14、BGP
写在前面
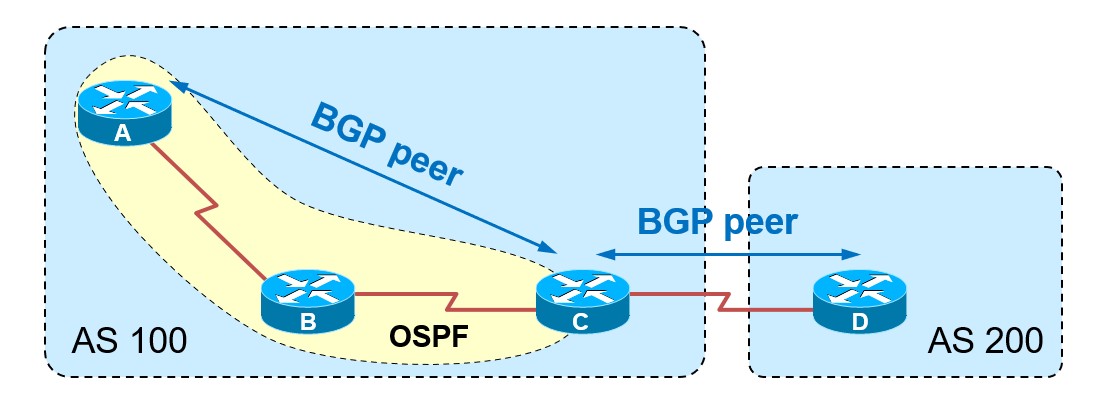
学习BGP这部分知识的时候,一定不要将之前路由协议的经验或概念,套到BGP上,因为BGP和他们有非常大的区别,因为之前接触的RIP,OSPF,EIGRP等等路由协议都是IGP(Interior Gateway Protocol)也就是内部网关协议,而BGP是EGP(Exterior Gateway Protocol)也就是外部网关协议,内\外部网关协议从根本上有很多不同。
本笔记大部分引用自红茶三杯的BGP技术笔记,基于自己的理解进行了小幅度添加及修改。
协议概述
存在意义
无需BGP的场景
在常见的小型或需求不高的企业网中,BGP存在的意义不大,比如以下的三个场景.
场景1:
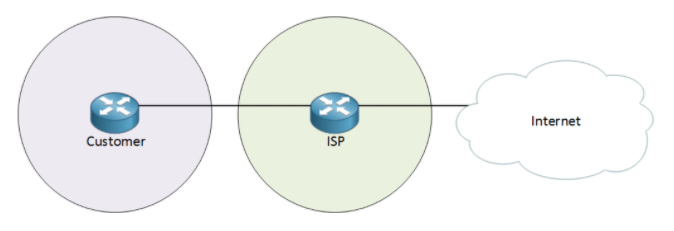
客户网络只有一台路由器的情况下,直接用默认路由指向运营商提供的公网IP地址A.B.C.D即可,IP route 0.0.0.0 0.0.0.0 A.B.C.D,网络内私网地址设备要访问互联网的话需要在出口路由器上做PAT\NAT,将私网地址转换成公网地址.所以这种情况下并不需要BGP就能满足用户需求.
场景2:
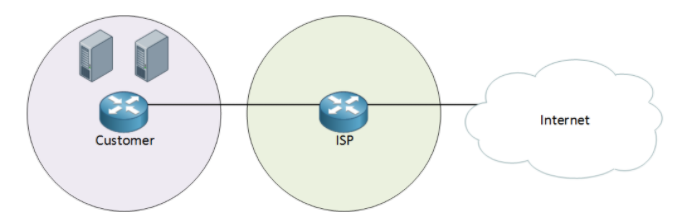
这种场景下,客户不只有一台路由器,还有几台服务器要接入互联网提供服务,这些服务器可能提供邮件或网页服务.这种情况下,需要用端口转发技术将正确的端口和这些服务器对应起来,因此这种情况下不需要用BGP也能够满足用户需求.
场景3:
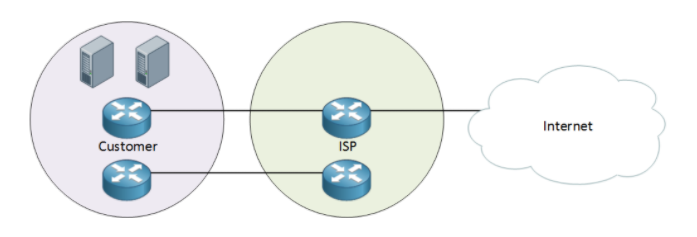
如果在之前场景中加上冗余需求呢?由于用户的服务器对外提供服务,只有一台路由器连接到ISP运营商可能会出现单点故障,也就是说一旦这台对外提供网络的服务器挂掉,整网就瘫痪了,服务器也无法对外提供服务.所以这时需要一个冗余路由器一起提供互联网连接,即使有一台路由器出现故障,另一台路由器可以顺利接替,大体配置方式如下:
- 为主路路线配置一条metric值较低的静态路由;
- 为备用路线配置一条metric值较高的静态路由;
主用线路由于metric值低,所以优先走主用路线,当主用路线挂掉以后会启用备用路线,如果需要主备用路线实现负载均衡则将两条线路的metric配置成相同即可,每条线路的流量会大致为50%,这种情况下也无需BGP。
需要BPG的场景
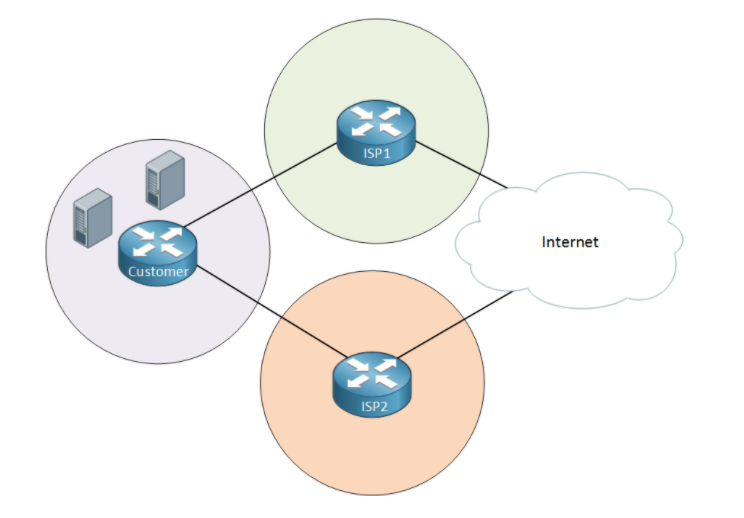
在上面的拓扑中,如果两条线路的负载均衡需求为80%和20%呢?显然这种场景下就必须BGP才能胜任了。
现在来看一个更复杂一点的场景,这种情况下,出口路由器需要连接两个不同的ISP运营商,以防在一个运营商挂掉的情况下,整网无法对外提供服务.但此时又遇到一个问题,由于我有两个ISP运营商提供服务,两个ISP都会给我属于他们的公网地址,如果我用了ISP1提供的地址,那么如果属于ISP1的这条链路出现问题,网络还是会断开连接,这时候我们就不能使用运营商所提供的公网地址了,而要使用我们自己从IANA(Internet Assigned Numbers Authority,互联网地址分配机构)申请到的地址,我们把从IANA申请到的地址告诉两家运营商,使用BGP和运营商进行连接并宣告申请到的地址进BGP协议。
除了上面的场景,其他使用BGP的理由主要如下:
大量路由需要承载的情况,只有BGP能胜任,IGP能容纳的路由条目以千条为单位,但BGP是以万条为单位起算的,一两百万条BGP路由条目的路由器也不在少数;
支持MPLS/VPN的应用,传递客户VPN路由;
策略能力强,可以很好的实现路由策略与数据控制。
基本概念
IGP&EGP
定义
- IGP(Interior Gateway Protocol)
IGP,内部网关协议,用来在Autonomous System内部的网关间交换路由信息.常见协议有OSPF,EIGRP,ISIS。
- EGP(Exterior Gateway Protocol)
EGP,外部网关协议,用来在Autonomous System之间交换路由信息.目前在用的EGP协议只有BGP一个协议。
AS是什么
An autonomous system (AS) is a collection of connected Internet Protocol (IP) routing prefixes under the control of one or more network operators on behalf of a single administrative entity or domain that presents a common, clearly defined routing policy to the internet. ——维基百科
维基的定义比较晦涩难懂,直译就是说,由一个或多个网络运营商代表单一行政实体或域控制下的连接的互联网协议(IP)路由前缀的集合,它向互联网提出一个共同的、明确定义的路由策略。
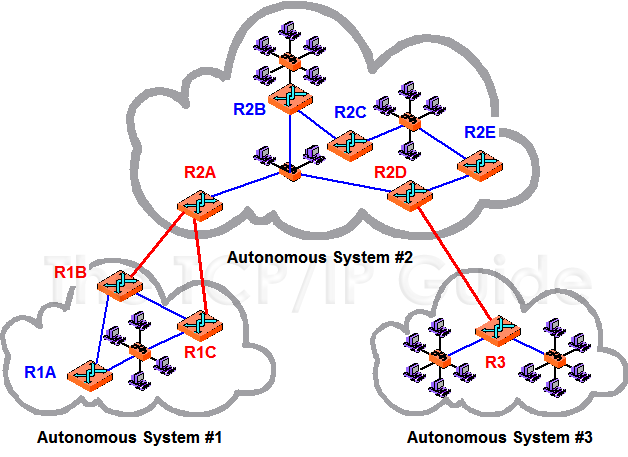
上面这个图能更直观的表现出什么叫一个AS,简单的说就是配置在同一个AS号码(和EIGRP的AS不同)下,自己可管理的所有设备组成的一个较大的逻辑区域。一个AS中必须包含最少一台运行BGP的路由器。
两者区别
IGP在AS内部发挥作用,它们的作用就是在AS内部为如何去往目的网段找到最短路径;EGP在AS之间发挥作用。为什么除了IGP以外还要搞出来一个BGP,简单理解就是因为IGP协议能够处理的路由条目不多,没法满足大批量路由的需要,比如有些路由器要处理一两百万条路由,一般的IGP没法胜任,路由条目在一万条左右就已经差不多了。
AS号
最开始的时候,AS号长度为2字节,也就是16比特,它的范围是1-65535,和IP地址一样,AS号也有公有和私有之分,1-64511是公有AS号,由IANA规定并出售,64512-65535是私有AS号,可以随意使用。由于互联网持续扩大,原有的65535个AS号已经逐渐用完,所以在RFC4893中将2字节(16比特)的AS号扩展为4字节(32比特),共有4294967295个AS号,和原有的65535个AS号相比,有了很大的提升,扩展的AS号中,4,200,000,000–4,294,967,294是私有AS号。00–4,294,967,294
可以通过CIDR Report查询AS号目前都被哪个运营商使用以及目前的前缀、邻居等信息。在使用AS号的时候必须使用由IANA所分配的AS号或私有AS号,胡乱使用其他机构的AS号可能导致互联网面临毁灭性的问题。
Looking Glass Servers
Looking Glass servers are computers on the Internet running one of a variety of publicly available Looking Glass software implementations. A Looking Glass server (or LG server) is accessed remotely for the purpose of viewing routing information. Essentially, the server acts as a limited, read-only portal to routers of whatever organization is running the LG server. ——维基百科
Looking Glass 服务器是一些部署在互联网上安装了Looking Glass软件的计算机,Looking Glass软件能让你远程登陆,运行一些基本的命令并查看关于BGP的相关信息,可以在该页面找到分布在全球的Looking Glass 服务器。
这个服务器的作用是什么呢?主要是用来方便排错。比如说运营商有很多那个边缘设备(可以简单的把边缘设备理解成在AS最边界的设备),跟别的运营商对接的peer邻居设备去收全球的路由表,有时候你会发现,你运行BGP的线路中突然有一个业务突然不通或某个网段好像突然不通了,但是为什么呢你也不知道,因为你不知道互联网上到这个网段的路径到底通不通,到底是那边的网络出了问题还是你这边的网络出了问题,这时候你可以用looking glass服务器去查他那个在互联网上他到底有没有问题,如果在他原本在互联网上就有问题的话,那就说明问题不在你这边,能够方便确定问题到底出在哪端。为什么你不知道到底是别人那边出了问题还是你这边出了问题呢?因为BGP是一个距离矢量协议,和之前的RIP有一些相通之处,都是基于传闻的协议,并不知道整个网络的情况。
BGP Peer&Speaker
运行了BGP协议的路由器被称为BGP Speaker,这里可以将BGP协议理解为一种语言,当一个路由器运行BGP协议时,相当于它说了BGP这种语言,所以将运行BGP的路由器称作BGP Speaker;当一个BGP Speaker和另一个BGP Speaker建立了一条基于TCP的BGP连接后,称两者为BGP Peer,直译成中文就是BGP 对等体,说白了就是在BGP协议中换了一种称呼两者为邻居的方式,不说他们是邻居了,而说他们是对等体。
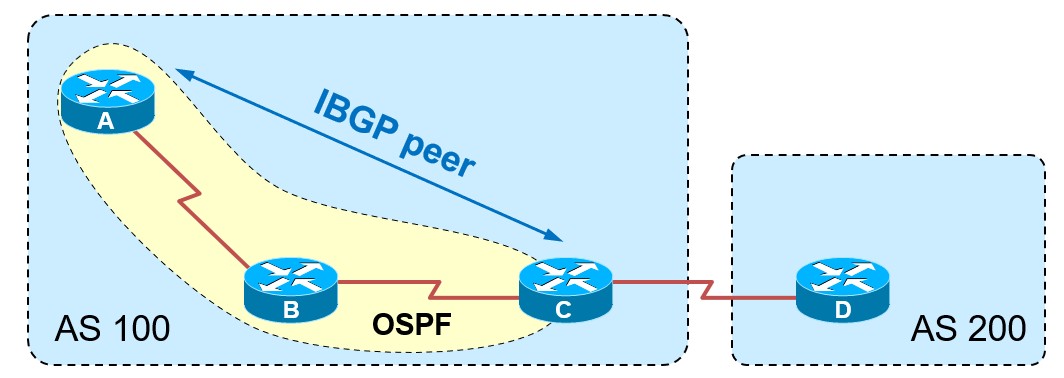
IBGP
IBGP就是Internal BGP,翻译成中文就是内部BGP,用来连接内部对等体(Peer),在同一个自治系统(AS)内运行BGP的路由器之间,是IBGP Peer,也就是IBGP邻居,在配置IBGP邻居时,推荐用loopback地址建立邻居关系。建立IBGP邻居要满足以下几个条件:
- AS号相同
- IBGP邻居之间建立TCP会话
EBGP
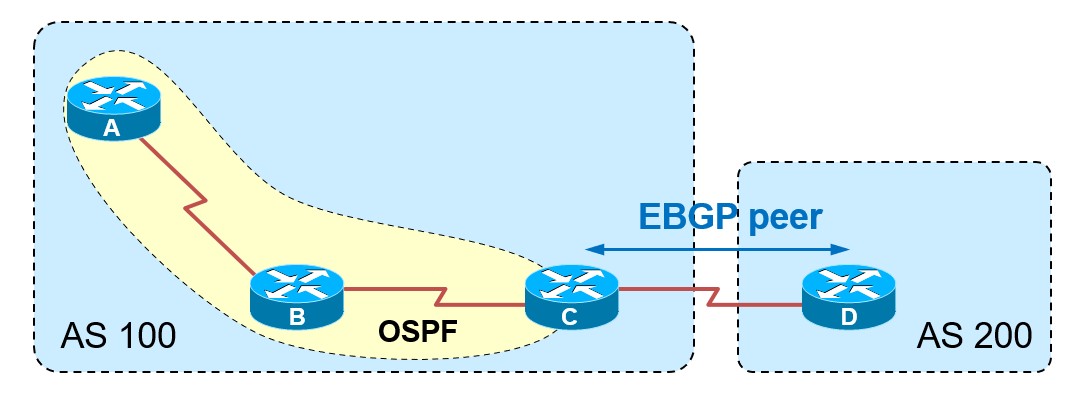
EBGP就是External BGP,翻译成中文就是外部BGP,用来连接外部,属于不同AS的路由器,不同的自治系统(AS)之间运行BGP的路由器之间,是EBGP Peer,也就是EBGP邻居,建立EBGP邻居时,推荐使用直连的IP地址建立邻居关系。建立EBGP邻居要满足以下几个条件:
EBGP之间AS号不同
EBGP邻居之间建立TCP会话
Neighbor中指定的地址要可达
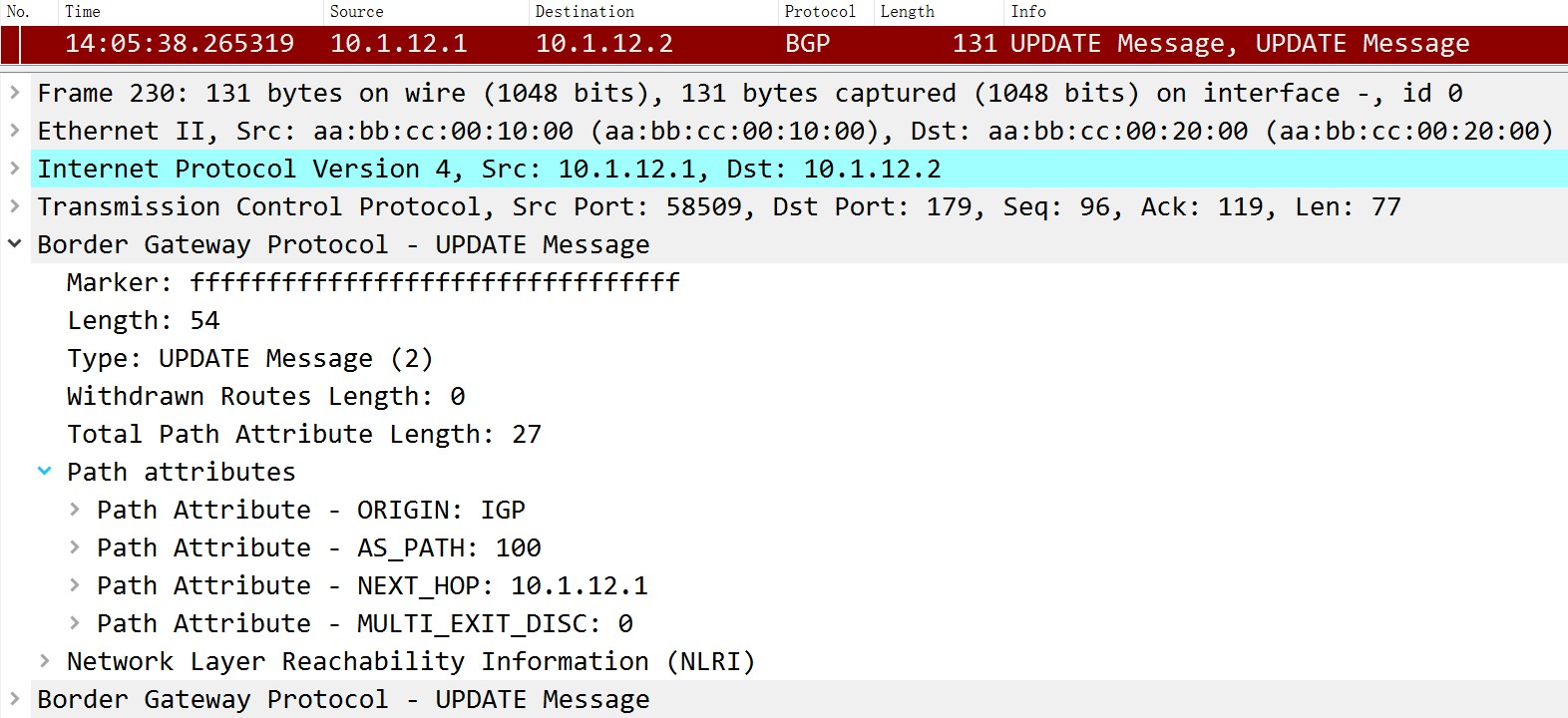
NLRI
