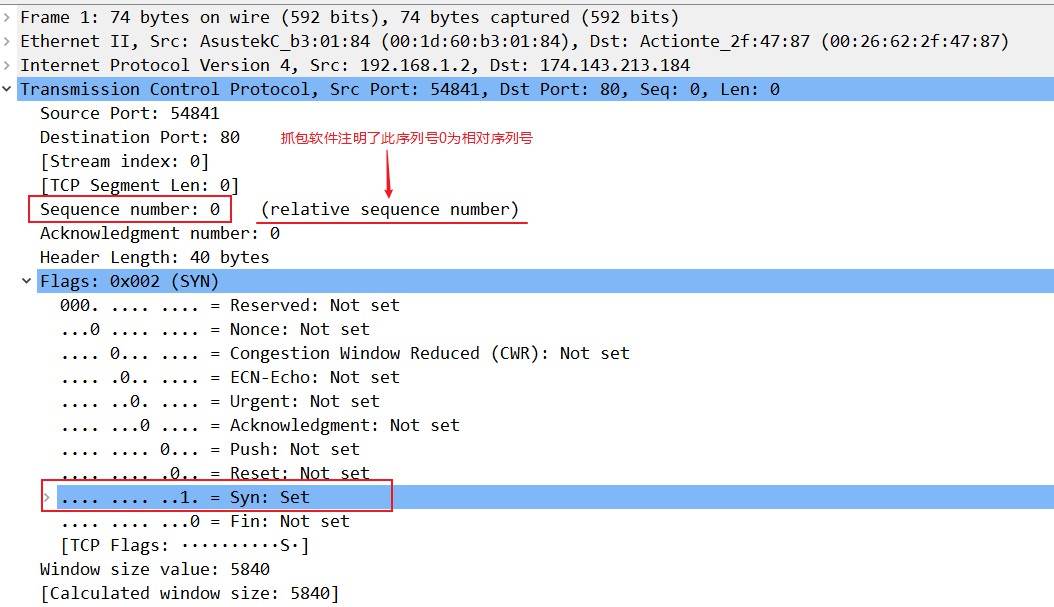
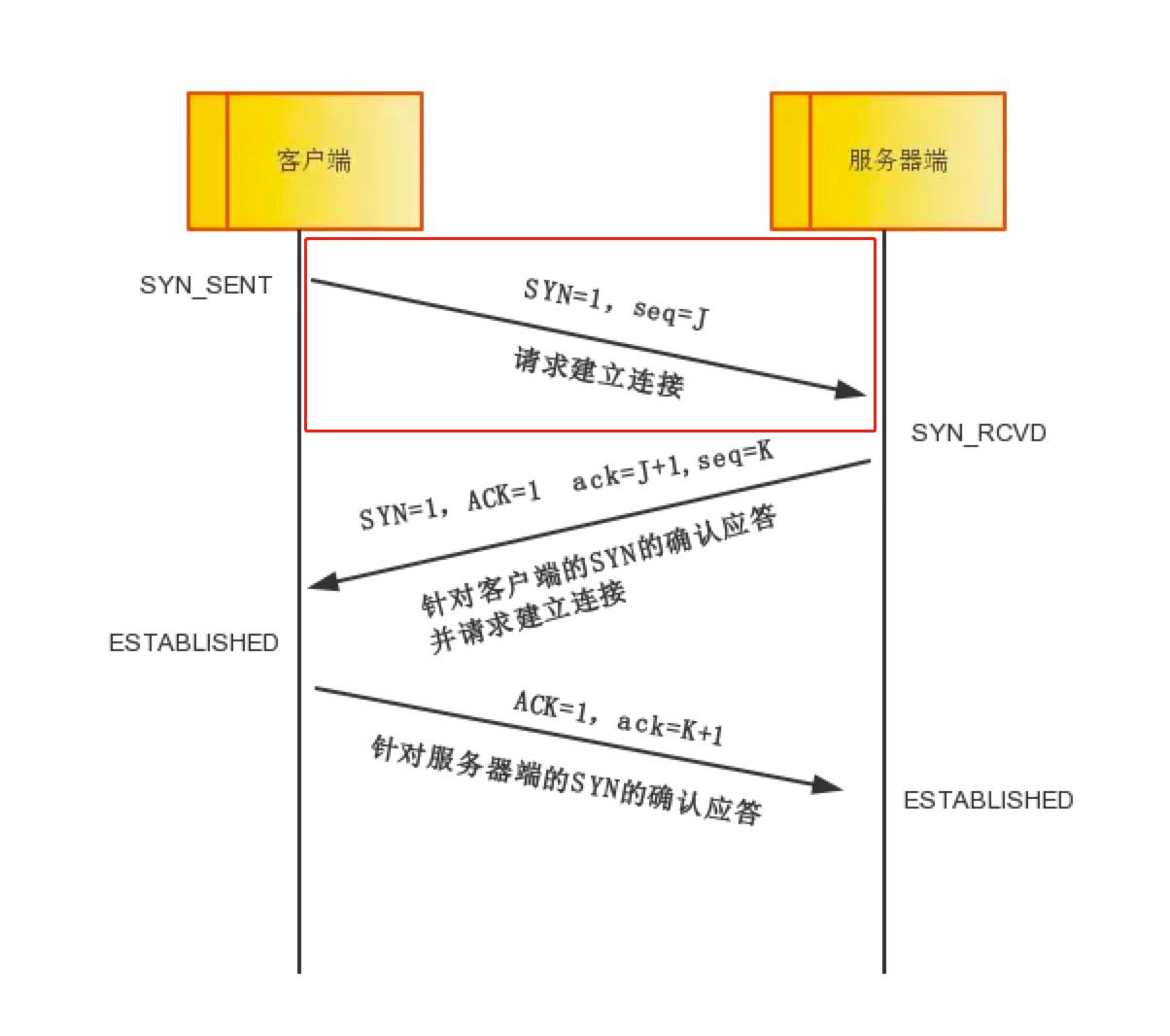
开始三次握手的设备1(IP地址为192.168.1.2)会将TCP控制位(Control Flag)中的SYN位置为1,表示希望建立TCP连接;序列号(Sequence Number)置为J,在这J为0,因为这是设备1发送的第一个TCP数据(这个0是相对序列号,解释见上边序列号部分或下段说明),并将该数据包发送给对端的设备2(IP地址为174.143.213.184),客户端进入SYN_SENT状态,等待对端确认。会话的每一端都以(相对)序列号零开始。同样,确认数也为零,因为还没有对话的互补面需要确认。
必须注意的是,主机启动TCP会话时,其初始序列号实际上是随机的; 它可以是0到4,294,967,295(含)之间的任何值。 但是,像Wireshark这样的抓包分析软件通常会显示相对序列和确认号来代替实际值。 这些数字是相对于该流的初始序列号。 这很方便,因为跟踪相对较小的可预测数字比在线上发送的实际数字要容易得多。
第二次握手:
- 理论分析:
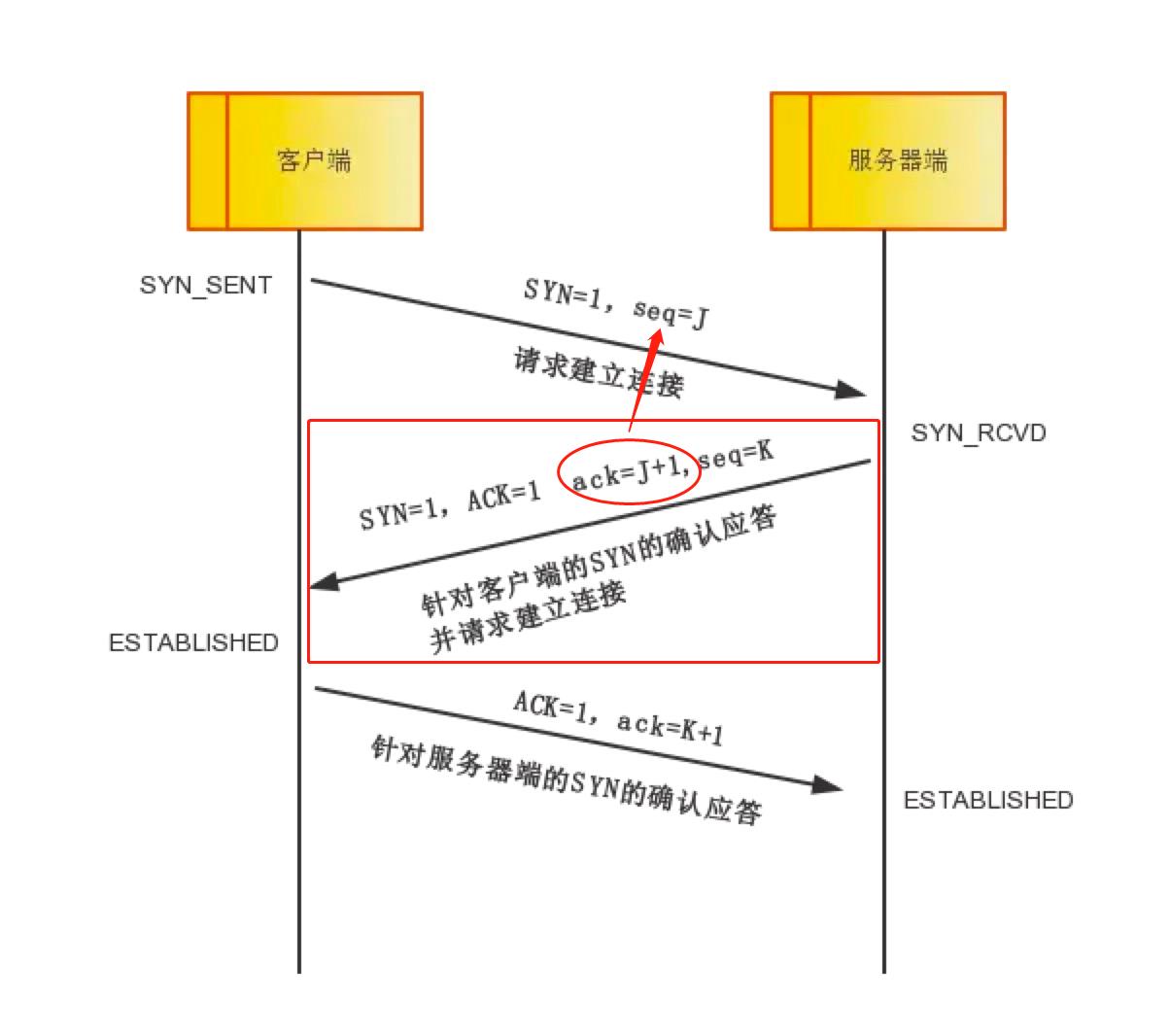
服务器端收到数据包后由标志位SYN=1知道客户端请求建立连接,服务器端将标志位SYN和ACK都置为1,SYN置位为1表示我也要建立连接,ACK置位为1表示这个是确认收到了对方之前的回复;ack=J+1,表示这个带ack的值是回应之前Seq值为J的数据的,随机产生一个值seq=K,并将该数据包发送给客户端以确认连接请求,服务器端进入SYN_RCVD状态。
- 实际抓包过程举例:

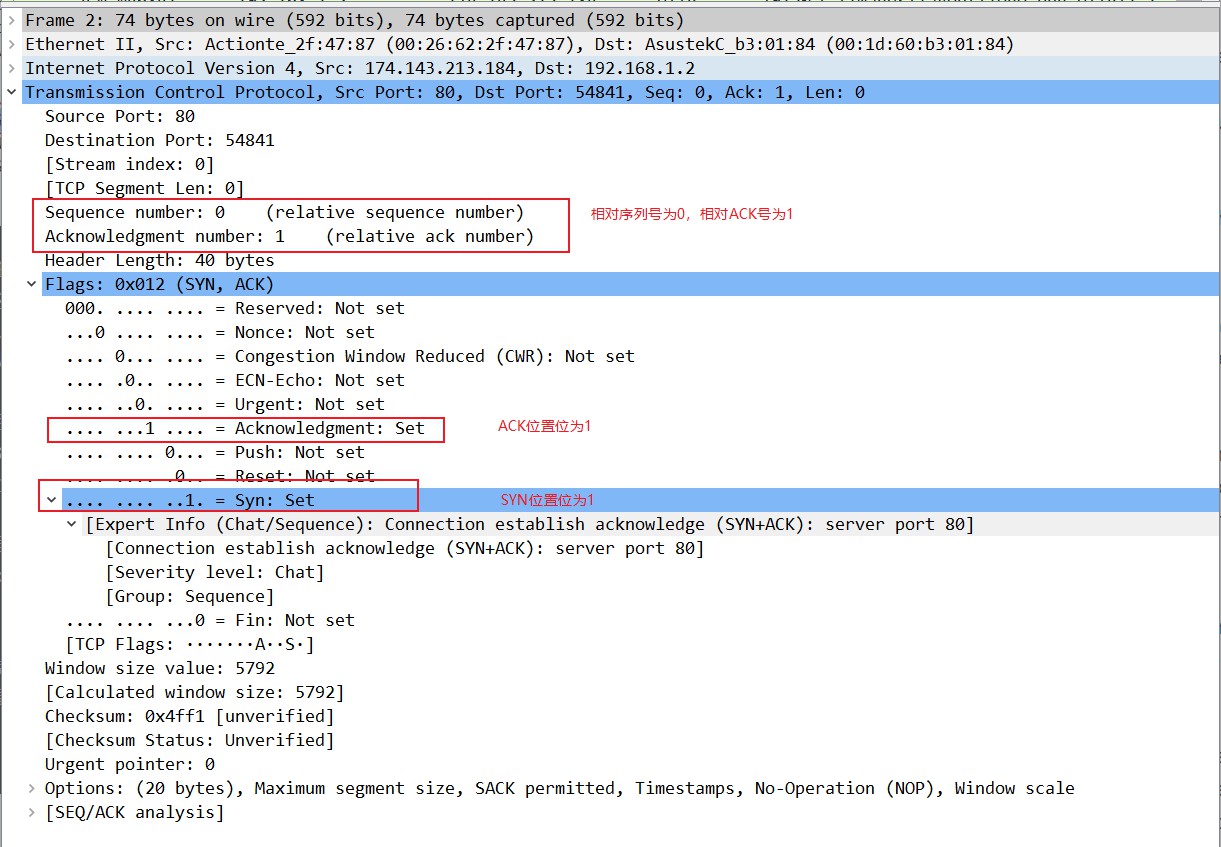
设备2(IP地址为174.143.213.184)收到数据包后解封装发现TCP的控制位中SYN置1,说明设备1(IP地址为192.168.1.2)请求建立连接,于是将自己TCP的控制位中的SYN和ACK都置为1,SYN置位为1表示我也要建立连接,ACK置位为1表示这个是确认收到了对方之前的回复;ACK为设备1的序列号J+1,第一次握手的J=0,所以这里的ACK为1,表示我确认的是之前序列号为0的那个数据;随机产生一个序列号K,这个K在这也是0(相对序列号),因为这是设备2第一次和设备1通信,然后将该数据包发送给设备1并进入SYN_RCVD状态。
第三次握手:
- 理论分析:
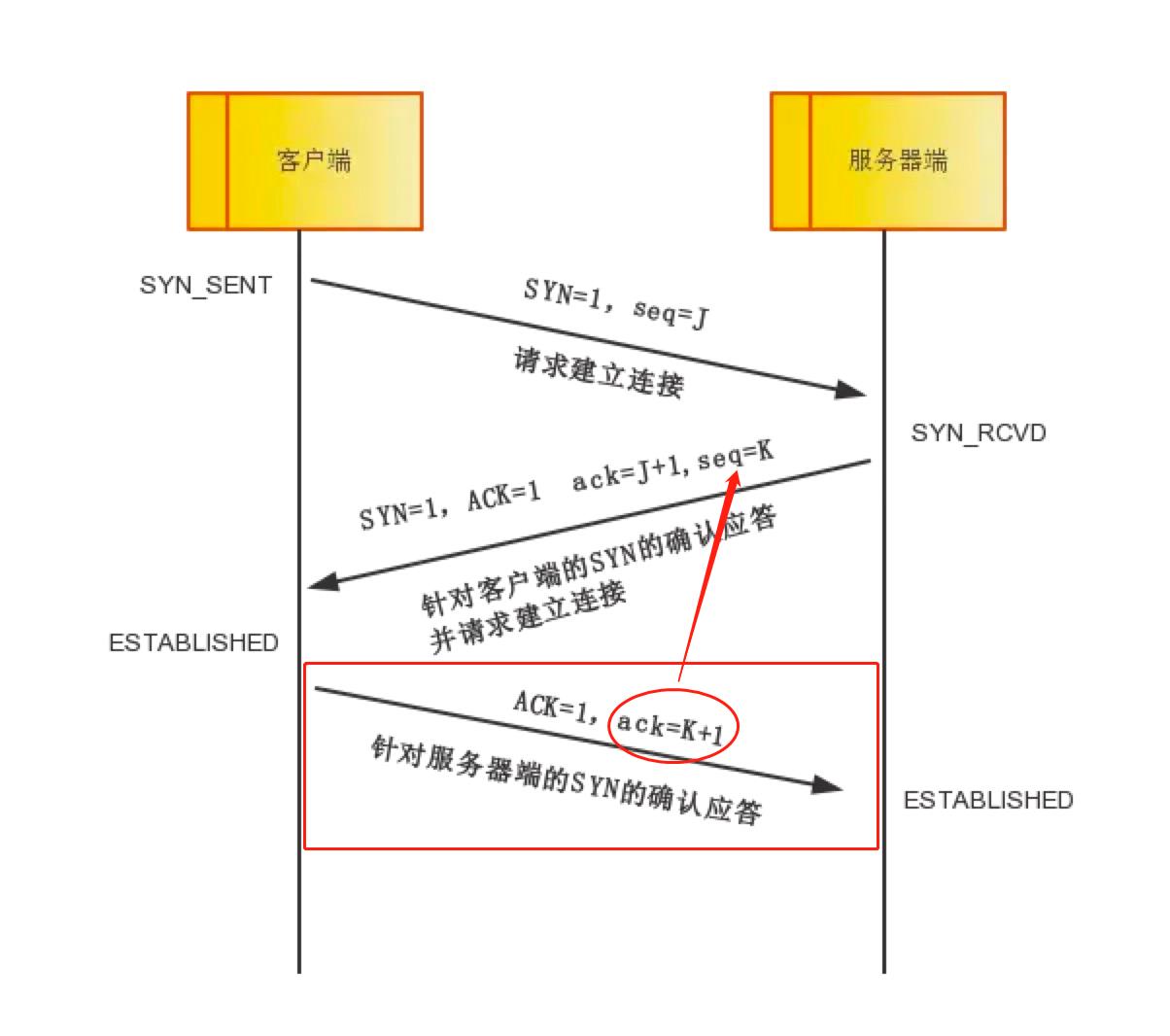
客户端收到确认后,检查ack是否为J+1(回应之前Seq值为J的数据),ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给服务器端,服务器端检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,客户端和服务器端进入ESTABLISHED状态,完成三次握手,随后客户端与服务器端之间可以开始传输数据了。
- 实际抓包过程举例:

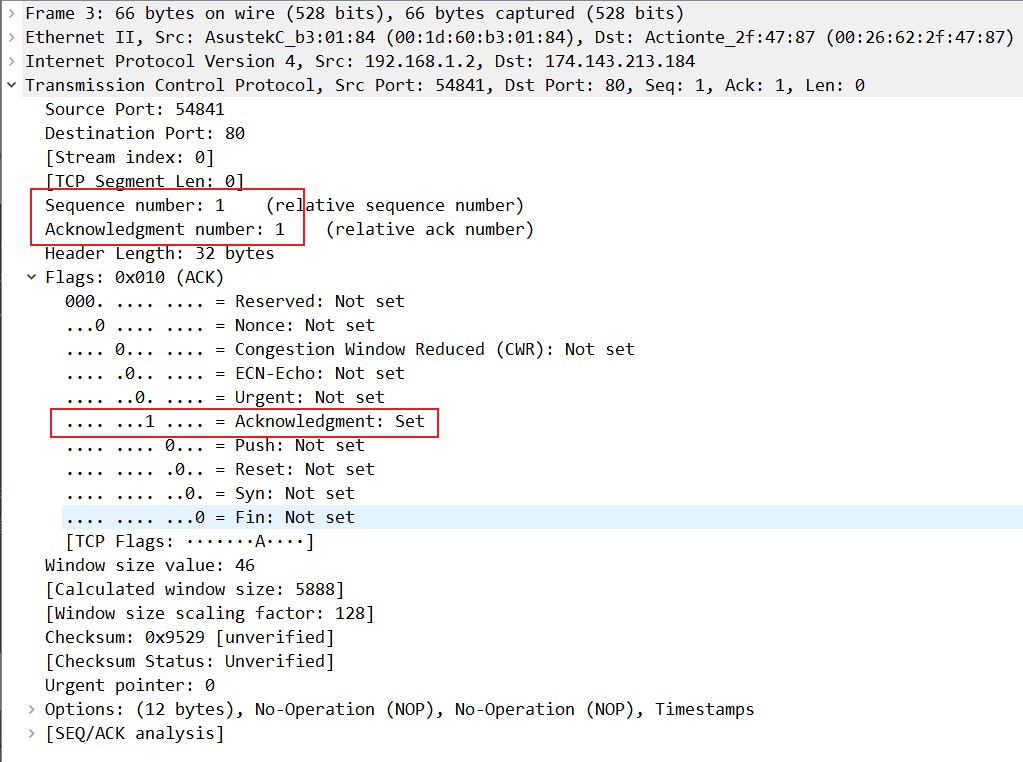
设备1(IP地址为192.168.1.2)收到确认后,检查ack是否为J+1,之前J=0,所以检查ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,前面的K=0,并将该数据包发送给设备2(IP地址为174.143.213.184),设备2检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,两个设备均进入了ESTABLISHED状态,完成三次握手,随后客户端与服务器端之间可以开始传输数据了。
TCP三次握手的漏洞:
漏洞:SYN洪泛攻击
定义:
通过网络服务所在的端口发送大量伪造原地址的攻击报文,发送到服务端,造成服务端上的半开连接队列被占满,从而阻止其他用户进行访问。
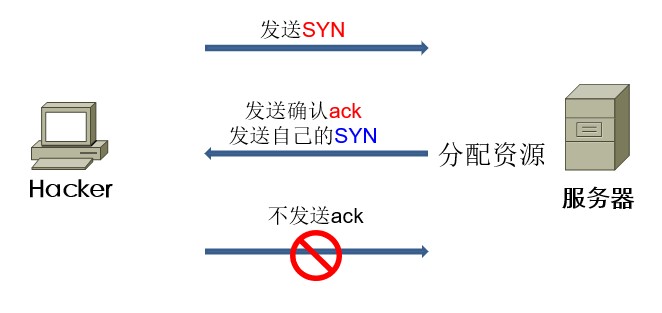
原理:
当开放了一个TCP端口后,该端口就处于Listening状态,不停地监视发到该端口的SYN报文,一旦接收到Client发来的SYN报文,就需要为该请求分配一个TCB(Transmission Control Block),通常一个TCB至少需要280个字节,在某些操作系统中TCB甚至需要1300个字节,并返回一个SYNACK报文,立即转为SYN-RECEIVED即半开连接状态,而某些操作系统在SOCKT的实现上最多可开启512个半开连接(如Linux2.4.20 内核)。
如果恶意的向某个服务器端口发送大量的SYN包(第一次握手),而服务端的响应(第二次握手)的报文将永远发送不到真实的客户端,服务端在等待客户端的第三次握手(永远都不会有的),则可以使服务器打开大量的半开连接,分配TCB,从而消耗大量的服务器资源,同时也使得正常的连接请求无法被相应。而攻击发起方的资源消耗相比较可忽略不计。
解决方案:
无效连接监控释放:
不停的监视系统的半开连接和不活动连接,当达到一定阈值时拆除这些连接,从而释放系统资源。这种方法对于所有的连接一视同仁,而且由于SYN Flood造成的半开连接数量很大,正常连接请求也被淹没在其中被这种方式误释放掉。
延缓TCB分配方法:
1、SYN Cache技术
这种技术是在收到SYN数据报文时不急于去分配TCB,而是先回应一个SYN ACK报文,并在一个专用HASH表(Cache)中保存这种半开连接信息,直到收到正确的回应ACK报文再分配TCB。
2、SYN Cookie技术:
Syn Cookie技术则完全不使用任何存储资源,这种方法比较巧妙,它使用一种特殊的算法生成Sequence Number,这种算法考虑到了对方的IP、端口、己方IP、端口的固定信息,以及对方无法知道而己方比较固定的一些信息,如MSS、时间等,在收到对方的ACK报文后,重新计算一遍,看其是否与对方回应报文中的(SequenceNumber-1)相同,从而决定是否分配TCB资源。
防火墙:
很多防火墙中都提供一种SYN代理的功能,其主要原理是对试图穿越的SYN请求进行验证后才放行。
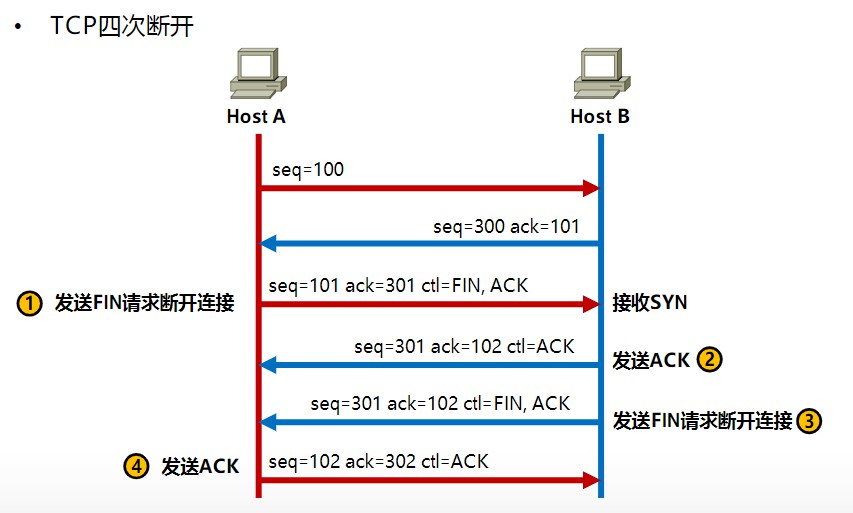
TCP的四次分手
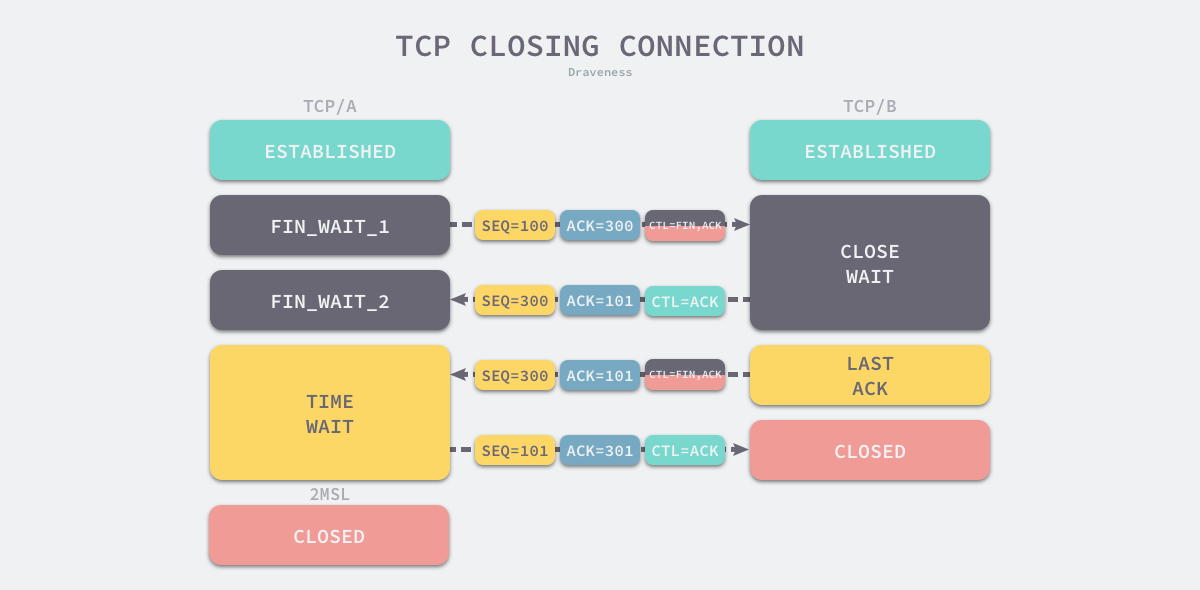


建立起TCP连接的设备两端均可以发起中断连接。
第一次分手:

理论步骤:客户端发送一个FIN=M,用来关闭客户端到服务器端的数据传送,客户端进入FIN_WAIT_1状态。意思是说”我客户端没有数据要发给你了”,但是如果你服务器端还有数据没有发送完成,则不必急着关闭连接,可以继续发送数据。
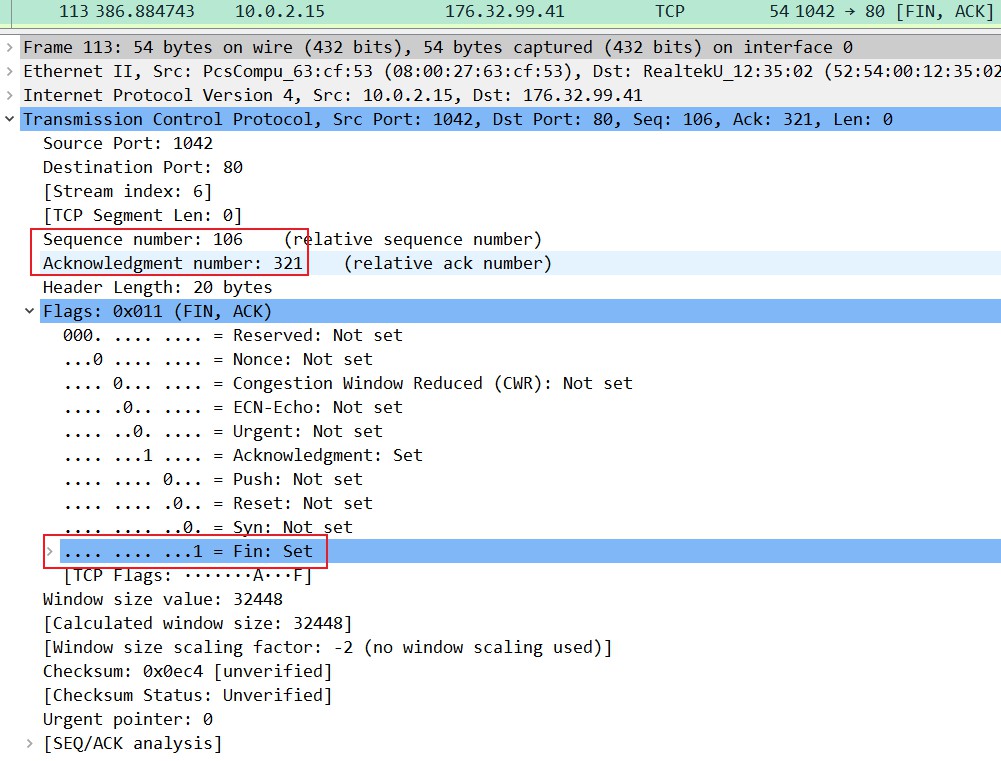
实际例子分析:设备1(IP地址为10.0.2.15)发送一个序列号(sequence number,此处为相对序列号)为106,确认应答号(Acknowledgement number)为321,这个321是用来确认之前对端发给该设备的,相对FIN与ACK均置为1的数据给设备2(IP地址为176.32.99.41),表示我这段要结束数据传送并进入FIN_WAIT_1状态。意思是说”我没有数据要发给你了”,但是如果你还有数据没有发送完成,则不必急着关闭连接,可以继续发送数据。
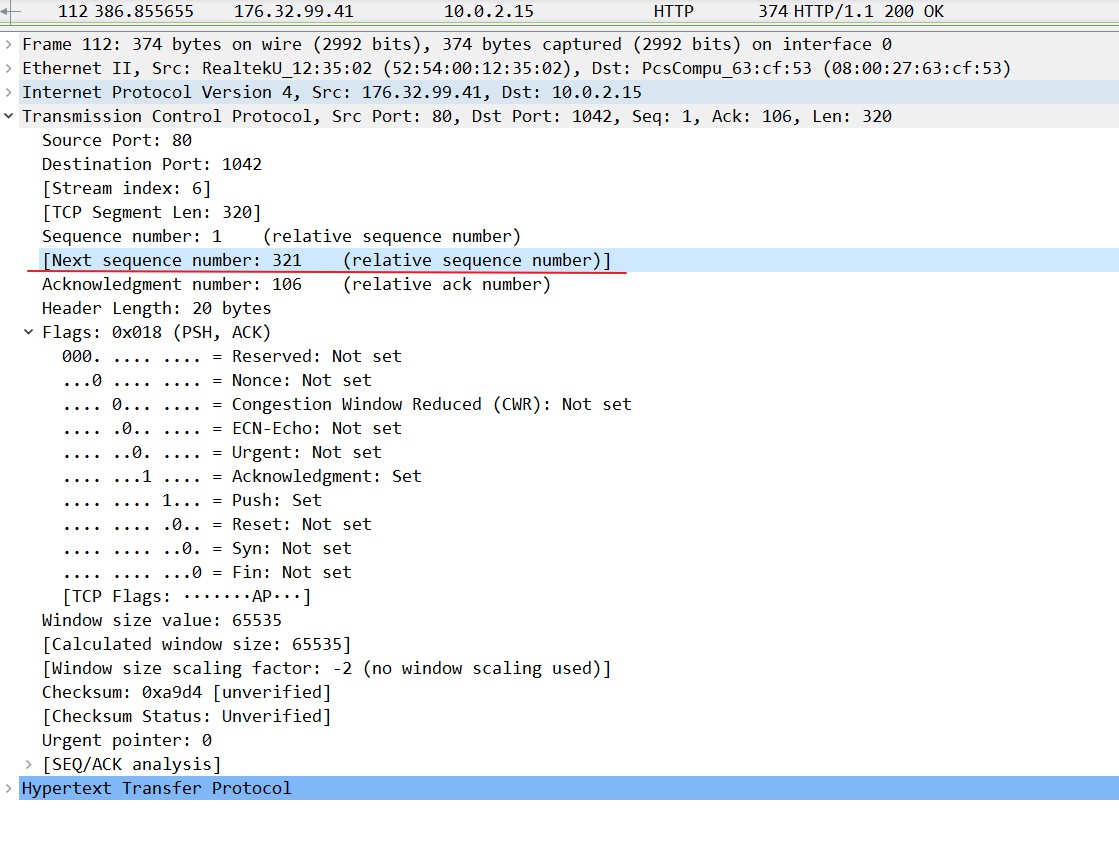
上一个数据包的Next sequence number是321,所以这个回送数据中的ACK为321,表示成功接收了320个数据,可以从序列号321开始发送,上一个数据包的抓包如下:
第二次分手:
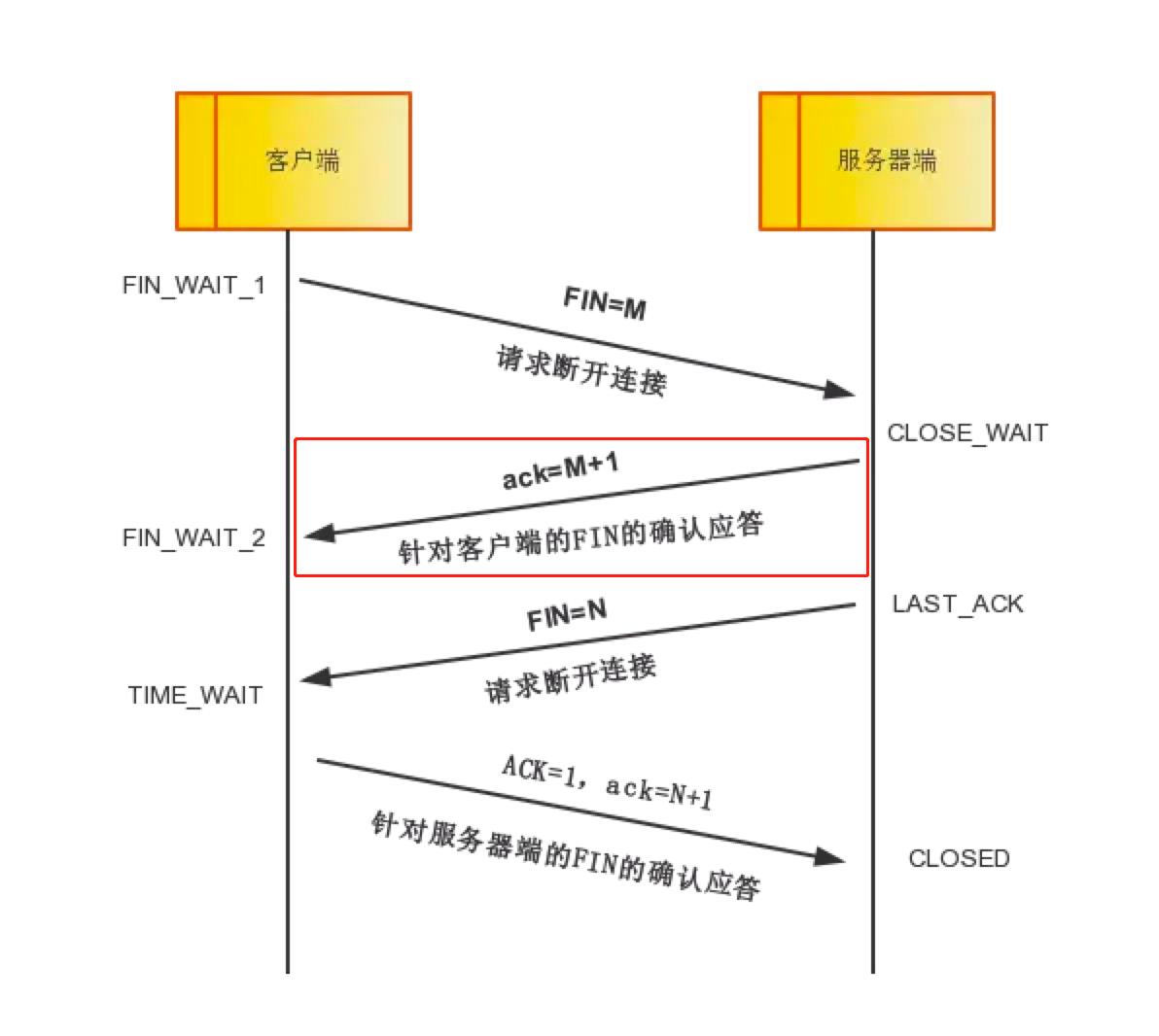
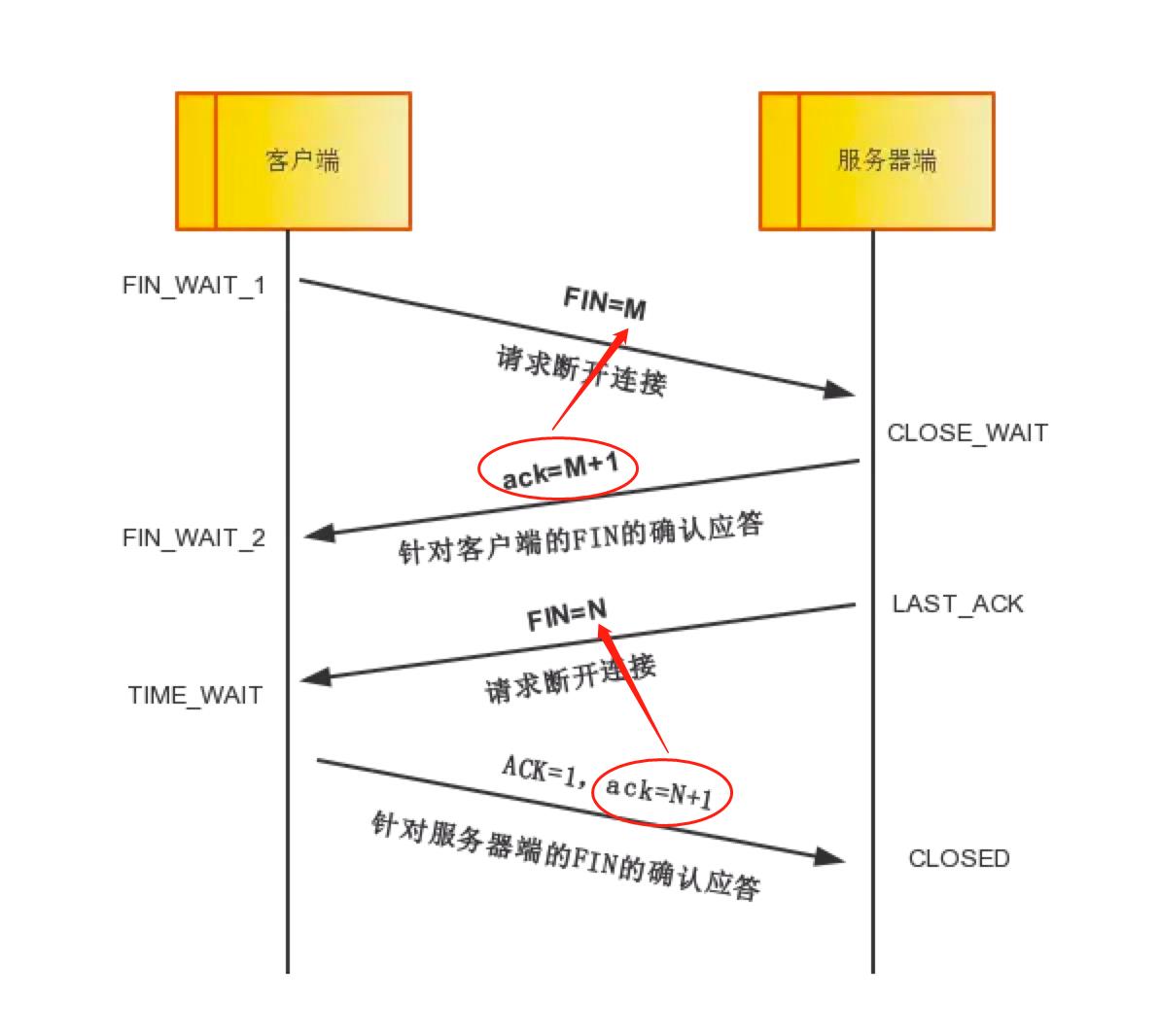
理论步骤:服务器端收到FIN后,先发送ack=M+1,告诉客户端,你的请求我收到了,但是我还没准备好,请继续你等我的消息。这个时候客户端就进入FIN_WAIT_2 状态,继续等待服务器端的FIN报文。
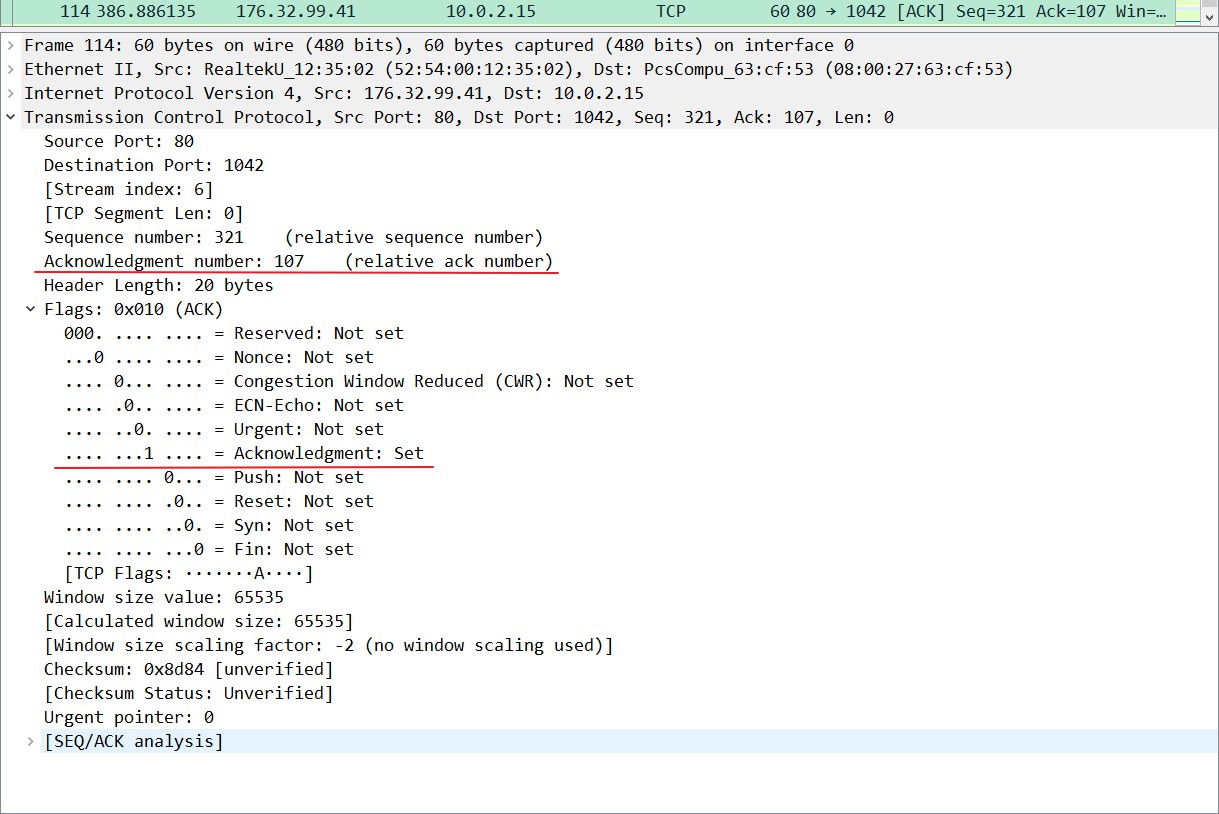
实际例子分析:设备2(IP地址为176.32.99.41)收到FIN后,先发送ack=M+1,这里的M为106,所以本数据包中的ACK为107,此序列号确认了设备1(IP地址为10.0.2.15)发送的序列号(sequence number,此处为相对序列号)为106的数据,告诉了设备1你的请求我收到了,但是我还没准备好,请继续你等我的消息。这个时候客户端就进入FIN_WAIT_2 状态,继续等待服务器端的FIN报文。
必须注意的是,这个ACK是个纯ACK,因为只有ACK置位为1了,TCP Segment Len:0,也就是没有DATA部分,没有其他的东西在里头,说明这个数据是个纯ACK,而一个只包含ACK的TCP报头不会增加序列号和ACK号的数字,所以后面第三次分手时数据的seq和ACK数字和第二次是一样的。
第三次分手:
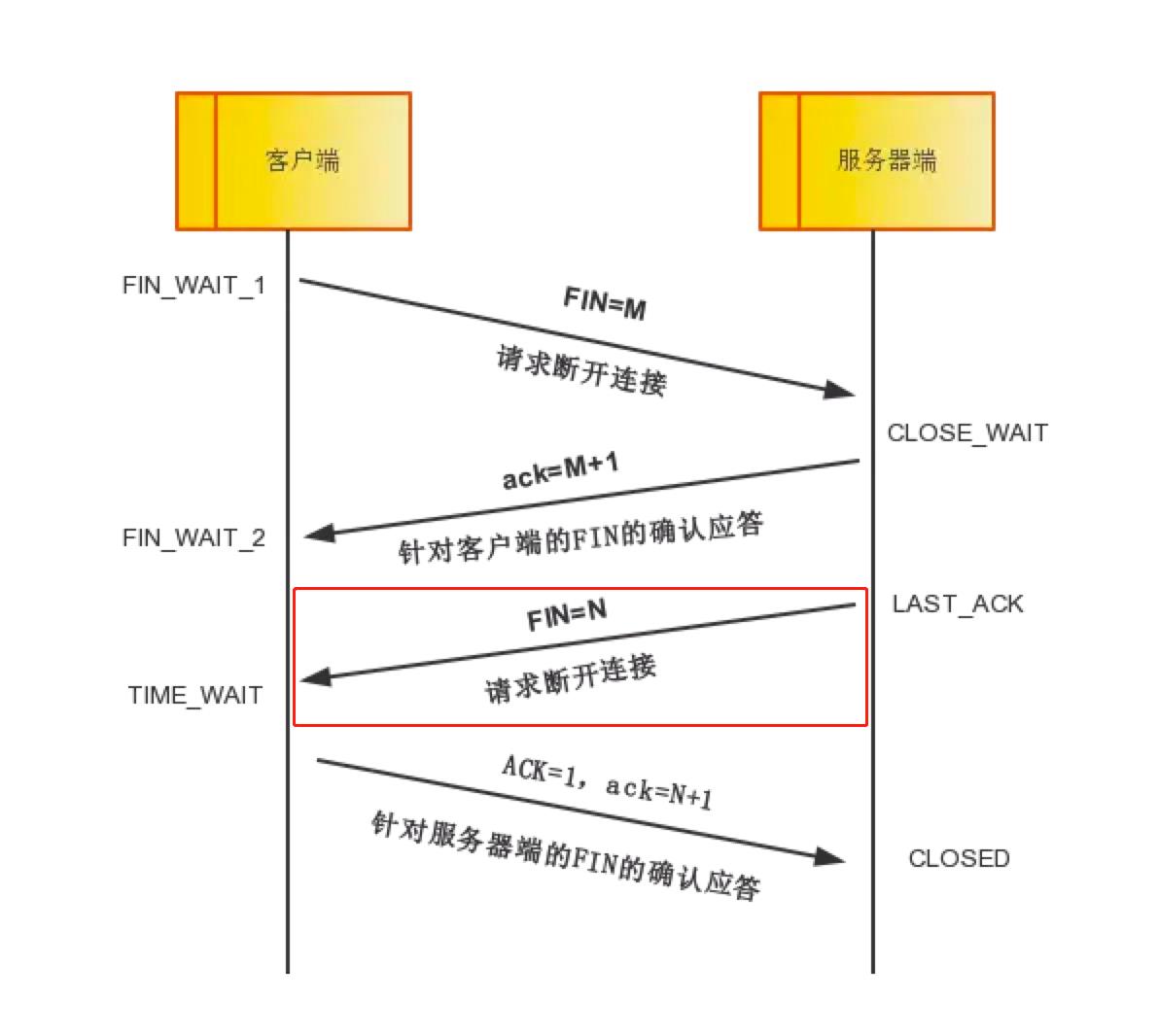
理论步骤:当服务器端确定数据已发送完成,则向客户端发送FIN=N报文,告诉客户端,好了,我这边数据发完了,准备好关闭连接了。这里其实ACK位也是置位为1的,然后ACK值也是M+1,表示确认的是之前FIN=M那个第一次分手。服务器端进入LAST_ACK状态。
实际例子分析:
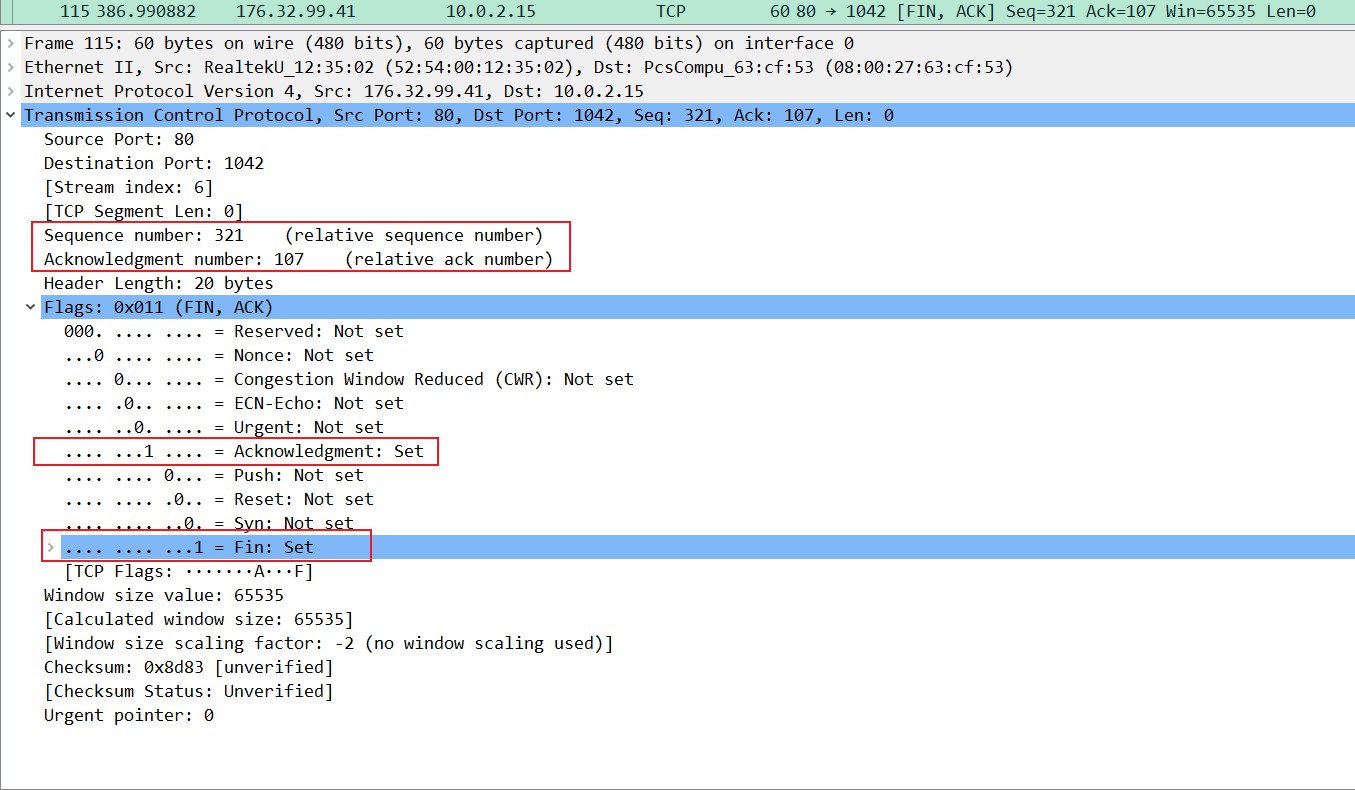
设备2(IP地址为176.32.99.41)向设备1发送FIN位置为1的报文,告诉设备1(IP地址为10.0.2.15),我这边的数据已经发送完毕,准备好关闭连接了。服务器端进入LAST_ACK状态。这里的ACK值也是上一次分手时发送给设备1的ACK值,为107,因为第二次回复的ACK是一个纯ACK,里面没有数据,TCP Segment Len=0,也就是这个里面的DATA部分为0,是一个纯ACK数据,所以这里ACK位也置为1。
关于TCP Segment Len
The TCP payload size is calculated by taking the “Total Length” from the IP header (ip.len) and then substract the “IP header length” (ip.hdr_len) and the “TCP header length” (tcp.hdr_len).
通过从IP报头(ip.len)中获取“总长度”,然后减去“ IP报头长度”(ip.hdr_len)和“ TCP报头长度”(tcp.hdr_len),可以计算出TCP有效负载大小。tcp payload是0 说明要么是三次握手,四次关闭,要么是纯ack。
第四次分手:
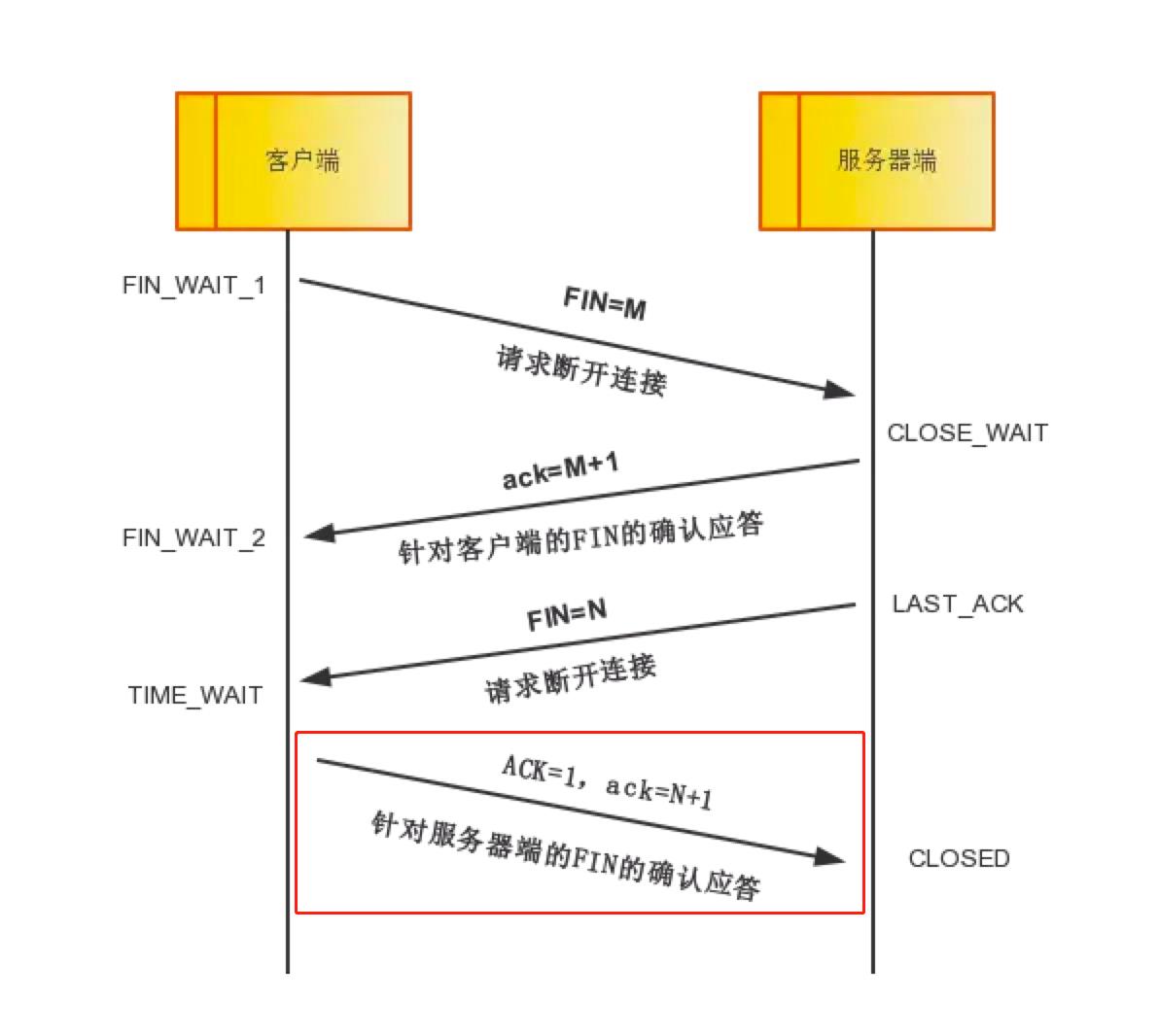
理论步骤:客户端收到FIN=N报文后,就知道可以关闭连接了,但是他还是不相信网络,怕服务器端不知道要关闭,所以发送ack=N+1后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。服务器端收到ACK后,就知道可以断开连接了。客户端等待了2MSL(Maximum segment lifetime is the time a TCP segment can exist in the internetwork system. )后依然没有收到回复,则证明服务器端已正常关闭,那好,我客户端也可以关闭连接了。最终完成了四次分手。
实际例子分析:
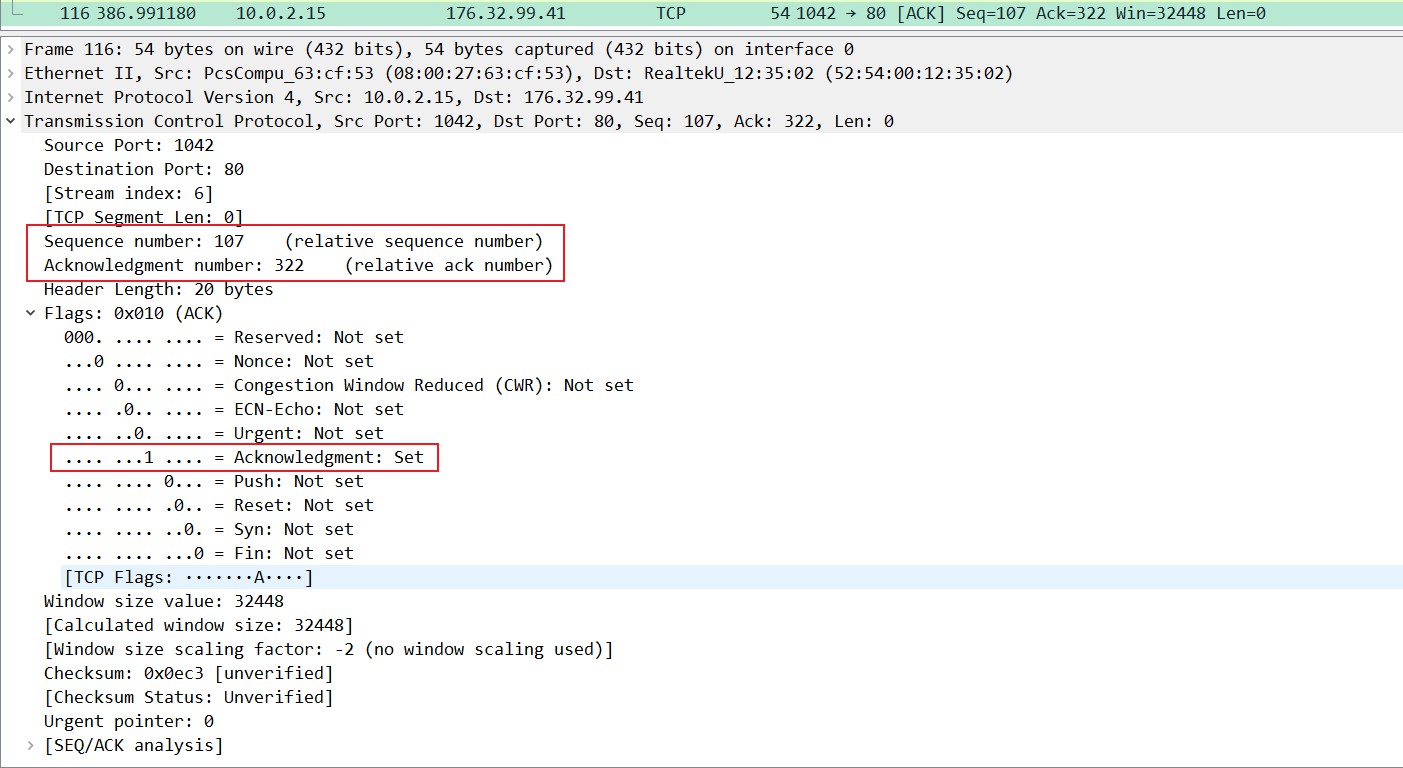
实际例子分析:
设备1(IP地址为10.0.2.15)向设备2(IP地址为176.32.99.41)发送了一个相对序列号为107,相对确认号为322,ACK置位为1的数据,表示用来确认之前对方所发送序列号为321的数据,进入TIME_WAIT状态,如果等待了2MSL(Maximum segment lifetime is the time a TCP segment can exist in the internetwork system. )后依然没有收到回复,则证明服务器端已正常关闭,那好,我客户端也可以关闭连接了。最终完成了四次分手。
上面是一方主动关闭,另一方被动关闭的情况,实际中还会出现同时发起主动关闭的情况。
It is also possible to terminate the connection by a 3-way handshake, when host A sends a FIN and host B replies with a FIN & ACK (merely combines 2 steps into one) and host A replies with an ACK
Tanenbaum, Andrew S. (2003-03-17). Computer Networks (Fourth ed.). Prentice Hall. ISBN 978-0-13-066102-9.
TCP连接的关闭也可以通过3次分手实现,当主机A发送FIN置位为1的数据时,主机B回复一个FIN和ACK位均置位为1的数据,相当于把中间的两步整合为一步,最后主机A回复一个ACK结束TCP连接,比如下图:

为什么TCP实放需要四次分手
为了保证双方都能通知对方“需要释放连接”,即在释放连接后都无法接收或发送消息给对方
- 需要明确的是:TCP是全双工模式,这意味着是双向都可以发送、接收的
- 释放连接的定义是:双方都无法接收或发送消息给对方,是双向的
- 当主机1发出“释放连接请求”(FIN报文段)时,只是表示主机1已经没有数据要发送 / 数据已经全部发送完毕;但是,这个时候主机1还是可以接受来自主机2的数据。
- 当主机2返回“确认释放连接”信息(ACK报文段)时,表示它已经知道主机1没有数据发送了 但此时主机2还是可以发送数据给主机1
- 当主机2也发送了FIN报文段时,即告诉主机1我也没有数据要发送了 此时,主机1和2已经无法进行通信:主机1无法发送数据给主机2,主机2也无法发送数据给主机1,此时,TCP的连接才算释放。
为什么 TCP 协议有 TIME_WAIT 状态
??????????????????????????????????????
TCP的流量控制——窗口滑动机制
窗口
TCP 用“序列号(Sequence Number)”和“确认应答号(Acknowledge Number)”确保数据可靠传输,但如果每发送一个数据都要等对端发送ACK确认后才能发送下一个数据的话,显然效率是很低的,而且包的往返时间越长通信性能就越低,为解决这个问题,TCP引入了窗口这个概念。不再是一个数据段确认一次,而是以更大的单位进行确认,这么做的好处是转发时间将会被大幅地缩短。也就是说,发送端主机,在发送了一个数据段以后不必要一直等待确认应答,而是继续发送其他的数据段。接收方的硬件性能有限,不可能在同一时间处理完这些数据,所以接收方利用接收缓存(Buffer)去暂时存储那些还没来得及处理的数据。但接收这些未经确认的数据是有大小限制的,这个限制的大小称作窗口大小,也就是TCP报头中的16位字段“Window Size”,这个字段用来告诉发送端,接收端还有多少缓存可以用,发送端会根据缓存的大小来调整发送的数据量。换句话说,窗口大小就是指无需等待确认应答而可以继续发送数据的最大值。但是这个数值并不是对方一次发送数据的值,因为发送数据的值收到带宽等多方面因素的影响。
窗口的作用:
1.确保数据不丢失:如果发送的数据丢失了可以重新发。
2.控制发送速度:控制发送速度,以免接收方的缓存不够大导致溢出,同时控制流量也可以避免网络拥塞。
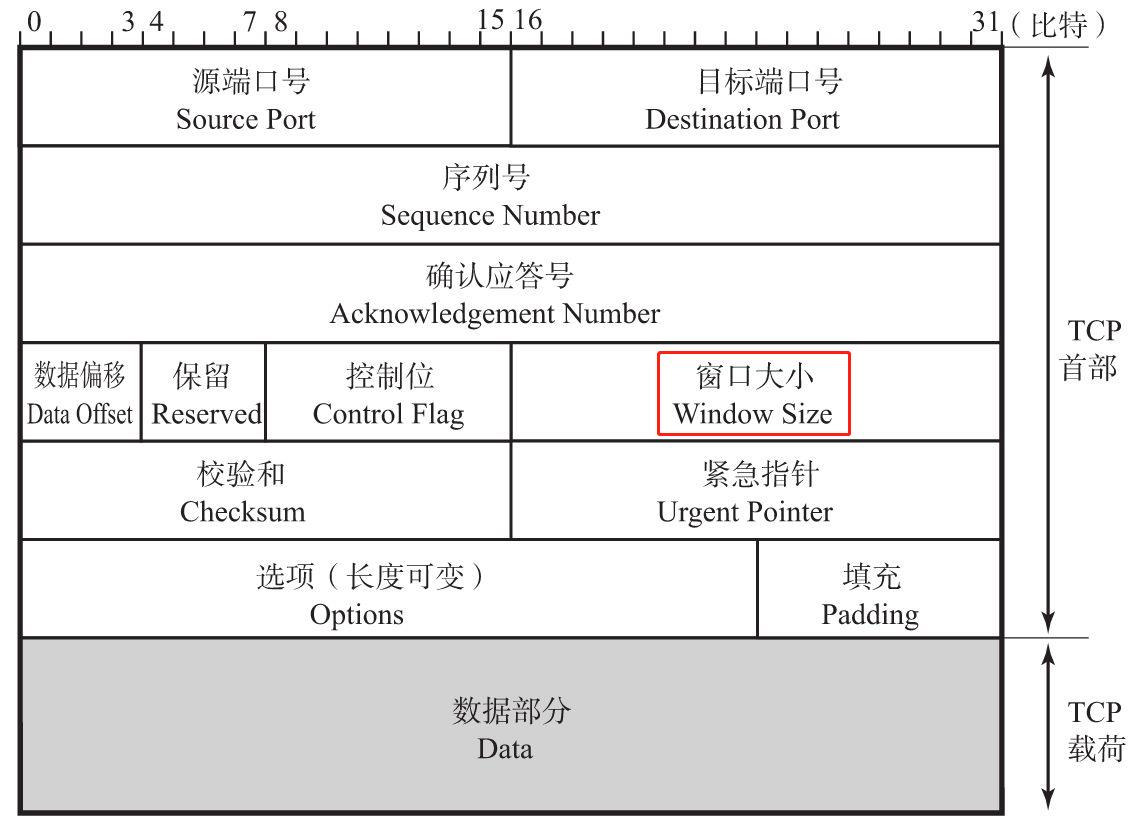
Suppose we have two hosts, A and B, that form a TCP connection. At the start of the connection, both hosts allocate 32 KB of buffer space for incoming data, so the initial window size for each is 32,768.
假设有两台主机用TCP协议连接,在TCP建立连接之初,两端都为接收数据设置了32K的缓存空间,所以这个初始的TCP 窗口大小是32678K(32X1024)。主机的buffer缓存,是由操作系统决定的。路由器交换机的buffer就是硬件内存。
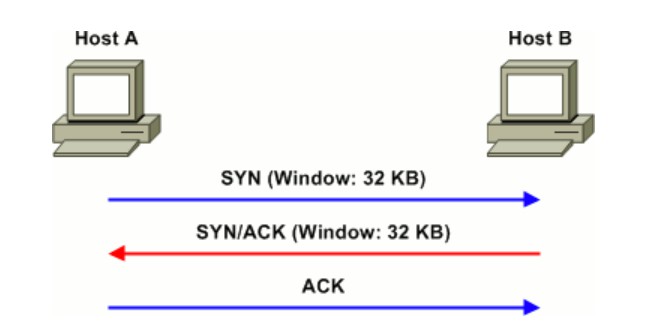
Host A needs to send data to host B. It can tell from host B’s advertised window size that it can transmit up to 32,768 bytes of data (in intervals of the maximum segment size, or MSS) before it must pause and wait for an acknowledgment. Assuming an MSS of 1460 bytes, host A can transmit 22 segments before exhausting host B’s receive window.
假设两边的MSS协商为1460位,主机A在主机B的接收缓存满之前,可发送22个数据段,1460X22=32120,小于窗口最大值32768。
When acknowledging receipt of the data sent by host A, host B can adjust its window size. For example, if the upper-layer application has only processed half of the buffer, host B would lower its window size to 16 KB. If the buffer was still entirely full, host B would set its window size to zero, indicating that it cannot yet accept more data.
确认收到主机A发送的数据后,主机B可以调整其窗口大小。 例如,如果上层应用程序仅处理了一半的缓冲区,则主机B会将其窗口大小减小到16 KB。 如果缓冲区仍然完全满,主机B会将其窗口大小设置为零,表明它还不能接收更多数据。
On a LAN with high bandwidth and extremely low delay, windows are rarely stressed as there are typically very few segments in transit between two endpoints at any given time. On a high-bandwidth, high-delay network, however, an interesting phenomenon occurs: it is possible to max out the receive window of the destination host before receiving an acknowledgment.
在具有高带宽和极低延迟的局域网也就是LAN上,TCP的窗口很少受到压力,因为在一定时间在两个端点之间传输的段通常很少。 但是,在高带宽,高延迟的网络上,会出现一个有趣的现象:主机A发送的数据有可能在主机A接收到确认之前就沾满了主机B的缓存。
As an example, let’s assume a TCP connection is established between two hosts connected by a dedicated 10 Mbps path with a one-way delay of 80ms. Both hosts advertise the maximum window size of 65,535 bytes (the maximum value of a 16-bit unsigned integer). We can calculate the potential amount of data in transit in one direction at one point in time as bandwidth * delay: 10,000,000 bps divided by 8 bits per byte, multiplied by 0.08 seconds equals 100,000 bytes. In other words, if host A begins transmitting to host B continuously, it will have sent 100,000 bytes before host B receives the first byte transmitted. However, because our maximum receive window is only 65,535 bytes, host A must stop transmitting once this number has been reached and wait for an acknowledgment from host B. (For the sake of simplicity, our example calculations do not factor in overhead from TCP and lower-layer headers.) This delay wastes potential throughput, unnecessarily inflating the time it takes to reliably transfer data across the network. TCP window scaling was created to address this problem.
举例来说,让我们假设两台主机A、B之间用延迟80ms,带宽为10M的专线物理连接,他们之间用TCP建立连接,两边都有最大值为65535的TCP窗口(因为TCP报头中window size是16位,2的16次方就是65535),我们能够通过 “ 带宽 * 延迟 ” 的公式计算出某一时间点在一个方向上传输的潜在数据量:
10Mbps连接的带宽:也就是10,000,000 bps,除以8,将单位由bps换算成Bps,换算成Byte是因为byte(字节)一般做容量,bit(比特、位)一般用作速率(1B=8b、1B/s=8b/s或1Bps=8bps),然后乘以延迟0.08s(1ms = 0.001s,80ms=0.08s),等于100,000bytes。
也就是说在主机B收到第一个数据前,主机A会发送100,000字节的数据。但是因为我们接收的TCP最大窗口值为65535字节,所以主机A发送了65535字节的数据后必须停下来等待主机B发送ACK表示数据成功接收,因为 “window size” 这个字段的含义就是接收端告诉发送端自己还有多少缓冲区可以接收数据,发送端会按照这个值去发送数据,等对端确认接收了再继续发送余下的数据。(为了简单起见,我们这个例子的计算不考虑TCP报头以及其他报头的开销)。这种延迟浪费了潜在的吞吐量,不必要地增加了跨网络可靠传输数据所需的时间,将最大窗口限制在65535对所谓的“大而胖的网络”(那些有大带宽延迟产品)的性能有显著的损害。TCP窗口缩放就是为了解决这个问题而产生的。
滑动窗口
Window scaling was introduced in RFC 1072 and refined in RFC 1323. Essentially, window scaling simply extends the 16-bit window field to 32 bits in length. Of course, the engineers could not simply insert an extra 16 bits into the TCP header, which would have rendered it completely incompatible with existing implementations. The solution was to define a TCP option to specify a count by which the TCP header field should be bitwise shifted to produce a larger value.
滑动窗口由RFC 1072 引入,并在RFC 1323 中进行了改进。本质上,只是简单的将“window size”这个参数从16位的窗口字段扩展为32位。当然,工程师们不是简单的将新增加的16位插入TCP报头,如果简单的将新增加的16位字段插入报头中,TCP的新报头和之前的报头将不同,导致无法互相兼容。解决办法是在TCP的opinion字段中定义一个数值,TCP报头中的“window size”字段按opinion的该数值移位以产生较大的值。
A count of one shifts the binary value of the field to left by one bit, doubling it. A count of two shifts the value two places to the left, quadrupling it. A count of seven (as shown in the example above) multiplies the value by 128. In this manner, we can multiply the 16-bit header field along an exponential scale to achieve more than sufficiently high values. Of course, this causes us to lose granularity as we scale (we can only increase or decrease the window size in intervals of 2n where n is our scale), but that isn’t much of a concern when dealing with such large windows.
当值为1时,会将“window size”字段的二进制值向左移一位,也就是将“window size”的值加倍。 当值为2时,将值向左移动两位,也就是将“window size”的值扩大4倍。 一个7的计数(如下面的示例所示)将该值乘以128。以这种方式,我们可以将16位opinion的字段沿指数范围相乘,以获得更多的足够高的值。 当然,这会导致我们在缩放时失去粒度(我们只能以2的n次方为间隔增加或减小窗口大小,其中_n_是我们的缩放比例),但是在处理如此大的窗口时,这并不是什么大问题。
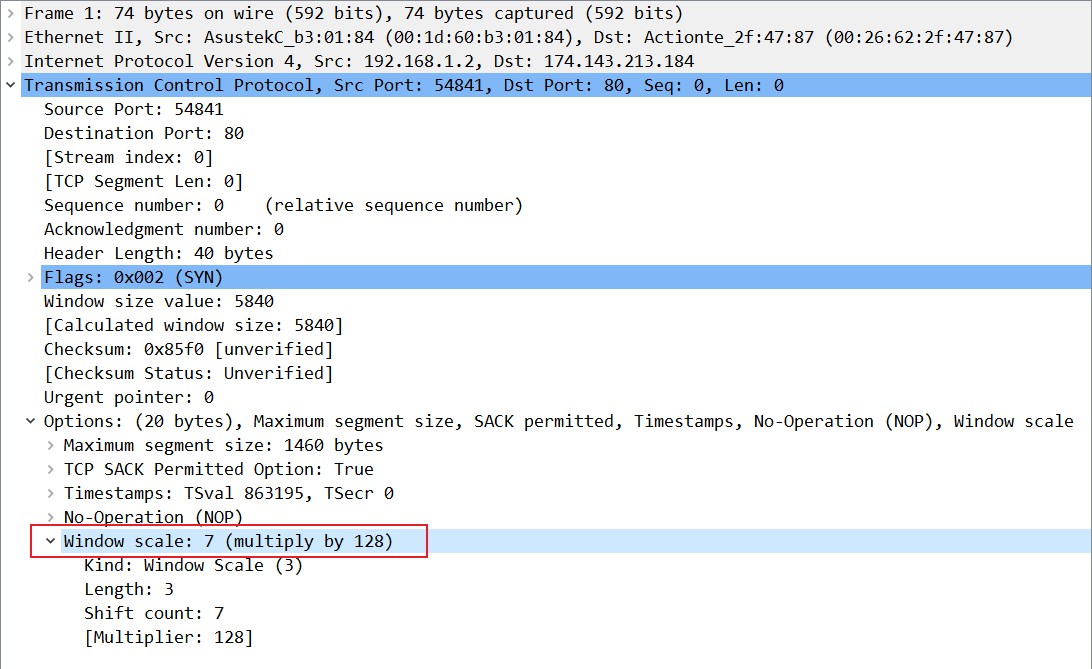
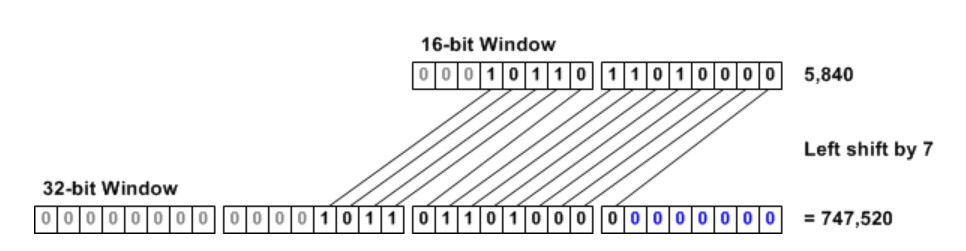
The window scaling option may be sent only once during a connection by each host, in its SYN packet. The window size can be dynamically adjusted by modifying the value of the window field in the TCP header, but the scale multiplier remains static for the duration of the TCP connection. Scaling is only in effect if both ends include the option; if only one end of the connection supports window scaling, it will not be enabled in either direction. The maximum valid scale value is 14 (section 2.3 of RFC 1323 provides some background on this caveat for those interested).
在TCP三次握手建立连接期间,窗口缩放选项只在其SYN数据包中发送一次。 可以通过修改TCP标头中的窗口字段的值来动态调整窗口大小,但是比例乘数在TCP连接期间保持不变。 仅当两端都包含该选项时,缩放才有效; 如果仅连接的一端支持窗口缩放,则两端都不会启用该参数。 最大有效比例值是14(有进一步研究兴趣的请查阅RFC 1323的2.3节)。
Revisiting our earlier example, we can observe how window scaling allows us to make much more efficient use of long fat networks. To calculate our ideal window, we double the end-to-end delay to find the round trip time, and multiple it by the available bandwidth: 2 * 0.08 seconds * 10,000,000 bps / 8 = 200,000 bytes. To support a window of this size, host B could set its window size to 3,125 with a scale value of 6 (3,125 left shifted by 6 equals 200,000). Fortunately, these calculations are all handled automatically by modern TCP/IP stack implementations.
回头看我们之前举的例子,我们可以看到,滑动窗口是如何让我们能更有效的利用“长且胖”(long fat networks)网络的。为了计算我们所需要的理想窗口大小,我们将“端到端延迟”加倍,就能得到“往返时间”(RTT),将这个往返时间(RTT)乘以现有的带宽:2 X 0.08s X 10,000,000 bps / 8 = 200,000 bytes。为了能支持200,000 bytes大小的理想window size,主机B将它的window size 设置成3125(小于window size最大值的65535),然后将缩放比例值(也就是window scale)设置为6,(3125 X 2的6次方等于200,000),幸运的是,这些计算都自动的被近代的TCP\IP协议栈所处理好了。
关于“长且胖”的网络和RTT
The term, long fat network (LFN), which are “long” in terms of distance and network delay and “fat” in terms of link bandwidth.
“长且胖”网络是从英文:Long Fat Network翻译过来的,简称LFN,“Long”表示传输距离,“Fat”表示链路带宽。
RTT表示来回通信延迟(Round-trip delay time),在通信(Communication)、电脑网络(Computer network)领域中,意指:在双方通信中,发讯方的信号(Signal)传播(Propagation)到收讯方的时间(意即:传播延迟(Propagation delay)),加上收讯方回传消息到发讯方的时间(如果没有造成双向传播速率差异的因素,此时间与发讯方将信号传播到收讯方的时间一样久)
关于 “ 带宽 * 延迟 ” 的公式
在文章中,一共有两个“ 带宽 * 延迟 ” ,一开始是由带宽乘以单向通信延迟,后面是由带宽乘以来回通信延迟(RTT)。
前面的带宽乘以单向通信延迟,是为说明65535作为window size 过小,已经影响了TCP传输效率。这里可以把主机A和主机B的通信想象成两台主机通过一根管子(网络)连接,我们要计算它的体积,通过其“宽度”(它的带宽,这更像它的横截面积,以比特每秒为单位)乘以“长度”(单向延迟,以秒为单位),得出来的值等同在任何特定时间该网络线路上的最大数据量——已发送但尚未确认的数据。因为这个计算出来的值是100,000 bytes,远远大于65,535 bytes这个window size的值,没有最大限度的利用网络带宽,最理想的状态是当A发送第1个字节到达B的时候,A刚好停止发送数据,等待ACK,所以后面要加入window scale这个参数把window size扩大到32位、4294967296,更好的利用网络。
后面由带宽乘以来回通信延迟(RTT)这个公式,就是带宽时延乘积(英语:bandwidth-delay product,简写为BDP;或称带宽延时乘积、带宽延时积等),网络速率越高、延迟越大的情况下,计算出来的BDP越大,在这种情况下,TCP的性能难以发挥。
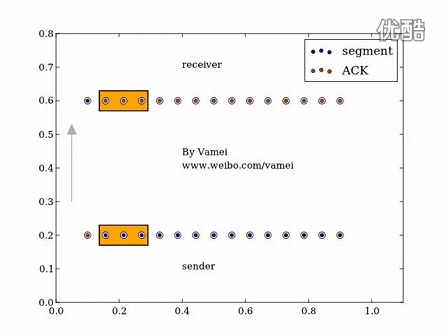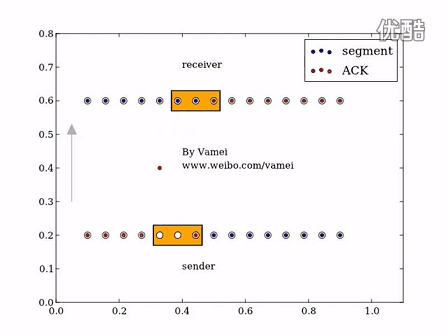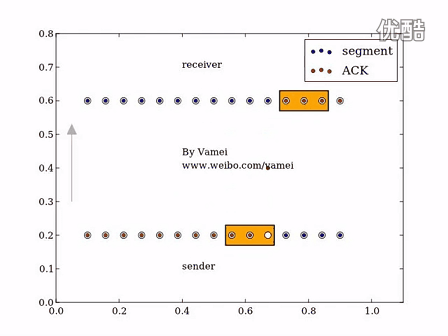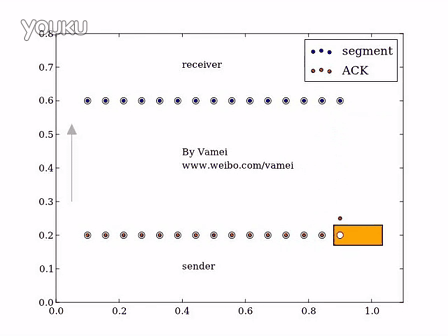
滑动窗口的工作机制演示:
TCP的重传机制
When the TCP transmits a segment containing data, it puts a copy on a retransmission queue and starts a timer; when the acknowledgment for that data is received, the segment is deleted from the queue. If the acknowledgment is not received before the timer runs out, the segment is retransmitted.
当TCP传输包含数据的段时,它将该数据段的副本放在重传队列上并启动计时器。如果在计时器计时结束之前,收到该数据的ACK,则将该数据段的副本从重传队列中删除,然后继续移动窗口,发送接下来的TCP片段。 如果在计时器用尽之前未收到确认,则重新发送该段。这个计时等待的时间叫做重新发送超时时间(RTO, retransmission timeout)。
注意,如果是发送端的数据到达了接收端,但接收端的ACK包没到发送端的情况下,也还是会重传数据。
数据被重发之后若还是收不到确认应答,则进行再次发送。此时,等待确认应答的时间将会以2倍、4倍的指数函数延长。此外,数据也不会被无限、反复地重发。达到一定重发次数之后,如果仍没有任何确认应答返回,就会判断为网络或对端主机发生了异常,强制关闭连接。并且通知应用通信异常强行终止。
除了上面的RTO,还有一个名词叫RTT,RTT,Round-trip delay time,来回通信延迟,就是在双方通信中,发讯方的信号传播到收讯方的时间,加上收讯方回传消息到发讯方的时间,要注意两者的区别。
需要注意的是,网络是一直波动的, RTT 是一直变化的, RTO 的值基于上次 RTT 往返时间动态计算出来的而不是一成不变的。
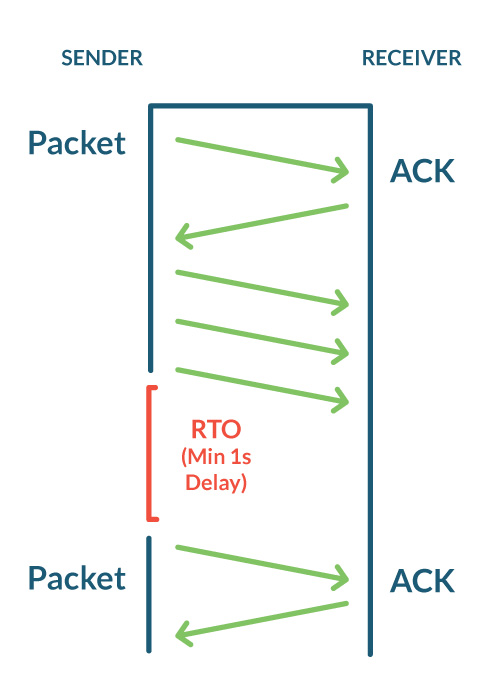
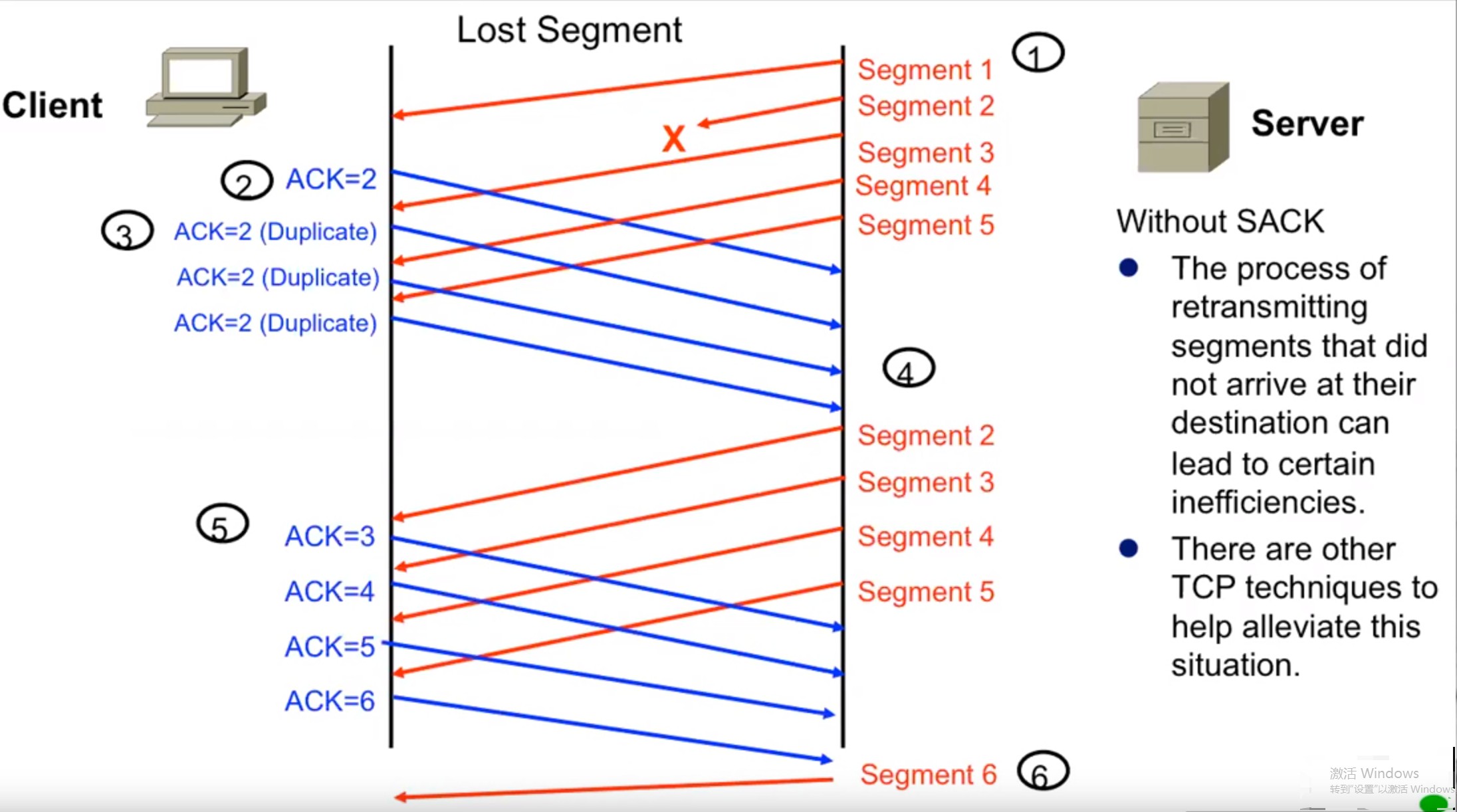
例如上图中,client没收到server发送的segment2 ,所以会一直发送ACK2用来请求seq为2的数据,请注意,这里client收到了其他的比如segment 5,但client是不会发送ACK6的,因为它没收到seq2的数据,并且TCP ACK 的语义是当前数据段前的全部数据段都已经被接收和处理,所以接收方无法发送 ACK 消息,由于发送方没有收到 ACK,所有数据段对应的计时器就会超时并重新传输数据。
server一直收到ACK=2的数据,说明client只确认收到了seq=1的数据,所以在计时完成(RTO),认为client没收到数据以后,server从seq=2的数据重新开始发送。
TCP的慢启动
定义和作用:
TCP slow start is an algorithm which balances the speed of a network connection. Slow start gradually increases the amount of data transmitted until it finds the network’s maximum carrying capacity.
TCP慢启动是一种用来平衡网络连接速度的算法,慢启动渐渐增加传输的数量直到发现网络最大负载能力为止。
Slow start prevents a network from becoming congested by regulating the amount of data that’s sent over it. It negotiates the connection between a sender and receiver by defining the amount of data that can be transmitted with each packet, and slowly increases the amount of data until the network’s capacity is reached. This ensures that as much data is transmitted as possible without clogging the network.
慢速启动可以通过调节网络上发送的数据量来防止网络拥塞。 它通过定义每个数据包可以传输的数据量来协商发送方和接收方之间的连接,并缓慢增加数据量,直到达到网络容量为止。 这样可以确保在不阻塞网络的情况下传输尽可能多的数据。
工作机制:
慢启动(Slow-start)是用于结合其他阶段算法,来避免发送过多数据到网络中而导致网络拥塞,算法在RFC 5681中定义。慢开始算法的思路就是,不要一开始就发送大量的数据,先探测一下网络的拥塞程度,也就是说由小到大逐渐增加拥塞窗口的大小。
慢启动初始启动时设置拥塞窗口值(cwnd)为1、2、4或10个MSS。拥塞窗口在每接收到一个ACK时增加,每个RTT(RTT,Round-trip delay time,来回通信延迟,就是在双方通信中,发讯方的信号传播到收讯方的时间,加上收讯方回传消息到发讯方的时间)内成倍增加,当然实际上并不完全是指数增长,因为接收方会延迟发送确认,通常是每接收两个分段则发送一次确认包。发送速率随着慢启动的进行而增加,直到遇到出现丢失、达到慢启动阈值(ssthresh)、或者接收方的接收窗口进行限制。如果数据发生丢失(发送端发现有个ACK一直没来,一直重传然后超过重传次数的threshold,就认为丢包了),则TCP推断网络出现了拥塞,会试图采取措施来降低网络负载。这些是靠具体使用的TCP拥塞算法来进行测量判断。当达到慢启动阈值(ssthresh)时,慢启动算法就会转换为线性增长的阶段,算法控制每个RTT内拥塞窗口只增加1个分段量。虽然称为“慢启动”,但实际上比拥塞控制阶段的窗口增加更为激进。
关于CWND、slow start与congestion avoidance 之间的切换
Understanding Throughput and TCP Windows
TCP拥塞的出现
当接口必须传输超出其处理能力的更多数据时,就会发生拥塞。传统的体现是当它的队列将达到限制,尾部的帧会被丢掉,也就是把缓存之外收到的数据丢弃掉,表示我的缓存已经满了,没法处理再多的数据了。当然这么做肯定有很多弊端,所以出现了拥塞避免机制,具体的见下文。
TCP拥塞避免
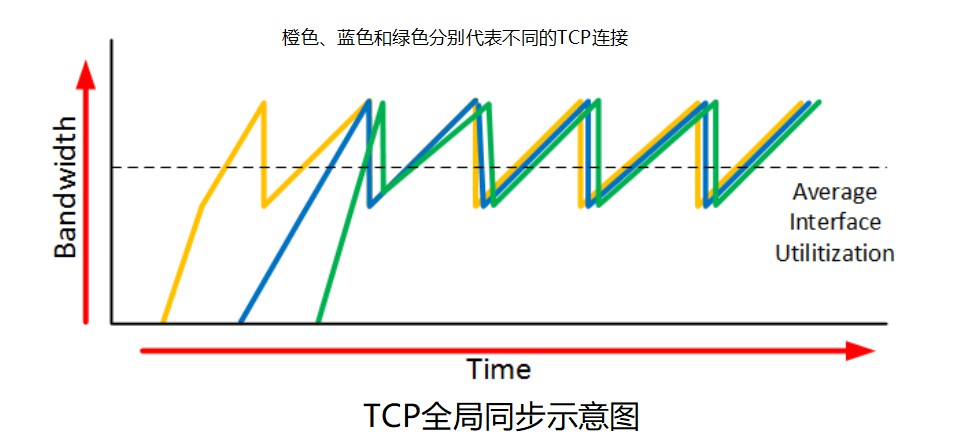
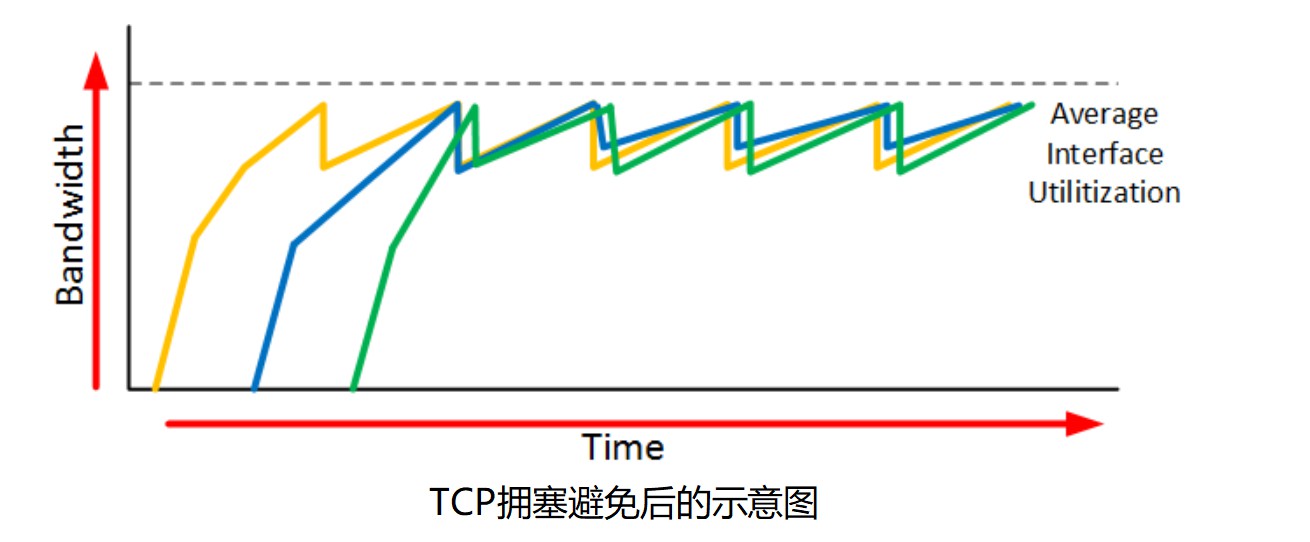
传统的做法是,如果接收方的缓存满了,就把尾部的帧丢弃,也就是丢弃了缓存外的数据,用来表示我的缓存已经满了,没法处理再多的数据了。发送方通过接收方的ACK发现,发送给对方1000个数据,可能只确认了200个,而且window size字段数字很小,说明接收方缓存已经满了,我得少发数据,因为发送了也处理不过来,等不拥塞了再多发数据。因为网络上用TCP的肯定不止一个程序,众多用TCP的程序发现拥塞以后是这么一个“传输——拥塞——丢尾部帧——等待不拥塞——传输”,大家同时这么干,这个过程就是TCP的全局同步(TCP global synchronization),这样对网络利用效率就很低,因为大家一股脑的在同一时间传输,再一起等待不拥塞,如果这时候再有UDP这种不管是否拥塞都传输的,就会造成TCP饥饿(tcp starvation),所以有了RED ( Random early detection ) 这个技术,大概就是说不丢尾部帧了,而是随机丢一些队列里的帧(这个随机是基于队列中的数据包数量和数据包的TOS标记),因为丢的不是同一时刻的数据包,所以不会造成TCP上面那些同步的情况,因为造成TCP全局同步需要在同一时间传输,同一时间等待,而因为RED的丢包是随机丢的,并不是同一时刻的包,所以不会造成TCP全局同步。但问题是还是需要丢包,会某些应用造成性能损伤,因为TCP的重传和慢启动机制,这时候ECN就横空出世,大概过程是一开始通过ECN字段为ECT(0),也就是这两位置10,来协商ECN这个字段,两边都支持协商好以后,当队列快要满的时候,网络设备给数据包mark CE bit(ECN=11),然后接收端看到数据包ECN=11 就知道路上有拥塞了,然后下一个TCP返回的报文就TCP flag ECE(ecn echo)=1,告诉发送端:我这检测到拥塞了,你慢点发,然后发送端收到这个TCP包之后,看到ECE=1,就调小发送速率,并且CWR=1,相当于ECE的确认。具体实现过程请参照后面IP报头部分的“服务类型”章节。为了改善RED的这个问题,衍生出来了其他的RED,比如最常用的WRED,是给数据设置优先级,每个优先级丢包的概率不同,优先级低的数据被丢的概率高,优先级高的数据被丢的概率低;除了最常用的WRED还有ARED,RRED等其他方式,就不展开说了,因为使用率不高我也没看,不会说什么,囧~
TCP全局同步的示意图:
加入RED之后的TCP拥塞避免示意图:
TCP快速重传(Fast Retransmit/Fast Recovery)
The TCP sender SHOULD use the “fast retransmit” algorithm to detect and repair loss, based on incoming duplicate ACKs. The fastretransmit algorithm uses the arrival of 3 duplicate ACKs (4 identical ACKs without the arrival of any other intervening packets) as an indication that a segment has been lost. After receiving 3duplicate ACKs, TCP performs a retransmission of what appears to be the missing segment, without waiting for the retransmission timer toexpire.
TCP的发送方应该基于收到的重复ACK数据,利用快速重传算法检测并修复丢失的数据。快速重传算法使用3个重复ACK数据的到来(也就是4个相同且中间没有其他数据ACK干预的ACK,为什么这里是4个相同的ACK,而前面是3个重复的ACK呢,是因为第一个ACK不是重复的,后面3个一样的才是重复的)作为丢包的标志。收到3个重复的ACK包后,TCP不用等待重传计时器超时,立刻对丢失的数据段进行重传。
After the fast retransmit algorithm sends what appears to be the missing segment, the “fast recovery” algorithm governs the transmission of new data until a non-duplicate ACK arrives. The reason for not performing slow start is that the receipt of the duplicate ACKs not only indicates that a segment has been lost, but also that segments are most likely leaving the network (although a massive segment duplication by the network can invalidate this conclusion). In other words, since the receiver can only generate a duplicate ACK when a segment has arrived, that segment has left the network and is in the receiver’s buffer, so we know it is no longer consuming network resources. Furthermore, since the ACK “clock” is preserved, the TCP sender can continue to transmit new segments (although transmission must continue using a reduced cwnd)
当快速重传算法发送了看似丢失的数据段后,“快速恢复”算法控制着新数据的传输,直到收到不重复的ACK为止。之所以不用慢启动是因为在这种情况下,重复的ACK不仅代表着数据段丢失,而且同时代表着这些数据段很可能离开了网络(尽管网络进行的大量段复制可能会使此结论无效),换句话说,因为接收方只能在数据段到达时产生重复的ACK,那个数据段已经不在网络上传输而是在接收方的缓存中了,所以并不消耗网络资源。此外,由于ACK的“时钟”被保留,所以TCP的发送方可以持续发送新的数据段(尽管网络必须使用缩小的CWND来传输)。
RFC中还有一个快速重传的步骤,因为快速重传已经被SACK(Selective Acknowledgments)所取代(The algorithm outlined in this document, heavily based on the algorithm detailed in [FF96], is aconservative replacement of the fast recovery algorithm –rfc3517),所以在这就不摘录翻译剩下的部分了。
TCP SACK
在TCP传输过程中,没有快速重传的情况下,如果一个传输数据被分成5个数据段发送,当其中一个数据段丢失时,假设数据段2丢失了其他数据段都收到了,接收者会发送一个ACK=2的数据告诉发送端,我只收到了数据段1,但无法告诉发送端我收到了数据段3-5,并且接收端也不能发送一个ACK=6或者其他不是2的数据,因为如果发送了ACK=6表示希望发送端下发送Sequence=6的数据,ACK表示的是希望下一个收到的报文段的序列号,接收端并没有收到数据段2所以不能发送除了ACK=2的其他的ACK信息,但此时接收端只需要数据段2就行了,其他的数据段重新传输完全是浪费网络资源并降低传输效率,所以SACK(Selective Acknowledgment)出现了,SACK可以告诉发送端哪些数据段我收到了,哪些我没有收到。SACK的能力也需要两端在TCP建立连接时进行协商,在两边都支持的情况下才能使用。
理论步骤分析:
Step 1
Response segment #2 is lost.
Step 2
The client realizes it is missing a segment between segments #1 and #3. It sends a duplicate acknowledgment for segment #1, and attaches a SACK option indicating that it has received segment #3.
Step 3
The client receives segment #4 and sends another duplicate acknowledgment for segment #1, but this time expands the SACK option to show that it has received segments #3 through #4.
Step 4
The server receives the client’s duplicate ACK for segment #1 and SACK for segment #3 (both in the same TCP packet). From this, the server deduces that the client is missing segment #2, so segment #2 is retransmitted. The next SACK received by the server indicates that the client has also received segment #4 successfully, so no more segments need to be transmitted.
Step 5
The client receives segment #2 and sends an acknowledgment to indicate that it has received all data up to an including segment #4.
步骤1:服务器发往接收端的Segment 2丢失。
步骤2:服务器继续发送数据段3被接收端成功接收。接收端通过查看序列号发现,数据段1和3之间丢失了数据段2,接收端发送重复ACK去确认Sequence=1的数据段成功收到并且在opinion中附加了SACK字段表示它收到了数据段3。
步骤3:接收端收到了服务器发送来的数据段4,并且接收端又发送了一个ACK确认数据段1成功接收,但这次扩展的opinion选项字段中的信息表示接收端收到了数据段3和4。
步骤4:服务器端收到了接收端发送的确认数据段1收到重复ACK,这个数据中的SACK字段还表明接收端除了收到数据段1以外还收到了数据段3。至此,服务器端已经可以推测出来接收端并未受到数据段2,因此重新发送数据段2。接收到后一个SACK后发现接收端也收到了数据段4,因此没有其他需要重新传送的数据段了。
步骤5:接收端收到了重新发送的数据段2并且发送了确认收到数据段1-4的ACK信息。
抓包分析:
TCP在三次握手的前两个数据交互的时候就已经决定了这个TCP连接是否支持SACK属性,SACK在opinion字段中。
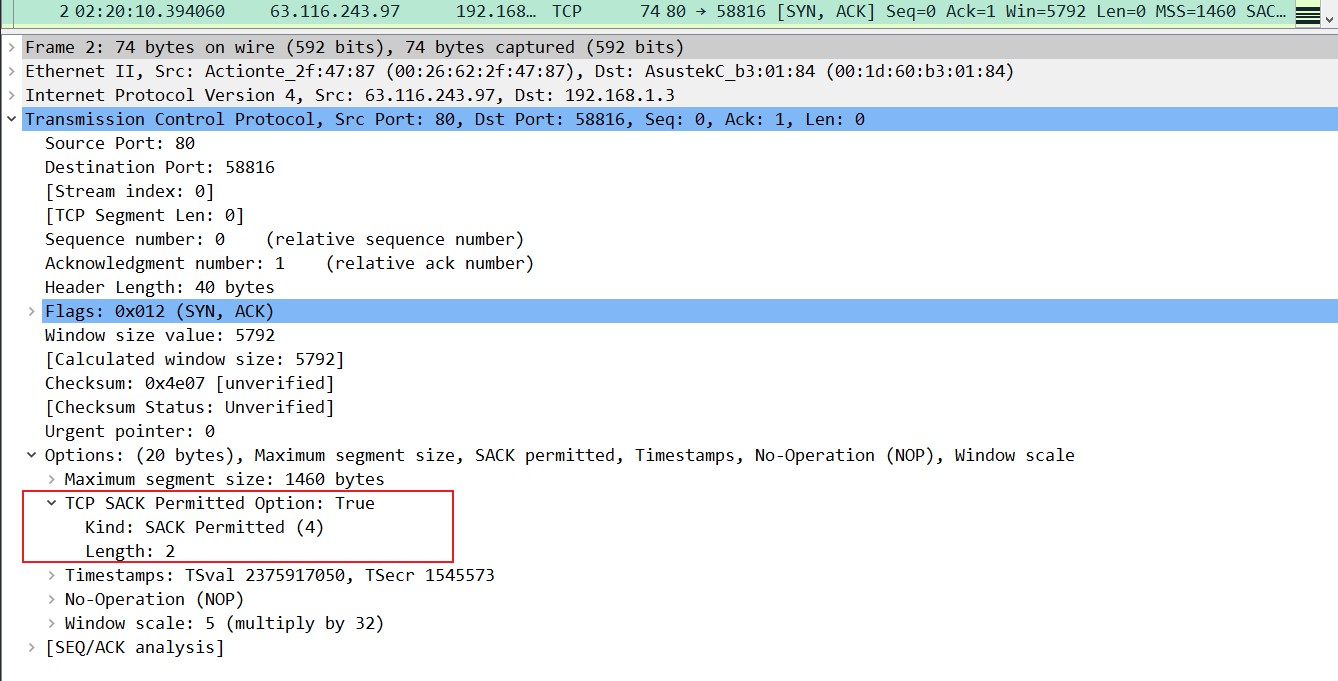
从第28个抓包中我们可以看到,这个ACK期待的下一个收到的序列号是17737:
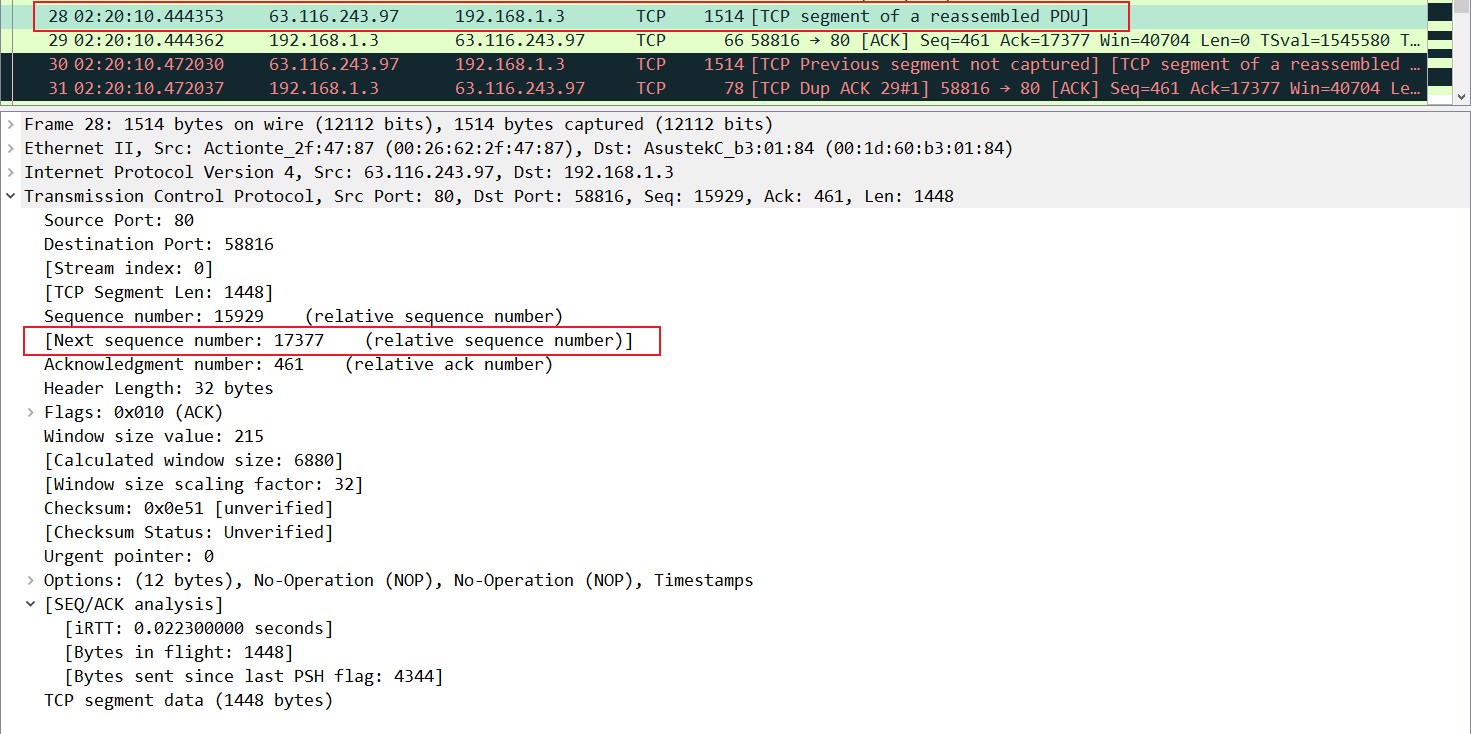
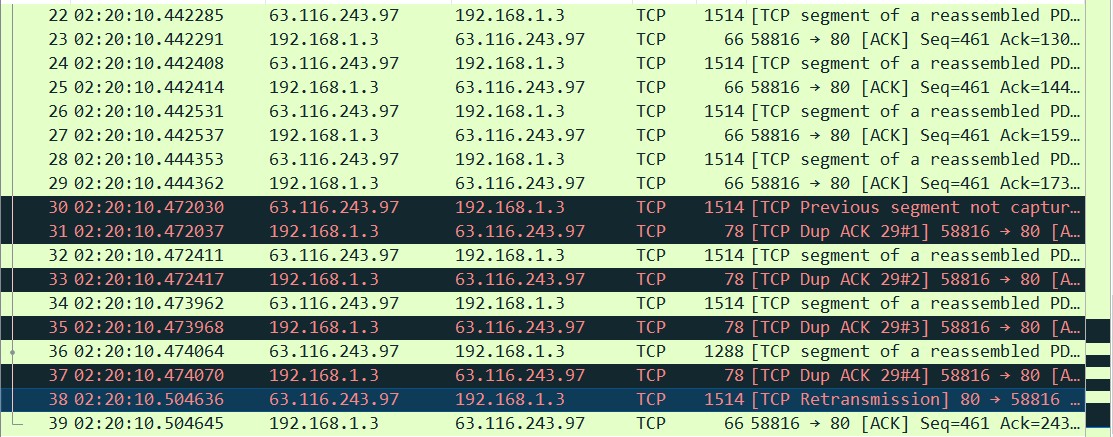
从第三十个抓包中我们可以看到,这个数据包是乱序的,因为前面收到的ACK表明下一个期待的数据序列号应为17377,而第三十个抓包中的序列号是18825,和之前ACK期待的不一样,所以是个乱序包。
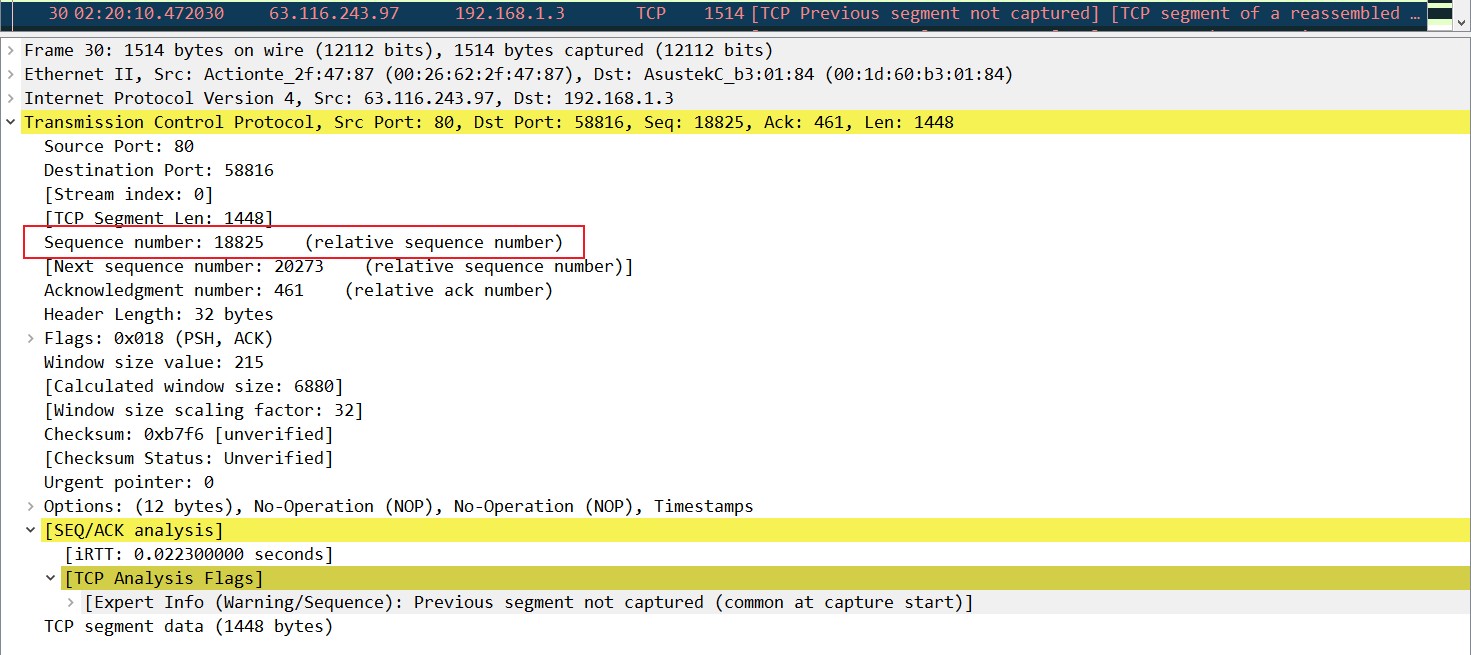
当收到乱序包以后,接收端用抓包31发送了重复的ACK,这个包中的opinion字段中有SACK部分,用来告诉发送端数据包30我收到了。当然这个SACK字段不可能简单的标明哪个数据段我收到了,而是标识出那些在数据包的确认号之外的数据的左右两边。从ACK17377到left edge18825之间的是没收到的,只传序列号17377-18825之间的数据段即可,而left edge18825到right edge20273这部分也是收到的,不用重新进行传递。
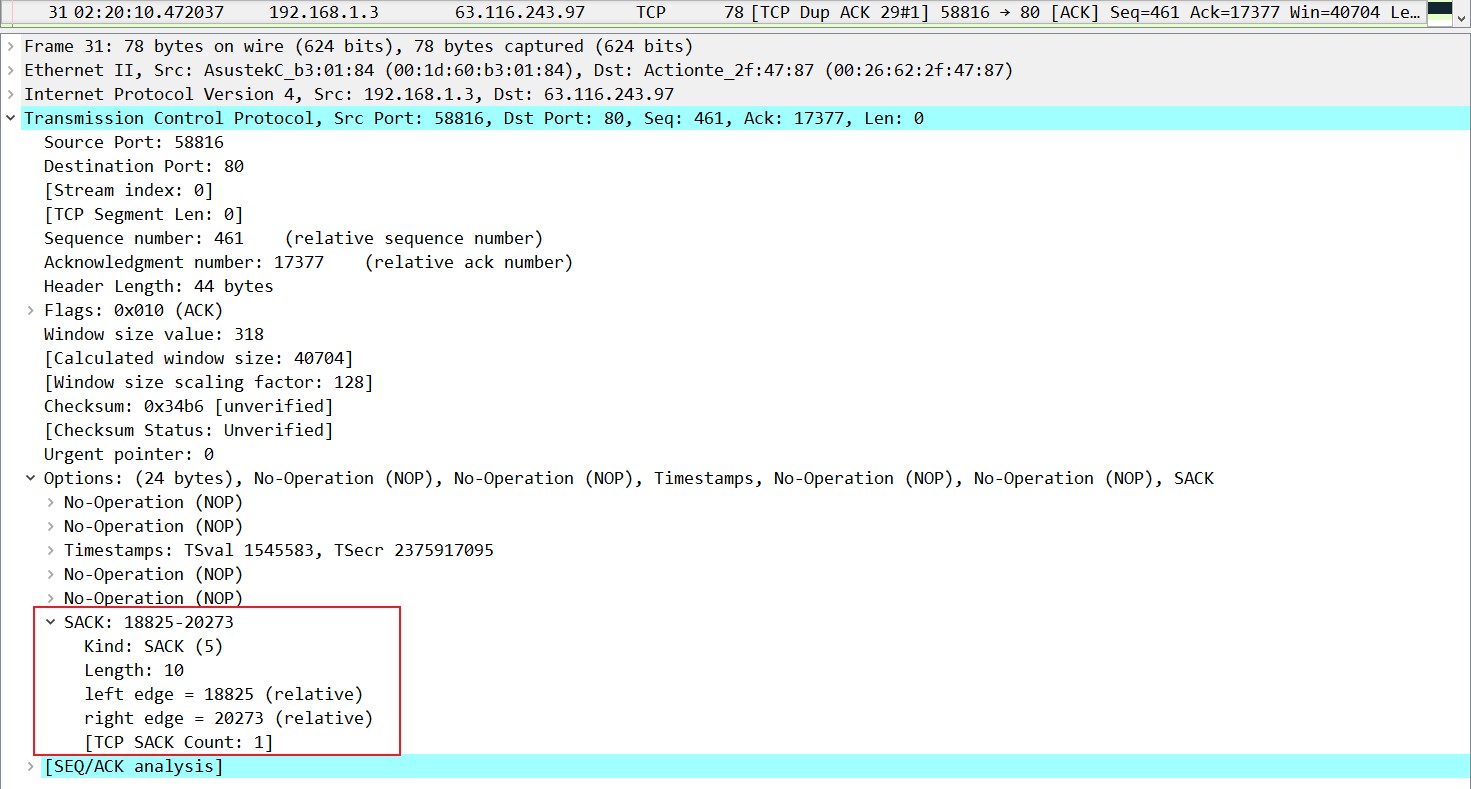
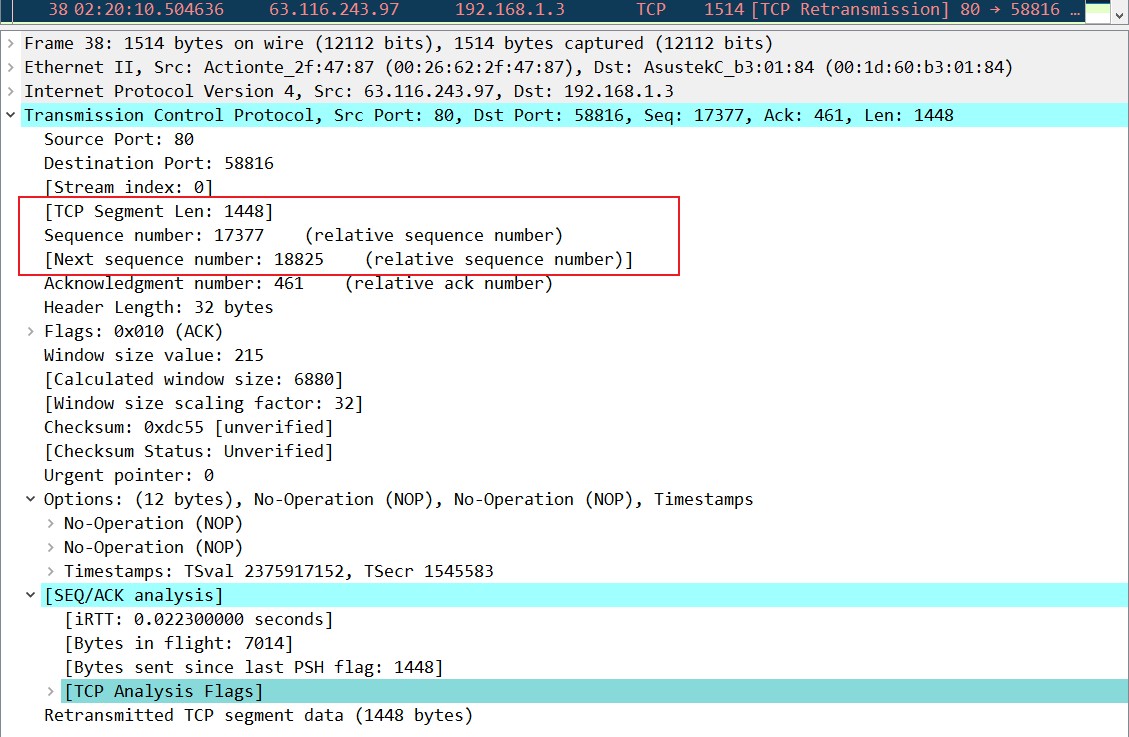
除了抓包31这个ACK以外,在抓包33、35、37也发送了同样的重复ACK,duplicate ACK,告诉发送端序列号17377-18825我没收到,于是发送端在抓包38的时候重新发送了序列号17377-18825的这些数据:
如果在TCP传输过程中,丢了好几个包,比如收到了序列号为0-500,900-1100和1300-2000的数据段,这时候SACK能否告诉发送端中间丢了好几段数据呢?当然可以,中间可以分几段来表示丢失的不同部分:
1 | +--------+--------+ |
1 | TCP ACK - 501 (in TCP header, not in SACK Option) |
TCP协议存在的问题及解决
TCP性能上存在的问题:
TCP 选择了充分利用带宽,为流量而设计,期望在尽可能短的时间内传输更多的数据,但这种设计会存在一些负面因素,例如TCP超时计算是RTOx2,这样连续丢三次包就变成RTOx8了,十分恐怖;例如TCP丢包时会全部重传从丢的那个包开始以后的数据;例如TCP为了充分利用带宽,延迟发送ACK(NODELAY都没用),这样超时计算会算出较大 RTT时间,延长了丢包时的判断过程;弱网环境是丢包率较高的特殊场景,TCP 在类似场景中的表现很差,当 RTT 为 30ms 时,一旦丢包率达到了 2%,TCP 的吞吐量就会下降 89.9%7,从下面的表中我们可以看出丢包对 TCP 的吞吐量极其显著的影响:

影响TCP性能的三个原因:
- TCP 的拥塞控制算法会在丢包时主动降低吞吐量;
- TCP 的三次握手增加了数据传输的延迟和额外开销;
- TCP 的累计应答机制导致了数据段的传输;
上边的这三个原因中,拥塞控制算法是导致 TCP 在弱网环境下有着较差表现的首要原因,三次握手和累计应答两者的影响依次递减,但是也加剧了 TCP 的性能问题。
目前解决的方法:
- 使用 UDP 构建性能更加优异、更灵活的传输协议,例如:QUIC 等;
- 通过不同的手段优化 TCP 协议的性能,例如:选择性 ACK(Selective ACK, SACK),TCP 快开启(TCP Fast Open, TFO)
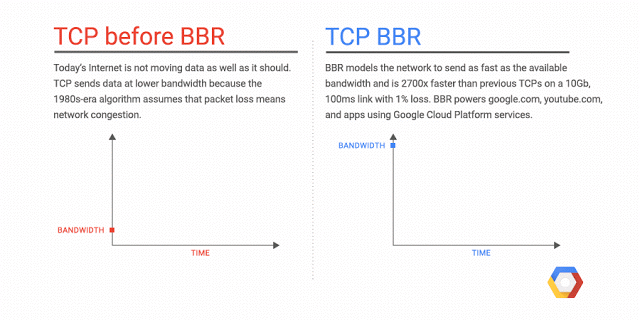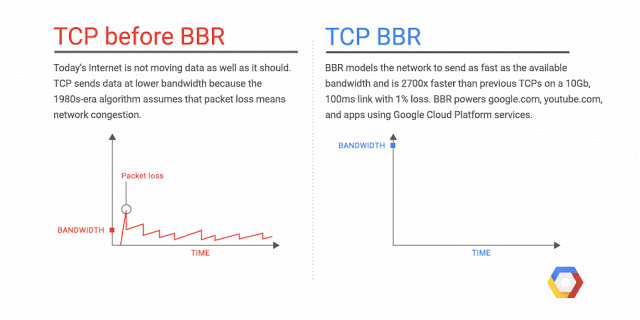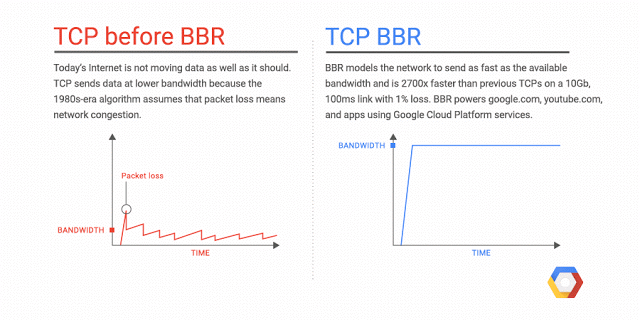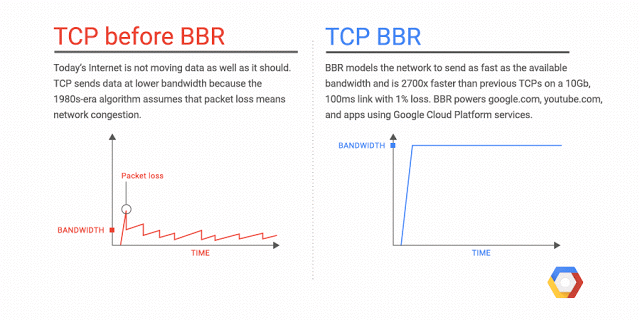
既然TCP的拥塞算法是导致网络表现较差的首要原因,我们就需要改进这个算法,其中一种算法就是基于不丢包的拥塞算法,CDG(CAIA-Delay Gradient),该算法以 延迟 作为判断依据,延迟增大说明拥塞, 数据开始在路由器的缓冲中积累. 降低发送 窗口。然而 CDG 算法与基于丢包的算法不兼容, 只有全球的设备都换上 CDG,但这是不可能的,目前市面上的设备不可能一下子都切换到 CDG,因此 Google 就不开心了,Google 的科学家们开发了一种过渡算法来解决这个问题,这个算法的名字就是 BBR(Bottleneck Bandwidth and RTT),它是一种全新的 拥塞控制算法,BBR 同 CDG 一致的思想是不以丢包作为拥塞控制信号,但是和 CDG 不同的是,BBR 能和 cubic 和 reno 共存。
BBR 由 Google 开发,供 Linux 内核的 TCP 协议栈使用,有了 BBR 算法,Linux 服务器可以显著提高吞吐量并减少连接延迟,简单来说 BBR 能加速网络传输速度。此外,部署 BBR 也很容易,因为该算法只需要发送方,而不需要网络或接收方的支持。
UDP
UDP的特点:
UDP是一种无连接的、不可靠的、面向报文、没有拥塞控制的协议。
无连接的:和TCP要建立连接不同,UDP传输数据不需要建立连接,就像写信,在信封写上收信人名称、地址就可以交给邮局发送了,至于能不能送到,就要看邮局的送信能力和送信过程的困难程度了。
不可靠的:因为UDP发出去的数据包发出去就不管了,不管它会不会到达,即使到达不了也不会像TCP那样重传,因为UDP报头很精简,不像TCP报头中有序列号、确认号以及重传机制,能知道哪些数据发送到哪些没法送到,也不会重传那些没发送到的数据,所以很可能会出现丢包现象,使传输的数据出错。
面向报文:数据报文,就相当于一个数据包,应用层交给UDP多大的数据包,UDP就照样发送,不会像TCP那样拆分。
没有拥塞控制:拥塞,是指到达通信子网中某一部分的分组数量过多,使得该部分网络来不及处理,以致引起这部分乃至整个网络性能下降的现象,严重时甚至会导致网络通信业务陷入停顿,即出现死锁现象,就像交通堵塞一样。TCP建立连接后如果发送的数据因为信道质量的原因不能到达目的地,它会不断重发,有可能导致越来越塞,所以需要一个复杂的原理来控制拥塞。而UDP就没有这个烦恼,发出去就不管了。
UDP的应用场景:
UDP通常用于对时间敏感的通信,在这种情况下,偶尔丢弃数据包比等待数据流更好。 语音和视频流量使用此协议发送,因为它们既对时间敏感,又被设计成可处理一定程度的丢失。 例如,许多基于Internet的电话服务使用的VOIP(基于IP的语音)通过UDP运行,在线游戏也通常使用UDP。 同样,由于DNS和NTP服务器都需要快速高效,因此它们通过UDP运行。
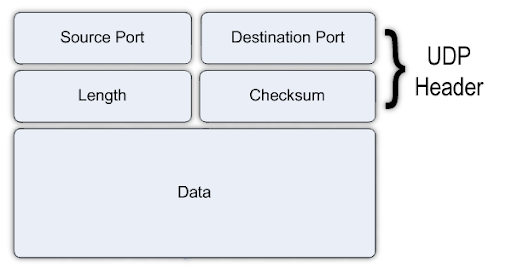
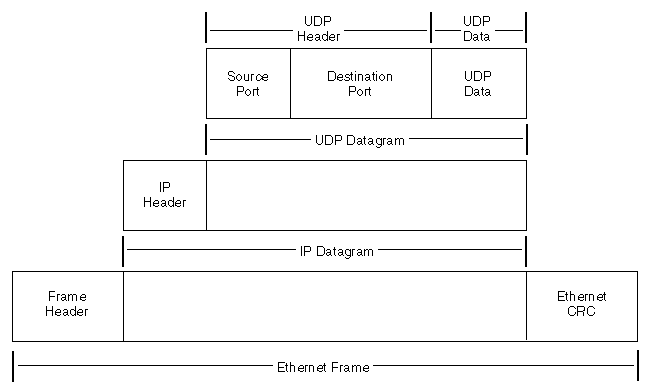
UDP报头
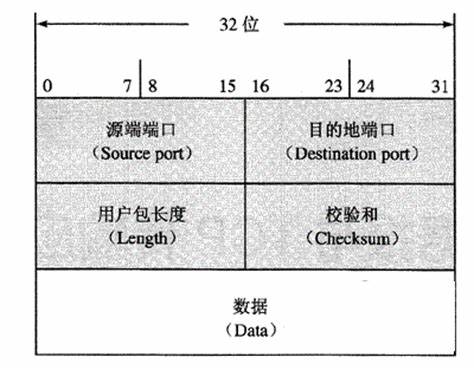
(1)源端口:源端口长度为16位,用于标识源端口号,在需要对方回信时选用,不需要时可全用0。
(2)目的端口:目的端口号长度为16位,用于标识目的地数据包的端口。
(3)长度:UDP用户数据报的长度,其最小值是8(仅有首部)。
(4)校验和:校验UDP用户数据报在传输中是否有错,有错就丢弃。
UDP常见协议:
Multimedia applications, DNS, BOOTP, DHCP, TFTP, SNMP, RIP
TCP VS UDP
TCP用于在传输层有必要实现可靠传输的情况。由于它是面向有连接并具备顺序控制、重发控制等机制的,所以它可以为应用提供可靠传输。例如浏览网页的HTTP服务
UDP主要用于那些对高速传输和实时性有较高要求的通信或广播通信。我们举一个通过IP电话进行通话的例子。如果使用TCP,数据在传送途中如果丢失会被重发,但这样无法流畅地传输通话人的声音,会导致无法进行正常交流。而采用UDP,它不会进行重发处理。从而也就不会有声音大幅度延迟到达的问题。即使有部分数据丢失,也只是会影响某一小部分的通话
网络层(Internet Layer)
网络层总览
TCP/IP的心脏是互联网层。这一层主要由IP(Internet Protocol)、ICMP(Internet Control Message Protocol)等协议组成。IP协议是一个面向无连接的协议,也就是在发送数据包之前不需要与目标地址之间建立连接,上层如果到需要发送给IP的数据,该数据会立即被压缩成IP包发送出去。
为什么IP是无连接协议
主要有两点原因:一是为了简化,二是为了提速。面向连接比起面向无连接处理相对复杂。甚至管理每个连接本身就是一个相当繁琐的事情。此外,每次通信之前都要事先建立连接,又会降低处理速度。需要有连接时,可以委托上一层(比如TCP)提供此项服务。因此,IP为了实现简单化与高速化采用面向无连接的方式。
如何提高可靠性
IP提供尽力服务(Best Effort),意指“为了把数据包发送到最终目标地址,尽最大努力。”然而,它并不做“最终收到与否的验证”。IP数据包在途中可能会发生丢包、错位以及数据量翻倍等问题。如果发送端的数据未能真正发送到对端目标主机会造成严重的问题。例如,发送一封电子邮件,如果邮件内容中很重要的一部分丢失,会让收件方无法及时获取信息。
因此提高通信的可靠性很重要。TCP就提供这种功能。如果说IP只负责将数据发给目标主机,那么TCP则负责保证对端主机确实接收到数据。
那么,有人可能会提出疑问:为什么不让IP具有可靠传输的功能,从而把这两种协议合并到一起呢?
这其中的缘由就在于,如果要一种协议规定所有的功能和作用,那么该协议的具体实施和编程就会变得非常复杂,无法轻易实现。相比之下,按照网络分层,明确定义每层协议的作用和责任以后,针对每层具体的协议进行编程会更加有利于该协议的实现。
网络通信中如果能进行有效分层,就可以明确TCP与IP各自协议的最终目的,也有利于后续对这些协议进行扩展和性能上的优化。分层也简化了每个协议的具体实现。互联网能够发展到今天,与网络通信的分层密不可分。
IPv4议报头
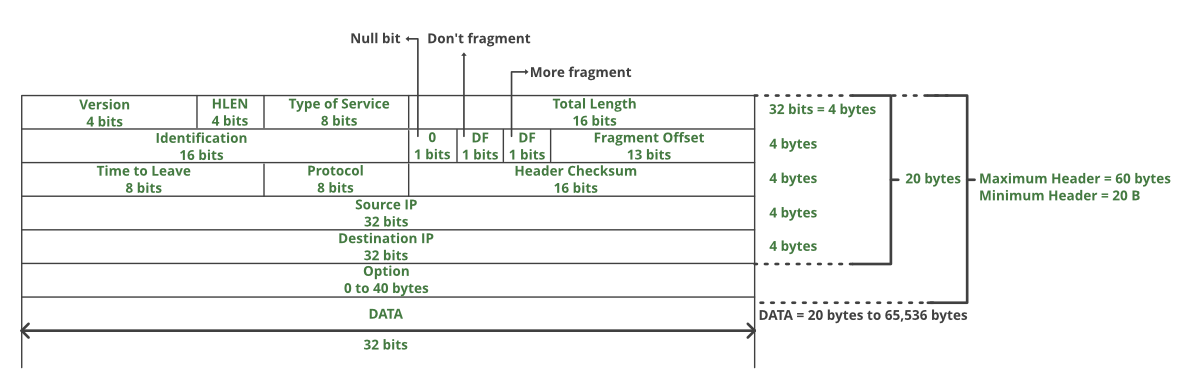
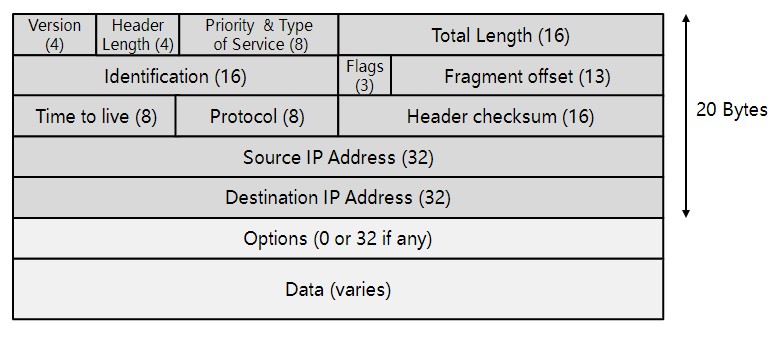
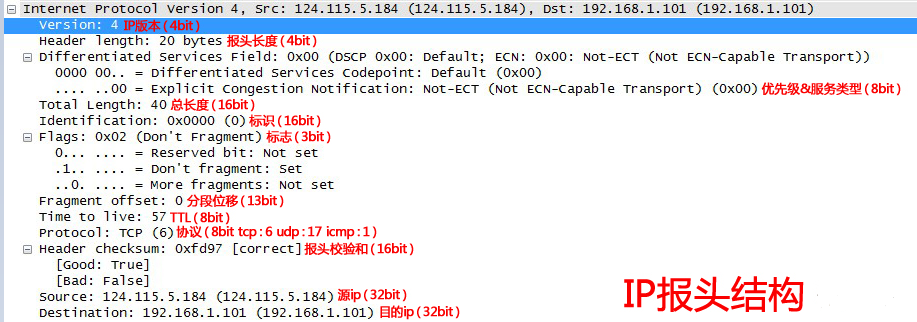
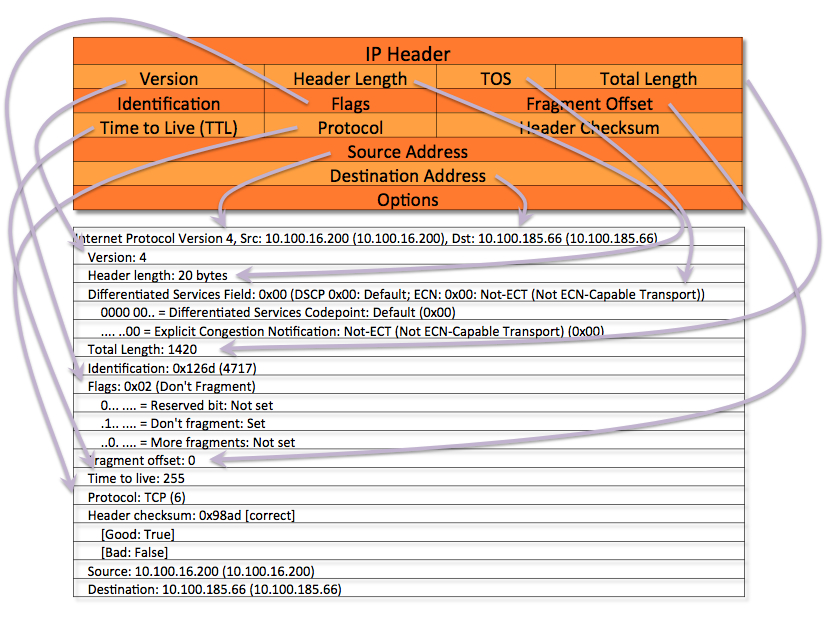
版本号(Version):
长度4比特。标识目前采用的IP协议的版本号。用二进制表示,一般的值为0100(IPv4),IPv6的值(0110),除此之外的版本号现网中已经几乎绝迹了。
如果不知道为什么0100对应IPV4,0110对应IPV6,请看4、基础知识中关于2进制转换的部分,这里简单的说一下计算方法。
二进制转换成十进制的方法:二进制数从低位到高位(即从右往左)计算,第0位的权值是2的0次方,第1位的权值是2的1次方,第2位的权值是2的2次方,依次递增下去,把最后的结果相加的值就是十进制的值了。
2进制的0100换算成10进制就是4,代表IPV4
1. 第0位 0 x 2^0 = 0;
2. 第1位 0 x 2^1 = 0;
3. 第2位 1 x 2^2 = 4;
4. 第3位 0 x 2^3 = 0;
所以2进制的0100换算成10进制是:0+0+4+0=4
2进制的0110换算成10进制就是6,代表IPV6。
1. 第0位 0 x 2^0 = 0;
2. 第1位 1 x 2^1 = 2;
3. 第2位 1 x 2^2 = 4;
4. 第3位 0 x 2^3 = 0;
所以2进制的0110换算成10进制是:0+2+4+0=6
IP包头长度(Header Length):
长度4bit。这个字段的作用是为了描述IP包头的长度,因为在IP包头中有变长的可选(最底下的Options)部分。IP包头最小长度为20字节,由于变长的可选部分最大长度可能会变成60字节,60个字节是header length字段,4bit能描述的最大长度。
服务类型(Type of Service、TOS):
长度8比特,通知沿途路由器包含在数据报中的数据的重要性,从而设置数据报的优先级,只有当网络设备能够支持(能够识别IP首部中的ToS字段)识别ToS字段时,这给字段设置才有意义。否则都是空谈。这个字段虽然在TCP\IP协议栈中被定义了,但一直以来基本没怎么使用过,在近些年被重新定义为Differentiated Services,这个字段又被划分为两部分,DSCP(differentiated services codepoint)和ECN(Explicit Congestion Notification)。
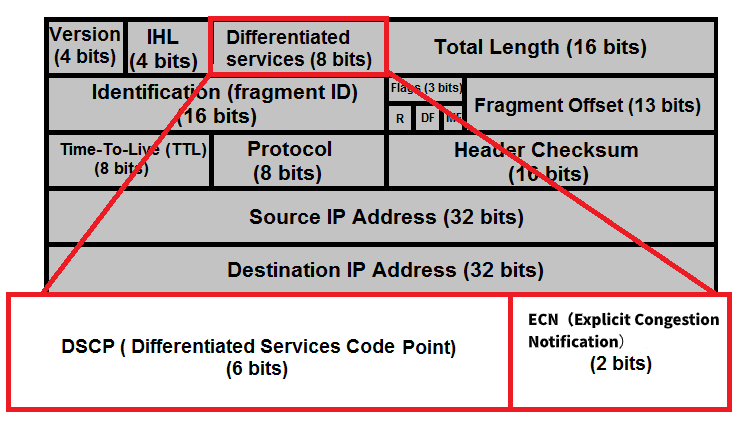
Differentiated services or DiffServ is a computer networking architecture that specifies a simple and scalable mechanism for classifying and managing network traffic and providing quality of service (QoS) on modern IP networks. DiffServ can, for example, be used to provide low-latency to critical network traffic such as voice or streaming media while providing simple best-effort service to non-critical services such as web traffic or file transfers.
DiffServ uses a 6-bit differentiated services code point (DSCP) in the 8-bit differentiated services field (DS field) in the IP header for packet classification purposes. The DS field replaces the outdated IPv4 TOS field.
Explicit Congestion Notification (ECN), is used by some routers to signal support for Explicit Congestion Notification and, when it is supported, the bits can be used to signal congestion (ECN = 11)
区分服务或DiffServ是一种计算机网络体系结构,它指定了一种简单且可扩展的机制,用于对网络流量进行分类和管理,并在现代IP网络上提供服务质量(QoS)。 例如,DiffServ可用于为关键网络流量(例如语音或流媒体)提供低延迟,同时为非关键服务(例如Web流量或文件传输)提供简单的尽力而为服务。
The definition of ToS was changed entirely in RFC 2474, and it is now called Differentiated Service (DS). On the eight fields, the upper six bit contain value called Differentiated Services Code Point (DSCP). The last two bits are used for Explicit Congestion Notification and it is defined in RFC 3168.
ToS的定义在RFC 2474中完全更改,现在称为差异化服务(DS)。 在8个字段上,高6位包含称为差分服务代码点(DSCP)的值。 后两位用于显式拥塞通知,它在RFC 3168中定义。区分服务代码点(DSCP)是一种分类和管理网络流量并在现代第3层IP网络中提供服务质量(QoS)的方法。
DiffServ使用了IP报头里8位差异服务字段(DS字段)中的6位差异服务代码点(DSCP)进行数据包分类。DS字段替换了过时的IPv4 TOS字段。