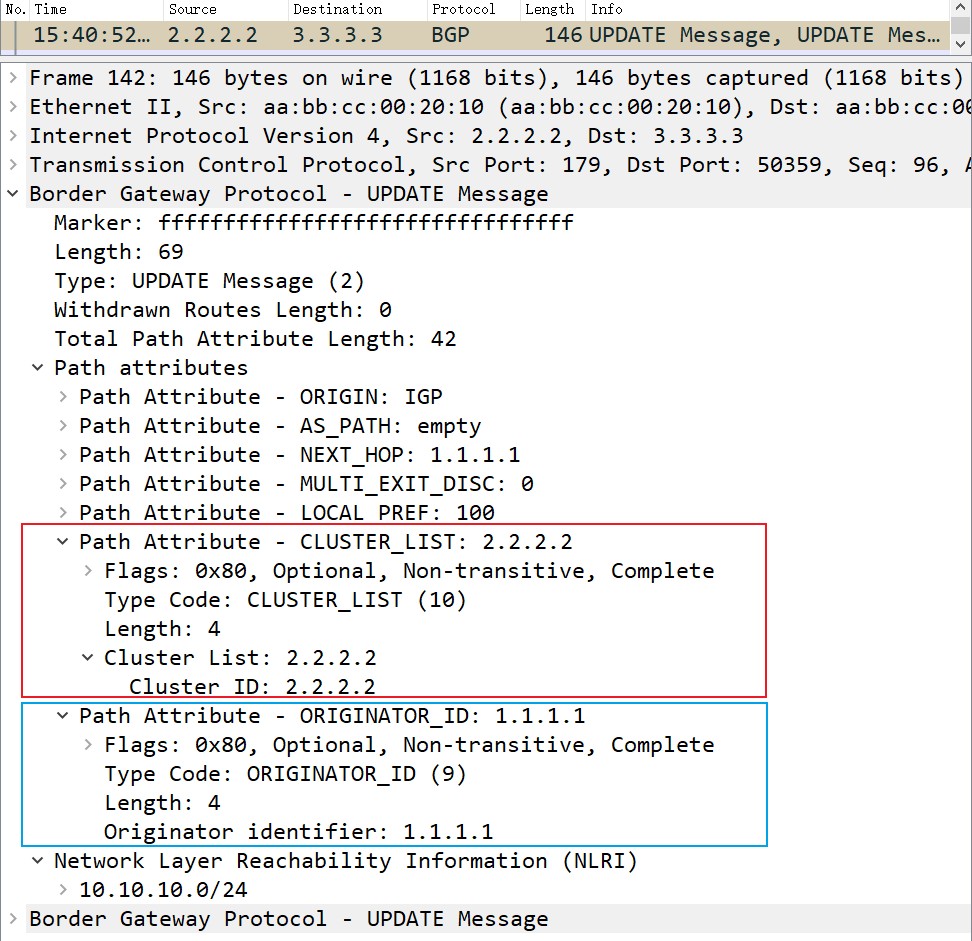
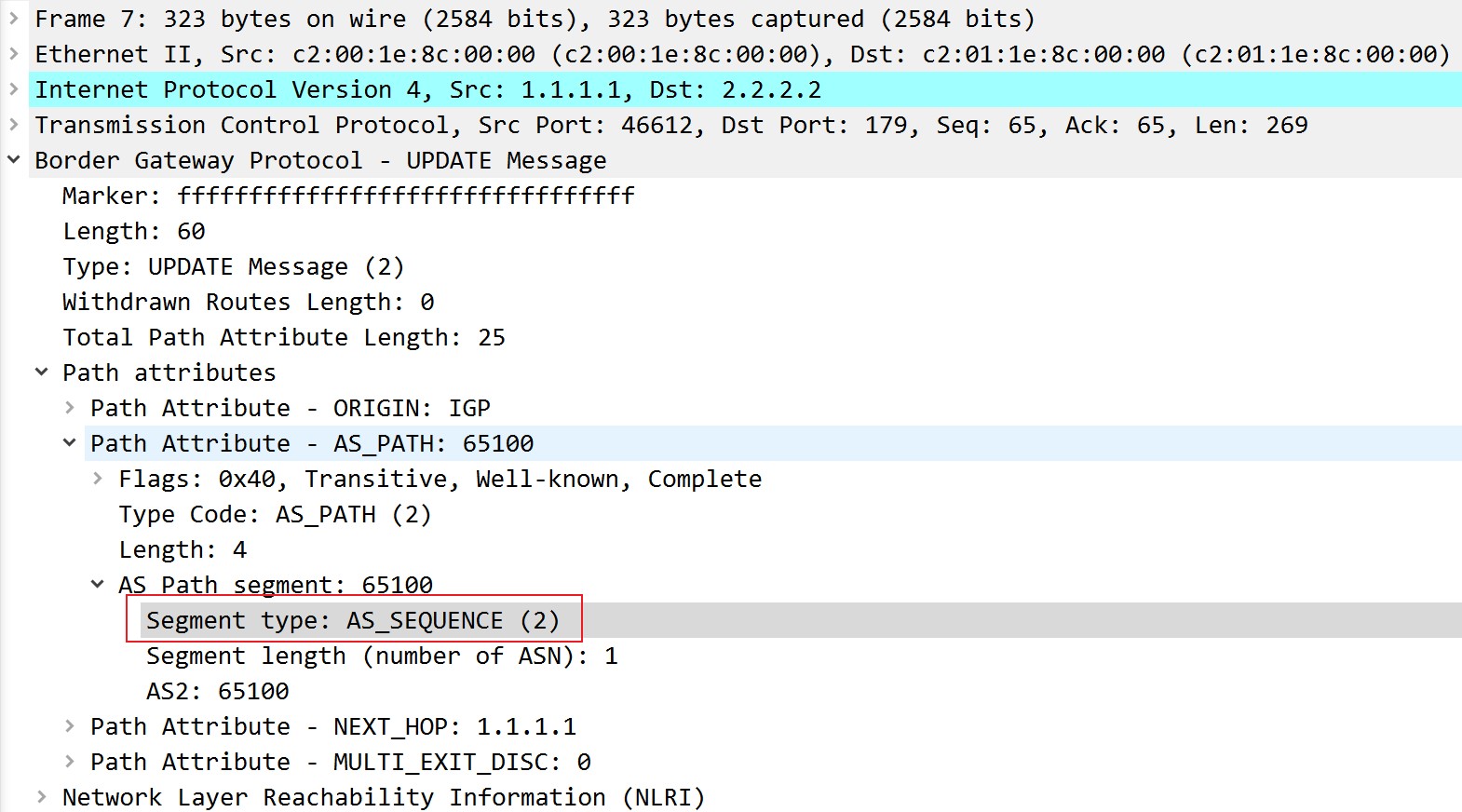
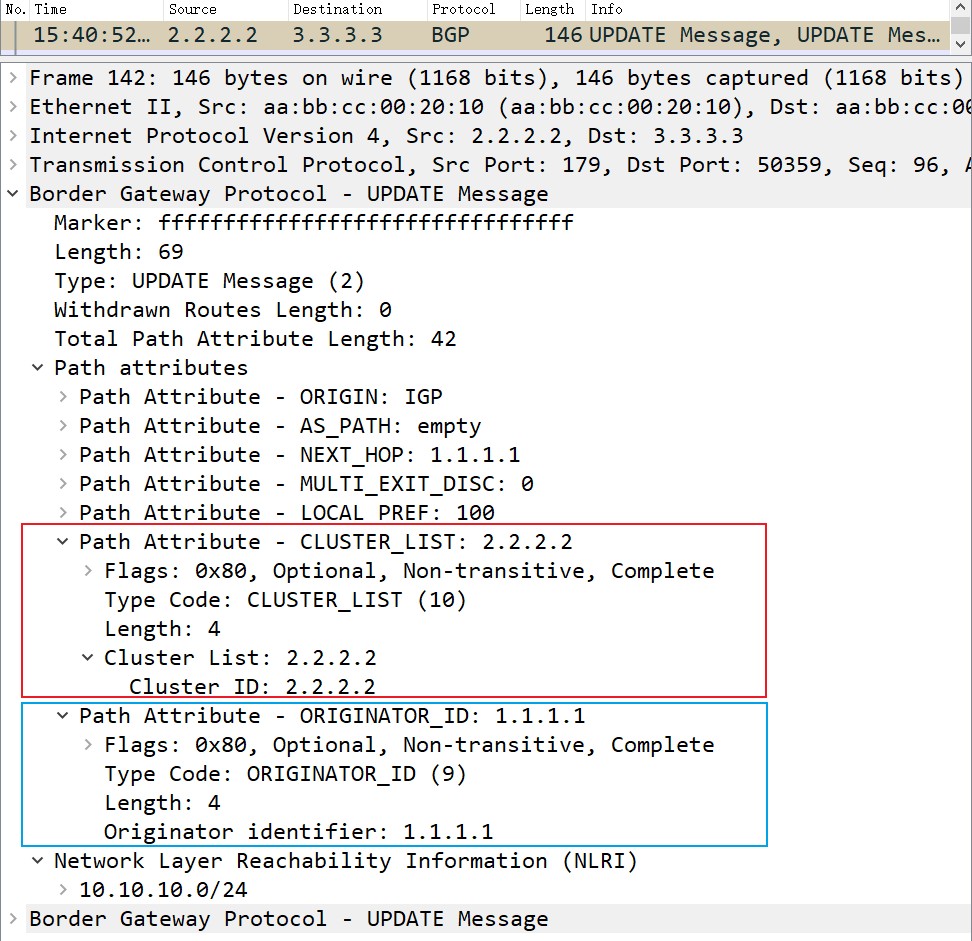
NLRI的全称是Network Layer Reachability Information,直译成中文是网络层可达信息,简单来说是BGP的网络前缀,抓包如下:
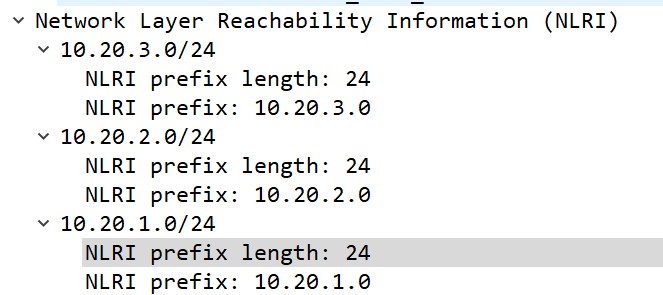
但问了个厂家的朋友说,NLRI其实是带着路径属性的前缀,不过抓包中并没在一起。
AFI\SAFI
Address family identifier is shared among the BGP peers during the BGP OPEN message as a part of BGP’s Multiprotocol capabilities extension. It is used to describe the network layer protocol associated with the network addresses that follow it during the BGP UPDATE message with the NLRI.
Subsequent Address family identifier provided additional information about the type of NLRI being advertised.
AFI是BGP的OPEN(在BGP邻居之间传递Open报文)报文里多协议能力扩展中的一部分,AFI用来描述BGP的Update报文中与NLRI相关的网络地址的网络层协议。
SAFI提供了对外宣告的NLRI的额外信息。
BGP uses TCP as its transport protocol. AFI means Address Family Indicator and SAFI is the Subsequent Address Family Indicator.
They are used in the Multiprotocol Extensions to BGP and are exchanged during neighbor capability exchange during the process for loading the peers. They basically tell the remote peer what Address family (IPv4, IPv6, VPNv4, VPNv6) and what specific sub address family (Multicast, unicast) the local BGP router will transport routes for.
This allows BGP to not only carry IPv4 prefixes but IPv6, VPN and to carry multicast and unicast routing information.
BGP在传输层使用TCP协议,AFI全称是Address Family Indicator,SAFI的全称是Subsequent Address Family Indicator.
这两个概念是在BGP中用来扩展多协议支持的,在邻居建立过程中互相交换,告诉邻居使用什么地址簇(IPv4、IPv6、VPNv4、VPNv6)以及本地BGP路由器将传输哪些特定的地址簇(组播、单播)。
这使得BGP不仅可以传输IPV4前缀,还可以传输IPV6、VPN等其他前缀的路由,还可以传输单播、组播的路由信息。
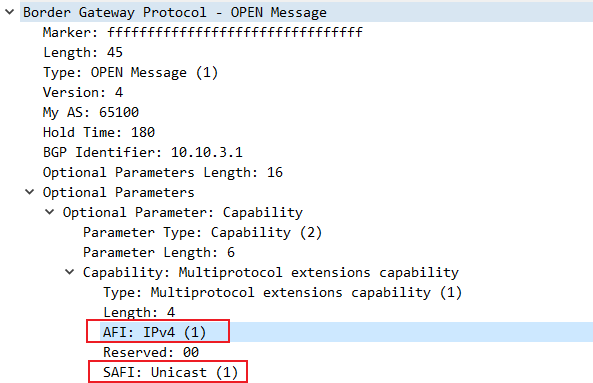
The following list shows all possible AFI and SAFI combinations:
- AFI=1, SAFI=1, IPv4 unicast
- AFI=1, SAFI=2, IPv4 multicast
- AFI=1, SAFI=128, L3VPN IPv4 unicast
- AFI=1, SAFI=129, L3VPN IPv4 multicast
- AFI=2, SAFI=1, IPv6 unicast
- AFI=2, SAFI=2, IPv6 multicast
- AFI=25, SAFI=65, BGP-VPLS/BGP-L2VPN
- AFI=2, SAFI=128, L3VPN IPv6 unicast
- AFI=2, SAFI=129, L3VPN IPv6 multicast
- AFI=1, SAFI=132, RT-Constrain
- AFI=1, SAFI=133, Flow-spec
- AFI=1, SAFI=134, Flow-spec
- AFI=3, SAFI=128, CLNS VPN
- AFI=1, SAFI=5, NG-MVPN IPv4
- AFI=2, SAFI=5, NG-MVPN IPv6
- AFI=1, SAFI=66, MDT-SAFI
- AFI=1, SAFI=4, labeled IPv4
- AFI=2, SAFI=4, labeled IPv6 (6PE)
几个管理概念
Local/Transit Traffic
Local Traffic,直译成中文是本地流量,这种流量要么是起源于本AS,要么是终点在本AS内,也就是起始或终点在本AS内的流量叫做Local Traffic。
Transit Traffic,直译成中文是穿越流量,这种流量起源于外部AS,并且目的地也不在本AS内,也就是起始或终点都不在本AS内的流量叫做Transit Traffic。
Stub/Multihomed AS
Stub AS:仅和另外一个AS相连。
Multihomed AS:和两个或两个以上的AS相连接。
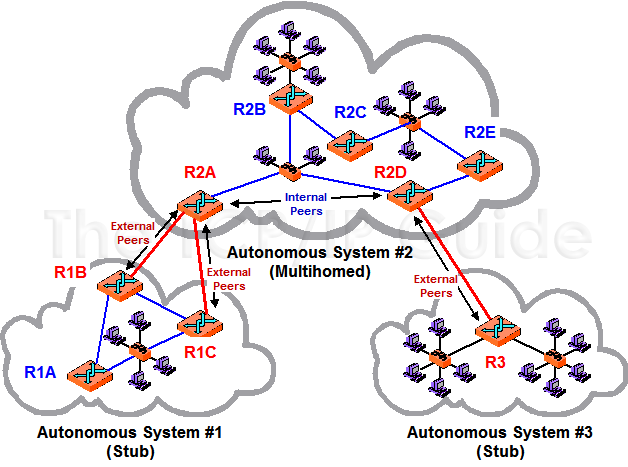
比如上图中的AS2,它同时和AS1及AS3连接,所以它是一个Multihomed AS,而AS1和AS3只和AS2这一个AS相连,所以它们是Stub AS。
No Transit/Restricted AS/Criteria–Based Transit Policy
No Transit Policy:直译过来就是不许穿越策略,也就是不允许处理上面提到过的穿越流量(Transit Traffic)。
Restrict AS Transit Policy:直译过来是严格的AS穿越策略,也就是只允许部分AS的穿越流量通过,但不允许其他AS的穿越流量通过的策略。
Criteria–Based Transit Policy:Criteria–Based,直译过来是基于标准的意思,也就是用标准去确定这些流量是否能穿越,符合规定的标准的穿越流量可以通过。
如何使用这些概念
以上这几个概念在什么时候用得上呢?一般是在规划BGP如何使用的时候。比如你有一些路由器想跑BGP的时候,肯定要先申请AS号码,这时候就得先定位你想跑BGP的这些路由器的作用是什么,你是只给你自己服务还是说你也要给别人通过BGP提供服务,不同的定位决定了BGP不同的玩法。如果你这些BGP的路由器只给自己服务,也就是说你的BGP路由器是流量的终点,是互联网的末端,跑BGP只是想通过BGP协议接受运营商的路由去进行选路,所以这种情况下,你的AS是一个Stub AS,这时候Private AS就足够了;如果你的AS不只是你自己用,你还要给别人提供服务,那么你就是一个Transit AS,跑的是Transit Traffic,那么这时你的BGP的AS号就得申请公有的AS号了,因为要对外提供服务不能只和自己玩了,那么这时你的Transit的是什么呢,你下面可能有一些小的ISP运营商,你上面有些比较大的ISP运营商,你要为他们之间提供Transit 服务,这时候你就是作为一个Transit AS存在的了。
Multihomed AS是说,当你是末端用户,也就是Stub AS的时候,如果你只和某一个ISP运营商连接的话,万一这个运营商挂掉了你就没法提供服务或连接网络了,也就是单点故障了,这时除了连接到主用ISP以外还要连接到另一个备份的ISP运营商,也就是和两个不同运营商的不同AS相连接,这种情况下会用到Multihomed AS这个概念。
基础属性
协议基本知识
BGP目前版本为BGP-4,使用TCP作为传输层协议,这样重传、确认、排序等一系列传输层需要实现的功能就由TCP完成而无需BGP操心,BGP会监听TCP的179端口;
由于BGP使用TCP作为传输层协议,所以它的传输是可靠的,在可靠的链路上需不要使用定期更新,所以BGP使用增量更新和触发更新;
由于BGP使用TCP协议来传输,所以它是一个应用层的路由协议;
每个AS都有一个标识号,也就是AS号,范围是1-65535,其中1-64511是共有AS号,64512-65535是私有AS号;
BGP的设计初衷就是在AS之间传递路由,因此它的一跳实际上是一个AS;
BGP是距离矢量协议,所以具有距离矢量协议的特征,比如水平分割原则(BGP路由器从iBGP获得的路由不会向它的iBGP邻居通告),路由是基于传闻,数据一跳一跳传播等特征。
BGP有三个管理距离,从IBGP学到的路由的AD为200,从EBGP学到的路由AD为20,这是因为BGP的设计初衷就是在AS之间传递路由,所以AS之间的EBGP路由AD值比较小,而在AS内部的路由传递,BGP希望IGP自己搞定,因此IBGP路由的AD值设置为一个较大的AD值,200;
BGP的Router ID和OSPF一样,RID是一个用来标识路由器的IP地址,长度为32位,作用是唯一地标识一台路由器,不能和其他路由器的Router ID重复,可以在BGP路由进程中手工指定,如果没有指定,路由器默认选择环回接口(Loopback接口)中最高的IP作为RID;如果没有环回地址,路由器使用所有激活的物理接口中最高的IP作为RID;
BGP计时器有两个,一个是Keepalive Interval,默认时间为60秒,意思是邻居之间每隔60秒发送Keepalive报文给对方,用来判断邻居是否还存在;另一个是Hold time,默认180秒,意思是如果邻居之间超过180秒还没收到对方的Keepalive信息则认为对方不可达;
BGP水平分割
定义
BGP水平分割原则是指,当运行BGP的路由器从一个iBGP邻居处收到的路由更新,不能再传递给其他iBGP邻居。
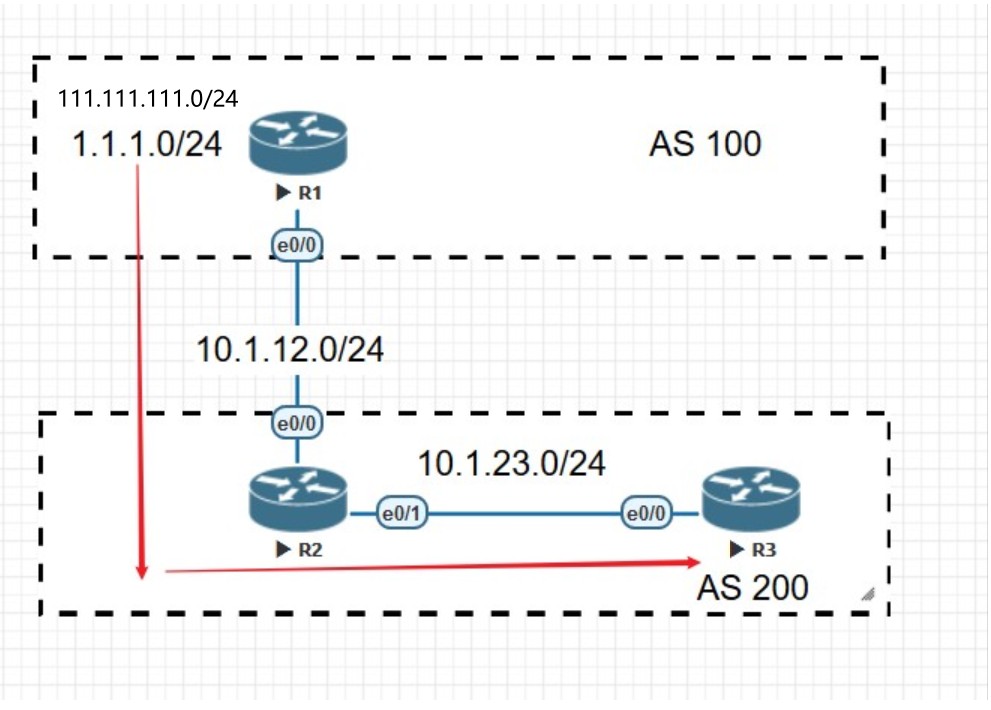
用上面的拓扑来说明水平分割就是,R1和R2是eBGP邻居,R1将网段1.1.1.1/32宣告进BGP并将该路由通过BGP协议宣告给R2,R2又将该路由宣告给iBGP邻居R3,但此时R3不能将从iBGP邻居R2处学到的1.1.1.1/32的路由宣告给iBGP邻居R4。
原因
为什么需要水平分割原则呢?是因为在eBGP中发挥防止路由环路功能的属性参数,AS Path,在iBGP会话中,不起作用。因为AS Path只有在离开一个AS后才会加上这个AS的号码,用来告诉其他路由器这条路由经过了哪些AS,不要再将它发回到那些AS中,否则会引起路由环路。如果没有水平分割原则,意味着iBGP邻居之间可以多次传递路由,比如一条由R1最初生成的1.1.1.1/32的路由,经过多次传递后可能会重新传回给生成它的R1,如果R1之前已经宣告撤销了1.1.1.1/32,就会使得本该被撤销的路由无法真正撤销。为了避免上面提到的风险,有了水平分割原则,并且水平分割原则无法被关闭,但如果有时候必须要打破水平分割原则该如何呢?可以用Full mesh或Route Reflectors。
Full mesh
BGP的Full mesh就是所有BGP路由器都和其他路由器建立iBGP邻居,这样做的好处是由于所有路由器之间都是iBGP邻居,所以水平分割原则不会对路由的宣告有影响。
比如上图中,R2,R3和R4之间就是Full mesh状态,彼此两两都是iBGP邻居,这种Full mesh情况下,R2就可以将另一个AS的BGP路由直接发送给另一边界处的R4,不受水平分割的影响了。
Route Reflectors
路由反射器在后面会具体说。
BGP三张表
邻居表(Neighbor Table):表中包含着关于BGP邻居的信息。查看邻居表的命令为show ip bgp summary(简略邻居信息)、show ip bgp neighbor(详细邻居信息);
BGP表(Forwarding Database):表中包含着查看BGP表的命令为show ip bgp;
路由表(Routing Table):查看路由表的命令为show ip route;
查看哪条路由未加表的命令为:show ip bgp rib-failure;
路由处理过程
三个路由信息库
Adj-RIBs-In
The Adj-RIBs-In contains unprocessed routing information that has been advertised to the local BGP speaker by its peers. —-RFC4271,Page 4
直译过来就是,Adj-RIBs-In中存放着的由BGP邻居发送来的未经处理的路由信息。这个“未经处理”指的是什么呢?就是没经过任何路由策略过滤或属性修改。说白了就是邻居发来的原始的路由信息是什么样的,原封不动的保存在Adj-RIBs-In中。通过命令 show ip bgp neighbor x.x.x.x received-routes查看Adj-RIBs-In。但这里也要注意,如果路由器的IOS比较老的情况下,想查看邻居发过来的未经处理的路由信息,必须在想查看路由的这个邻居上配置一条命令’neighbor X.X.X.X soft-reconfiguration inbound’,比如说我是12.1.1.2,现在我想查看12.1.1.1发过来的未经处理的原始BGP路由信息,就得在12.1.1.1上配置一条neighbor 12.1.1.2 soft-reconfiguration inbound,否则会提示’% Inbound soft reconfiguration not enabled on 12.1.1.1’,这是因为‘neighbor X.X.X.X soft-reconfiguration inbound’这条命令的作用是让所有BGP的路由前缀保存在本地设备内存中,即使这些路由前缀被BGP的入向策略拒绝掉也会在内存中,如果不配置这条命令,则无法查看。如果路由器的IOS比较新的情况下,是不需要配置这条命令的,具体参见后面‘协议配置——重置BGP连接部分’。

Loc-RIB
The Loc-RIB contains the routes that have been selected by the local BGP speaker’s Decision Process.—-RFC4271,Page 5
Loc-RIB英文全称是Local Routing Information Base,是Adj-RIBs-In中邻居发送过来的原始路由信息,经过BGP路由选择出来的Best路由条目会放入Loc-RIB(BGP表)中存储。
Adj-RIBs-Out
The Adj-RIBs-Out contains the routes for advertisement to specific peers by means of the local speaker’s UPDATE messages. —-RFC4271,Page 4
Adj-RIBs-Out中存储着宣告给特定邻居的路由条目,这些路由条目通过update报文发送给邻居。通过命令show ip bgp neighbor x.x.x.x advertise-routes来查看Adj-RIBs-Out。
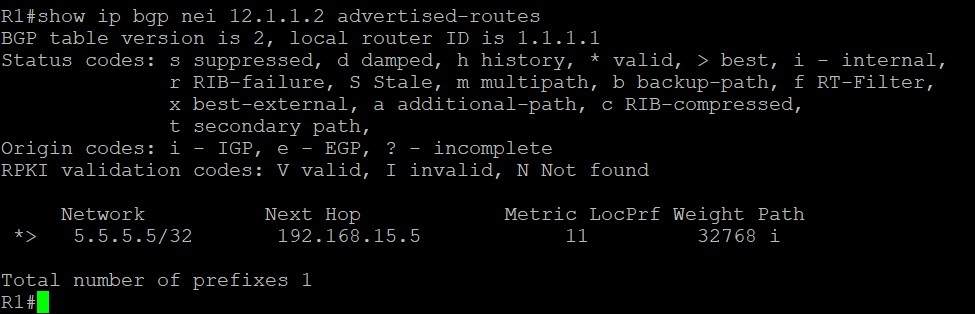
上面的截图中输出表示,R1向邻居12.1.1.2宣告了1条5.5.5.5/32的BGP路由,这条路由的下一跳是192.168.15.5。
处理过程
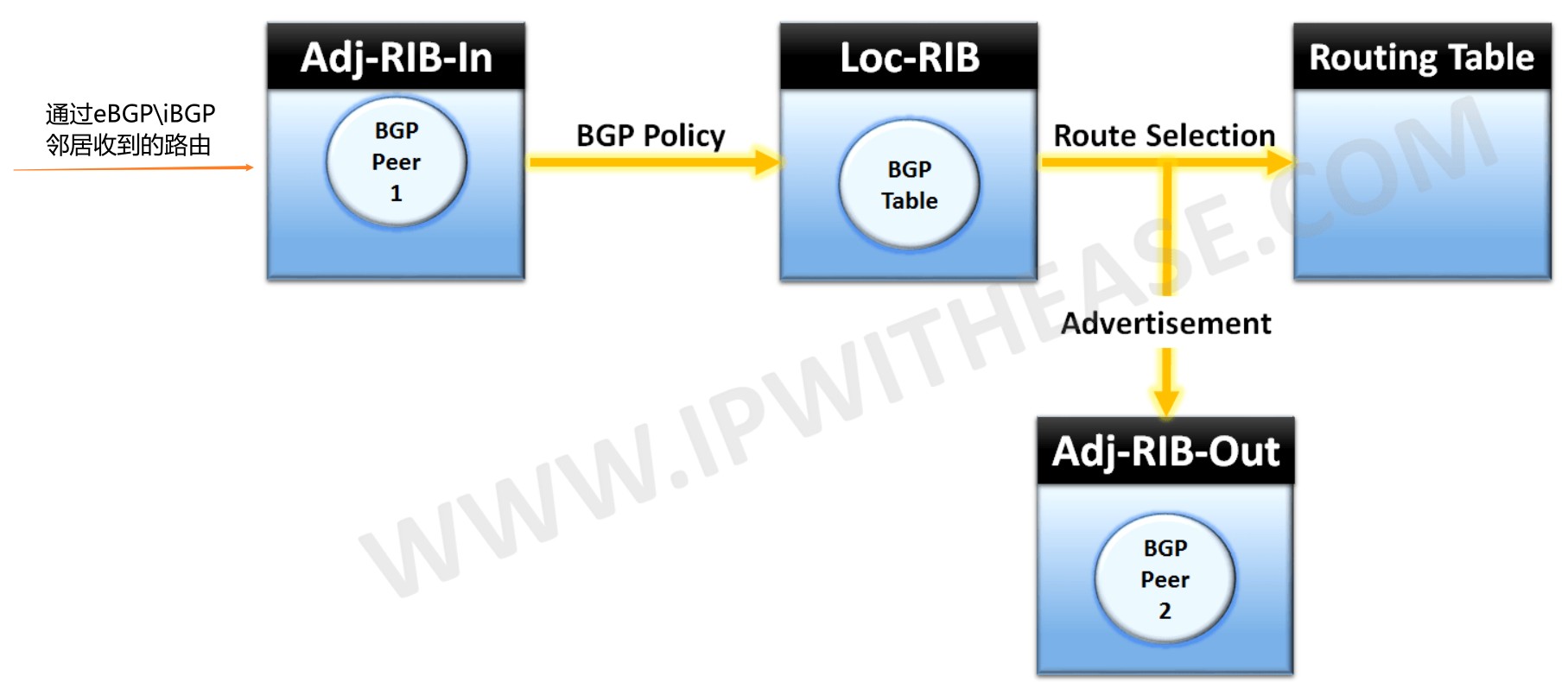
把邻居们(eBGP\iBGP方式建立的)发来的所有路由前缀保存到Adj-RIBs-In中,检查下一跳是否可达,如果不可达则该路由不可能成为最优的BGP路由;
将上面存储的所有路由用BGP Policy过滤,过滤后同一个目标前缀可能有多条路径;
对去往同一前缀有多条路径的路由执行路由选择,在多条路径中选择出一条去往目标前缀最优的路径,比的是BGP的路径属性,最优的BGP路由带有>符号,表示该路由是BGP表中去往某一路径的最优路由,最优的BGP路由会保存在Loc-RIB,也就是BGP表中;
将选择出来的BGP最优路由一方面要看是否能放入路由表中,另一方面要将它放入Adj-RIBs-Out中宣告给其他对等体邻居。是否放入路由表的决策过程为,如果目的地址有其他IGP路由,则需要比较两者的AD值,越小越优。如果BGP路由的AD值小,则会将这条之前在BGP表最优的路由放入路由表中,如果BGP路由的AD值大则不会放入路由表中。如果目的地址没有其他IGP路由,则该BGP路由直接放入路由表中;
BGP路由通告
- 当存在多条路径时,BGP路由器只选取BGP表中最优的路由,也就是带>标识为Best的;
- BGP路由器只把自己使用的路由,也就是自己认为Best的路由发送给邻居:
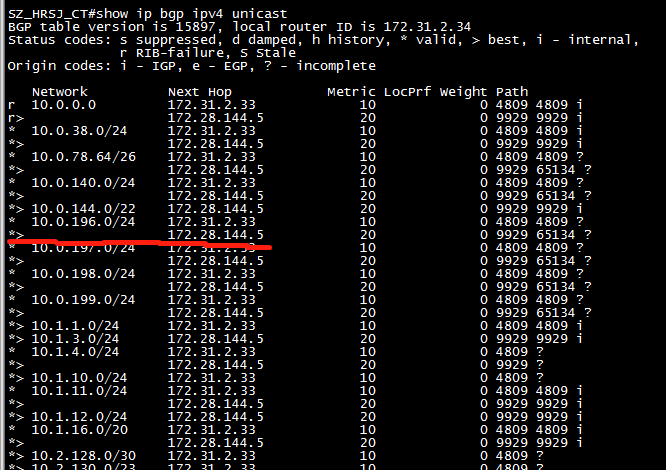
比如上图中,到10.0.196.0/24这个前缀有两条路径,只把下面带>的那个,就是下一跳是172.28.144.5的那条发送给邻居,不是Best的就存在本地的Adj-RIBs-in中。
BGP路由器从eBGP获得的路由会向它所有的BGP邻居通告,包括eBGP和iBGP;
BGP路由器从iBGP获得的路由不会向它的iBGP邻居通告,因为有水平分割原则并且要避免出现环路(存在RouterReflect的情况除外);
BGP路由器从iBGP处获得的路由是否通告给其他的eBGP路由器要看IGP和BGP同步的情况来决定;
BGP计时器
Holdtime&Keepalive
Holdtime和Keepalive是BGP用来确定邻居还存在的重要机制,当路由器之间没有Update报文可供交换时,运行BGP的路由器之间会相互发送Keepalive报文,看邻居是否还存在,如果收到Keepalive报文的时间在Hold Time规定范围内,则确定了对方还存在,收到Keepalive报文后,Holdtime计时器会重置;如果HoldTime计时器过期前都没收到Keepalive或update报文,则会认为对方已经挂掉,那么路由器就会认为从这个挂掉的邻居那收到的路由前缀已经失效,将这些路由从BGP表以及路由表中去掉,并用其他可用路径代替这些被移除的路径。Keepalive是HoldTime数值的三分之一,RFC4271中对这两个值的建议时间为,HoldTime为90秒,Keepalive为30秒,Juniper设备默认的计时器也是整个数字,但思科和华为对BGP默认的Hold Time为180秒,Keepalive为60秒,也就是每过60秒发送Keepalive报文,如果180秒内没收到邻居的Keepalive报文或update报文,则说明邻居已经挂掉。
在思科设备中对HoldTime和Keepalive进行更改的命令为:neighbor X.X.X.X timers A B。其中X.X.X.X是需要更改计时器的邻居路由器的RID,A是Keepalive的时间,B是HoldTime的时间。如果配置命令为 neighbor 1.1.1.1 timers 10 30,说明将对邻居1.1.1.1的Keepalive时间设置为10秒,HoldTime时间设置为30秒。这里必须注意的是,Open报文中交互的只是HoldTime,而不会对Keepalive进行交互。
Holdtime
Holdtime的数值表示一个路由器在多长时间未接到邻居信息以后认为这个邻居已经挂掉,比如思科设备默认的Hold time为180秒,从180开始倒数计时,那么如果在180秒内还没收到邻居发来的消息,也就是计时器到0之前都没收到邻居的消息,则会认为邻居已经挂掉,那么路由器就会认为从这个挂掉的邻居那收到的路由前缀已经失效,将这些路由从BGP表以及路由表中去掉,并用其他可用路径代替这些被移除的路径;如果在HoldTime计时器到期前收到了Keepalive或Update报文,则说明邻居还存在,此时HoldTime计时器会重置为180秒,重新进行新一次的倒计时并循环往复。HoldTime在Open报文中会相互交互。
Keepalive
Keepalive计时器不会在Open报文中交互,Keepalive在思科设备中默认时间是60S,也就是三分之一的Holdtime时间。