一些路由器使用显式拥塞通知(ECN)来表示对显式拥塞通知的支持,这是一个2个比特的字段,置00时,表示设备不支持ECN字段,当两边都置为ECT的时候,表示两端设备均支持ECN字段,可以协商这个能力。ECT(1)和ECT(0)均表示支持这个能力,但一般用ECT(0)。置位为11(CE)的时候,表示网络中出现拥塞。
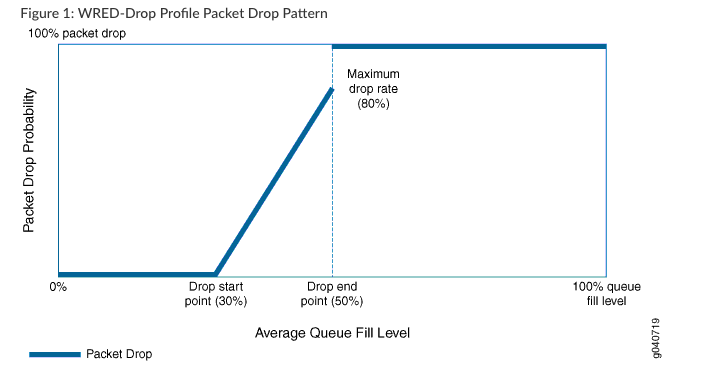
一开始是没有ECN这个字段的,传统的做法是,如果接收方的缓存满了,就把尾部的帧丢弃,也就是丢弃了缓存外的数据,用来表示我的缓存已经满了,没法处理再多的数据了。发送方通过接收方的ACK发现,发送给对方1000个数据,可能只确认了200个,而且window size字段数字很小,说明接收方缓存已经满了,我得少发数据,因为发送了也处理不过来,等不拥塞了再多发数据。因为网络上用TCP的肯定不止一个程序,众多用TCP的程序发现拥塞以后是这么一个“传输——拥塞——丢尾部帧——等待不拥塞——传输”,大家同时这么干,这个过程就是TCP的全局同步(TCP global synchronization),这样对网络利用效率就很低,因为大家一股脑的在同一时间传输,再一起等待不拥塞,如果这时候再有UDP这种不管是否拥塞都传输的,就会造成TCP饥饿(tcp starvation),所以有了RED ( Random early detection ) 这个技术,大概就是说不丢尾部帧了,而是随机丢一些队列里的帧,因为丢的不是同一时刻的数据包,所以不会造成TCP上面那些同步的情况,因为造成TCP全局同步需要在同一时间传输,同一时间等待,而因为RED的丢包是随机丢的,并不是同一时刻的包,所以不会造成TCP全局同步。但问题是还是需要丢包,会某些应用造成性能损伤,因为TCP的重传和慢启动机制,这时候ECN就横空出世,大概过程是一开始通过ECN字段为ECT(0),也就是这两位置10,来协商ECN这个字段,两边都支持协商好以后,当队列快要满的时候,网络设备给数据包mark CE bit(ECN=11),然后接收端看到数据包ECN=11 就知道路上有拥塞了,然后下一个TCP返回的报文就TCP flag ECE(ecn echo)=1,告诉发送端:我这检测到拥塞了,你慢点发,然后发送端收到这个TCP包之后,看到ECE=1,就调小发送速率,并且CWR=1,相当于ECE的确认。更具体的协商工作机制如下:
TCP initiation and process for ECN:
- Host A sends a SYNC packet with ECE and CWR set in TCP options field. ECN bit set to 00 in IP header.
- Host B responds with a SYNC+ACK packet with ECE set in TCP options field. ECN bit set to 00 in IP header.
- After TCP establishes with ECN capable, data start to be transmitted with ECT set(ECN=01/10,same meaning)
- The middle device must enable support ECN on respective queue to enable ECN feature.
- If a middle device detects that the WRED drop probability is greater than 0 in a ECN enabled queue, which means congestion experiencing in this queue. Device will remark the packet with CE(Congestion Experienced, ECN=II), and downstream device must remain it unchanged.
- The receiver gets a packet with CE set, it responds in next ACK with ECE flag set in TCP header
- When sender gets the ACK packet with ECE flag set, it reduces the sending rate and reply with CWR flag set in next packet to ack the ECE set packet.
- When the receiver receives the CWR flag, the receiver stops setting the ECE bit in replies to the sender.
TCP 三次握手时ECN的过程:
1、主机A在TCP三次握手发送第一次SYN时,除了将SYN位置1以外,还将TCP报头里的控制位中的ECE和CWR两个位也置为1;将IP报头中的ECN位设置为00:


2、主机B发送数据相应主机A的TCP三次握手,将TCP报头中控制位里的SYN和ACK两位置为1,将IP报头中ECN两位也置为00。
3、当TCP建立完具有ECN能力的连接后,所传输的数据的IP报头中的ECN位将设置为01或10(表示的含义一样),这两个ECT置为本质上是在IP数据包中的ECN field中放置了一个随机数(The use of two ECT codepoints essentially gives a one-bit ECN noncein packet headers, and routers necessarily “erase” the nonce whenthey set the CE codepoint)。
4、主机AB之间的中间网络设备,必须在相应的队列上启用支持ECN才能启用ECN功能。
5、如果中间设备在启用ECN的队列中检测到WRED丢弃概率大于0,则表示此队列中出现拥塞。 设备将使用CE(表示经历拥塞,ECN = 11)标记该数据包,下游设备必须保持其不变。
6.接收方获得一个带有CE设置的数据包,它在下一个ACK中响应,并在TCP报头中设置了ECE标志
7.当发送方收到设置了ECE标志的ACK数据包时,它将降低发送速率并在下一个数据包中设置CWR标志进行答复,以确认ECE设置数据包。
8.当接收方收到CWR标志时,接收方停止设置ECE位,以回复发送方。
关于ECT的说明:
The use of two ECT codepoints essentially gives a one-bit ECN noncein packet headers, and routers necessarily “erase” the nonce whenthey set the CE codepoint [SCWA99]. For example, routers that erasedthe CE codepoint would face additional difficulty in reconstructingthe original nonce, and thus repeated erasure of the CE codepoint would be more likely to be detected by the end-nodes. The ECN nonce also can address the problem of misbehaving transport receivers lying to the transport sender about whether or not the CE codepoint was setin a packet.
这两个ECT置为本质上是在IP数据包中的ECN field中放置了一个随机数,当路由器将ECN field置为位CE(也就是置位11的时候),会将ECT置位抹去(其实也就是将ECT的10换为CE的11用来表示有拥塞了)。举例来说,如果路由器将CE字段抹去会面临难以恢复ECT置位中的那个随机数的情况(因为抹掉CE置位的路由器也不知道ECT置位的随机数是多少,它收到的只是个CE置位,所以就没法复原那个随机数,所以后面的路由器就会知道这个数据有问题因为没有ECT的随机数或者随机数有问题和之前的不同。这里说的这个抹去CE<11>的动作其实是错误的,因为CE表示有拥塞,不能简单的把这个抹去而不进行相应的动作),并且重复的抹去CE置位会让后面的路由器更容易发现这个问题。ECN随机数还可以解决不管是否在分组中设置CE码点的情况下,传输层接收者欺骗传输层发送者的问题。我理解是说是加上了ECT以后,因为多了一个随机数,如果上游设备对TCP层进行了擅自改变,能够检测出来。
IP包总长(Total Length):
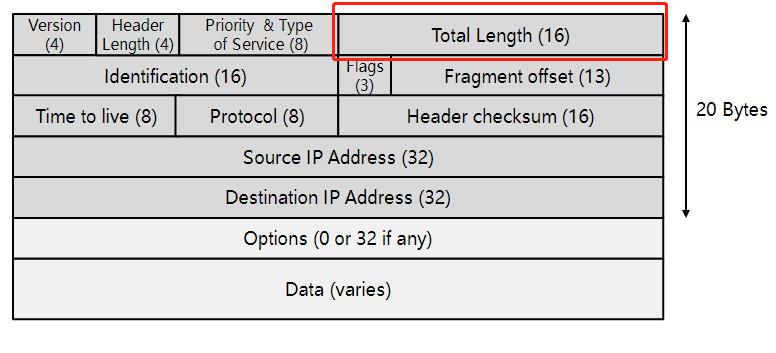
长度16比特。总长度是一个16比特字段,以字节为单位指定包的总长度,包括报头。IP包最大长度65535字节。
标识符(Identifier):

长度16比特。该字段和Flags和Fragment Offest字段联合使用,对大的上层数据包进行分段(fragment)操作。当数据包的大小超过接口的最大传输单元(英语:Maximum Transmission Unit,缩写MTU)时,必须将该数据包分割成较小的数据包,然后,路由器在“标识符(Identifier)”字段中用相同的数字标记每个片段,以便接收设备可以识别这些被分割的数据包,并将它们整合到一起。
标记(Flags):
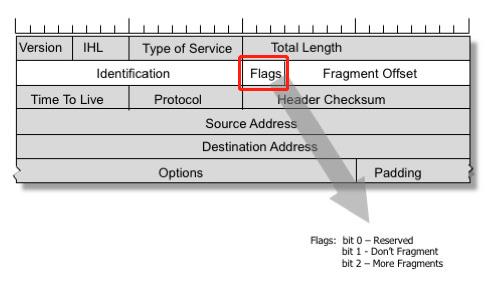

长度3比特。该字段第一位不使用。第二位是DF位,DF位设为1时表明路由器不能对该上层数据包分段。如果一个上层数据包无法在不分段的情况下进行转发(例如数据包大小超过MTU但不允许分片),则路由器会丢弃该上层数据包并返回一个错误信息。第三位是MF位,当路由器对一个上层数据包分段,会将最后一个分段之外的所有MF位都设置为1,以便接收设备明白要继续等待分段,直到遇到MF = 0的分段为止。假设一个数据包被分为10段,当其中的分段5的数据在传输中丢失的话,整个所有的分段,也就是10个分段的数据都必须要重新传输。这种情况有可能会增加网络拥塞。
分段序号(Fragment Offset):

长度13比特。该字段对包含分段的上层数据包的IP包赋予序号。由于IP包在网络上传送的时候不一定能按顺序到达,这个字段保证了目标路由器在接收到IP包之后能够按照发送的顺序准确还原分段的上层数据包。如果在传输的过程中丢掉了某单个分片,那么整个数据包都要重新发送,并且分段的位置要和之前相同。
生存时间(Time to Live、TTL):
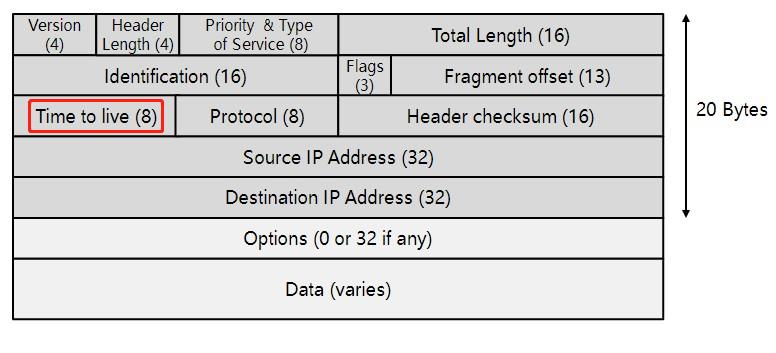
长度8比特。当IP包进行传送时,先会对该字段赋予某个特定的值。当IP包经过每一个沿途的路由器的时候,每 个沿途的路由器会将IP包的TTL值减少1。如果TTL减少为0,则该IP包会被丢弃。这个字段可以防止由于故障而导致IP包在网络中不停被转发。TTL虽然中文翻译成生存时间,但实际来看其实是一个经过多少路由器的跳数计算,一般情况下建议TTL设置成为64,当然更小的TTL值(例如32或15)也能见到。
协议(Protocol):
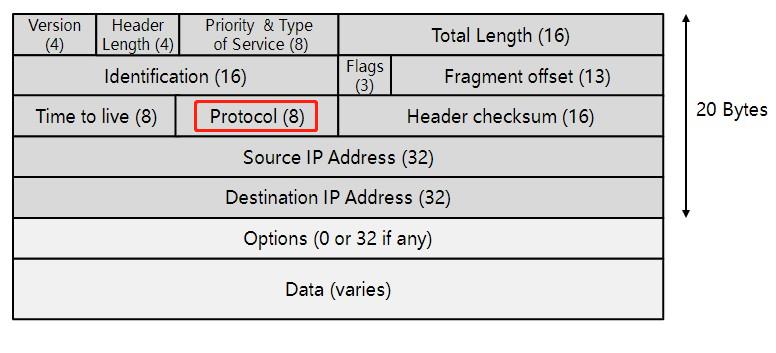
长度8比特。IP头中的协议号用来说明IP报文中承载的是哪种协议(一般是传输层协议,比如6 TCP,17 UDP;但也可能是网络层协议,比如1 ICMP;也可能是应用层协议,比如89 OSPF)。
一些知名协议号:
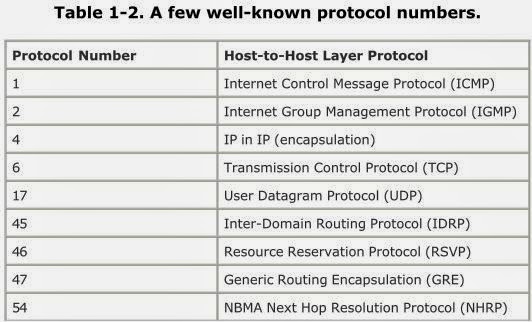
头部校验和(Header Checksum):

长度16位,由于IP包头是变长的,所以提供一个头部校验值来保证IP包头中信息的正确性。这个校验和不包括所封装数据,因为UDP、TCP和ICMP这些有自己的校验和去检测信息正确与否。该字段包含一个16位的补码校验和,由数据包的初始发送设备计算得出。
起源和目标地址(Source and Destination Addresses):

这两个地段都是32比特。标识了这个IP包的起源和目标地址。
可选项(Options):

这是一个可变长的字段。该字段由起源设备根据需要改写。可选项目包含以下内容:
松散源路由(Loose source routing):给出一连串路由器接口的IP地址。IP包必须沿着这些IP地址传送,但是允许在相继的两个IP地址之间跳过多个路由器。
严格源路由(Strict source routing):给出一连串路由器接口的IP地址。IP包必须沿着这些IP地址传送,如果下一跳不在IP地址表中则表示发生错误。
路由记录(Record route):当IP包离开每个路由器的时候记录路由器的出站接口的IP地址。
时间戳(Timestamps):当IP包离开每个路由器的时候记录时间。
这几个参数由于有安全方面的问题,所以几乎不再使用。比如互联网上有人截获报文,就可以知道拓扑,截获大量报文,甚至可以推算全网的拓扑、IP以及接口,比较危险。
比如关于Loose Source and Record Route (LSRR),RCF6274上3.13.2.3.的描述是:
1 | The LSRR option has well-known security implications. Among other |
IPv4地址
定义及格式
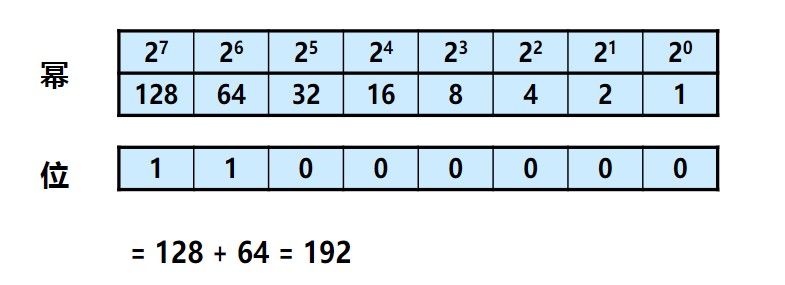
IPv4地址(以下简称IP地址)是为了确切地标识Internet中的主机和路由器,TCP/IP建立了一套编址方案,为每台主机和路由器分配一个全网唯一的地址。这个地址的名字就叫IP地址。(相当于国家为了知道谁是谁为每个人都分配了一个身份证号码一样),IP地址是一个逻辑地址,可以规划改变的。和现实中家里或公司的地址类似,现实中的地址绝大多数是唯一的,是为了让使用一个地址的人收到快递,现实中,一个身份证号(一个地址)对应一个人,网络中,一个IP地址对应一个设备或接口;互联网中的IP地址除极个别情况外也是唯一的,是为了让使用一个虚拟IP地址的人收到数据。IP地址的长度为32位,也就是IP报头中的源和目的IP地址所占的空间,也就是2的32位,32个1和0,例如00001011110000100011111101100100,但这个方式只有机器可以明白,因为机器只能识别0101这种二进制的数字,人类很难理解,于是把32位的IP地址分成4组,这样每个IP地址段中数字不太大方便人类记忆,每个八位组都可以用0到255之间的十进制数表示,然后将2进制换算成10进制,也就是点分十进制,比如上面的地址可以写成:00001011.11000010.00111111.01100100,换算成10进制是:11.194.63.100。这个换算的方式只说一下第一段如何换算,其他的以此类推:
00001011:

8+2+1=11,所以第一段00001011这个二进制数字换算成10进制数字为11。
以此类推,如果要将11000000换算成10进制:
我们需要记住上图的2的幂的结果,不需要死记硬背,这个是有技巧的,从上图来看,很容易发现,由于是2的幂,所有相邻的幂的前后都是相差2倍,所以只要知道其中一个幂值,就知道相邻的幂的值。
但要注意,点分十进制这个写法只是为了方便人类理解记忆IP地址,而网络设备只能看懂32位的0101组合的数字。IP地址由网络位和主机位构成。网络位的概念基本可以等同于代表一个网段的网络号,网络位用于确定某一特定的网络,主机位用于确定该网络中某一特定的主机,它在这个特定的网络中的编号是多少。同一网段内的计算机网络部分相同,主机部分不同同时重复出现。初看这段可能一开始接触会觉得不知所云,这个命名规则用收件地址来类比会比较易懂一些:
比如要从广州寄个快递给北京市海淀区复兴路26号复兴小区7号楼1单元109的李磊收,快递员拿到这个快递以后,只需要看最开头的“北京市海淀区”就够了,他不需要管后面那一长串详细的小区名门牌号之类的因为那些信息等快递到了北京才要去管,快递不到北京知道那些东西毫无意义,他只需要知道地址最开头的大地址“北京市海淀区”,然后把这个快递交给发往北京的线路,发送到北京海淀的集散中心,由北京海淀的集散中心再去关心后边的具体的门牌地址之类的具体信息进行分拣投送。网络位起到的作用和收货地址里“北京市海淀区”这个大范围的作用类似,网络位(网络号/网段)定义了一个大的IP地址范围,网络位对应使用同一个网络号的主机范围,一个网络号(网段)可能包含N个IP地址(具体有几个地址要结合子网掩码计算得出),只要是发往这个网络号包含主机的数据,都可以直接发往通往这个网络号的设备,网络号和网络位的概念基本一致,就是网络位+主机位为0;主机位则是在这个特定的网络中的某一台特定的设备或接口,和地址后面具体的门牌号和收件人功能类似,属于在特定的网络号的范围内,精确定位用的。比如一个四合院里面可能住了很多人,但四合院的门牌号可能都是北京市西城区西直门大街西直门胡同1号院,但如果地址只写这个1号院,谁知道这封信是给院子里哪个人的呢,所以必须在这个1号院的地址后边加上收件人,这个“北京市西城区西直门大街西直门胡同1号院”代表了所有住这个院子里的人的一个大范围的地址,相当于网络号(网络位)的作用,确定一个大的地址范围(IP地址所属的大的范围也就是IP地址所属的网段),所有属于这个网段的每一个IP地址都是这个网络号的一部分,而收件人:张三、李四、王二麻子,相当于主机位。也可以用身份证号码的命名模式类比来理解网络位和主机位:

至于一个网段里有多少主机位,要看具体情况,比如192.168.1.0/24这个网段所能容纳的主机IP地址数,是从192.168.1.0 — 192.168.1.255这么多,但由于192.168.1.0是本网段的网络号所以不能使用,而192.168.1.255是本网段的广播地址,也不能作为普通IP地址使用,最后IP地址的数字是从192.168.1.1 — 192.168.1.254,一共是253个IP地址,把最后的主机位写成二进制,会明白这个意思:
192.168.1.0换算成二进制:
192 . 168 . 1 . 0
1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 0 0 0 0 0 0 0 0
由于最后一个8位组都是主机位,所以第一个IP地址是00000001,将00000001换算成2进制,补全网络位以后,这个IP地址就是192.168.1.1;在这个基础上加1,主机位为00000002,由于这个是二进制,也就是逢二进一,所以加1以后主机位应为,00000010,第二个IP地址就是192.168.1.2;在前面的基础上加1 , 主机位为00000011,换算成2进制并补全网络位以后,IP地址为192.168.1.3。以此类推可以得出该网段包含的所有IP地址,因为1个8位组最大的数值就是8个1,也就是:11111111,所以一个8位组换算成10进制最大不会超过255。
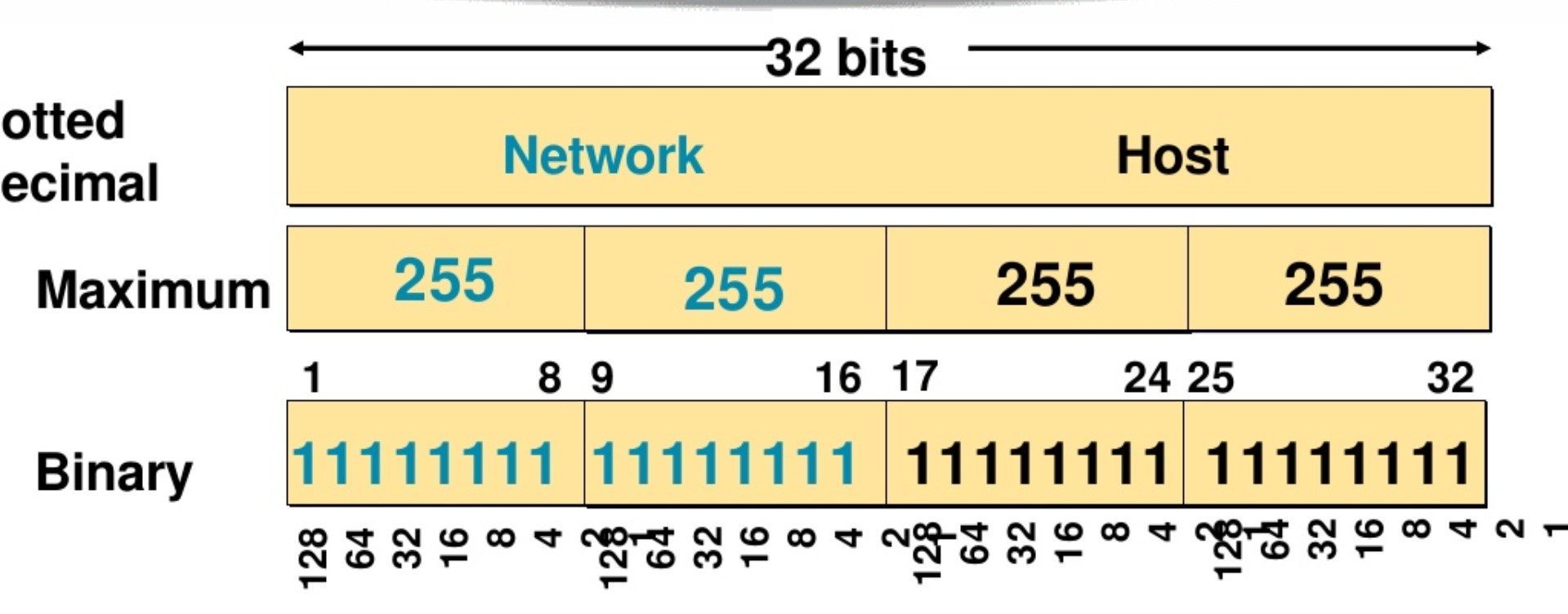
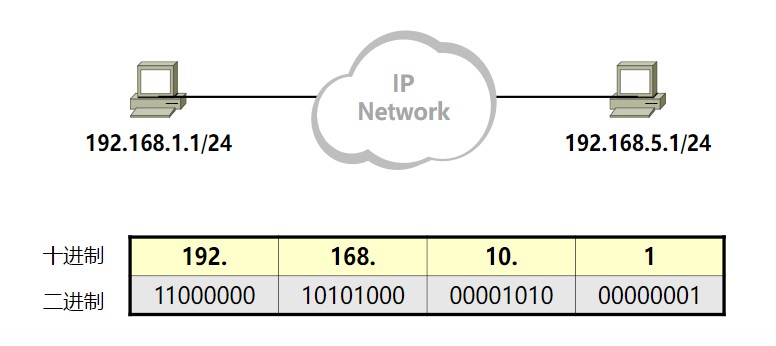
IP地址的类别:
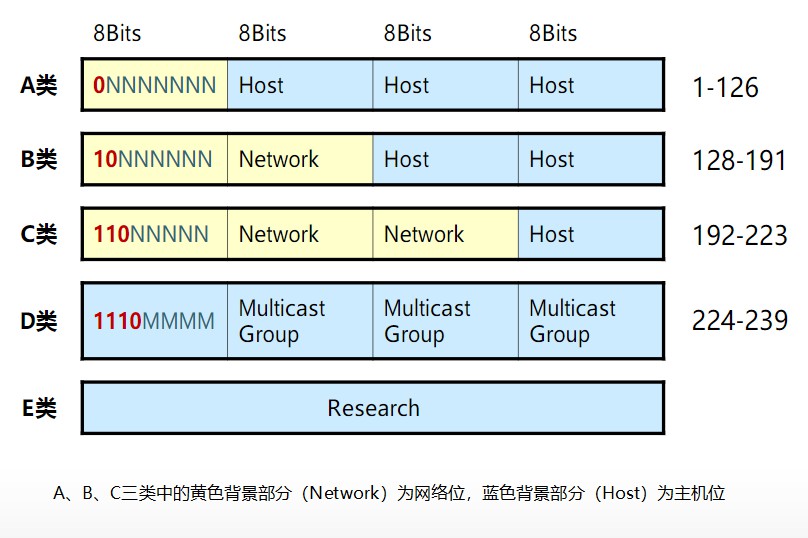
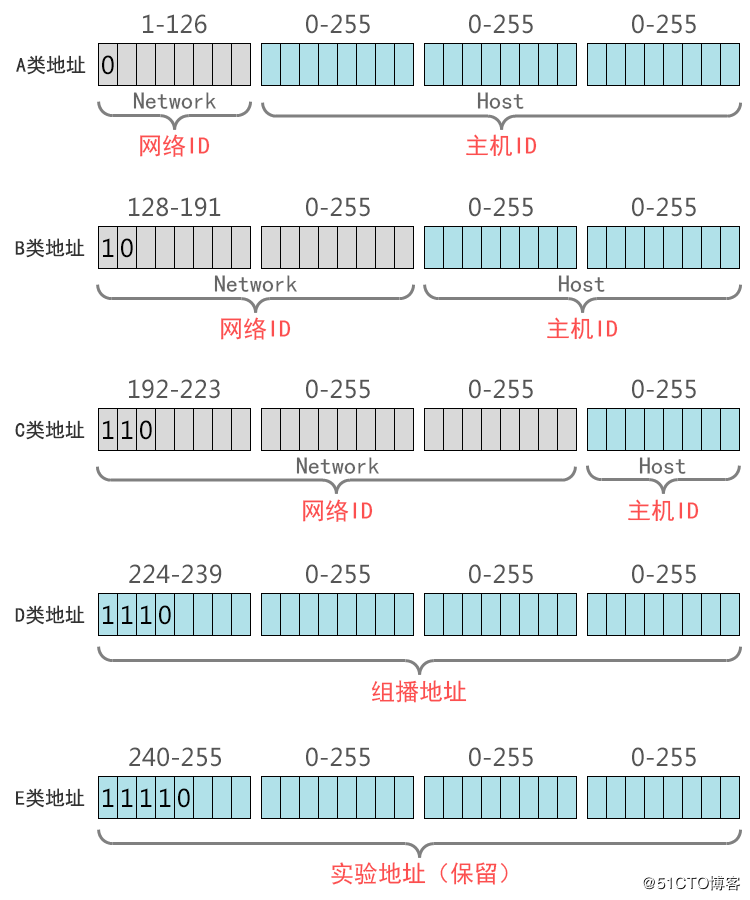
网络位部分决定了设备位于网络的哪个网段中,主机位部分标识了一个网段中的特定设备。
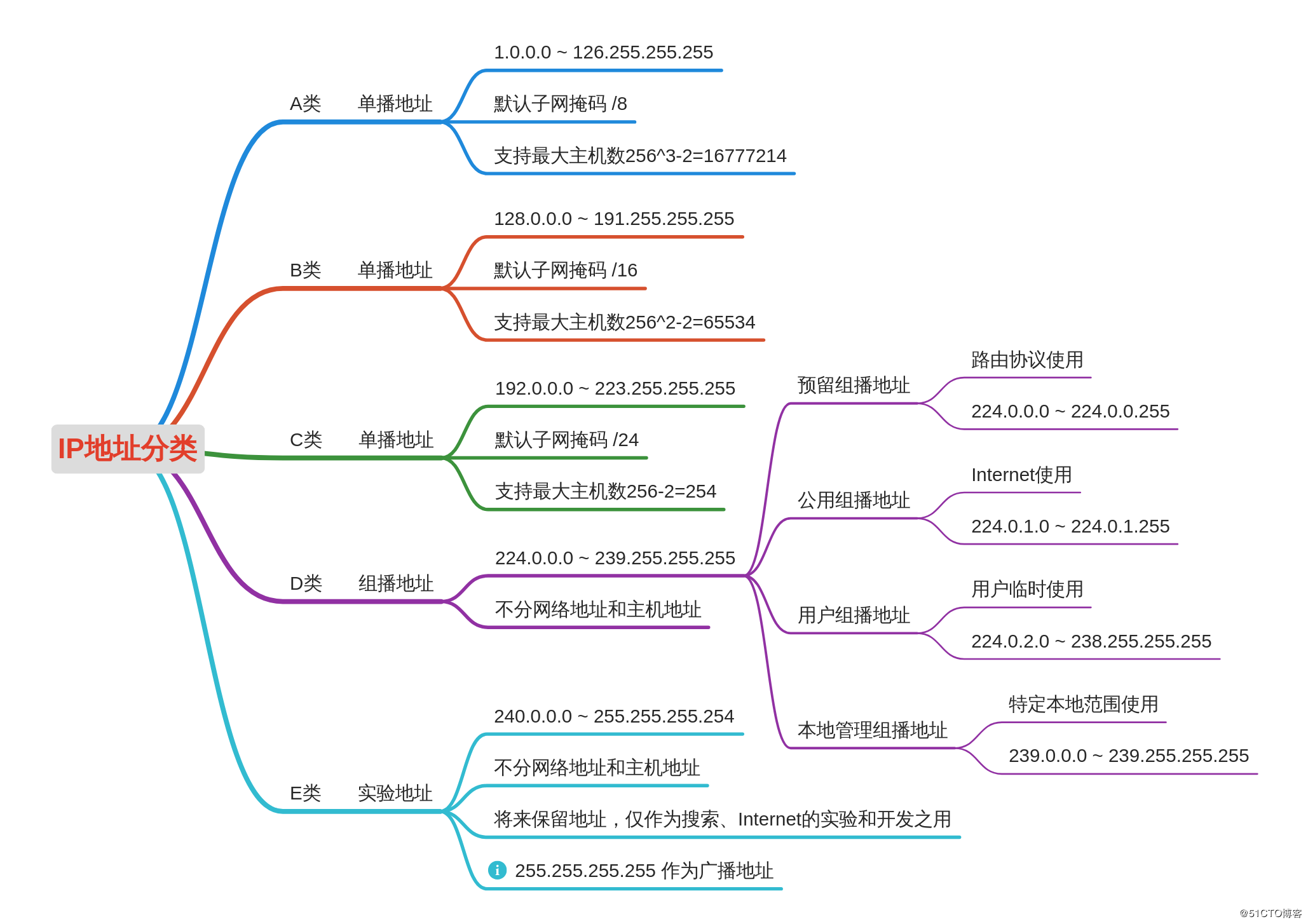
IP地址共分5个类别:A、B、C、D、E
A:左起第1位必须是0,其他随意变换(1~126)。第一个八位组为网络位,它第一位必须是0其他位数没有要求,其他三个八位组为主机位。A类网络默认子网掩码为255.0.0.0,也可写作/8。
第1位必须是0,说明第1个八位组中的第一个数字是固定的,其他7个数字可以任意变化,也就是从00000000,00000001,00000010,00000011….. ~ 01111111,将前面的二进制换算成十进制,就是从1 ~ 127,但由于全0地址被保留,因为0.0.0.0表示所有IP地址,常用于定义默认路由,而127.*的这个整个网段常被用作loopback网络接口的默认地址,用于测试本机的TCP\IP协议是否正常(能ping通这个地址说明本机的TCP\IP协议工作正常),按惯例通常设置为 127.0.0.1。这个地址在其他计算机上不能访问,就算你想访问,访问的也是自己,因为每台带有TCP/IP协议栈的设备基本上都有 localhost/127.0.0.1。所以A类地址的网络位只是从1~126,因为0和127都有特殊的用途和意义,所以可用的A类网络有126个(1.0.0.0;2.0.0.0…126.0.0.0),A类网络最大主机数量是256×256×256-2=166777214(减去1个主机位为0的网络地址和1个广播地址),也就是从1.0.0.0 ~ 126.255.255.255。
B:左起第1、2位必须是10(128 ~ 191)第一和第二个八位组为网络位,第一个八位组的第一位和第二位必须是0、1,其他位数没有要求,其他两个八位组为主机位。B类网络默认子网掩码为255.255.0.0,也可写作/16。
第1、2位必须是10,说明第1个八位组中的第1、2位数字是固定的,其他6个数字可以任意变化,也就是从10000000 ~ 10111111,将前面的二进制换算成十进制,就是从128 ~ 191,所以IP地址的范围是从128.0.0.0 ~ 191.255.255.255。可用的B类网络有16382个,每个网络最大主机数量256×256-2=65534。
C:左起第1、2、3位必须是110(192 ~ 223),前三个八位组为网络位,最后一个八位组为主机位。C类网络默认子网掩码为255.255.255.0,也可写作/24。
第1、2、3位必须是110,说明第1个八位组中的第1、2、3位数字是固定的,其他5个数字可以任意变化,也就是从11000000 ~ 11011111,将前面的二进制换算成十进制,就是从192 ~ 223,所以IP地址的范围是从192.0.0.0 ~ 223.255.255.255。C类网络最大主机数量256-2=254。
D:左起第1、2、3、4位必须是1110(224 ~ 239),不分网络地址和主机地址。
第1、2、3、4位必须是1110,说明第1个八位组中的第1、2、3、4位数字是固定的,其他5个数字可以任意变化,也就是从11100000 ~ 11101111,将前面的二进制换算成十进制,就是从224 ~ 239,所以IP地址的范围是从224.0.0.0 ~ 239.255.255.255。D 类地址没有主机标识,常用于组播(多播)。
E:左起第1、2、3、4、5位必须是11110(240 ~ 255)E类地址用于实验和将来使用。不分网络地址和主机地址。
在分配 IP 地址时关于主机标识有一点需要注意。即要用比特位表示主机地址时,不可以全部为 0 或全部为 1。因为全部为 0 只有在表示对应的网络地址或 IP 地址不可以获知的情况下才使用。而全部为 1 的主机通常作为广播地址。因此,在分配过程中,应该去掉这两种情况。这也是为什么 C 类地址每个网段最多只能有 254( 28 - 2 = 254)个主机地址的原因。
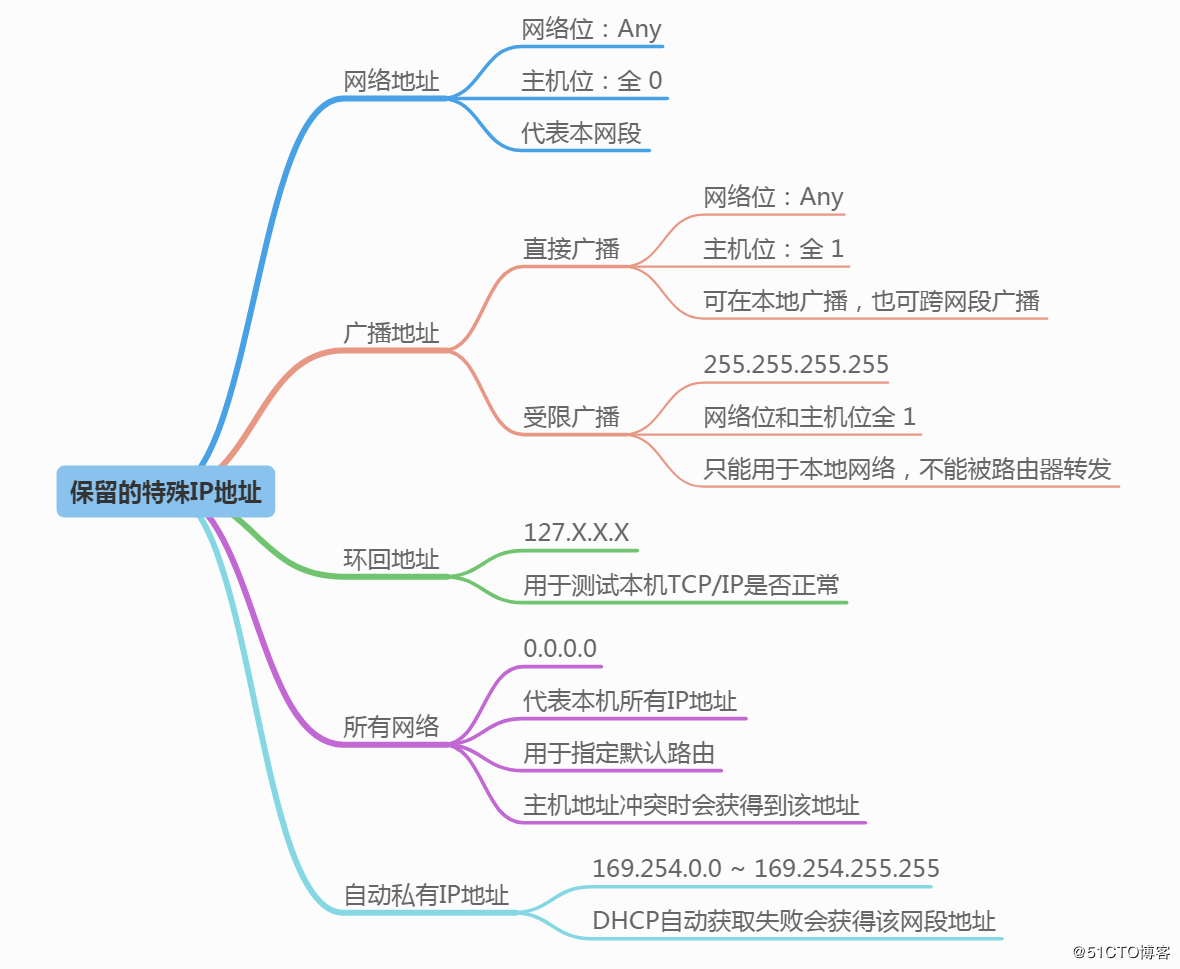
关于IP地址的基本概念
•单播(Unicast):
主机之间一对一的通讯模式,网络中的交换机和路由器对数据只进行转发不进行复制,单播过程类似于我们现实生活中一对一的打电话。如果10个客户机需要相同的数据,则服务器需要逐一传送,重复10次相同的工作。但由于其能够针对每个客户的及时响应,所以现在的网页浏览全部都是采用单播模式,具体的说就是IP单播协议。网络中的路由器和交换机根据其目标地址选择传输路径,将IP单播数据传送到其指定的目的地。
•广播(Broadcast):
主机之间一对所有的通讯模式,网络对其中每一台主机发出的信号都进行无条件复制并转发,所有主机都可以接收到所有信息(不管你是否需要),由于其不用路径选择,所以其网络成本可以很低廉。类似我们的校园广播,校园广播一开启播放,校园里的所有人都能听到,但是不是所有人都对广播内容感兴趣,有些人选择倾听,有些人选择忽略。但不管你是倾听还是忽略,广播的声音都会传到你的耳边。例如,校园广播一条失物招领通知,你根本没丢东西,所以这个广播内容与你无关,但是广播的声音还是会传到你的耳边。对比广场舞音乐,对于跳广场舞的大妈大婶来说,这就是音乐,对于想睡觉的您来说,这就是噪音。在数据网络中也允许广播的存在,但其被限制在二层交换机的局域网范围内,禁止广播数据穿过路由器,防止广播数据影响大面积的主机。
•组播(Multicast):
主机之间一对多(一组ip地址)的通讯模式,加入了同一个组的主机可以接受到此组内的所有数据,网络中的交换机和路由器只向有需求者复制并转发其所需数据。主机可以向路由器请求加入或退出某个组,网络中的路由器和交换机有选择的复制并传输数据,即只将组内数据传输给那些加入组的主机。这样既能一次将数据传输给多个有需要(加入组)的主机,又能保证不影响其他不需要(未加入组)的主机的其他通讯,有点类似于我们常用的微信群,只有加入了特定的微信群才能收到特定群发送的消息,也可以随时退出微信群,这样就无法收到相关微信群的消息了。IP地址中的D类就是组播用的地址,大概意思就是想接收特定组播地址的设备去监听该组播地址,就能收到相应的组播消息。
公网IP地址
公有地址分配和管理由Inter NIC(Internet Network Information Center 因特网信息中心)负责。各级ISP使用的公网地址都需要向Inter NIC提出申请,有Inter NIC统一发放,这样就能确保地址块不冲突。有公网IP地址的话可以直接用这个地址访问互联网上的其他资源。
私网IP地址
创建IP寻址方案的人也创建了私网IP地址。这些地址可以被用于私有网络,在Internet没有这些IP地址,Internet上的路由器也没有到私有网络的路由表。
私有地址类似于“10号楼1单元808”,这个在本小区的内部可以正常使用,但出了本小区以外,很多小区都有10号楼1单元808这个地址,就没法正确的定位设备也就没法使用了。私有地址的使用仅限于局域网内部使用,无法在公网上获得路由,一般内部网络都是用私有地址,因为IPV4地址资源有限,如果使用私有地址的设备想访问互联网则使用NAT\PAT技术将私有地址转换成公有地址即可。
- A类:10.0.0.0 255.0.0.0,保留了1个A类网络。
- B类:172.16.0.0 255.255.0.0~172.31.0.0 255.255.0.0,保留了16个B类网络。
- C类:192.168.0.0 255.255.255.0~192.168.255.0 255.255.255.0,保留了256个C类网络。
PS:私网地址访问Internet需要做NAT或PAT网络地址转换,目前我们常用的家用路由器,都是给家里分配一个私有地址网段,所有设备使用这个网段在内网进行通信,如果要访问互联网上的资源,需要将私有地址进行转换,转换成公有地址才可以。

子网掩码:
因为越来越多的用户接入互联网,原有的IP地址不够分的,比如一个A类地址中包含的IP地址过多,一般大公司用不了那么多,但按原有的IP地址规定又不好分开,所以加入了子网掩码,和IP地址结合使用,用于描述一个IP地址中的网络部分及主机部分,用来确定目标IP是否在“逻辑上”与本计算机在同一个网络内。为什么要确定两个IP地址在逻辑上是否在同一个网络呢?是因为如果两个IP在同一个网络内,也就是在同一个网段内,也就是他们的三层地址在同一个大的范围内,所以通信的时候只需要二层设备就可以通信了;如果他们的三层地址不在同一个大的范围内,必须要三层设备才能互相通信。1对应网络号字段和子网号字段,0对应主机号字段。
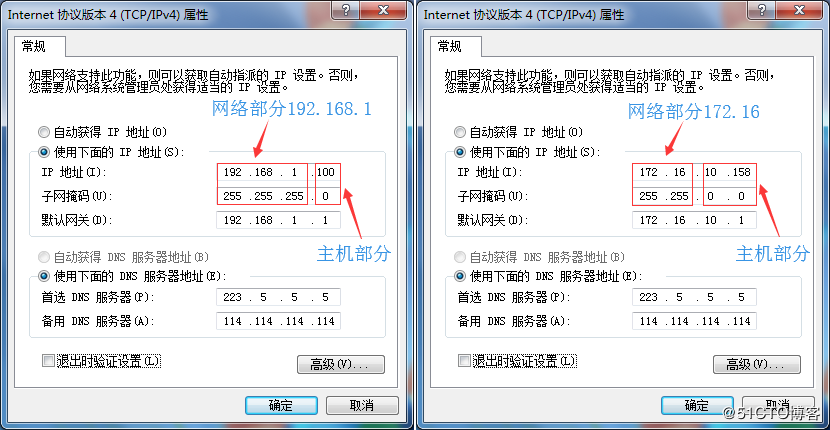
子网掩码的长度是32bit,可以像ipv4地址一样用点分十进制一样,但必须知道子网掩码不是IP地址,两者不一样。
A、B、C类网络都有默认的子网掩码(default subnet mask).A 类IP 地址的默认子网掩码为255.0.0.0;B 类的为255.255.0.0;C 类的为255.255.255.0 ,但子网掩码也可以改变,也就是让网络位和主机位之间相互借位,已达到更好划分网络利用IP地址的目的,例如VLSM和超网,这两个概念在后面章节有详细的介绍。
如果子网掩码是24/的时候,就是说子网掩码为24位,前24位为网络位,后8位为主机位,也就是24个二进制的1:11111111.11111111.11111111.00000000,换算成10进制就是255.255.255.255.0
如何如何计算出两个IP地址是否逻辑上在同一个网络(在同一网段)呢?也就是用32位的IP地址和32位的子网掩码,一位对一位的进行与运算,得出的就是所在网段。
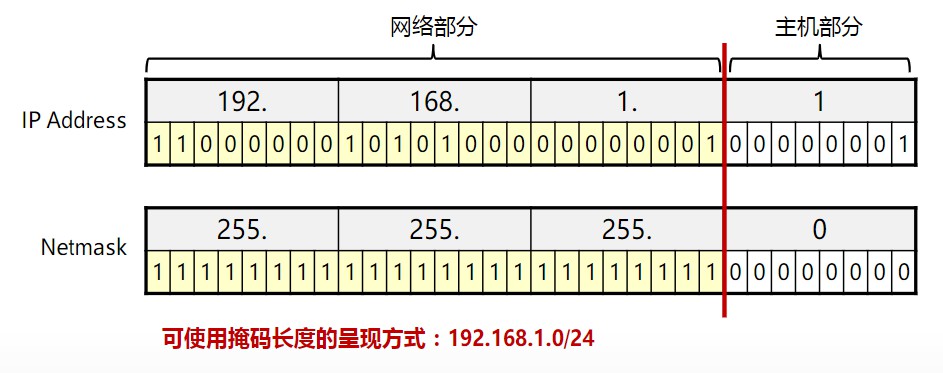
IP地址与子网掩码的与运算:
与运算的整体规则为:0&0=0; 0&1=0; 1&0=0; 1&1=1。即:当且仅当两位同时为“1”,结果才为“1”,否则为0,举个例子:4&6
4的二进制:0 1 0 0
6的二进制:0 1 1 0
得出结论: 0 1 0 0
所以得出结论,4&6=4
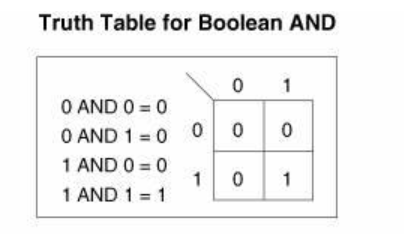
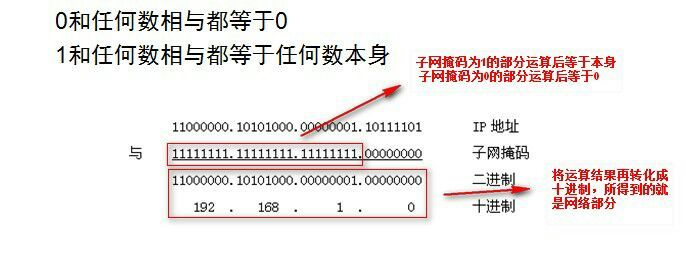
IP地址与子网掩码的运算步骤为:
1、把IP地址和子网掩码变成二进制
2、将二进制的IP地址与子网掩码进行每一位对应的与运算
3、将运算后的结果换算为十进制得到网络地址也就是网络号
4、网络号不变,主机位全为0得出的即为该网段的网络号,主机位全为1得出的即为该网段的广播地址。
比如IP地址为192.168.1.129和192.168.1.5这两个C类网络地址,在子网掩码为255.255.255.0和255.255.255.128的时候是不同的。
当子网掩码为255.255.255.0的时候,掩码为/24位,因为一个8位组全为1的时候,1111111,换算成十进制以后是255,三个255,也就是3X8=24,掩码为24位,换算成二进制就是11111111.11111111.11111111.11111111。
192.168.1.5/24的网络号计算:
IP地址: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 0 0 0 0 0 1 0 1
子网掩码: 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 0 0 0 0 0 0 0 0
网络号: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 0 0 0 0 0 0 0 0 = 192.168.1.0
广播地址: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 1 1 1 1 1 1 1 1 = 192.168.1.255
所以192.168.1.5这个IP当它的掩码为/24的时候,网络号为192.168.1.0,广播地址为192.168.1.255。
192.168.1.129/24的网络号计算以此类推:
IP地址: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 1 0 0 0 0 0 0 1
子网掩码: 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 0 0 0 0 0 0 0 0
网络号: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 0 0 0 0 0 0 0 0 = 192.168.1.0
广播地址: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 1 1 1 1 1 1 1 1 = 192.168.1.255
所以192.168.1.129这个IP当它的掩码为/24的时候,网络号为192.168.1.0,和192.168.1.5的网络号相同,在同一个网段,当然二者的广播地址也是相同的,因为在同一网段。
下面来看看当这两个IP地址的子网掩码为255.255.255.128(也就是掩码为/25,前三个8位组均为255的时候一共是24位,所以第四个8位组的第一位也为1的时候<10000000=128>,正好是25个1,也就是/25位,)他们的网络号分别为多少。
192.168.1.5/25的网络号计算:
IP地址: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 0 0 0 0 0 1 0 1
子网掩码: 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 0 0 0 0 0 0 0
网络号: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 0 0 0 0 0 0 0 0 = 192.168.1.0
广播地址: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 0 1 1 1 1 1 1 1 = 192.168.1.127
所以192.168.1.5这个IP当它的掩码为/25的时候,网络号为192.168.1.0,广播地址为192.168.1.127,广播地址这里要注意一下,因为子网掩码是25/位的,也就是说网络位有25位,IP地址一共32位,32-25=7,所以主机位是后7位,所以该网段的广播地址为192.168.1.127,并不是192.168.1.255。
192.168.1.129/25的网络号计算:
IP地址: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 1 0 0 0 0 0 0 1
子网掩码: 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 1 1 1 1 1 1 1 . 1 0 0 0 0 0 0 0
网络号: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 1 0 0 0 0 0 0 0 =192.168.1.128
广播地址: 1 1 0 0 0 0 0 0 . 1 0 1 0 1 0 0 0 . 0 0 0 0 0 0 0 1 . 1 1 1 1 1 1 1 1 = 192.168.1.255
所以192.168.1.129这个IP当它的掩码为/24的时候,网络号为192.168.1.128,和192.168.1.5的网络号不同,说明他们属于不同的网段,相互通信的时候需要三层设备。
子网划分
要知道,为了完成路由的整个过程,每一条链路都要有自己独一无二的网段,而且在链路上的每台主机也要有IP地址,这个IP地址标识了主机属于该网段的一部分且将该主机和网络中的其他主机区别开。架设一个网络需要很多个链路,如果按照上面这个定义(每条链路要有自己独一无二的网段),那么全球只有不到1700万个链路可用,显然这样是不靠谱的,因为一个A类地址有一亿六千多个IP地址,只能在一个链路上使用显然太浪费了,之所以如此浪费IP地址,是因为在一开始定义A\B\C类网段的时候并没有像今天这么多的互联网用户,所以并没有考虑的如此周全。因此必须将如此大的网络进行进一步划分,在划分前先来回顾两个事实:
- ipv4地址的主机位可以按需使用;
- ipv4地址的网络位由子网掩码决定。
子网划分的定义
可以自由的加减子网掩码长度,也就是不限制于A/B/C类默认的掩码长度,A类地址不必须使用8/位的掩码,也可以用诸如:10/位掩码或者7/位掩码。
子网划分的原因
子网就是把一个大网划分为几个小网,而如果按照默认的A\B\C类默认使用的话,比如一个B类地址,默认掩码为255.255.0.0,意味着这个地址空间里有2的16次方个IP,并且该网络号只能用于一个广播域,造成了IP地址的极大浪费,如果一个广播域中的PC数量过于庞大,网络可能被广播报文消耗大量资源。把一个大网络划分成几个不同的小网络以后,他们之间的网络号和广播地址各不相同,可以尽可能多的使用IP地址避免浪费,一个网段中的主机数量相对少一些的话,广播报文消耗的资源也会少很多,使得网络更有层次性。
为了解决IPv4的不足,提高网络划分的灵活性,诞生了两种非常重要的技术,那就是VLSM(可变长子网掩码)和CIDR(无类别域间路由),把传统标准的IPv4有类网络演变成一个更为高效,更为实用的无类网络。
VLSM用于IPv4子网的划分,也就是把一个大的网络划分成多个小的子网;而CIDR则用于IPv4子网的聚合,当然主要是指路由方面的聚合,也就是路由汇总。通过CIDR可以把多个小的子网路由条目汇总成一个大网络的路由条目,以减少路由器中路由条目的数量,提高路由效率。
子网划分的方法
子网划分的总体思路是借用现有网段的主机位的最左边某几位作为子网位,划分出多个子网:
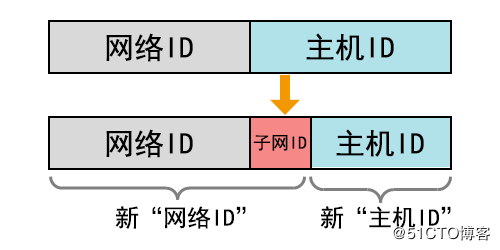
①、把原来有类网络IPv4地址中的“网络ID”部分向“主机ID”部分借位
②、把一部分原来属于“主机ID”部分的位变成“网络ID”的一部分(通常称之为“子网ID”)。
③、原来的“网络ID”+“子网ID”=新“网络ID”。“子网ID”的长度决定了可以划分子网的数量。
网络ID等同于网络位,主机ID等同于主机位,翻译方式不同。
具体的划分步骤参见:子网划分
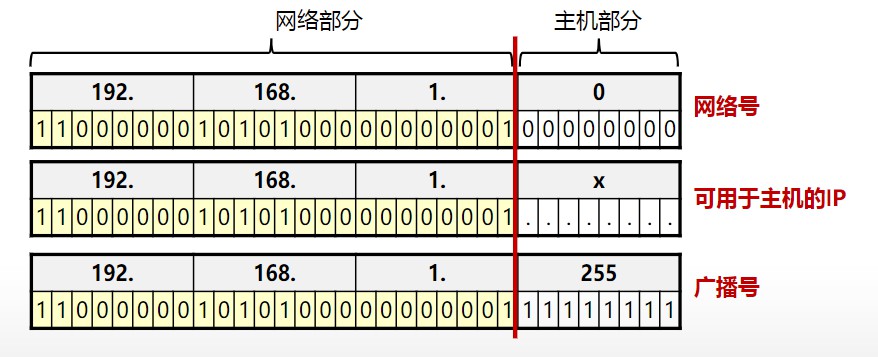
网络地址、网络号、网络位:
指代网络的地址,又叫网络号。标识网络上的一个物理网络地址,位于相同的物理网络上的所有主机(包括网关)共享一个相同的网络号,其主机地址的网络部分相同。这样的地址模式便于对大量地址进行分级管理,可以极大的减少路由表的规模,使得网络容纳大量主机成为可能。比如说,如果没有网络号,去往192.168.10.2、192.168.10.3、192.168.10.4将数据从E0口发送出去这个路由,在路由表中就要生成三个条目,而如果用网络号记录则只需要记录一条192.168.10.0的条目即可,能大大节约网络设备的条目数量。
当一个IP地址的主机位全为0的时候得出的地址就是网络号。如果两个IP地址的网络号相同说明这两个IP地址在逻辑上处于同一个网络,在同一网段,通信的时候只需要二层设备就可以通信了;如果他们的三层地址不在同一个网段,所以必须要三层设备才能互相通信。比如如果两个主机的IP地址分别是192.168.1.25/24和192.168.1.186/24,因为子网掩码都是24,所以表示前24位为网络位,后8位为主机位,当主机位全为0的时候,IP地址和子网掩码之间做逻辑与运算,只有两位都为1的情况下,与运算的结果才为1:
192 .168 .1 .25
11000000 10101000 00000001 00011001
255 .255 .255 .0
11111111 11111111 11111111 00000000
因此两者逻辑与运算的结果为:
11000000 10101000 00000001 00000000
也就是192.168.1.0,这个就是这个主机的网络号,另一台主机的192.168.1.168/24同理可得网络号也是192.168.1.0,因此两台主机不需要三层设备(比如路由器或三层交换机)而只用二层设备(比如二层交换机或集线器)就可以相互通信。
广播地址:
用于向网络中的所有主机发送数据的特殊地址。广播地址使用该网络范围内的最大地址。即主机部分的各比特位全部为1的地址。如下图中,192.168.1.255是192.168.1.0这个网络号代表的网段的广播地址,如果向192.168.1.255这个广播地址发送数据,整个192.168.1.0网段包括的IP地址都能收到这个消息。
当一个IP地址的主机位全为1的时候得出的地址就是该网段的广播地址。
主机地址:
分配给网络中终端设备的地址,例如:192.168.1.5。
网关
网关的定义
网关实质上是一个网络通向其他网络(其他网段)的IP地址,比如有网络A和网络B,网络A的IP地址范围为“192.168.1.1 ~ 192.168.1.254”,子网掩码为255.255.255.0;网络B的IP地址范围为“192.168.2.1 ~ 192.168.2.254”,子网掩码为255.255.255.0。在没有路由器的情况下,两个网络之间是不能进行TCP/IP通信的,即使是两个网络连接在同一台交换机(或集线器)上,TCP/IP协议也会根据子网掩码(255.255.255.0)判定两个网络中的主机处在不同的网络里。而要实现这两个网络之间的通信,则必须通过网关。如果网络A中的主机发现数据包的目标主机不在本地网络中,就把数据包转发给它自己的网关,再由网关转发给网络B的网关,网络B的网关再转发给网络B的某个主机。网络B向网络A转发数据包的过程也是如此 所以说,只有设置好网关的IP地址,TCP/IP协议才能实现不同网络之间的相互通信。那么这个IP地址是哪台机器的IP地址呢?网关的IP地址是具有路由功能的设备的IP地址,具有路由功能的设备有路由器、启用了路由协议的服务器(实质上相当于一台路由器)、代理服务器(也相当于一台路由器)。
举一个生活中的例子方便理解网关的概念和用途,大家都知道,从一个房间走到另一个房间,必然要经过一扇门。同样,从一个网络向另一个网络发送信息,也就是不同的网段不同的网络号之间相互发送信息,也必须经过一道“关口”,这道关口就是网关。顾名思义,网关(Gateway)就是一个网络连接到另一个网络的“关口”。没有这个“关口”,不同网段之间的通信就无法进行,就相当于去别的国家没法过人家海关,就没法入境。
网关的作用及工作流程的通俗解释
假设你的名字叫小不点,你住在一个大院子里,你的邻居有很多小伙伴,在门口传达室还有个看大门的李大爷,李大爷就是你的网关。当你想跟院子里的某个小伙伴玩,只要你在院子里大喊一声他的名字,他听到了就会回应你,并且跑出来跟你玩。
但是你不被允许走出大门,你想与外界发生的一切联系,都必须由门口的李大爷(网关)用电话帮助你联系。假如你想找你的同学小明聊天,小明家住在很远的另外一个院子里,他家的院子里也有一个看门的王大爷(小明的网关)。但是你不知道小明家的电话号码,不过你的班主任老师有一份你们班全体同学的名单和电话号码对照表,你的老师就是你的DNS服务器。于是你在家里拨通了门口李大爷的电话,有了下面的对话:
小不点:李大爷,我想找班主任查一下小明的电话号码行吗?
李大爷:好,你等着。(接着李大爷给你的班主任挂了一个电话,问清楚了小明的电话)问到了,他家的号码是211.99.99.99
小不点:太好了!李大爷,我想找小明,你再帮我联系一下小明吧。
李大爷:没问题。(接着李大爷向电话局发出了请求接通小明家电话的请求,最后一关当然是被转接到了小明家那个院子的王大爷那里,然后王大爷把电话给转到小明家)
就这样你和小明取得了联系。
在网络中,同网段之间的设备要进行通信(和同一个大院里的其他小朋友联系)是不需要经过网关(看门的X大爷)的,不同网段之间的设备要进行通信,就必须经过网关(你家大院看大门的X大爷),帮你把你要发送的信息传送给目的IP所在网段的网关(对方大院看门的X大爷),因为只有对方的网关才能在收到发往该网段的数据时,完成之后的通信步骤,具体的通信步骤以及网关所扮演的角色,请参后文“用TCP/IP模型分析数据传输过程”部分。
默认网关
如果搞清了什么是网关,默认网关也就好理解了。就好像一个房间可以有多扇门一样,一台主机可以有多个网关。默认网关的意思是一台主机如果找不到可用的网关,就把数据包发给默认指定的网关,由这个网关来处理数据包。现在主机使用的网关,一般指的是默认网关。如果一台设备中配置了默认网关,那么在路由表中没有某个数据包中目标IP地址的明细路由的时候,设备就会把数据包发送给默认网关,由默认网关去发送。有可能通过默认网关可以到达目标IP地址,也有可能没法送达。
网络层协议
ICMP(ping、Traceroute)
用途:
ICMP由设备(如路由器)用于与数据包的源进行通信,以解决传输问题,例如,如果数据未发送到目的设备,则ICMP可能将此信息报告给主机,并提供详细信息,以帮助识别传输错误。比较常用的是两种工具,Ping和Traceroute。
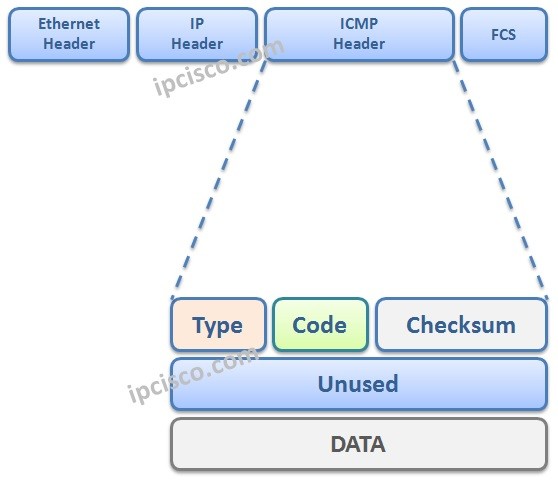
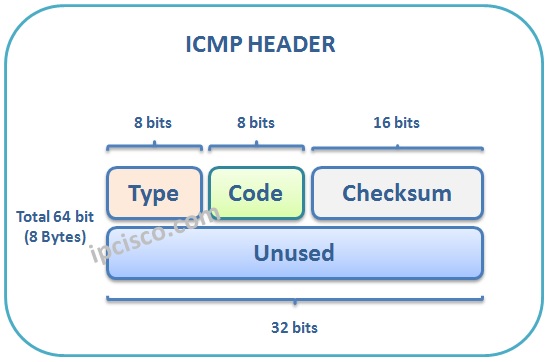
ICMP报头跟在IPV4报头后面,ICMP在IPV4报头中的协议号为1,所有的ICMP包都有8字节的报头部分和可变长度的数据部分,8字节的报头中,前4字节为固定格式,后4字节取决于ICMP数据包的类型/代码。
Type和Code两个字段,结合使用,在不同的字段下表示不同的含义,Type字段常用的为:
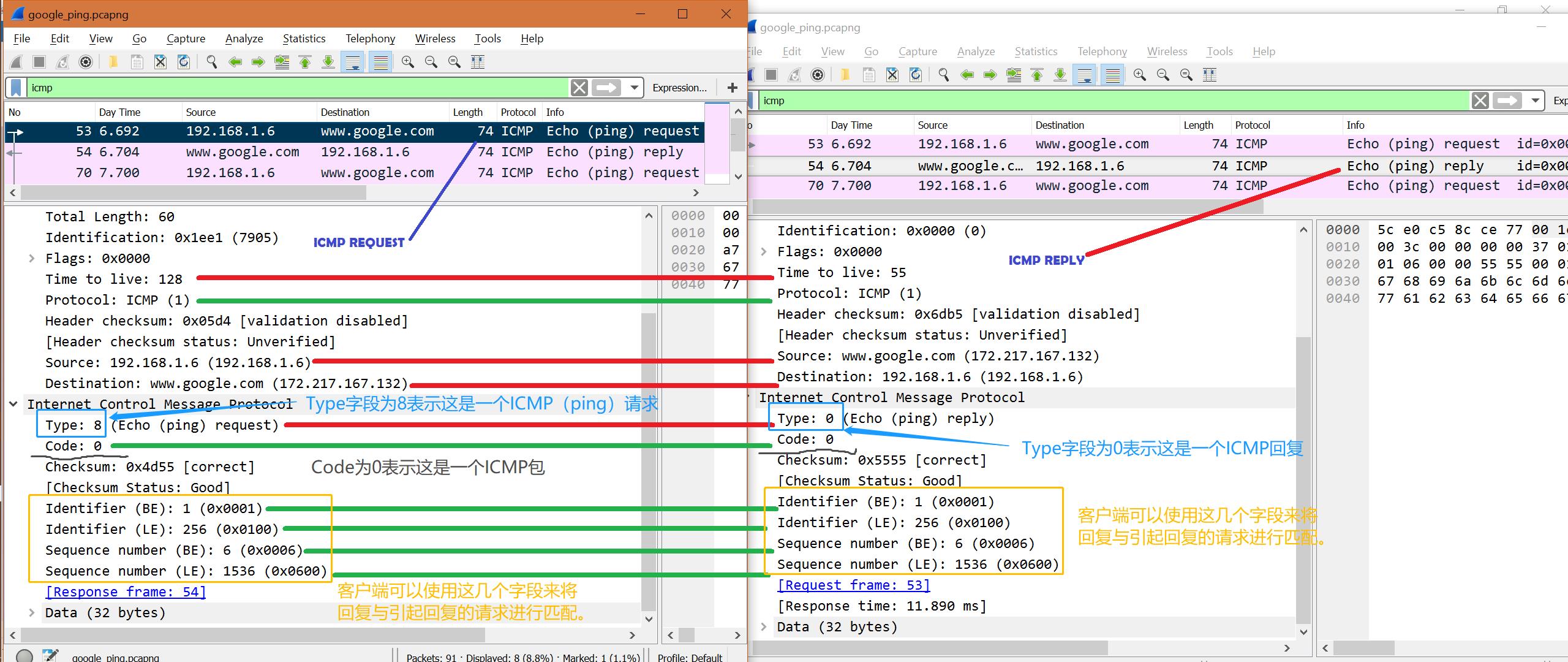
- Echo Reply (0):表示对于ping包的回复,和Type8结合使用
- Echo Request (8):表示ping包的请求,和Type0结合使用
- Destination Unreachable (3):表示目标设备不可达
- Time Exceeded (11):表示ICMP等待超时
下面来看看常见的ICMP的抓包:
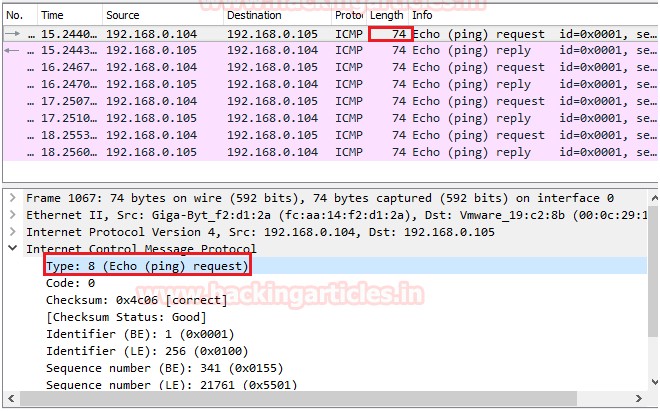
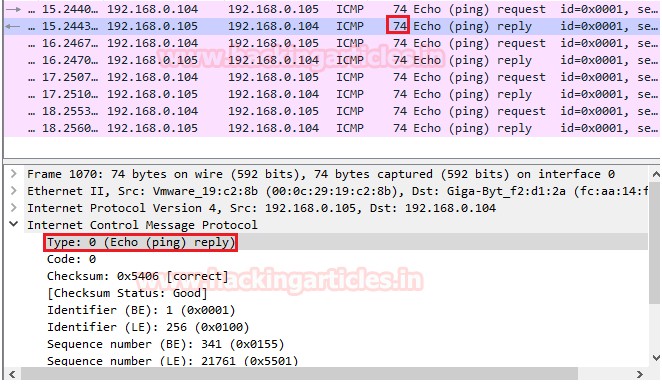
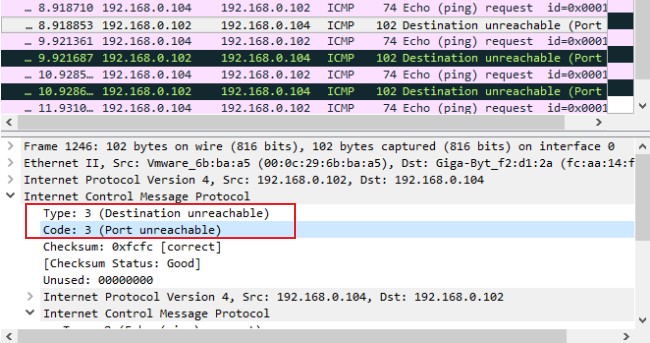
更多的关于Type和Code表示的含义有兴趣可以查看下表
.png)
Ping( Echo Request and Reply—Types 8 and 0)
Ping是一种非常实用的程序,它使用ICMP消息来报告有关网络连接和主机与目标计算机之间的数据中继速度的信息。大概工作原理就是模拟双向通信过程来检测链路是否畅通,常用命令就是Ping x.x.x.x,一般会返回以下几种信息:
! ! ! ! ! 每一个感叹号代表收到一次回复,表示链路畅通
. . . . . 每一个省略号表示网络在等待答复时超时,表示链路不通
U U U U U 每一个U表示收到目标不可达的错误
Q Q Q Q Q 收到Q表示目的设备太忙无法回复
ping包出去时,在Type中的字段是8,ping包的回复,在Type中字段是0。
Traceroute
traceroute命令可用于识别数据包到达其目标所使用的路径。 它标识从源主机到目标主机的路径中的所有路由器,在排除网络故障时很有用。 这个命令可以帮助网络管理员确定数据传输到哪台设备时发生了丢失,以便对该设备进行进一步的检查以确定问题原因。该命令利用IP头部的TTL字段,TTL字段在每经过一个设备时减少1,当TTL为0时(实际上,TTL来没有被减小到0,因为将其减小到0的路由器在TTL变成0之前会产生错误)数据包会被丢弃然后返回一个ICMP信息告诉源设备该情况,Traceroute命令就是利用TTL超时报错的特性来探测网络路径中的每一个设备节点。
Traceroute工作过程:
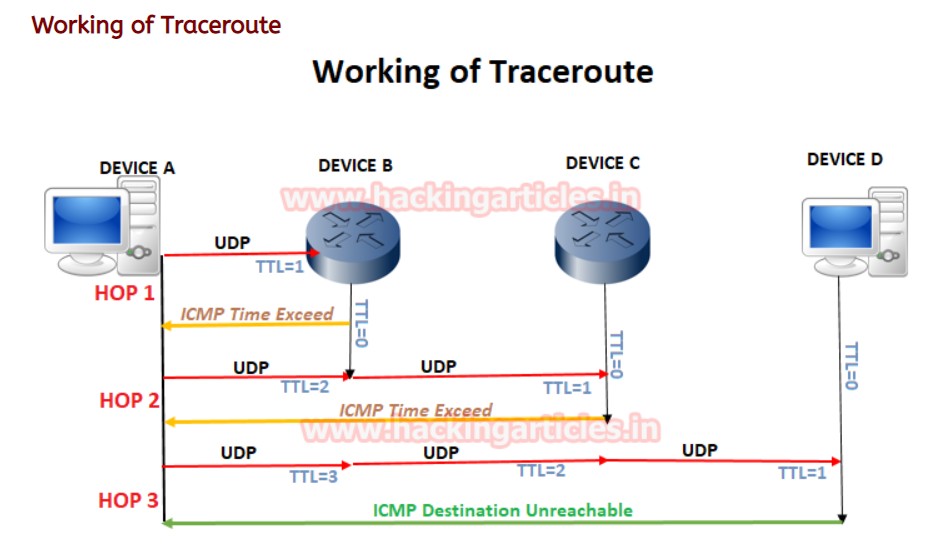
当设备A发送Traceroute到设备D时,A发出的数据的TTL从1开始并且持续增加,第一次发出的数据TTL=1,第二次发出的TTL=2,以此类推。当TTL=1的第一个数据到达设备B时,B发现TTL=1,再将这个TTL-1的话就为0了,会出现错误,从而丢弃该数据并返回一个ICMP超时的信息给设备A;设备A发送第二个数据,将TTL设置为2,经过设备B到达设备C后,设备C发现设备B发过来的数据TTL=1,再将这个TTL-1的话就为0了,会出现错误,从而丢弃该数据返回一个ICMP超时的信息,后面以此类推直到到达最终的设备D,从而将设备A——设备D之间的设备都搞清了。