计时器协商
当两个BGP邻居配置的计时器不同时,两边用Open报文交互了HoldTime的数值,所以彼此知道对方路由器所配置的数值,此时:
HoldTime采用两个路由器设置值的最小值,也就是说,如果一边的HoldTime为60,另一边的HoldTime为30,则最后采用较小的30,作为HoldTime值。
Keepalive的话,如果手工配置的Keepalive timer小于两边配置的最小的HoldTime的三分之一,则采用配置值;如果手工配置的Keepalive timer大于两边配置的最小的HoldTime的三分之一,则采用两边配置最小的HoldTime的三分之一这个值作为Keepalive。
如果配置了timer bgp 0 0,则表示两边的邻居永远不会down。
触发更新计时器
英文全称为:MinRouteAdvertisementIntervalTimer(MRAI Timer),BGP不会周期性更新路由,仅在需要的时候更新,由于公网的路由可能的动荡,为了保持BGP路由的稳定性,因此触发更新(包括宣告新路由或撤销路由在内)也会有一定的收敛时间,IBGP peer为5秒,EBGP peer为30秒,在这段时间内,BGP仍可以进行路由信息的收集,但不能宣告\撤销任何BGP路由,所以BGP收敛会比较慢。
ConnectRetryTimer
翻译成中文就是重传计时器,这个计时器定义的是重新连接请求之前的超时间隔。
报文格式
BGP路由器之间交互任何BGP报文之前,必须先建立TCP连接。
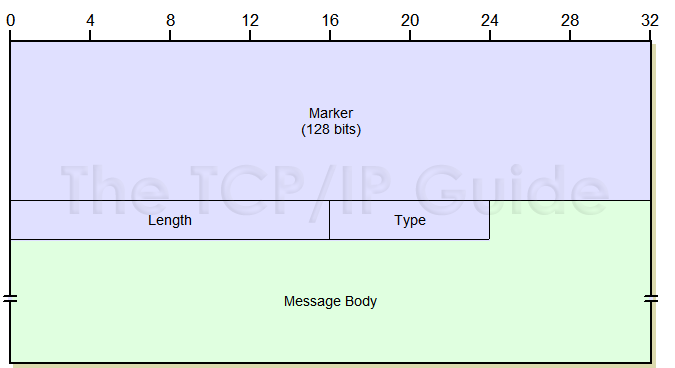
报头部分
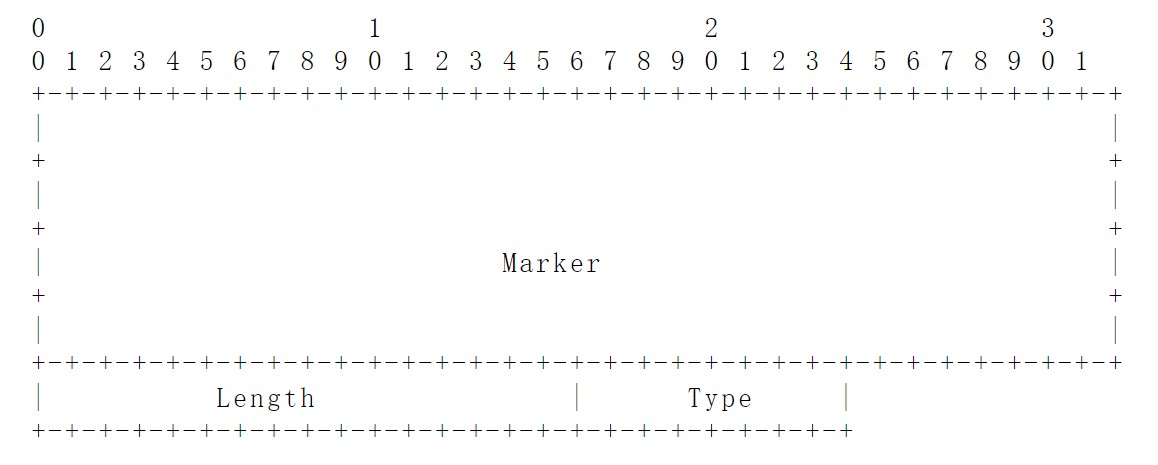
BGP的每个报文都有固定大小的报头:
Marker:长度为16位,用来检测BGP对等体之间同步丢失情况,并且在支持验证功能的情况下进行报文验证。如果报文类型为open或open报文中没有包含验证消息,此字段被置为全1;
Length:长度为2位,表示BGP报文包括头部在内的长度;
Type:1为Open,2为Update,3为Notification,4为Keepalive;
消息部分
BGP消息部分的字段根据报头部分中的Type字段不同而不同。
Open
报文概述
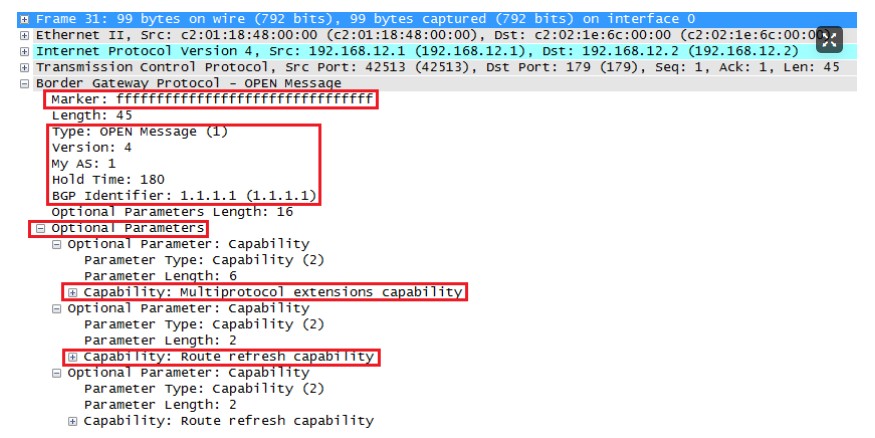
当两台运行BGP协议的路由器已经建立好TCP连接后,他们开始尝试用Open报文建立连接,双方使用Open报文标识自己,并且规定自己的BGP运行参数,如果Open信息被接受则会回送一条Keepalive信息进行确认,确认后再发送Update信息。BGP会话由发送Open信息建立。Open信息的作用是为两台设备建立连接,标识发送Open设备的AS号及Router ID,并且协商BGP会话的重要参数(Keepalive、认证等)。如果两台路由器中的任意一台不接受Open信息中的参数则会发送Notification告知对方无法建立邻居的问题所在。Open信息的最小长度为29字节。
报文格式
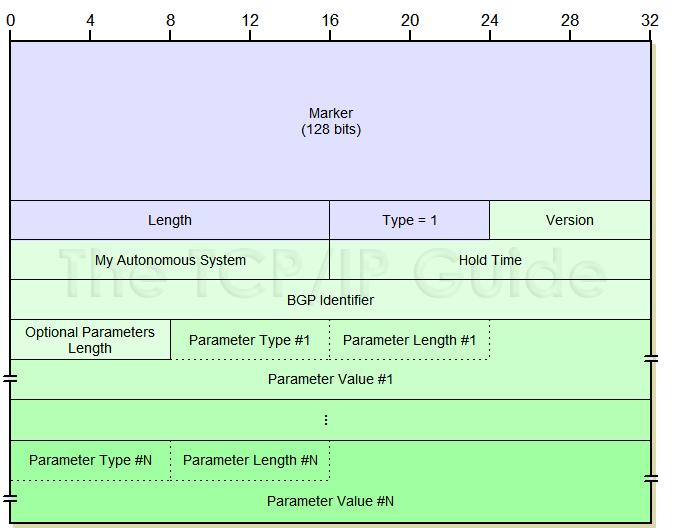
当Type位值为1时,说明此消息为BGP的Open信息;
Version:长度为1字节,标识着发送Open信息的路由器运行的BGP版本,通常这个值为4,表示运行的是BGP-4版本;
My Autonomous System:长度为2字节,标识着发送Open信息路由器的AS号;
Hold Time:长度为2字节,该字段的值默认为180秒,表示如果邻居之间超过180秒还没收到对方的Keepalive信息则认为对方不可达;
BGP Identifier:长度为4字节,和之前OSPF的Router ID作用一致,用来标识运行BGP协议的路由器的身份,选取方式也和OSPF的Router ID选取方式一致,在Cisco设备中,路由器上环回接口的最高IP地址是BGP的Identifier,如果未配置环回接口,则将选择任何最高IP地址物理接口作为BGP标识符的值。
Optional Parameters Length:用来表示后面可选参数字段的长度,如果该字段为0说明该Open信息内没有可选字段;
Optional Parameters:可选参数,包含了一个可选参数列表,每个参数都由一个长度为8位的类型字段、长度为8位的长度字段以及一个可变长度的参数数值字段组成。用来宣告是否支持验证、多协议支持和路由刷新等可选功能,通常被成为能力值,意思就是这台路由器具备什么能力。
A BGP speaker that supports a particular capability may use this capability with its peer after the speaker determines (as described above) that the peer supports this capability. Simply put, a given capability can be used on a peering if that capability has been advertised by both peers. If either peer has not advertised it, the capability cannot be used.
A BGP speaker determines that its peer doesn’t support capabilities advertisement if, in response to an OPEN message that carries the Capabilities Optional Parameter, the speaker receives a NOTIFICATION mecification [RFC4271] and not a new requirement.) In this case, the speaker SHOULD attempt to re-establish a BGP connection with the peer without sending to the peer the Capabilities Optional Parameter.
—-RFC 5492 page 2
上面这段话的大概意思是,两个BGP在建立邻居时,会用open报文协商彼此支持的BGP特性,如果两者支持相同的特性那么两者会使用该特性;如果两者支持的特性不同,则会发送Notification报文给对方,然后在不发送Capabilities Optional Parameter的情况下重新建立邻居。
wireshark抓包
Update
报文概述
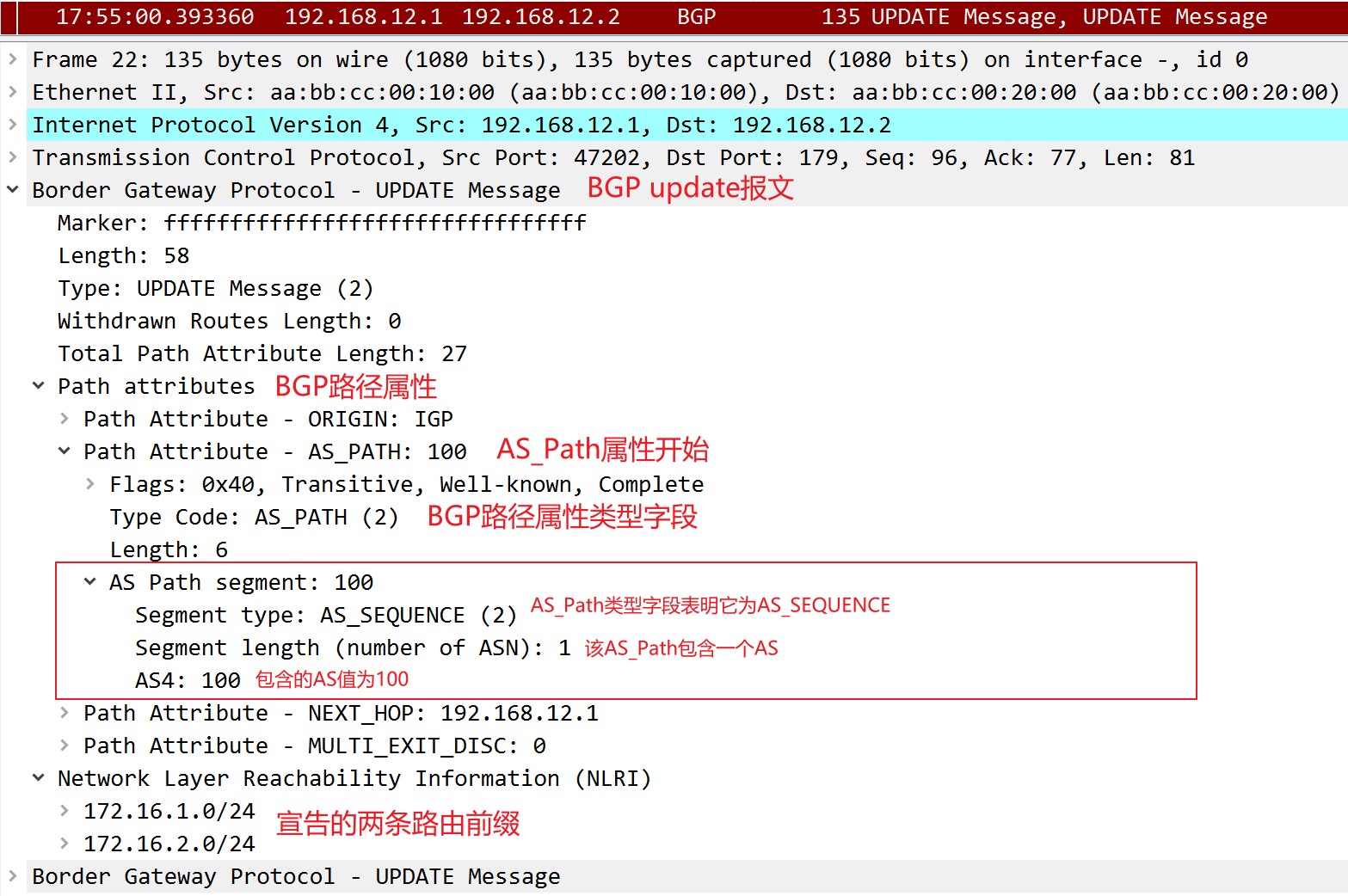
当两台BGP Speaker通过Open报文建立连接后,开始交互路由信息的过程,路由器会将那些经过路由决策筛选出来的路由条目宣告给邻居。这些需要宣告给Peer的路由信息会放入BGP的Update报文,Update会发送给每一个已用Open信息建立会话的邻居。每一个Update报文中有以下的某一个或全部元素:
- 路由通告:一条路由的特征;
- 路由撤销:不可达网络的列表。
必须注意的是,一个Update报文息中,只能通告一组路径属性相同的路由前缀,但能撤销多条路由。这是因为撤销路由只需要被撤销网段的网络号即可,而宣告路由则需要很多信息,比如要宣告路由的多种路径属性,这需要占用很大空间。当然update报文也可以只撤销路由而不进行任何宣告。实际上,只能通告一条路由这句话并不是简单的一个update报文里只有一个网络前缀,而是说一个Update报文中只发送一组路径属性相同的NLRI的路由前缀,可以参照下面的抓包对这句话进行理解:
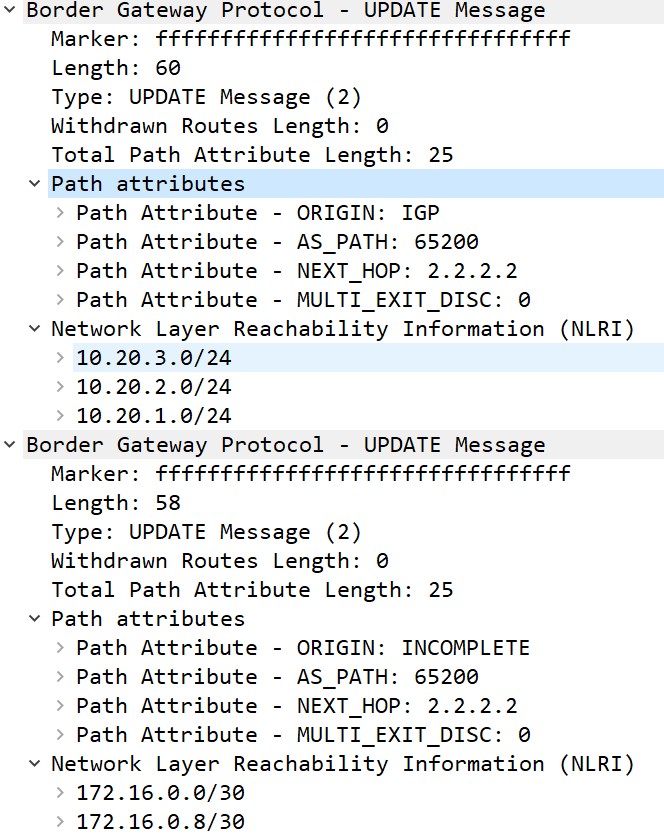
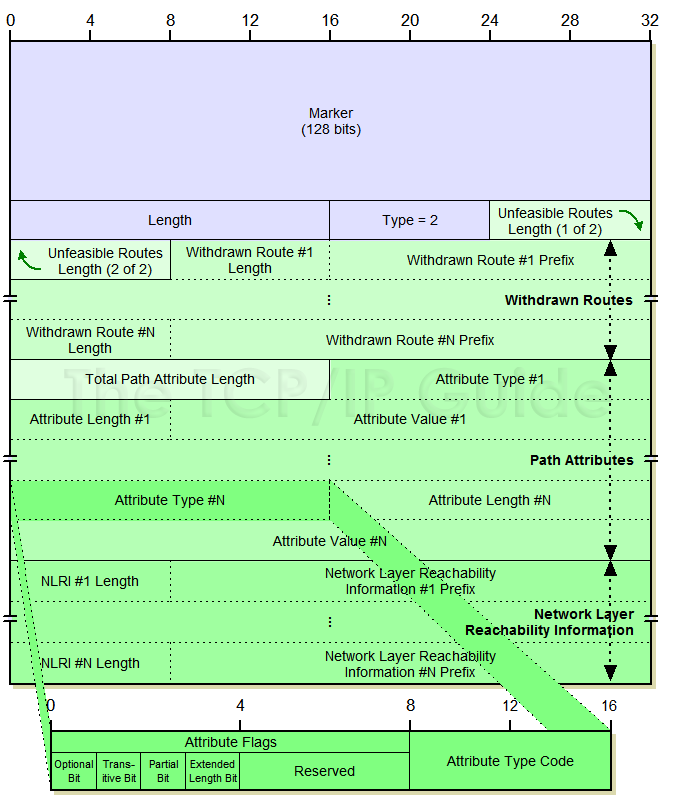
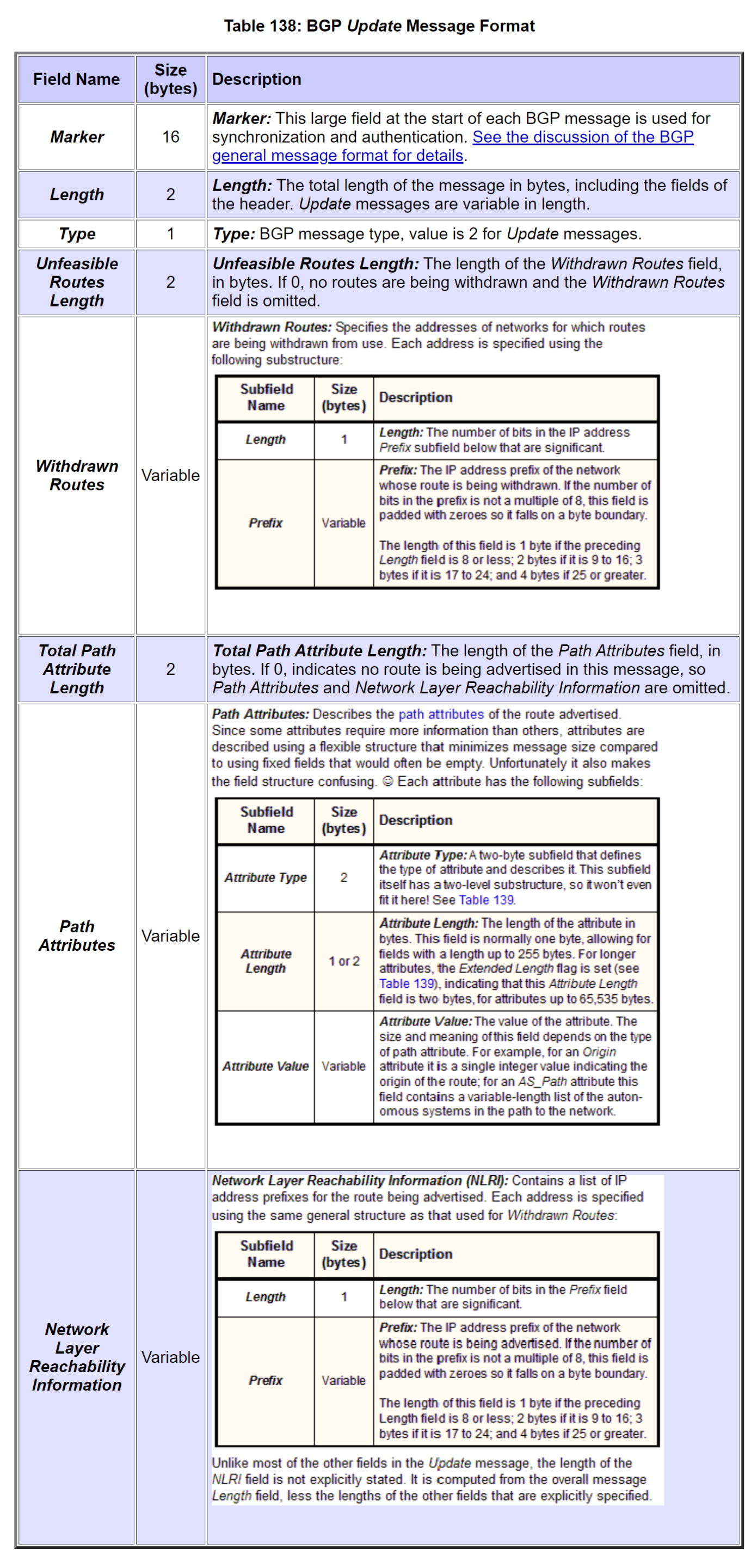
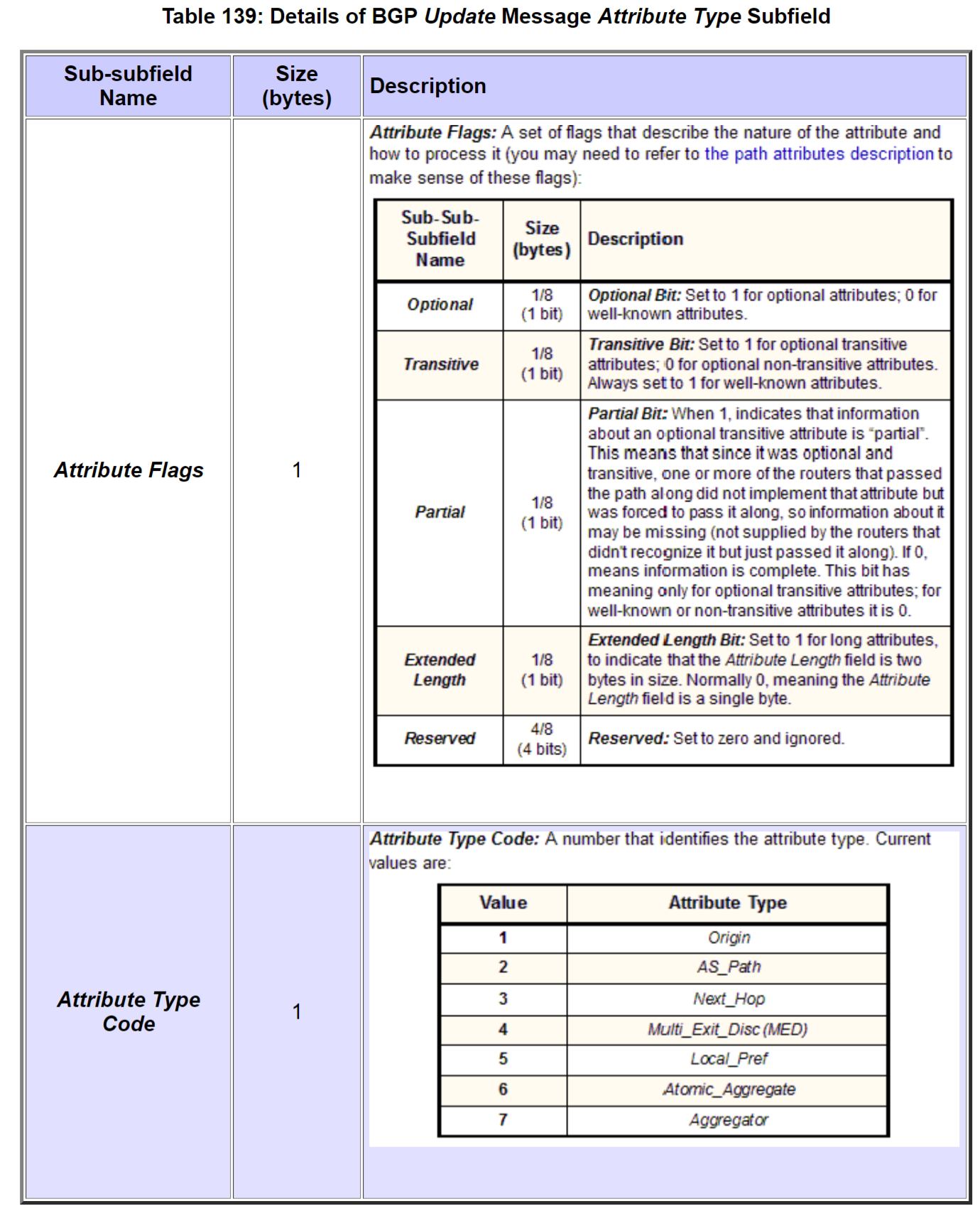
报文格式
update报文的结构比较复杂,具体参见这个网页,我截了两张图在下面,就不展开说了。
wireshark抓包
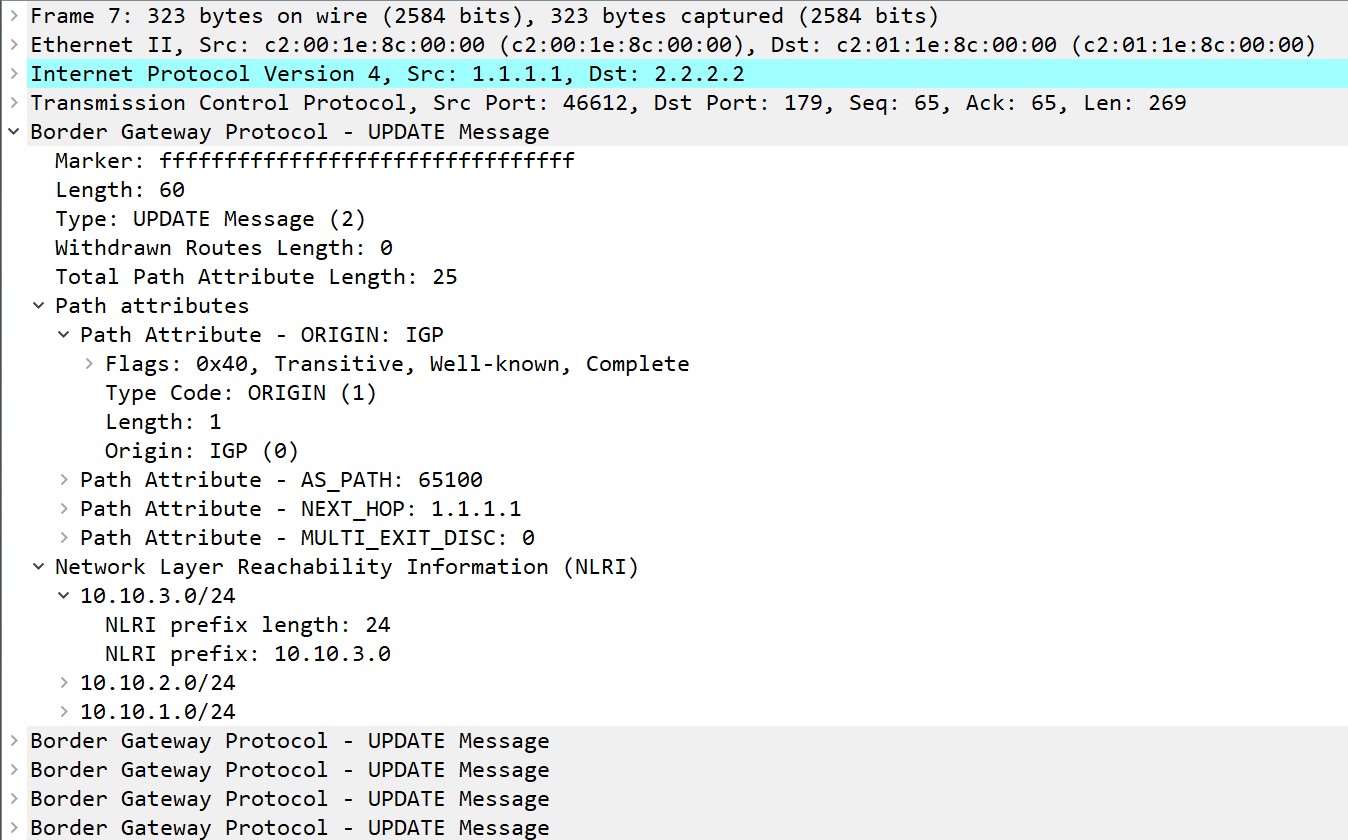
update报文的格式看起来非常复杂,实际上wireshark的抓包并没有上面看起来那么复杂,每个update报文中是具有相同路径属性的前缀的集合:
Keepalive
报文概述
当BGP通过Open报文建立连接后,BGP Speaker之间开始用Update报文交互路由信息,当路由信息交互完毕后,BGP进入了一个平稳的状态,只有当路由情况发生变化时,才会再度交互Update报文,此时BGP不会依靠TCP的连接状态去判断对方是否还在,而是用彼此交换Keepalive报文来确定对端没有Down掉。Keepalive报文交互的间隔是Hold Time时间的三分之一,在思科设备中,Hold Time默认时间是180秒,它的三分之一就是60秒,所以默认Keepalive时间是60秒。如果协商后的Hole Time为0,那么两个BGP Speaker之间不会交互Keepalive报文保活。
报文格式
Keepalive报文中没有任何实际的信息,它里面只有BGP的报头。
wireshark抓包

Notification
报文概述
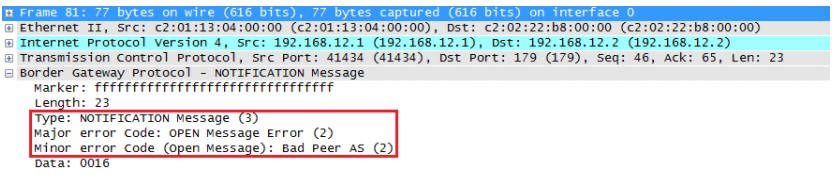
当BGP Speaker建立好连接后,可能会出现一些影响到BGP日常通信的错误,当这种问题出现时,BGP会通过Notification报文将这个错误通告给它的所有对等体(Peer,也就是邻居),当Notification报文发送时,通常会导致BGP的连接中止。Notification中有许多能告知为什么发生错误的字段,这里面包括了一组主要的错误代码以及一些错误代码的子代码,有些错误可能还会附加额外的信息帮助诊断问题所在。
报文格式


wireshark抓包
Route-refresh
当路由策略发生变化时,用Route-refresh报文去请求邻居重新通告路由,因为BGP不会周期性发送更新,只有在路由产生变化时才会发送Update报文更新路由。首先先查看邻居是否支持,只有支持了该特性时才能使用:
1 | R2#show ip bgp neighbors 192.168.23.3 | section Neighbor capabilities |
从上面可以看到,该路由器支持新的Route refresh功能,所以可以使用。
1 | R2#debug ip bgp in |
从上面的Debug中能看出,发送了sending REFRESH_REQ报文给邻居去请求重新发送路由通告,使得BGP新配置的策略能够尽早生效。
邻居建立
过程概述
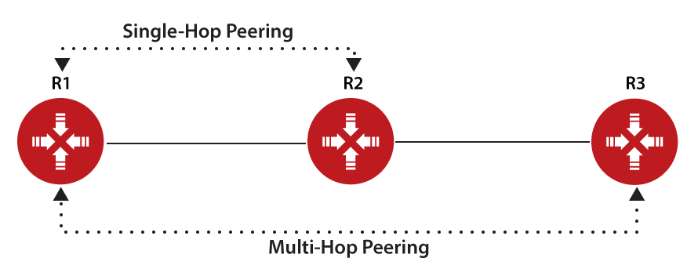
由于BGP是一个EGP协议,所以它的邻居的建立和之前学的其他IGP协议(比如OSPF和EIGRP)完全不同,IBGP协议只要在路由器上配置了以后就能自动发现邻居,比如在运行OSPF的路由器上,配置了router ospf 1、network x.x.x.x y.y.y.y area z宣告了网段进入OSPF后,其他相连接的路由器也宣告网段进OSPF的话,只要OSPF建立邻居的组播地址(224.0.0.5,224.0.0.6)能正常通信,两者就自动开始建立邻居了,但BGP不同,它必须明确指定和哪个路由器建立邻居,才会启动建立邻居的过程,如果不宣告则不会进行邻居建立。BGP协议由于在传输层采用了TCP协议,BGP邻居建立不像OSPF、EIGRP这些IGP一样邻居之间必须直连才能建立邻居,因为BGP的控制报文(Keepalive、Open、Update、Notification和Withdraw报文)能够被路由从而跨越多个子网进行传输,这意味着BGP支持单跳、多跳的邻居建立:
由于TCP需要经由三次握手建立连接,所以BGP的邻居建立实际上分成了两部分:
- TCP连接建立阶段:Idle、Connect、Active;
- BGP连接建立阶段:Opensent、Openconfirm、Established;
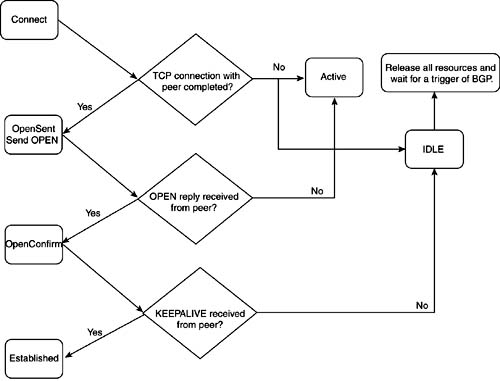
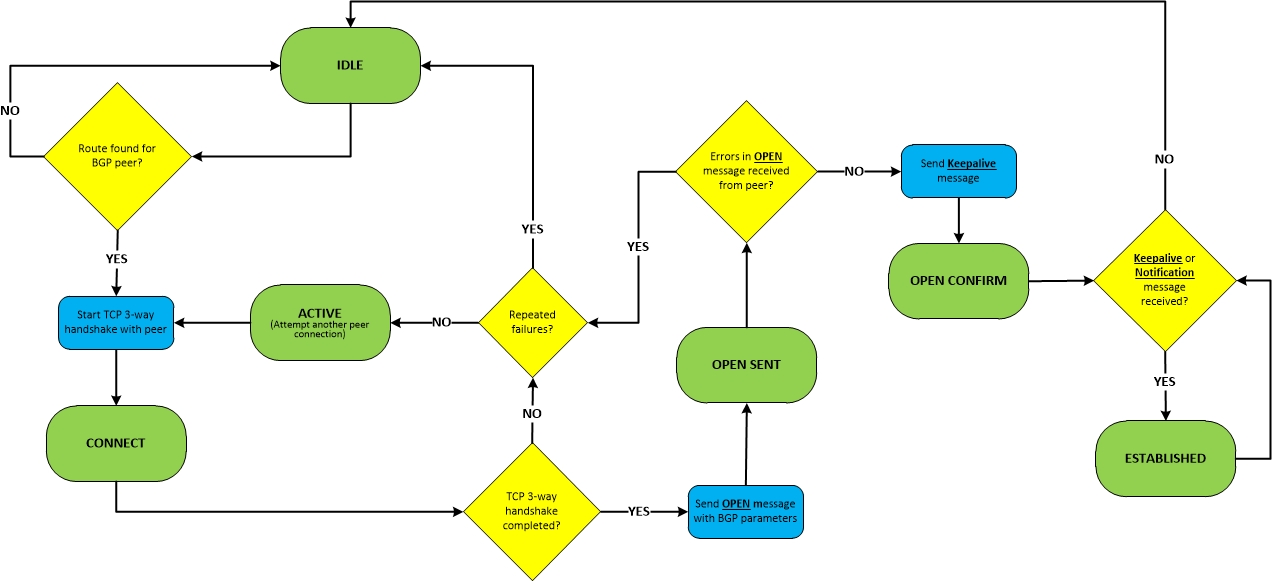
BGP的有限邻居状态机(Finite State Machine,FSM)共有6个状态,其中Idle、Connect、Active属于TCP建立连接阶段,在这个阶段中,会交换交换TCP报文用来建立TCP连接,因为BGP协议需要可靠的TCP连接来传递BGP报文;Opensent、Openconfirm、Established属于BGP建立连接阶段,其中Opensent和Openconfirm两个阶段对应的是运行BGP的路由器交换BGP会话所必需的属性值,Established阶段表示邻居进入了稳定阶段,可以接受彼此的BGP路由更新。
TCP连接建立阶段
在BGP连接建立前,必须先建立TCP连接,因为BGP的四层协议采用的是TCP协议,BGP报文交换需要TCP提供稳定的传输,如果TCP连接中断,BGP会话也会中断,当然TCP阶段建立和BGP阶段建立是两个独立的阶段,并不是只要TCP建立成功以后的BGP连接建立也会成功,因为TCP连接建立成功只是BGP连接建立的基础,而BGP建立阶段也要协商参数,也可能出现错误导致BGP阶段无法建立。当BGP的有限状态机在Idle、Active和Connect几个阶段来反复时,说明是TCP连接出现了问题。
Idle
Idle是BGP有限状态机的第一个状态,BGP在检测到“Start event启动事件”之前是不会和邻居路由器开始建立邻居过程的。当路由器检测到BGP的Start event后(当路由器配置了一个新的BGP邻居或BGP Peer重置时),BGP会尝试和邻居建立TCP连接并且也会接受其他路由器发送的建立BGP邻居的消息,路由器也会在本地开始寻找一条到邻居的路由用于建立TCP连接。如果完成了上述步骤,则BGP进入下一个阶段——connect;如果在BGP邻居建立过程中发生错误,那么BGP会话会立刻终止并回到Idle状态,接下来ConnectRetry Timer(重连计时器)会设置为60秒,在重传计时器倒数到0之前,不会再尝试去建立邻居。每次连接建立失败后重新回到Idle状态的话,会导致ConnectRetry Timer(重连计时器)的时间比上次加倍。
导致BGP进程终止回到Idle状态的原因可能有以下几种:
TCP的179端口未打开;
高于1023的TCP随机端口未打开;
任意一端地址配置错误;
任意一段AS号配置错误;
Connect
在Connect状态,路由器会在本地尝试找到一条到邻居的路由,初始化TCP连接并尝试TCP三次握手且等待三次握手完成。认证也是在TCP建立期间完成的。在Connect状态下,BGP会启动重传计时器(ConnectRetry),等待TCP完成连接,在思科设备上使用’show tcp brief’来查看TCP会话建立的结果:
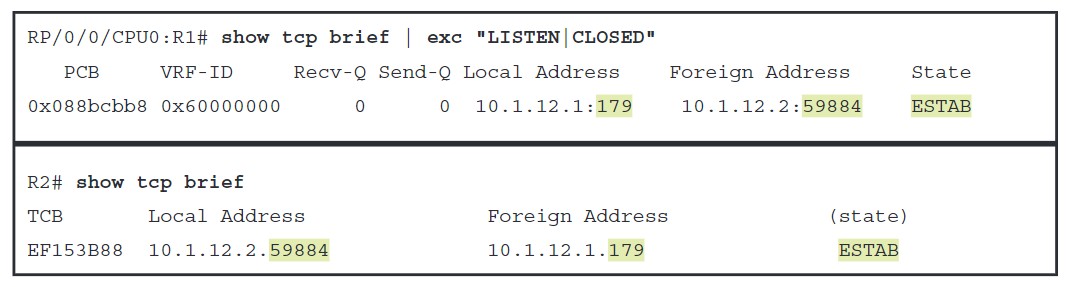
如果TCP连接成功,那么BGP在这个状态的时间会比较短,接着会向邻居对等体发送Open报文,并进入OpenSent状态;
如果TCP连接失败,那么会进入Active状态反复尝试进行TCP连接;
如果重传计时器(ConnectRetry)过期之前,BGP路由器没有收到邻居对等体的响应,那么BGP会停留在Connect状态,会对邻居对等体尝试进行新的TCP连接,此时ConnectRetryTimer会重置且进入Active状态。如果在这过程中对配置进行了更改或收到同一个IP又发过来的三次握手的SYN<比如三次握手还没完,shutdown了这个neighbor>(思科原文用的是If any other input is received),那么会话会重新回到Idle开始;
Active
TCP连接如果没成功建立,则会在Active状态反复尝试TCP连接。
- 如果在Active状态TCP连接成功建立,则会发送Open报文,Hold Timer会设置为4分钟,也就是240秒,然后进入OpenSent状态;
- 如果TCP连接建立失败,则进入Connect状态并且重置ConnectRetryTimer;
BGP连接建立阶段
OpenSent
在OpenSent状态,BGP会话的起始路由器会发送Open报文给对端,等待对端响应Open报文。Open报文用来检查两端BGP的参数是否匹配,下列参数会被比较\协商:
BGP版本必须相符;
Open报文中的源IP地址必须和邻居配置的IP地址相等;
Open报文中两端配置的AS号要相匹配;
BGP的Identifiers(RID)必须唯一;
安全方面的参数(Password、TTL等);
如果Open报文的协商过程中没有出现错误,将会协商出来Hold Time的时间(以两端配置的最低值为Hold Time),并且发送Keepalive报文(假设Keepalive不设置为0的情况下),发送完keepalive报文后BGP会进入OpenConfirm状态。
如果Open报文的比较过程中出现了错误,会发送Notification报文,BGP状态会回到Idle状态。
如果在OpenSent状态中收到了TCP的disconnect报文,则BGP会关闭连接,重置ConnectRetryTimer,状态变为Active。
如果在OpenSent状态,配置进行了更改,那么状态会变为Idle。
OpenConfirm
在OpenConfirm状态下,BGP会等待Keepalive或Notification报文。
- 如果收到Keepalive报文则进入Establish状态;
- 如果等待Keepalive的时间超过了Hold timer计时器的时间或收到Notification报文,那么状态会变为Idle。
Established
在这个状态下,BGP会话建立完毕,BGP邻居之间通过Update报文交换路由。当收到Update和Keepalive报文时,Hold Timer时间会重置,如果收到Update\Keepalive报文的时间超过了Hold Timer,说明邻居之间出现了问题,BGP会重新回到Idle状态。
流程图
实验验证
直连EBGP邻居
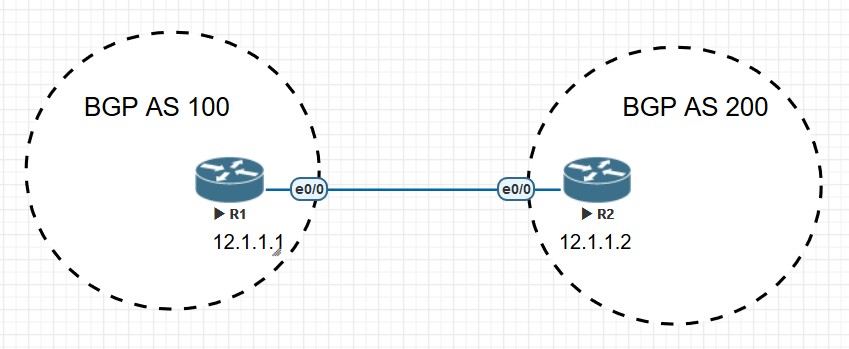
线缆直连的单跳路由器之间建立EBGP邻居,是EBGP中最简单也最常见的方式,不需要对BGP进行过多的配置。
基本配置:
R1
1 | interface Loopback0 |
R2
1 | interface Loopback0 |
命令简析
- router bgp 命令表示在两台路由器上对BGP进程进行初始化的同时,也指出了本路由器所在的AS,比如R1上配置的是router bgp 100,这个100表示R1属于AS100。
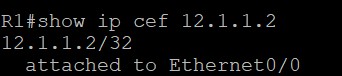
- neighbor命令在BGP配置模式中确定建立邻居的路由器的地址和AS号,R1配置的命令为’neighbor 12.1.1.2 remote-as 200’表示R1要和在AS200的IP地址为12.1.1.2的这个路由器建立邻居。R1从这个命令中得知,12.1.1.2在AS200中,和自己不在同一个AS中,所以R1知道了它和R2的BGP为EBGP;neighbor命令还告诉了路由器的TCP协议,只接受地址为12.1.1.2的TCP连接,由于我是在BGP邻居已经建立以后输入的命令,所以可以看到除了监听了neighbor命令中输入的12.1.1.2的179端口以外,12.1.1.1和12.1.1.2的TCP状态是已经建立(ESTAB)。除了TCP方面的影响,在输入neighbor命令后,R1还会运行一个IOS内部的检查机制,叫做samecabletest/same-cable test(The reason behind this is because of an internal IOS check mechanism that is known as the same-cable test. IOS makes sure the eBGP neighbor is directly connected (“C” route) before sending BGP open messages to the neighbor.),也就是看EBGP的邻居是否是由同一个线直接连接,并且R1会查询到12.1.1.2的路由是否是类型C的,也就是否是直连路由。R1发送给R2的TCP和BGP报文中的TTL会设置为1,从抓包中可以看出这一点,因为要建立的是EBGP邻居。从show ip cef 12.1.1.2中能看到,到12.1.1.2的路由直连E0/0接口。

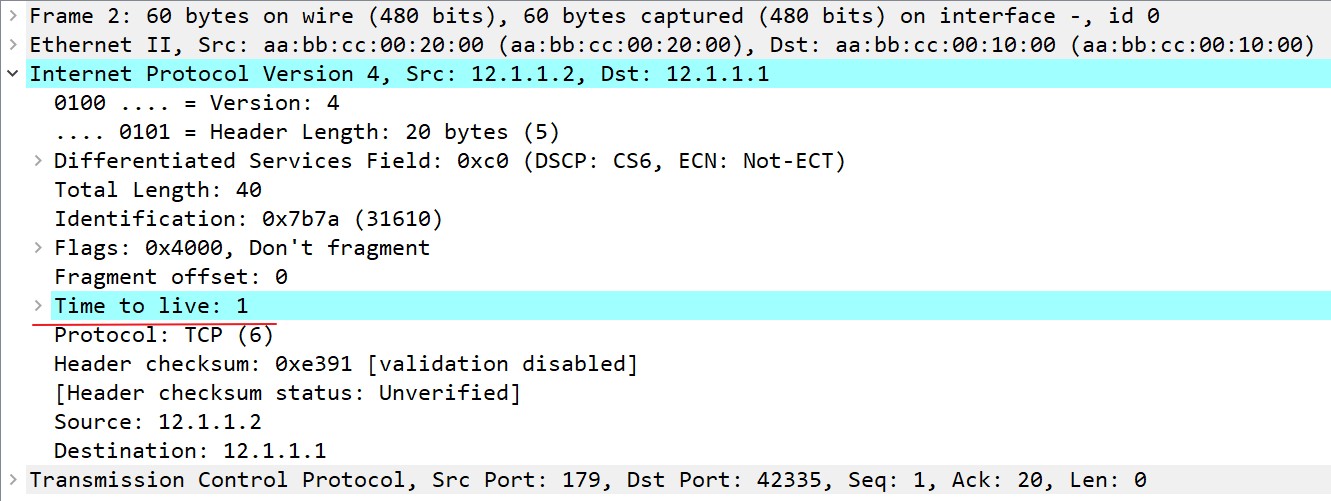
BGP会话建立完毕后,BGP邻居之间使用Update报文交换路由,可以用show ip bgp neighbor查看建立状态:

环回口EBGP邻居
实验分析
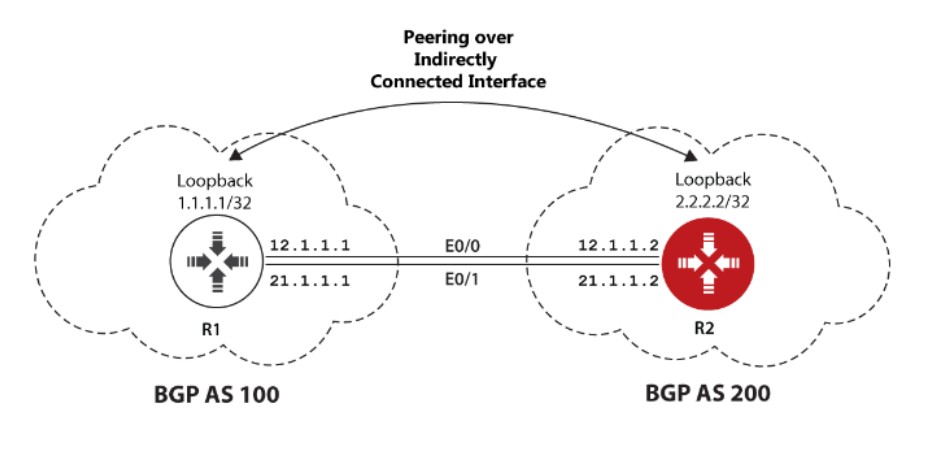
当两个AS之间有两根或以上的链路连接时,这时如果还用直连的地址建立BGP邻居,那么有以下两个方式:
- 如果只用E0/0或E0/1之中的一个接口建立EBGP邻居,如果当这跟链路中断时,两端的BGP邻居会中断,所有从另一端学到的BGP路由信息都会从BGP路由表中删除,即使还有另一根备份链路能够联通两台路由器也是这样,因为只在其中一个链路上宣告了BGP,从而浪费了另一个链路的路由备份功能;
- 如果分别使用E0/0和E0/1都和对方建立EBGP邻居,这么做的缺点是,损失了可扩展性。因为在两条链路上分别宣告了BGP,E0/0一个BGP,E0/1一个BGP,也就是一共有两个宣告了BGP的链路,所以所有的路由信息会被宣告两次。
经过分析可以发现,上面的两个方案都在高可用性和扩展性方面都存在着一定问题,所以这次不用两台路由器之间直连的地址建立EBGP邻居,而用两个路由器上的Lookback接口建立EBGP邻居。为什么这么做呢?因为loopback接口不是物理上存在的接口,而是一个逻辑上的接口,能够同时提供高可用性和扩展性。高可用性就是,只要两个设备之间的TCP连通性还在,用Loopback接口建立的邻居就不会Down掉,可以充分的利用冗余链路;扩展性就是,两台路由器之间还能加入更多的物理链路,而不会影响Loopback接口,也不用加入其他的配置。Loopback接口会一直保持的up的状态,除非两设备之间的物理链路断掉或逻辑接口被人为Shutdown。当然这两个Loopback接口之间并不是物理直连,所以这两个路由器上必须有对方Loopback的路由,保持这两个Loopback接口的TCP连通性,因为BGP协议的传输层用的是TCP协议。一般情况下,EBGP会用静态路由来保证两个Loopback接口的TCP连通性,而IBGP则用IGP(OSPF、EIGRP)协议提供Loopback的连通性。
配置过程
由于要用Loopback接口建立邻居,所以在R1和R2上进行如下配置:
R1
1 | interface Loopback0 |
R2
1 | interface Loopback0 |
但配置过后发现,两者并未建立起BGP邻居,由于BGP在传输层采用TCP协议,所以先测试TCP协议是否成功建立,使用Ping命令测试两边Loopback接口的连通性:
1 | R2#ping 1.1.1.1 source 2.2.2.2 |
发现两边接口没问题,此时用debug ip bgp查看输出后发现:
1 | R1(config)# |
这个Debug前半段显示的是,配置中的Update源头不存在,这是一个EBGP邻居会话独有的错误提示,默认情况下,运行思科IOS系统的路由器会用出接口,在这里是E0/0和E0/1,去连接配置中邻居的地址2.2.2.2,所以这个错误提示其实是说,2.2.2.2这个地址和本路由器不直连:
1 | R1#show ip cef 2.2.2.2 |
输入命令show ip bgp neighbors 2.2.2.2 | include External BGP neighbor也能得到类似的结果:
1 | R1#show ip bgp neighbors 2.2.2.2 | include External BGP neighbor |
为什么在两边都有对方Loopback接口路由的情况下,依然TCP连接还失败呢?一方面是因为BGP的报文默认TTL为1,而两个Loopback接口之间至少需要两跳,也就是至少TTL=2才行,所以TCP连接一直无法建立;另一方面是因为BGP默认的update接口为直连口,必须将update源配置为Loopback接口才行。

所以分别在R1和R2上配置如下命令BGP才能顺利建立邻居关系:
1 | R1: |
Update-source
BGP建立邻居时没有用到组播地址,所以它无法像IGP那样自动发现邻居,需要手工指定,邻居的IP由本地的BGP neighbor命令指定,而该BGP连接的源IP(更新源)默认情况下为流量的出接口IP,只有当本地配置的邻居IP与邻居用于BGP连接建立的源IP相同时,BGP连接才能被正常建立,如果两台路由器之间需要用Loopback接口建立邻居,那么对方的Loopback接口就不是直连的IP,不满足BGP建立邻居的要求,无法建立起BGP邻居,解决这个问题,需要配置neighbor x.x.x.x update-source Loopback0这条命令,下面来看EBGP和IBGP两种不同情况:
- EBGP邻居之间的建立通常用直连的IP地址建立,建立EBGP邻居关系时,会首先检查直连路由,并且TTL默认为1,这么做是为了确保想要建立的邻居路由器和本路由器之间只有一跳,这么设计的初衷是为了保护EBGP的会话,缓解收到基于TCP或IP的攻击,也说明BGP的设计者认为EBGP用直连接口建立是最好的选择。如果此时用Loopback接口建立邻居的话就,就得指定Loopback接口为更新源,也就是配置一条neighbor x.x.x.x update-source Loopback0的命令,从而顺利完成邻居建立。那么,是需要在两边都配置这条命令还是只需要在一端配置呢?各个厂家的规定不同,思科只在一端配置****即可,但Juniper是必须在两端都配置该命令才能建立起邻居,所以严谨起见还是查阅厂家文档更万无一失。当R1和R2到对方的Loopback的网段使用静态或动态路由获取时,BGP邻居可以正常建立,但如果两端都用默认路由互指的话,BGP邻居无法正常建立,这么设计的原因是为了防环。
- IBGP为了保持邻居关系的稳定,一般使用Loopback接口建立,这是因为如果使用物理接口,一旦用于建立BGP邻居关系的接口发生故障,BGP邻居就Down了,而且在AS内部,通常路径都是由冗余备份的,也就是有多条路径能够到达两个路由器,邻居之间的Loopback路由可通过IGP获取并提供一定的路由冗余性,只要还有其他的路径能维持两台路由器之间的TCP连通性,则BGP邻居就不受单一路径故障的影响,能一直维持BGP邻居的稳定。所以IBGP邻居用Loopback接口建立邻居时,也需要配置TTL和update-source这两条命令。
一端配置分析
在上面的拓扑中,如果使用思科设备时只在一端,比如只在R2上配置了Update-source Loopback0这条命令,则建立邻居的步骤如下:
R1尝试建立源为1.1.1.1,目标为2.2.2.2的EBGP邻居;
R2尝试建立源为2.2.2.2,目标为1.1.1.1的EBGP邻居;
R1收到R2试图建立TCP连接的SYN报文,因为TCP成功建立连接后路由器才会发送Open报文开始建立BGP邻居,R1拒绝了R2建立邻居的请求,因为R1上并没有配置Update-source Loopback0这条命令,所以R1认为它要和2.2.2.2建立邻居,而不是12.1.1.2<因为BGP连接的源IP(更新源)默认情况下为流量的出接口IP>;
R2收到了R1试图建立TCP连接的SYN报文,并且接受了TCP连接建立的请求,因为TCP连接的源地址为1.1.1.1,目标地址为2.2.2.2,R2配置了Update-source Loopback0这条命令,将BGP连接的更新源地址配置成了Loopback0;
R2用TCP的SYN-ACK报文回复R1,回复的报文源地址为2.2.2.2,目标地址为1.1.1.1;
R1收到了R2发过来的SYN-ACK报文,回复了TCP的ACK报文;
R1和R2之间的TCP连接成功建立,R1是TCP的Client端,R2是TCP的Server端,TCP连接建立的抓包如下:

Update-source Loopback0这条命令只会对路由器初始化TCP连接时的动作产生影响,而不会对路由器作为TCP Server去回应TCP连接的动作产生影响。只要路由器从配置的neighbor地址上收到请求,就会允许连接建立。具体到上面的例子就是,R2配置了Update-source Loopback0这条命令,所以会使用2.2.2.2作为更新源,尝试与1.1.1.1建立BGP连接,而R1没有配置更新源的命令,所以更新源还是默认的12.1.1.1,但两者之间的TCP连接建立是没问题的,因为R2向R1的连接是没问题的。
如果使用loopback接口建立连接时忘记配置update-source这条命令,在debug bgp的时候会显示类似‘BGP: 2.2.2.2 Active open failed - tcb is not available, open active delayed 12288ms (35000ms max, 60% jitter)’的信息,里面的tcb表示tcp control block,也就是TCP连接受阻。
从上面可以看到,仅需保证一方满足上面的条件即可,也就是说一边配置update-source Loopback0命令即可,但为了加深印象、加快邻居建立以及防止漏配方便排错,建议两边都配置上。
ebgp-multihop
如果在配置ebgp-multihop时并未指定具体条数,也就是配置了neighbor x.x.x.x ebgp-multihop命令时,则BGP报文的TTL被设置为255的同时,路由器会放弃直连检测;
如果在配置ebgp-multihop时明确的将数值配置成1,也就是配置了neighbor x.x.x.x ebgp-multihop 1,则BGP报文的TTL仍旧为1,路由器也会继续进行直连检测;
如果在配置bgp-multihop时将条数配置为2-255之间的数值,也就是配置了neighbor x.x.x.x ebgp-multihop {2-255},则BGP报文的TTL值会配置为配置中的具体值,路由器放弃直连检测。
思科的文档中描述该命令时说的是:
To accept and attempt BGP connections to external peers residing on networks that are not directly connected, use the neighbor ebgp-multihop command in router configuration mode.