上图是一个Traceroute成功的例子,Traceroute会把从源到目的设备的每一跳设备的信息显示出来。

上图是一个Traceroute失败的例子,表示数据包到10.0.0.1以后就无法再传输下去,表示极有可能是在该设备上出了问题。
Traceroute一般会返回如下的信息:

ping包抓包:
数据链路层(DataLink Layer)
The data link layer contains the protocols that control the physical layer: how the medium is accessed and shared, how devices on the medium are identified, and how data is framed before being transmitted on the medium. Examples of data-link protocols are IEEE 802.3/Ethernet, Frame Relay, ATM, and SONET.
——Routing TCP/IP, Volume I
数据链路层包含着那些控制着物理层的协议,比如如何访问和共享传输介质(传输介质,也就是两台设备中间的物理线路,包含光纤、网线、同轴电缆所有在内的这些),如何定义设备之间的传输介质,以及数据如何在传输之前形成数据帧的。数据链路层的常见协议有IEEE802.3,帧中继、ATM(asynchronous transfer mode,异步传输模式协议)和SONET(Synchronous optical networking,同步光纤网络)。
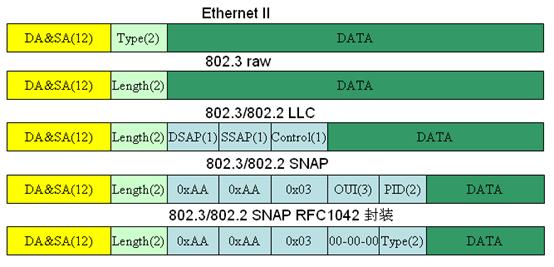
二层封装格式简析
二层封装格式,能见到的有四种,分别是TCP/IP协议使用、目前基本大一统的Ethernet II,IEEE的IEEE 802.3、802.2 LLC、802.2 SNAP,常见的封装结构为IEEE 802.3和Ethernet II帧(以太网2),之所以有两种帧封装格式,是因为有OSI七层以及TCP/IP两种模型定义了两种不同的分装格式,他们的差别主要是在帧头封装部分,具体的区别有兴趣的自行搜索。之前商定的结果是控制层面的用802.3格式封装,转发层面的用以太网2封装,但目前基本上是以太网一统天下,所以在这就不介绍802.3的相关东西了。至于什么是控制层面、转发层面,后面会有专门的章节进行阐述。除了以上的知识,还有一些扩展的信息在思科论坛的这个帖子以及这个帖子里,如果有兴趣可以看看,这里贴一段我觉得总结的比较好的话:
if you are going to look at an IPv4 or IPv6 communication, it will be practically always encapsulated into Ethernet II frames because those are the most efficient in terms of overhead. 802.3 + LLC frames are used nowadays mostly for older protocols authored by IEEE itself, such as STP/RSTP/MSTP. SNAP frames are often used for vendor-proprietary Layer2 protocols - Cisco uses it for CDP, DTP, VTP and PAgP, to name a few.
如果你观察IPV6或者IPV4的通信,它们实际上都是用以太网2进行封装的,因为从开销方面来说这是最有效率的封装方式。如今,802.3+LLC子层的帧格式绝大部分时候是出现在IEEE编写的较老的协议上,比如STP/RSTP/MSTP等协议。SNAP帧格式经常出现在厂家私有的二层协议中,比如思科用在CDP, DTP, VTP 和 PAgP等协议上。
为什么Ethernet 2 使用的更加广泛
To run TCP/IP over IEEE 802.3, the SNAP format has to be used. That requires 8 bytes of the data field to identify the kind of data the frame is carrying: three bytes for the Logical Link Control, three bytes for the SNAP header, and two bytes for the Protocol Type field. That means the data field shrinks from the standard range of 46 to 1500 bytes down to a range of 38 to 1492. This is the reason most network managers stay with Ethernet II.
在TCP/IP协议上运行IEEE802.3的封装时,必须使用SNAP格式,它需要8字节的数据字段用来标识帧所携带的数据的类型。这8个字节由,3个字节的逻辑子层控制、3字节的SNAP报头、2个字节的协议类型字段组成。这意味着能携带的数据部分将从46到1500字节,缩小到38到1492字节。数据部分缩小是绝大多数网络使用以太网2封装的原因。
以太网2帧头分析

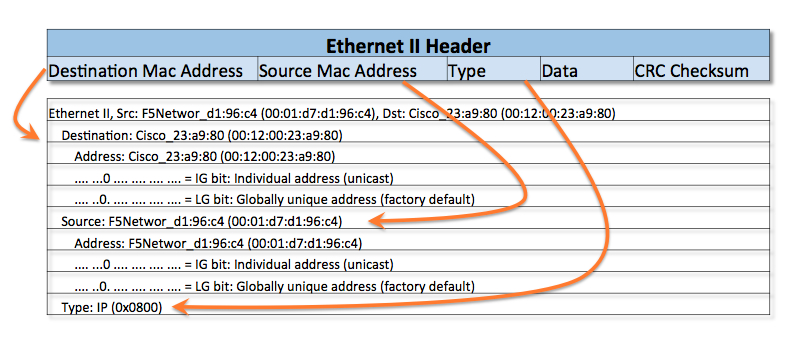
源目的MAC地址两个字段并不复杂就不多说了。
EtherType:这个字段标识由帧数据封装的上层协议,以便接收端能根据不同的上层协议用不同的协议进行处理,提高数据处理的效率。 例如,EtherType值0x0800表示该帧包含IPv4数据包。同样,以太类型0x0806表示ARP帧,0x86DD表示IPv6帧,0x8100表示存在IEEE 802.1Q标签,具体可以参考下表:
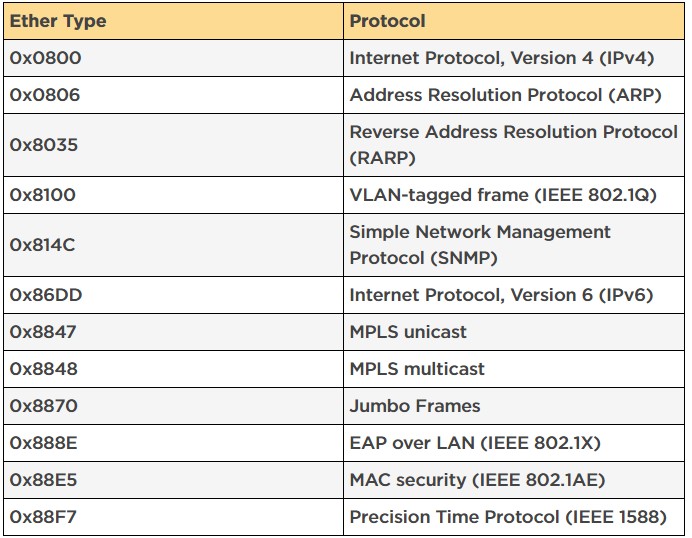
最后的CRC checksum,4字节,是表示Cyclical Redundancy Check (CRC),最后这个部分是让接收端在收到数据的时候检查收到的帧是否正确无误。如果帧校验和错,就丢弃此帧。如果校验和正确,再去判断帧的目的硬件地址是否符合自己的接收条件,看帧校验和是二层解封装后的第一步。多说两句,这个部分从严格意义上来说应该叫“FCS - Frame Check Sequence”,FCS是用算法校验数据的过程,而CRC是FCS这个校验过程可以采用的一种校验的方式,以太网用的就是CRC这种校验方式,所以在以太网里可以暂且把两者看成是同一个东西,但从概念上来讲,要知道二者是不同的。
MAC地址
所有的计算机和终端设备都需要通过网络适配器连接到局域网中,每一个适配器都有唯一的链路层地址,也被叫做 LAN 地址或者 MAC 地址,MAC 地址被设计成了扁平结构,它们不会随着所处网络的不同而发生改变。
MAC地址是烧录在Network Interface Card(网卡,NIC)里的MAC地址,所以也叫硬件地址,可以用两种不同的格式表示,分别是48位的 EUI-48 和 64 位的 EUI-64,IPV4网络中的MAC地址是EUI-48,EUI-64 主要用于 IPv6 协议。EUI-48长度为48比特,由16进制的数字组成。MAC地址是物理地址,一般情况下出厂时候就烧录到网卡中,也有一些特定的方式可以对其进行更改,但一般不推荐这么做。
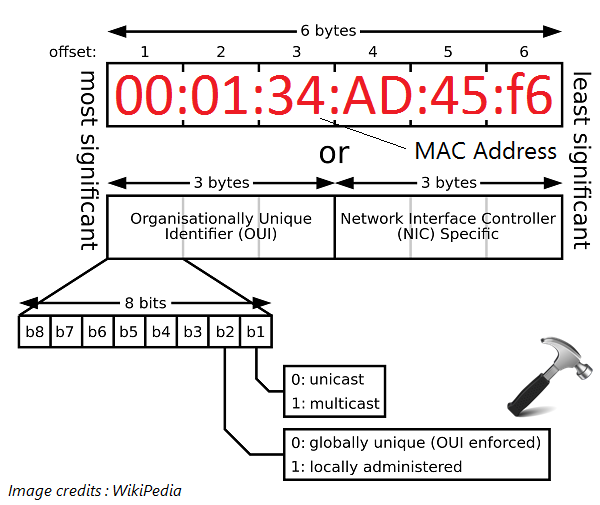
其中,0 — 24位由厂家自己分配;25 — 47位是组织唯一标志符(organizationally unique identifier,OUI)。OUI是由IEEE分配给每个组织,再由组织按高到低的顺序分配1个唯一的全局地址给每个网卡以保证不会有重复的编号。第47位是individual/Group(I/G)位,当I/G位为0的时候,我们可以设想这个地址是MAC地址的实际地址可以出现在MAC头部信息;当I/G位为1的时候,我们可以设想它为广播或多播。第46位是G/L位,也叫U/L位。当这个位为0的时候代表它是由IEEE分配的全局地址;当这个位为1的时候,代表本地管理地址 (例如在DECnet当中) 。当MAC地址为全F的时候,代表该数据是个广播。和IP地址全球统一的点分十进制记录方式不同,MAC地址有一些厂家采取自己规定的方式进行记录:

MAC地址由IEEE负责分配,厂家在生产网卡时也需要向IEEE购买MAC地址,这种由机构分发 MAC 地址段并由设备商保证地址唯一的方式就是为了保证全世界所有硬件的网络地址唯一,但是在实际操作中,全球唯一是无法保证的而且我们也并不需要地址的全球唯一,这主要因为以下两个原因:
- 在不同操作系统上,我们都可以通过软件直接修改网卡的 MAC 地址;
- 只需要保证一个局域网内的 MAC 地址不重复,网络就可以正常工作;
MAC地址和IP地址
MAC地址和IP地址除了处于层级不同(IP地址在三层,MAC地址在二层),地址的位数不同(MAC地址12位,IP地址32位),MAC地址通常无法改变IP地址可以更改,IP地址是逻辑地址MAC地址是物理地址,这几个比较显著比较好理解的区别以外,还有一个最为关键且显著的差别,也就是他们使用功能以及范围上的区别:IP地址是用于在全球互联网上通信时标识一台设备的,而MAC地址是用于在特定本地网络中标识一台设备的,通信的过程也是先根据IP地址将数据发送到IP地址所在的特定本地网络中,然后根据MAC地址在本地网络中再把数据发送给该设备。关于两者的区别,这里举两个例子,一个是身份证号码和姓名,另一个是寄快递的地址。
姓名和MAC地址类似,在一个小区或者一个村里,不管你是叫张三李四王二麻子,一说名字大家都知道这个是你,因为一个村或一个小区人不多,大家也都相互认识,重名的不多,用名字来标识一个人基本是够用的也是很精确的;但当出去旅游或办事时,范围已经扩大到了全国,这时候叫同名同姓的可能性极高,再只用名字作为标识显然是不够的,这时候就需要一个全国唯一的东西,身份证号码,来标识一个人,IP地址类似于身份证号码。
下面再说说寄快递,比如一个地址“北京市西城区玉桃园小区3号楼2门808”这个地址,前面的“北京市西城区玉桃园小区”是在全国这个大范围里定位快递应送到哪个小区,功能类似于IP地址,在全球互联网内定位数据应发送到哪个网段(小区)中,而后面的“3号楼2门808”是在特定的小区内精准定位,功能类似于MAC地址,在数据发送到特定网段(玉桃园小区)后,在该网段(该小区)内的定位由MAC地址完成,因为全国有很多小区,很多小区都有“3号楼2门808”,光靠后面的无法将货物送达,货物必须到了特定小区后,后面的楼号以及门牌号才能发挥作用。
当然上面这两个比喻只是为了方便理解他们作用范围的区别,而不是对两者完全精确的比喻,请批判的阅读这个比喻后,重新看关于MAC地址和IP地址的准确定义,才能真正明白二者的作用。
数据链路层协议:
ARP(Address Resolution Protocol )
ARP协议是一个纯二层协议,这点从抓包上能看得更清楚:
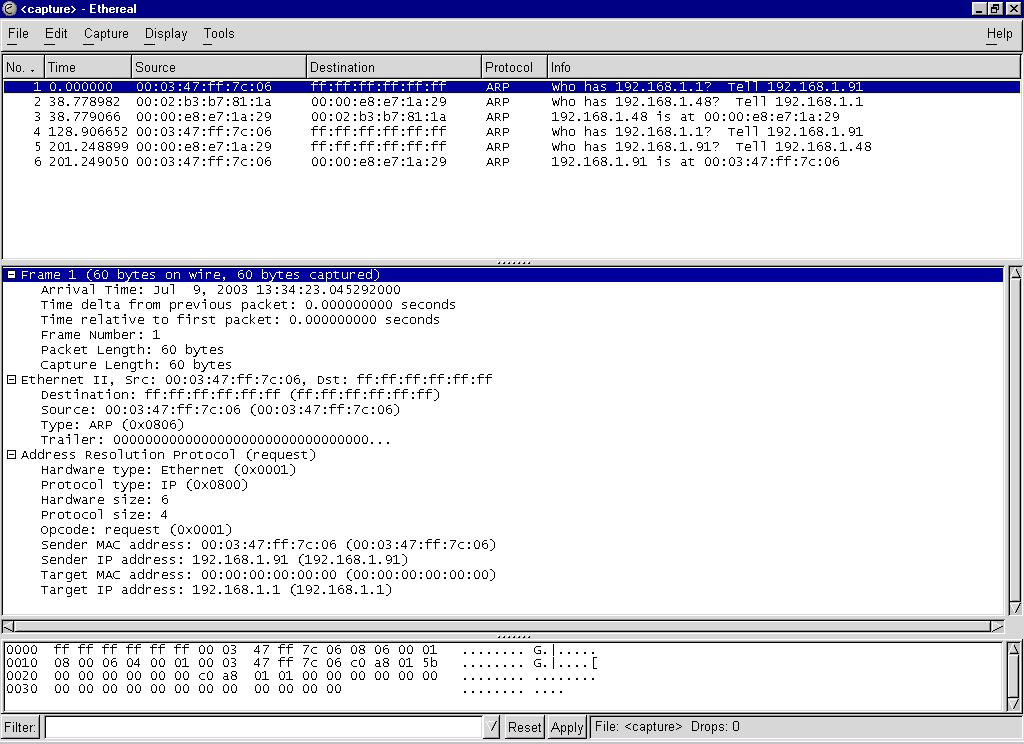
可以看到,ARP只有一层和二层两个报头,后面跟的就是ARP协议的payload,没有别的了,所以这是一个纯二层协议。
作用:
– 将IPv4 地址解析为MAC 地址
– 维护IP与MAC映射关系的缓存
ARP是为了促进IP和以太网之间的动态地址解析而开发的,现在也可以在其他第二层技术上使用。 它通过允许IP设备在本地网络上发送广播来工作,并且它请求来自同一本地网络上另一设备的带有硬件地址的响应。
ARP协议解决现网中的什么问题?
在前面的笔记中也提到过,识别、传输一个数据通信是靠:源IP地址、目的IP地址、协议、源端口地址、目的端口地址,这5个元素,其中源、目的IP地址以及协议是封装在三层的ipv4报头中的,源、目的端口是封装在二层的以太网2报头中的,必须有这几个东西,数据才能封装成帧然后转换成0101的电信号通过网线传给另一端的设备,但一般情况下,网工测试线路是否通畅采用的是ping这个工具,比如你的地址是192.168.1.2,想看看到192.168.1.3是否通畅,你都是直接输入“ping 192.168.1.3”,然后系统就会告诉你连通性,但这时候通信必须的五元组里,你只有源、目的IP地址,协议(ping是ICMP协议中的一部分)以及源MAC地址这四个元组,目的MAC地址是不知道的,如何获取目的MAC地址完成二层帧封装呢?这就需要用到ARP协议,英文翻译成中文就是地址解析协议,地址解析是将网络层地址(IP地址)解析为数据链路层地址(MAC地址)的过程。
必须注意的是,这里的ARP地址解析协议只用于解析Internet协议(IPv4)版本4中的单播地址,而IPv4下的组播地址使用直接映射方法,而IPv6使用新的邻居发现(ND)协议代替ARP,IPV4组播和IPV6中的部分会在后面的笔记中涉及到。
有两种关联IP和以太网地址的基本方法:直接映射或动态解析。但是,以太网地址长48位,而IP地址只有32位,这立即排除了直接映射的可能。
顺便提一句,ARP协议是出现时间比较早而且还在大范围使用的协议之一,RFC编号是826,发布于1982年。
ARP协议分类
1、静态映射。用命令添加静态的IP地址和MAC地址之间的映射条目,功能类似于大厦1层的索引牌。用静态映射的相对少一些。

2、动态解析。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。动态映射的应用场景比较多。功能类似于你去小红家找妹纸玩,但只知道她在哪个楼住,但不知道具体楼层门牌号,然后在楼下大喊“小红你在哪~”,她听到你喊她以后出来告诉你她具体的楼层和门牌号,比如“我在地下十八层住,大爷来玩啊”这种。
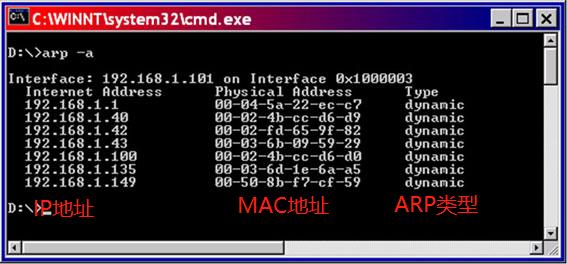
ARP表缓存查询命令
windows:arp - a
Cisco IOS:show arp

表中的**Age(min)**表示自从该ARP条目进入ARP表中以来的时间,当设备第一次收到该ARP时在ARP表项中输入该条目并启动该计时器,ARP的过期时间Nexus和普通交换机过期时间不同:
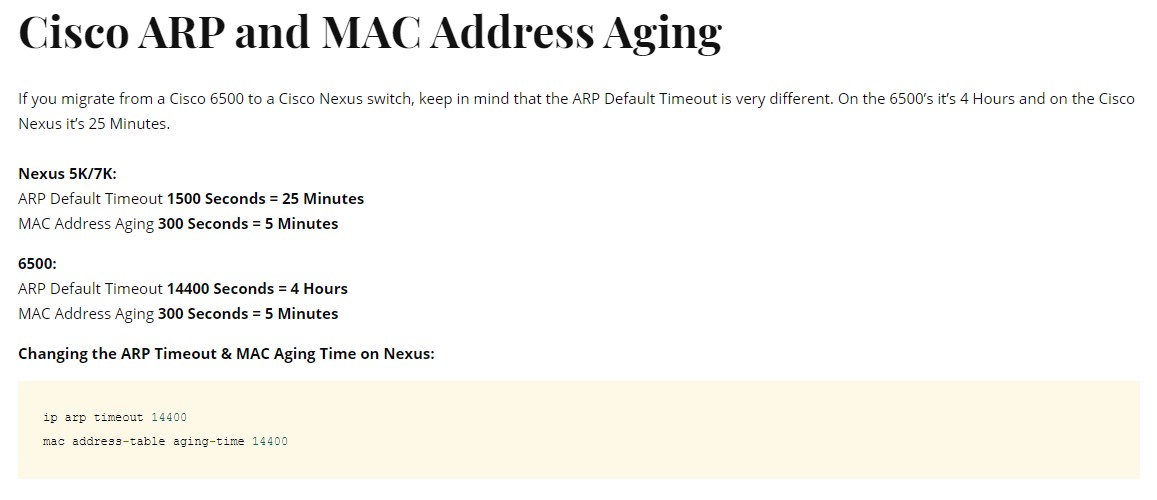
表中的ARPA是一种以太网默认的封装格式:
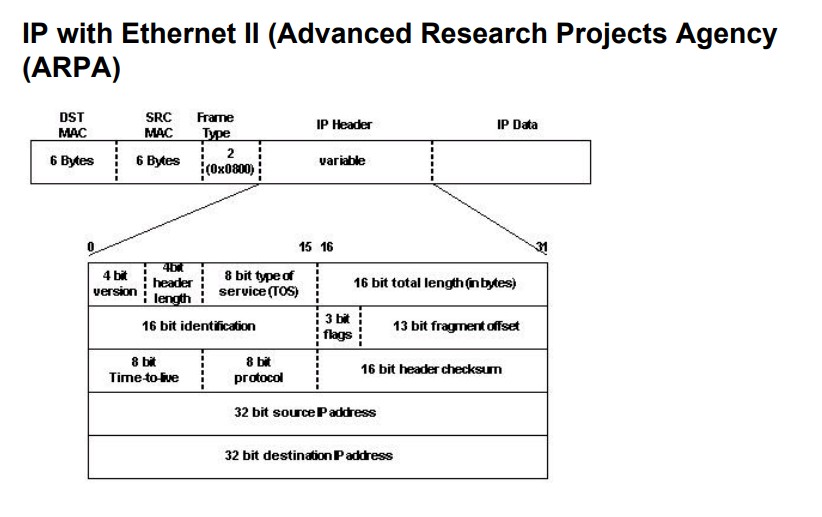
ARP封装格式

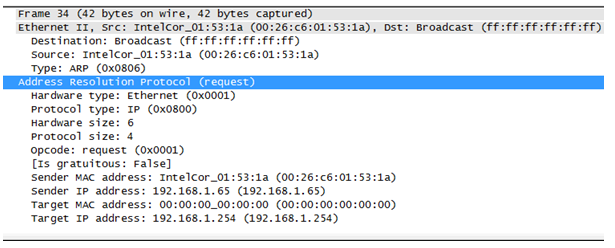
Hardware type :该字段表示网络链接协议类型。例如常用的TCP/IP中以太网表示为1,换算成16进制就是0X0001。
Protocol type:该字段表示ARP请求所针对的互联网络协议。对于IPv4,其值为0x0800。
Hardware address length:硬件地址(MAC地址)的长度(八位字节)。以太网地址长度为6。
Protocol address length:互联网络地址(IP地址)的长度(八位字节)。互联协议在PTYPE中指定。示例:IPv4地址长度为4。
Operation code:ARP request,也就是ARP请求时该字段为1,当为ARP reply,也就是ARP回复时该字段为2。
**Sender protocol address (SPA)**:Internetwork address of the sender,也就是发送设备的IP地址
**Target protocol address (TPA)**:Internetwork address of the intended receiver,也就是目标设备的IP地址。
在图中有两组MAC地址,要明白他们各自代表的是什么含义并且区分开,可以简单理解为一组是以太网2协议中的通信用MAC地址,另一组是arp协议中的请求用MAC地址:
- 从左边起算的,在ARP前边的destination address 和 source address, source address表示的是这整个的数据帧的发送者的源MAC地址,destination address表示的是整个数据帧接收者的MAC地址,这个是以太网报头中的通信用的MAC地址,这组MAC地址的目的是把ARP请求信息送到接收端。
- 而ARP段中的source hardware address根据该数据是ARP请求还是ARP回复所表示的含义不同,在ARP请求中,此字段用于指示发送请求的主机的地址。在ARP答复中,此字段用于指示请求正在寻找的主机的地址。Target hardware address含义也是有区别的,在ARP请求中,此字段为空,因为并不知道目标MAC地址才要使用ARP协议。在ARP答复中,此字段用于指示发起ARP请求的主机的地址。ARP中的这组MAC地址是为了完成请求目的MAC地址的功能的。
工作过程:
ARP is a relatively simple request-and-reply protocol. The source device broadcasts an ARP Request that’s looking for a particular device based on the device’s IP address. That device responds with its hardware address in an ARP Reply message.
ARP是一个相对来说比较简单的“请求——回应”的协议,源设备广播它的ARP请求,这个ARP请求基于目标设备的IP地址,那个有ARP请求中同样IP地址的设备将用ARP回复来告知源设备它的MAC地址。
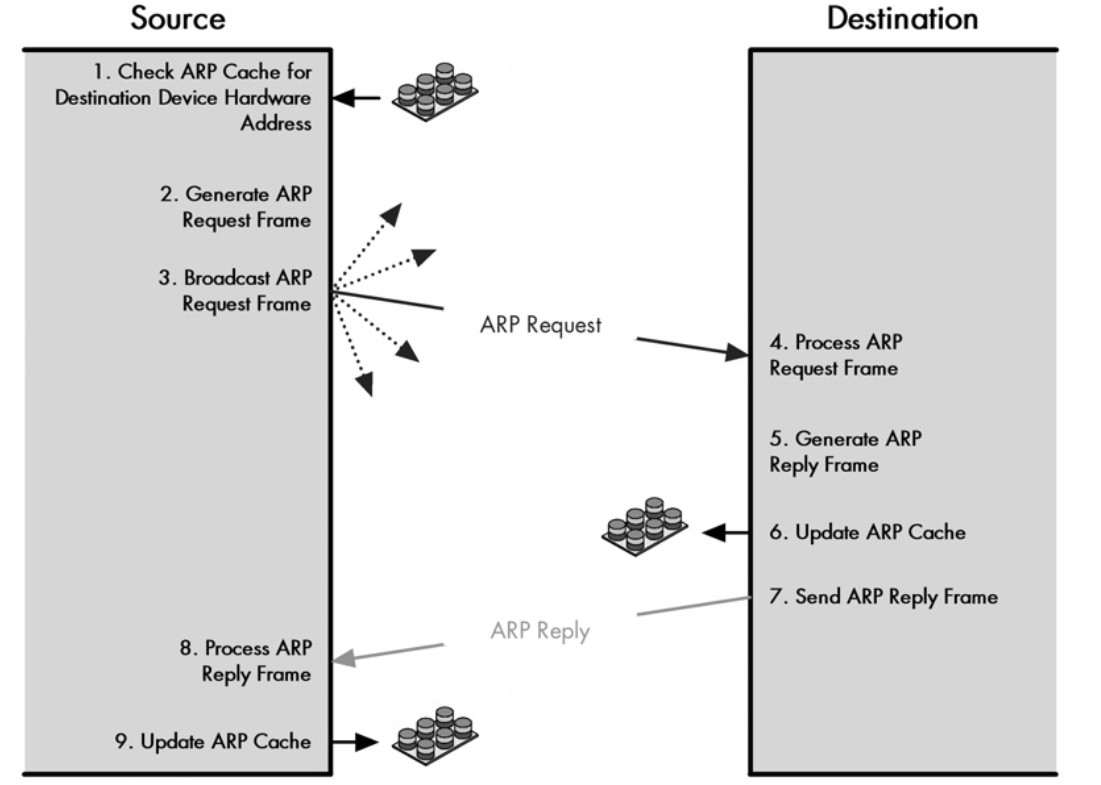
- Source Device Checks Cache The source device will first check its cache to determine if it already has a resolution of the destination device. If so, it can skip to step 9.
- Source Device Generates ARP Request Message The source device generates an ARP Request message. It puts its own data link layer address as the Sender Hardware Address and its own IP address as the Sender Protocol Address. It fills in the IP address of the destination as the Target Protocol Address. (It must leave the Target Hardware Address blank, since that it is what it is trying to determine!)
- Source Device Broadcasts ARP Request Message The source broadcasts the ARP Request message on the local network.
- Local Devices Process ARP Request Message The message is received by each device on the local network. It is processed, with each device looking for a match on the Target Protocol Address. Those that do not match will drop the message and take no further action.
- Destination Device Generates ARP Reply Message The one device whose IP address matches the contents of the Target Protocol Address of the message will generate an ARP Reply message. It takes the Sender Hardware Address and Sender Protocol Address fields from the ARP Request message and uses these as the values for the Target Hardware Address and Target Protocol Address of the reply. It then fills in its own layer 2 address as the Sender Hardware Address and its IP address as the Sender Protocol Address. Other fields are filled in, as explained in the description of the ARP message format in the following sec-tion.
- Destination Device Updates ARP Cache If the source needs to send an IP dat-agram to the destination now, it makes sense that the destination will probably need to send a response to the source at some point soon. (After all, most com-munication on a network is bidirectional.) Next, as an optimization, the desti-nation device will add an entry to its own ARP cache that contains the hardware and IP addresses of the source that sent the ARP Request. This saves the desti-nation from needing to do an unnecessary resolution cycle later on.
- Destination Device Sends ARP Reply Message The destination device sends the ARP Reply message. This reply is, however, sent unicast to the source device, because there is no need to broadcast it.
- Source Device Processes ARP Reply Message The source device processes the reply from the destination. It stores the Sender Hardware Address as the layer 2 address of the destination and uses that address for sending its IP datagram.
- Source Device Updates ARP Cache The source device uses the Sender Proto-col Address and Sender Hardware Address to update its ARP cache for use in the future when transmitting to this device.
KEY CONCEPT ARP is a relatively simple request-and-reply protocol. The source device broadcasts an ARP Request that’s looking for a particular device based on the device’s IP address. That device responds with its hardware address in an ARP Reply message.
源设备,也就是要发送数据的设备为设备A
目标设备,也就是要接收数据的设备为设备B
1、源设备A进行ARP缓存表查询。发送数据的源设备A在一开始将会对自己的ARP缓存表进行查询,看它是否有目标设备的“IP地址——MAC地址”的ARP解析结果,如果有该结果则直接跳到第九步。
2、源设备A生成ARP请求消息。当源设备A发现自身并没有对应的ARP缓存时,源设备生会成ARP请求信息,将本设备的源IP地址以及源MAC地址作为ARP请求信息的源IP地址以及源MAC地址,将目的设备B的IP地址作为目标IP地址。这个请求消息会将目标MAC地址设置为空因为A正在请求目标MAC地址。对比ARP报头格式我们可以知道,ARP封装的信息已经齐了,可以进行ARP报头的封装了。
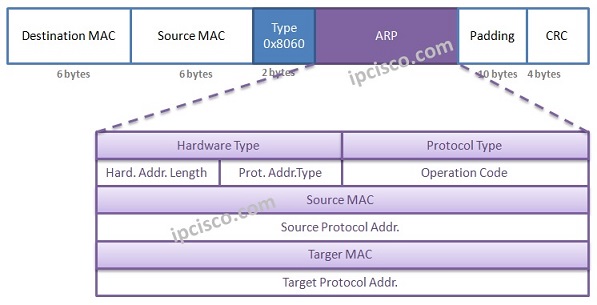
“**Sender protocol address (SPA)”是Internetwork address of the sender,也就是发送设备的IP地址,“Target protocol address (TPA)**”是Internetwork address of the intended receiver,也就是目标设备的IP地址。
3、源设备A将ARP请求信息在本网段上进行广播。
4、本网段设备对ARP请求信息进行处理。本网段所有设备将收到源设备发送的ARP的请求信息,因为ARP请求信息是个“broadcasts”,也就是广播,它所传播的范围就是在本网段,每个收到该广播的设备都会核对自身的IP地址和ARP请求信息中的“目标”是否一致,如果不一致的话将丢弃该ARP请求信息也不会有下一步的处理了。如果所请求的arp目标在不同网段,则需要用到代理ARP,在这篇笔记中暂时不涉及到。
5、目标设备B生成ARP回复信息。那个IP地址和ARP请求信息中“目标IP地址”相同的设备,将生成一个ARP回复信息,这个回复信息将使用ARP请求信息中的源IP地址和源MAC地址,并将它们作为ARP回复信息中的目的IP地址和目的MAC地址。然后将自身的IP地址作为ARP回复信息中的源IP地址,将自己的MAC地址作为源MAC地址,然后封装好ARP报头。
6、目标设备B更新自身的ARP缓存表项。如果源设备A在得知目标设备B的MAC地址后要向目标设备发送数据,目标设备B之后回复数据的时候,也是需要源设备A的MAC地址的,毕竟大多数的通信都是双向的,所以作为一个优化步骤,目标设备B会将收到的ARP请求中的,源设备A的“IP地址——MAC地址”对应的ARP条目放入缓存中,以便于以后使用,因为缓存中有源设备A的ARP条目后,再通信的时候就不用进行ARP请求而可以直接使用了。
7、目标设备B发送APR回复消息。目标设备B发送ARP回复信息,这个ARP回复信息是基于单播的,因为已经知道源设备A的IP地址和MAC地址,无需用广播回复。
8、源设备A处理ARP回复消息。源设备处理A从目标设备B处收到的ARP回复消息,源设备A使用ARP中的发件人硬件地址(也就是ARP报头中的Target hardware address)作为发送给目标设备B的以太网报头中的目的MAC地址。
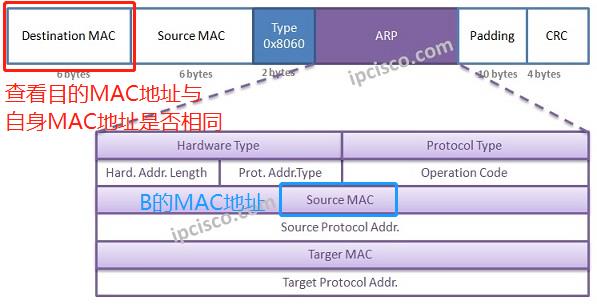
9、源设备A更新ARP缓存。源设备A用目标设备的IP地址及MAC地址更新ARP表项,以便未来使用。
示例分析:
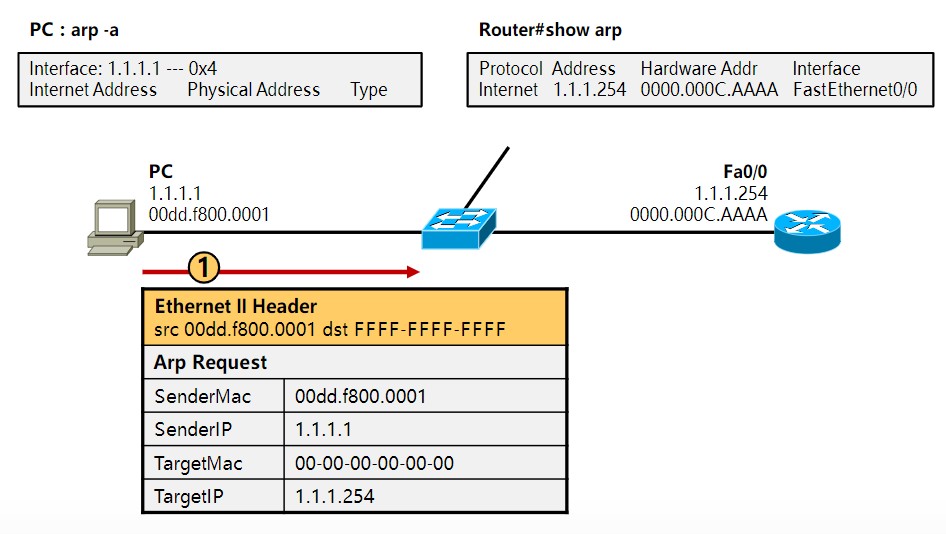
当PC想和1.1.1.254通信,通过上面ARP的9步我们知道,它先要查询本地的ARP表中是否有相关条目,这时在PC上是用arp -a这个命令在CMD中查询发现,PC并没有该条目所以要发送ARP请求来获知1.1.1.254的MAC地址。先看二层封装,由于ARP请求是一个广播,所以源MAC地址是自身的MAC地址,目的MAC地址则为全F,表示这是一个广播;然后看ARP报头封装,源MAC地址和源IP地址都是自身的地址不多说,目标MAC地址为全0,因为前面也说了,发送ARP请求就是为了获取ARP缓存,目标IP地址就是1.1.1.254。
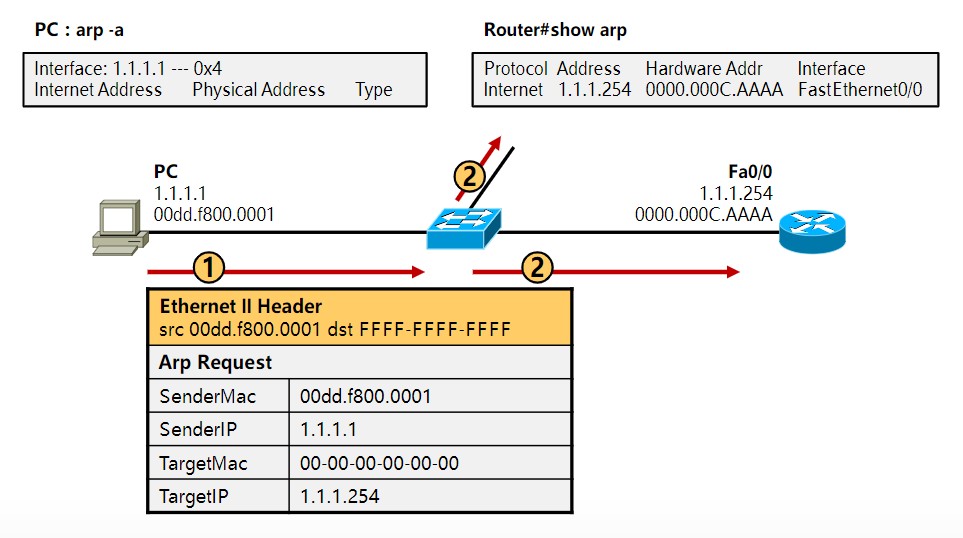
当ARP请求到达交换机时,交换机会将该广播从除了接收接口以外的其他所有接口发送出去,每个收到该广播的设备都会核对自身的IP地址和ARP请求信息中的“目标”是否一致,如果不一致的话将丢弃该ARP请求信息也不会有下一步的处理。
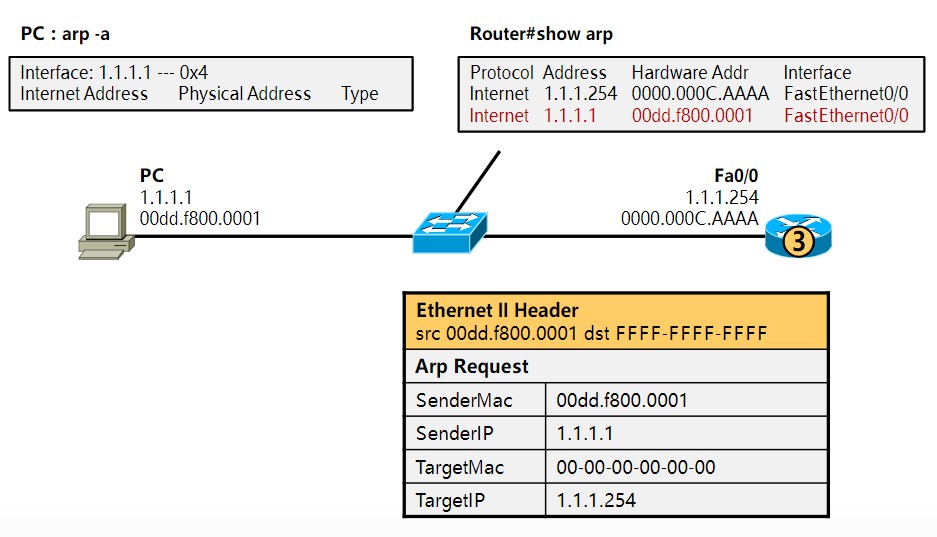
当路由器收到该ARP请求时,将0101的电信号还原成帧,然后解二层封装,发现目标MAC地址为全F,也就是一个广播,因为广播是发送给全网段的,所以也就是发给自己的于是进一步解封装到ARP报头,发现Target IP和自身F0/0接口一致,于是对该请求进行处理。路由器将ARP请求信息中的源IP地址1.1.1.1,与源MAC地址00dd.f800.0001的对应条目放入本地ARP缓存中。
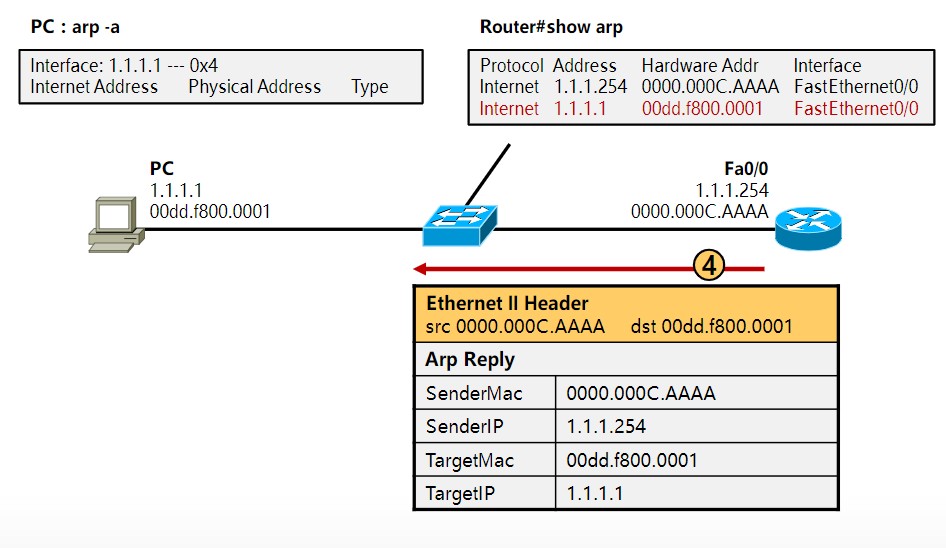
路由器生成回复ARP请求的单播数据,二层封装的源MAC地址为路由器F0/0的MAC地址,0000.000C.AAAA,目的MAC地址为PC的MAC地址00dd.f800.0001,PC的MAC地址是从PC的ARP报头中获得的,ARP报头封装的源MAC地址与源IP地址为F0/0口的相应地址,目标IP地址与目标MAC地址为PC的相应地址。
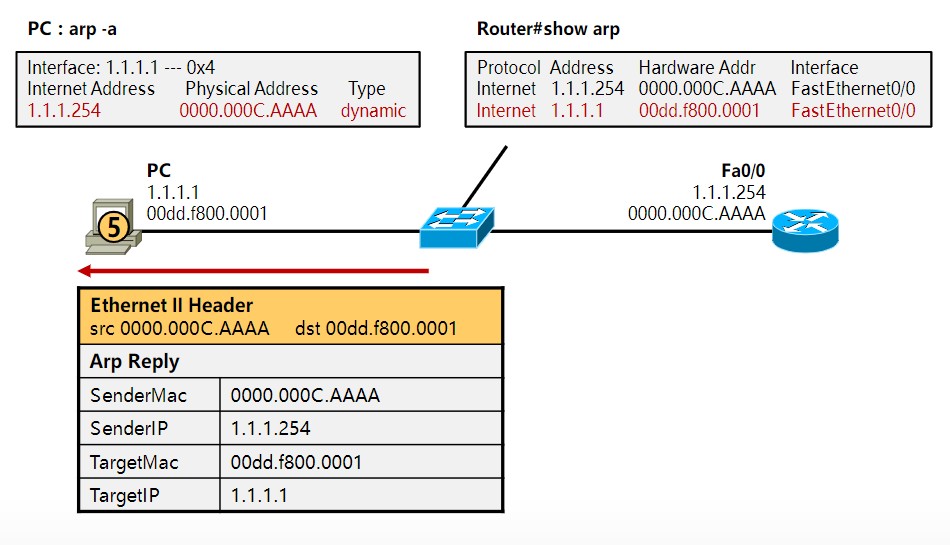
ARP回复信息经交换机发送给PC后,PC对回复的信息还原成帧后查看目标MAC地址发现是发送给自己的,然后进一步对数据进行解封装,发现是arp 回复消息,然后将1.1.1.254与它的对应MAC地址条目放入arp缓存表,以后再向1.1.1.254发送数据的时候,就不用再通过arp请求MAC地址了。
ARP缓存在思科设备上的默认过期时间是1500秒,也就是25分钟,这个数字可以自行设置,设置范围为60 — 28800秒之间。
ARP抓包:
arp请求信息
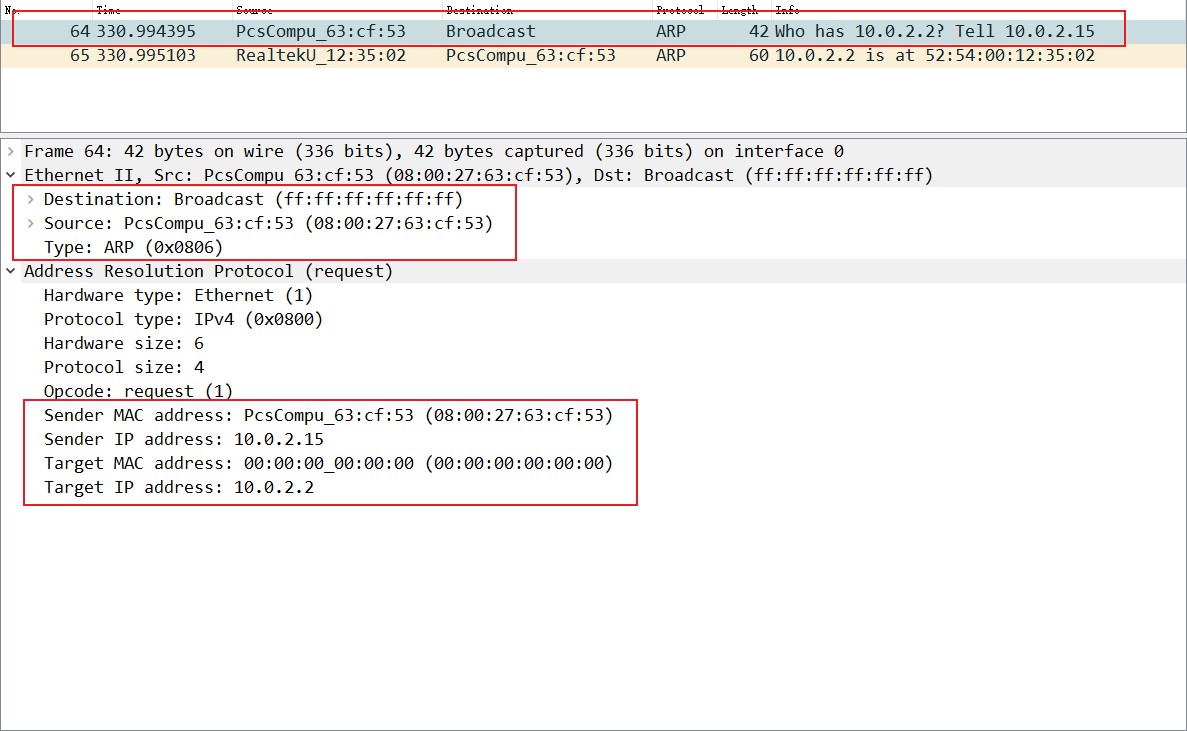
arp回复信息
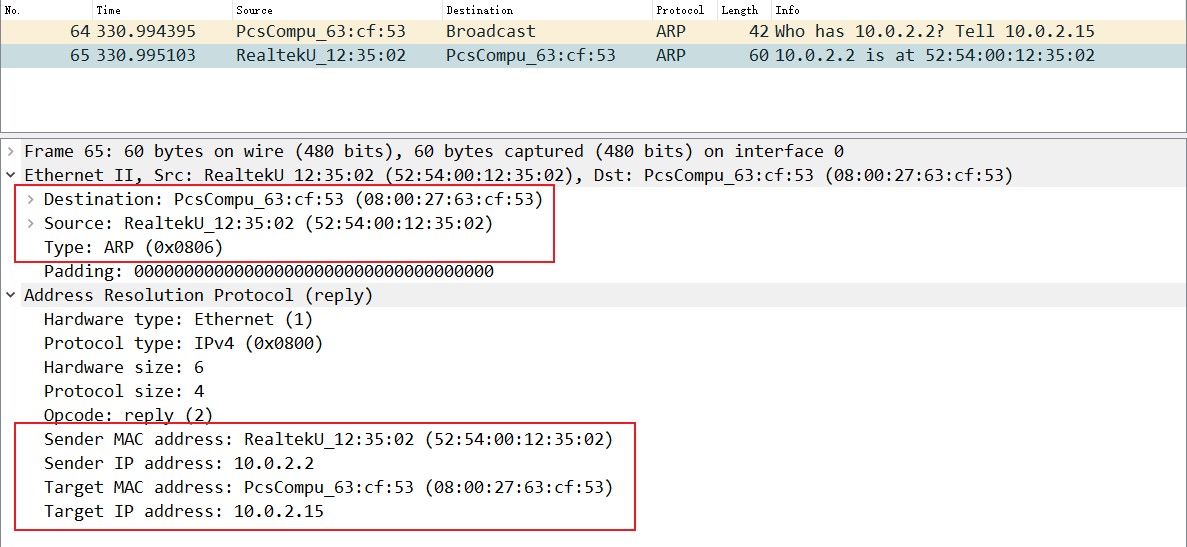
代理ARP(Proxy ARP)
Proxy ARP is a technique by which a proxy device on a given network answers the ARP queries for an IP address that is not on that network. The proxy is aware of the location of the traffic’s destination, and offers its own MAC address as the (ostensibly final) destination.
代理ARP是一种技术,这种技术使得在特定网段上的代理设备回答不在该网段上的IP地址的ARP查询。代理设备知道如何前往数据的目的地址,并且将代理设备自身的MAC地址提供给ARP的查询者。
简单来说,当ARP请求目标跨网段时,网关设备收到此ARP请求,会用自己的MAC地址返回给请求者,这便是代理ARP(Proxy ARP)。代理ARP本质上来说是一个“善意的欺骗”,是一个“错位”的映射,实际网络中,代理ARP由网络中的网关设备来执行,包括路由器、多层交换机、无线路由器、防火墙等设备。并且,网关即便有代理ARP功能,也未必一定执行,还必须满足两个条件:①网关已经开启代理ARP功能;②网关有目标的路由信息。思科设备默认开启代理ARP功能,不用再手动进行开启,如果被关闭的话在接口上输入ip proxy-arp将接口的代理ARP打开。
数据链路层在数据传输时的步骤:
在发送端,数据链路层收到上层传过来的数据后,打上数据链路层的报头,然后发送给物理层。在接收端,数据链路层收到下层发过来的数据后,对二层报头进行解封装,首先查看二层的FCS部分校验是否正确,如果正确再查看报头中的目的MAC地址和本地的MAC地址是否相符,如果相符就根据二层报头中的EtherType将数据发给上层的相应协议继续处理,如果目的MAC地址和本机MAC地址不相符就将数据丢弃。
物理层(Physical Layer)
The physical layer contains the protocols relating to the physical medium on which TCP/IP will be communicating. Officially, the protocols of this layer fall within four categories that together describe all aspects of physical media:
Electrical/optical protocols describe signal characteristics such as voltage or photonic levels, bit timing, encoding, and signal shape.
Mechanical protocols are specifications such as the dimensions of a connector or the metallic makeup of a wire.
Functional protocols describe what something does. For example, “Request to Send” is the functional description of pin 4 of an EIA-232-D connector.
Procedural protocols describe how something is done. For example, a binary 1 is represented on an EIA-232-D lead as a voltage more negative than 3 volts.
——Routing TCP/IP, Volume I
物理层包含那些和物理传输介质相关的协议,定义了电压、数据传输率、最大传输距离等参数,官方规定了四类属性来描述物理层的各个方面:
电气/光学协议,描述了信号特征,例如电压或光子电平,位时序,编码和信号形状。
机械协议,规定。例如规定了连接器的尺寸或电线的金属外观。
功能协议描述了某些功能。 例如,“请求发送”是EIA-232-D连接器的引脚4的功能描述。
过程协议描述了如何完成某件事。 例如,二进制文件1在EIA-232-D引线上表示为比3伏更负的电压。
简单来说,物理层在传输中完成的动作就是在发送端将二层数字帧转换成电磁脉冲,在不同的传输介质中,转换的结果不同,如果是在光纤中传输,也就是将0101的数字信号转换为光信号然后传输,如果是在铜缆中就是转换成高低电平然后传输,在接收端完成的动作就是将电磁信号还原成帧然后交给上层处理。
工作在物理层的设备有:中继器,常规集线器和收发器。

引用文章:
Understanding TCP Sequence and Acknowledgment Numbers
Routing TCP/IP, Volume I
数据通信与联网技术
图解TCPIP
TCP Windows and Window Scaling
TCP - Interface MTU VS. IP MTU
Long Fat Network (LFN) and TCP
What’s the use of an acknowledgement number without the ACK flag set?
localhost、127.0.0.1 和 本机IP 三者的区别?
IP Address Version 4 (IPv4) 網際網路協定位址
TCP/IP 协议到底在讲什么TCP/IP 协议到底在讲什么
Working of Traceroute using Wireshark
What is the Difference Between Ethernet II and IEEE 802.3
TCP分段与IP分片
IP FRAGMENTATION IN WIRESHARK (1)
 wechat
wechat alipay
alipay