翻译过来大概意思是,如果想要建立不直连的EBGP邻居时,需要配置该命令,不配置该命令的默认情况下,只有直连的邻居可以建立,因为EBGP默认情况下使用直连接口作为更新源。由于只有直连能够建立邻居,不配置ebgp-multihop时,R1的Loopback接口和R2的Loopback接口无法建立邻居,所以说明不用直连接口建立邻居时,肯定使用了直连检测看建立邻居的接口是否直连。那么能不能只把直连检测关闭呢?因为如果R1和R2之间直连用Loopback接口建立邻居时,TTL=1是能保证两者BGP报文相互传达的,因为中间没有其他路由器,TTL只有经过路由器时才会减1。答案是可以只关闭直连检测,用到的命令是:neighbor x.x.x.x disable-connected-check。
disable-connected-check
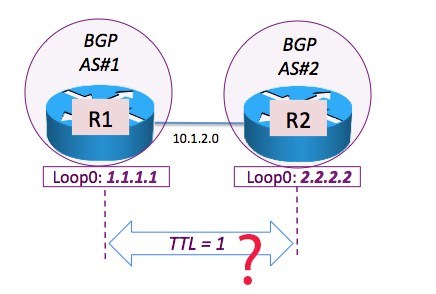
图中R1和R2直连但属于不同的AS,如果此时想用Loopback接口建立BGP邻居,那么两个Loopback接口之间的TTL是多少才能确保顺利通信呢?答案是1,因为在R2上用traceroute 1.1.1.1 source 2.2.2.2 ttl 1 1时,TTL=1也是能顺利trace到R1的1.1.1.1:
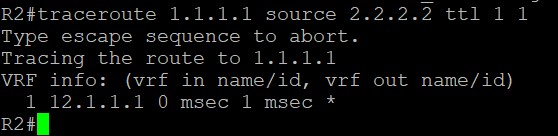
所以如果R1和R2此时想用Loopback接口建立邻居,且希望TTL=1应该如何呢?配置neighbor x.x.x.x disable-connected-check就能关闭直连检测用TTL=1建立Loopback邻居。
EBGP多跳邻居
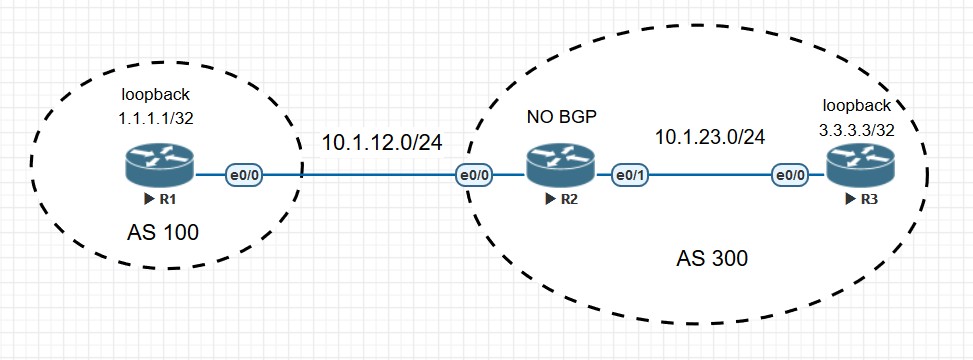
TCP阶段配置:
R1和R3用Loopback接口建立邻居,首先要考虑两个Loopback接口的TCP连通问题,这里用静态路由实现:
R1:
1 | interface Loopback0 |
R2:
1 | interface Ethernet0/0 |
R3:
1 | interface Loopback0 |
配置完上述命令后,在R1或R3上分别ping对方的Loopback接口测试两个Loopback接口之间的连通性:

BGP阶段配置
R1:
1 | router bgp 100 |
R3:
1 | router bgp 300 |
配置完BGP后,查看BGP邻居建立情况:

GRE隧道建立eBGP
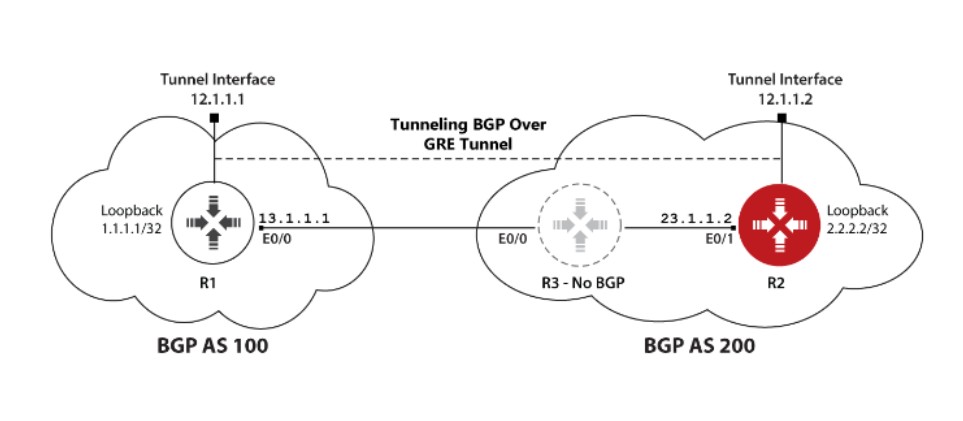
TCP连接建立阶段
用GRE隧道建立BGP连接,首先要保证GRE隧道两端隧道的地址以及两个Loopback接口的连通性,这里用静态路由实现。由于使用了GRE隧道,R3上就不需要为1.1.1.1或2.2.2.2配置静态路由,因为GRE隧道的原目的IP地址是13.1.1.1和23.1.1.2:
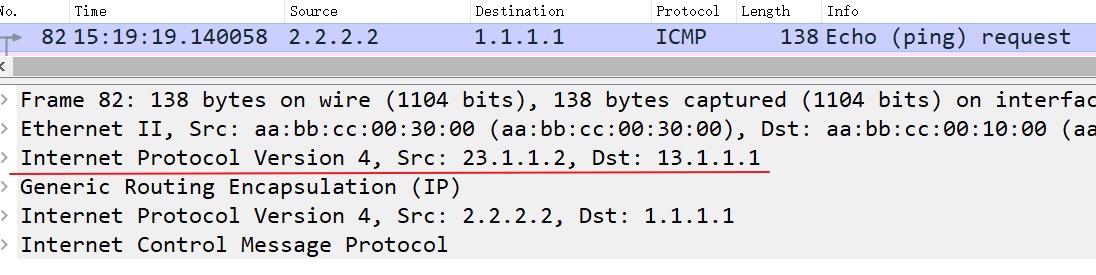
R3和这两个端口直连,已经有了它们的路由:
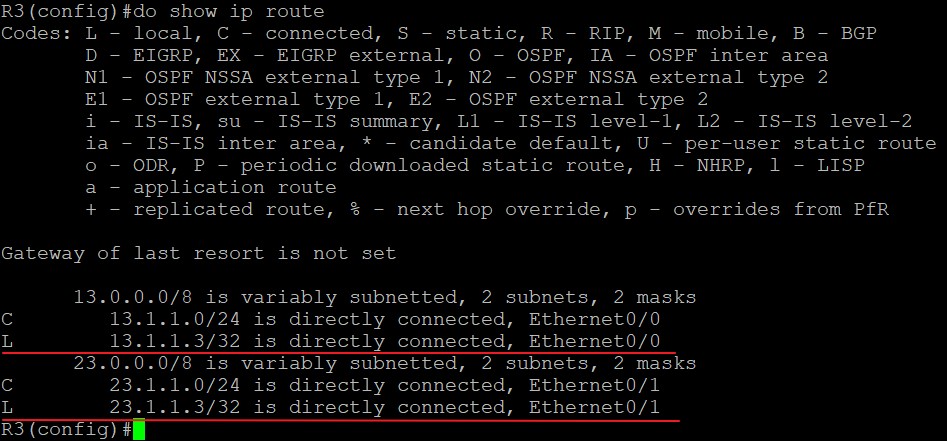
所以在配置完tunnel和静态路由后,TCP连通性已经没有问题。
BGP连接建立阶段
R1
1 | interface Loopback0 |
R2
1 | interface Loopback0 |
通过上面的配置,R1和R2可以在不改变BGP的TTL值情况下成功建立邻居,这种使用Loopback接口通过Tunnel(隧道)方式建立的BGP邻居,在逻辑上只有一跳,比如TCP建立过程中的SYN包中的TTL为1:
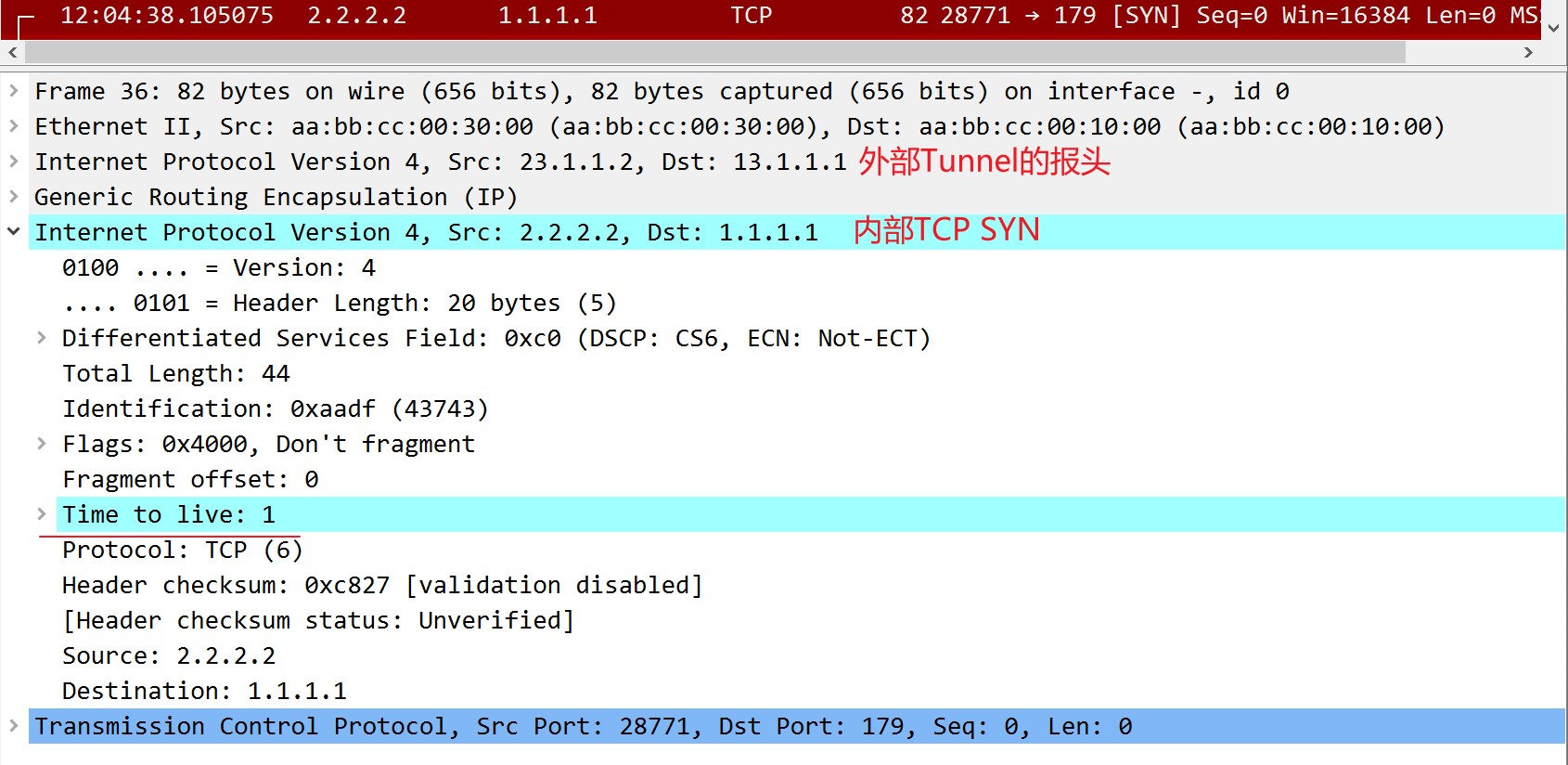
所以结合上边几个实验可以得出结论,当配置了正确的update更新源时,ebgp-multihop命令只需要在两台设备物理上被其他设备隔开,也就是需要物理上多跳时必须配置,因为这种情况下的TTL大于默认值1;在设备直连并且通过Loopback接口建立邻居时,只是用‘disable-connected-check’命令就能建立起邻居,因为这种情况下的TTL=1,和默认的TTL相同,只需要关闭直连检测就行。
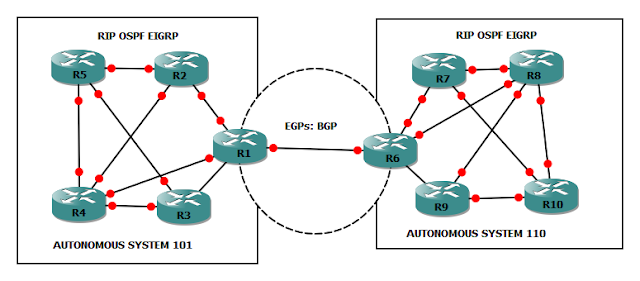
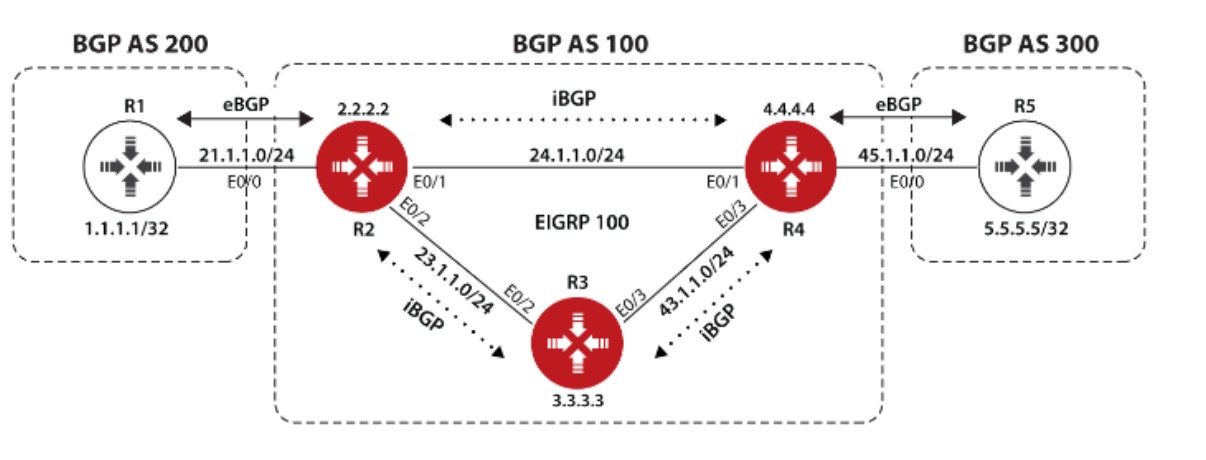
iBGP直连邻居建立
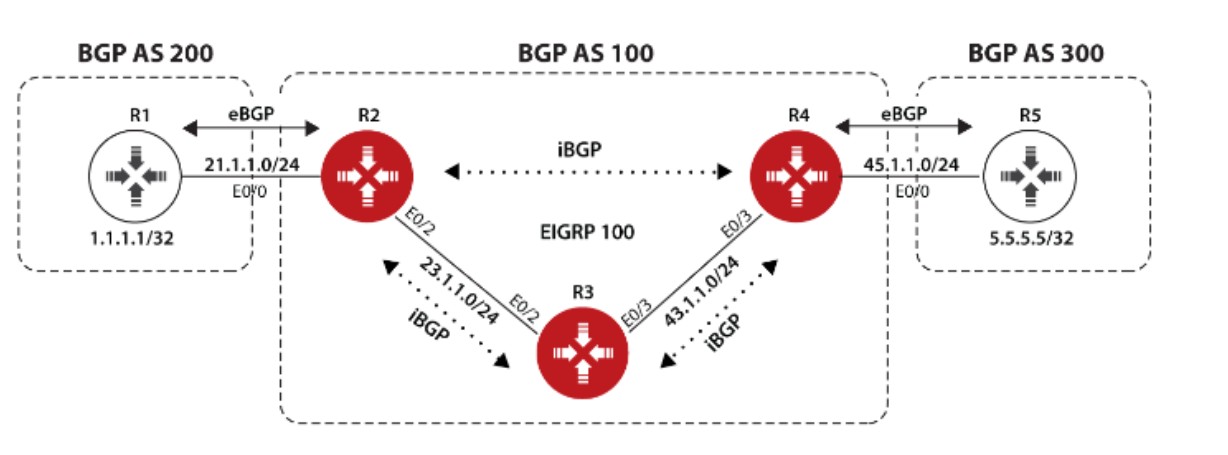
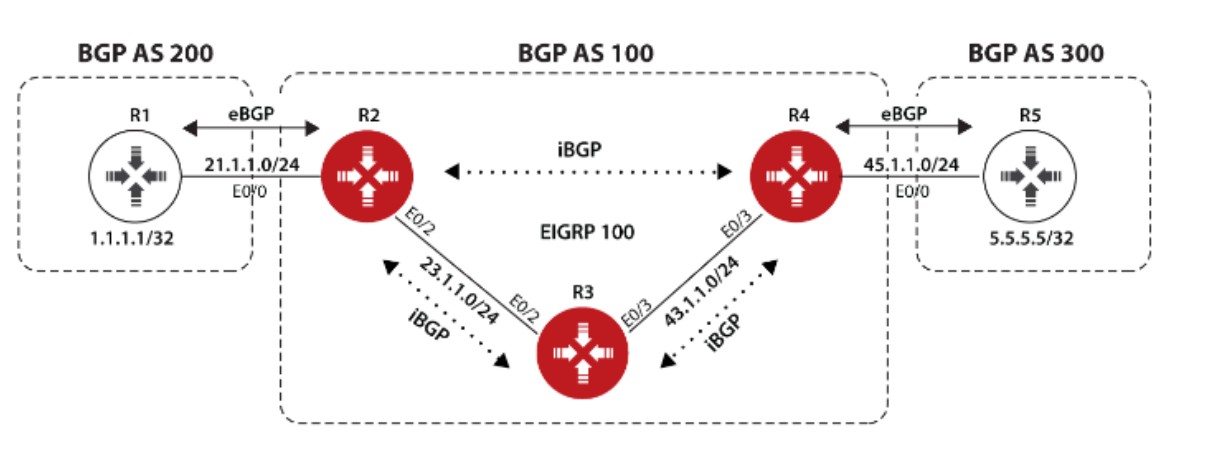
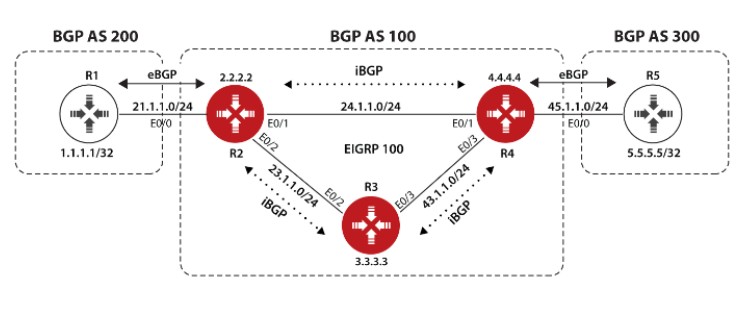
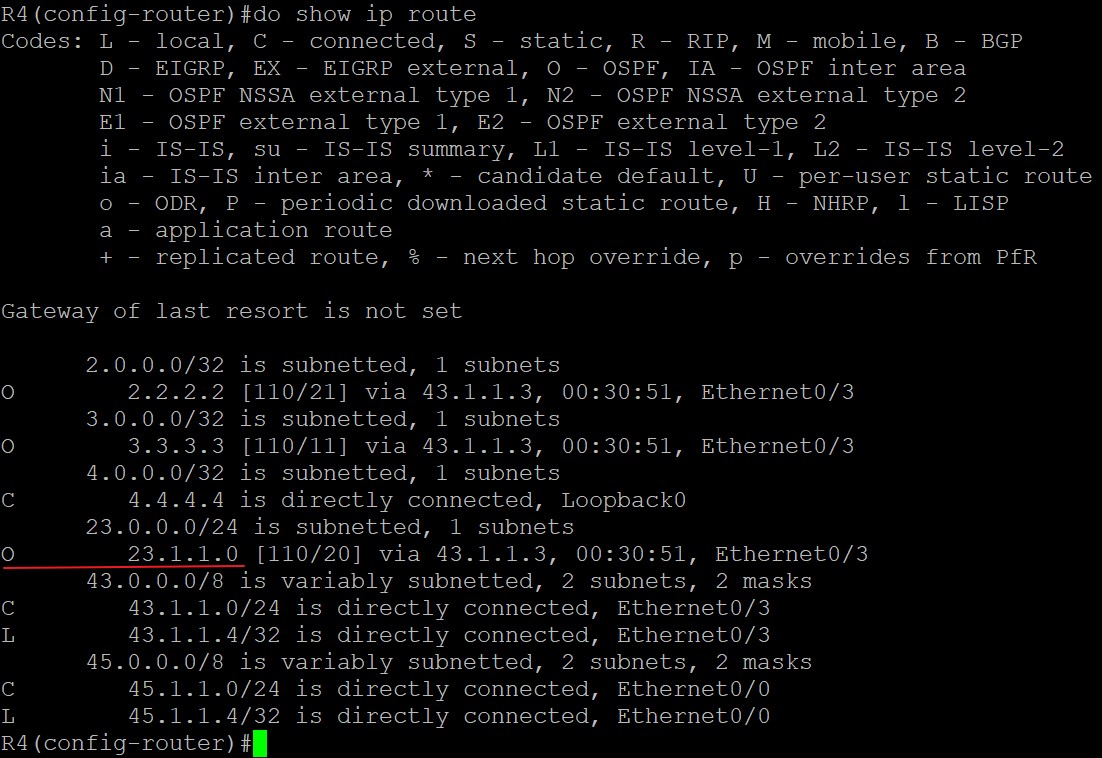
上图中,AS100有两个相邻AS,AS100和AS200,由于AS100会承载起源和目标都不在本AS的流量,比如位于AS300的R5要发送数据给位于AS200的R1时会经过AS100,所以AS100是一个Transit AS,R2和R4是AS100的边界路由器;AS200和AS300由于之和AS100相连,所以它俩是Local AS;为了成功传递AS200和AS300之间的流量,所以两个边界路由器,R2和R4必须想办法交换他们从eBGP邻居那学到的路由条目,这种情况下就要用到iBGP了,R2和R4建立iBGP邻居后,两者就能交换彼此的路由。与eBGP不同,iBGP不在乎两个iBGP邻居之间的跳数是多少,因为iBGP设计的初衷就是为了让处于AS边界的路由器,例如R2,把它从eBGP邻居那学到的路由发送给在同一个AS的其他边界路由器,比如R4,虽然图中R2和R4之间只间隔了一个路由器R3,但在实际中两个边界路由器之间可能隔着很多其他路由器,因此没法要求iBGP邻居之间直连。
TCP连接建立阶段
前面说过,要使得R2和R4建立BGP邻居首先要保证两台路由器TCP层面的连通性,可以使用静态路由或动态路由来达到这个目的从而使得BGP邻居顺利建立,这个实验中,我们用OSPF协议来保证AS100内部三个路由器彼此的TCP连通性,配置OSPF的时候在R3上偷懒使用了network 0.0.0.0 0.0.0.0 area 0,生产网络中中为了提高安全性还是尽量别这么配置,要宣告接口进OSPF,下面来看基本配置和连通性配置:
R1:
1 | interface Loopback0 |
R2:
1 | interface Loopback0 |
R3:
1 | interface Loopback0 |
R4:
1 | ! |
R5:
1 | interface Loopback0 |
这时查看R2、R3、R4的路由表可以发现,他们彼此有对方全部接口的路由,所以TCP连接没问题:
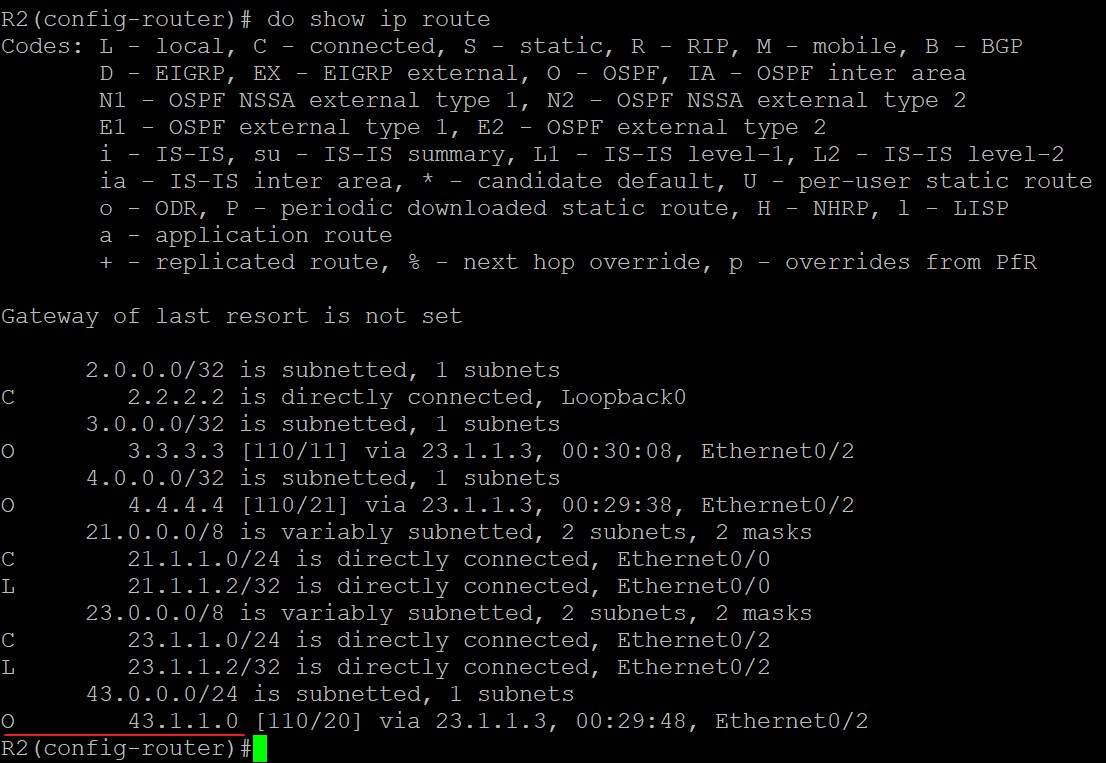
BGP连接建立阶段
BGP阶段的目标是,R2、R3、R4彼此之间建立全互联(Full mesh)的iBGP邻居,R1和R2建立eBGP邻居,R4和R5建立eBGP邻居。配置如下:
R1:
1 | router bgp 200 |
R2:
1 | router bgp 100 |
R3:
1 | router bgp 100 |
R4:
1 | router bgp 100 |
R5:
1 | router bgp 300 |
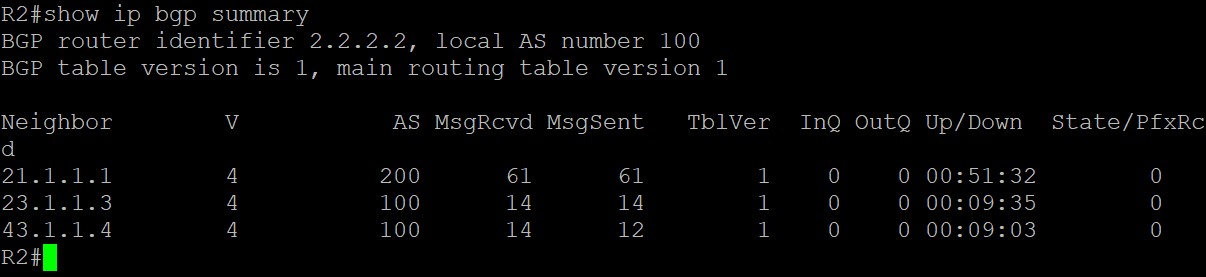
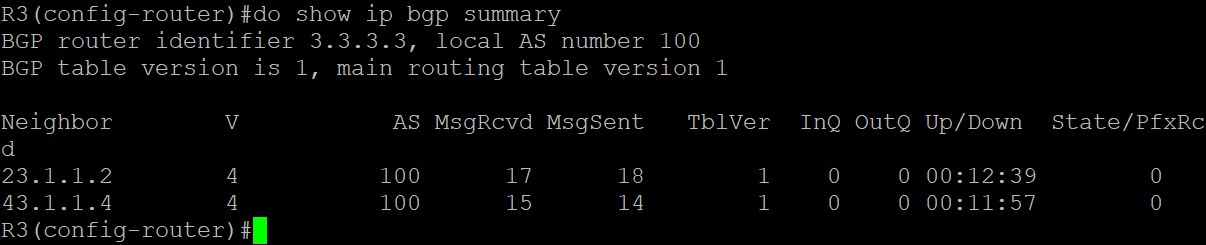
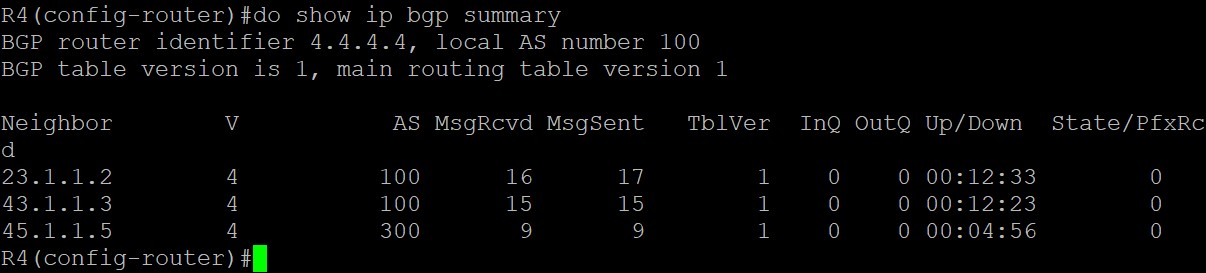
用show ip bgp summary命令查看各路由器之间邻居建立关系:
iBGP邻居Loopback口建立
TCP连接建立阶段和上个实验相同,依旧用OSPF建立TCP连接,这里就不再赘述了,下面来看BGP连接建立阶段。
R2:
1 | router bgp 100 |
R3:
1 | router bgp 100 |
R4:
1 | router bgp 100 |
配置完后查看BGP邻居可以看到三个路由器之间彼此建立了iBGP邻居:
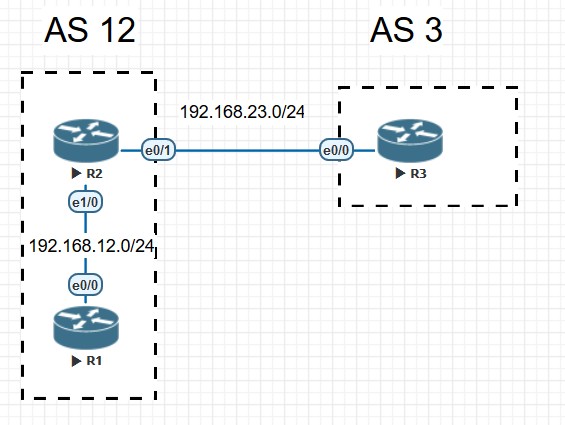
iBGP邻居Next-hop-self
iBGP邻居的一个潜在的坑就是,它不会自动更改next-hop-self也就是不会改变BGP表中的下一跳部分的值,让我们具体看个例子:
基本配置
R1和R2是iBGP邻居,用OSPF协议保证TCP连通性;R2和R3是eBGP邻居,用直连接口建立。
R1:
1 | interface Loopback0 |
R2:
1 | interface Loopback0 |
R3:
1 | interface Loopback0 |
此时iBGP、eBGP邻居都已顺利建立:
路由分析
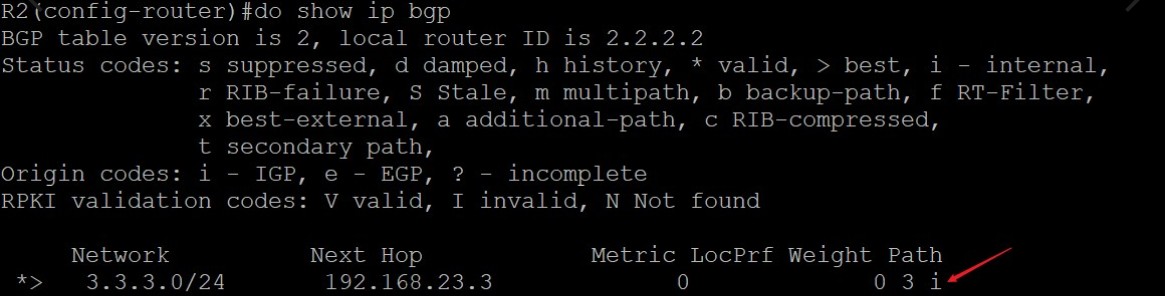
R3使用network命令将3.3.3.0/24的路由引入BGP,该路由在R3上是最优,所以传递给eBGP邻居R2,由于3.3.3.0/24始发于R3,所以在R3上的下一跳值为0.0.0.0:
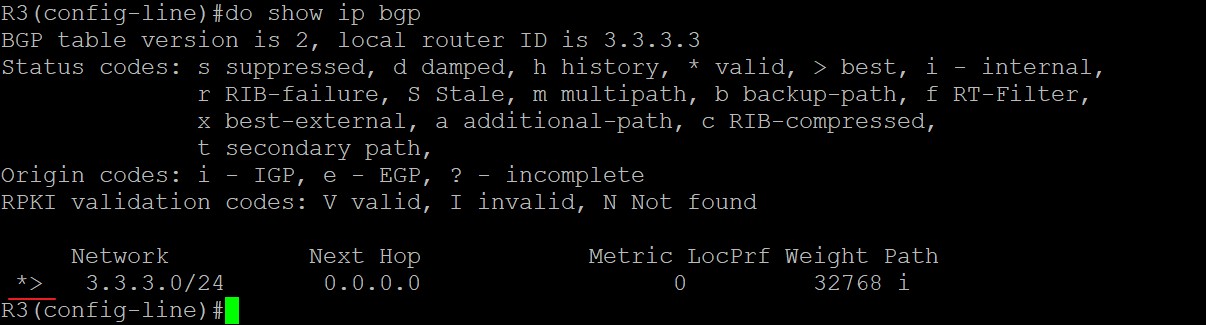
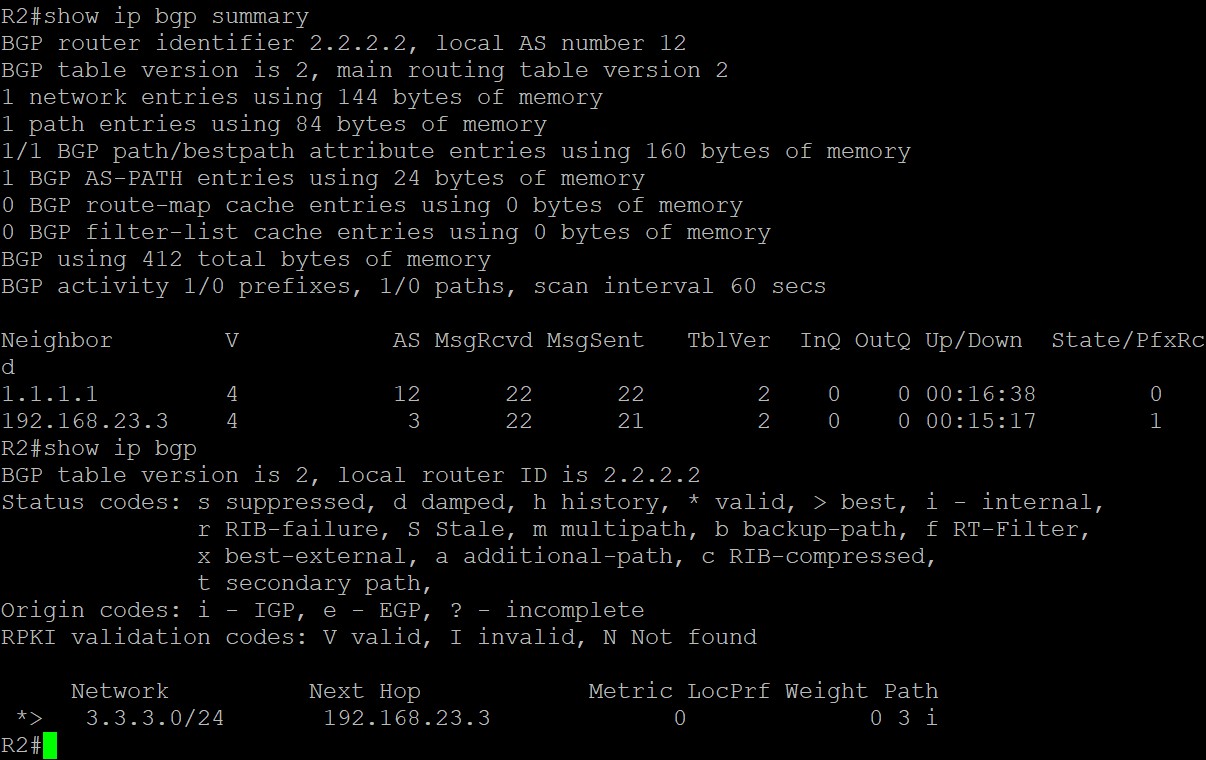
现在来看R2上关于3.3.3.0/24的路由,收到R3发来的eBGP路由后,由于没有入向策略,所以这条路由不会被入向策略拒绝而直接进入Adj-RIBs-in路由表中,第一步先会检查下一跳是否可达,在R2上,这条路由的下一跳地址是192.168.23.3,R2的路由表中有去往该地址的路由,因为R2和它直连,所以这条路由有资格被选做最优的BGP路由;第二步进行BGP的路径选择,由于去往3.3.3.0只有一条BGP路由故该路由直接为最优,思科在前面加上>表示Best;第三步BGP将这条是Best的路由的BGP放入Loc-RIB和Adj-RIBs-out表中,放入Adj-RIBs-out中的路由会更新发送给其他邻居,在本拓扑中也就是也就是发送给R1;第四步这条最优的BGP路由会发送到路由表,经过执行路由表选择程序,看它能否放入路由表中,由于R2的IGP路由表中没有关于3.3.3.0这条前缀的路由,所以这条BGP就是最佳的路由,最终加入路由表中。
这条路由中的Next Hop部分为什么是192.168.23.3呢?因为R2和R3使用直连接口建立邻居,eBGP邻居发过来的路由使用更新源地址作为Next Hop,也就是eBGP邻居彼此建立邻居用的地址,R2上配置eBGP邻居的命令是‘neighbor 192.168.23.3 remote-as 3’,所以由R3这个eBGP邻居宣告过来路由的下一跳是192.168.23.3。假设如果两者使用Loopback接口建立eBGP邻居,则R3宣告给R2的路由的Next Hop部分就是R3的Loopback接口地址。
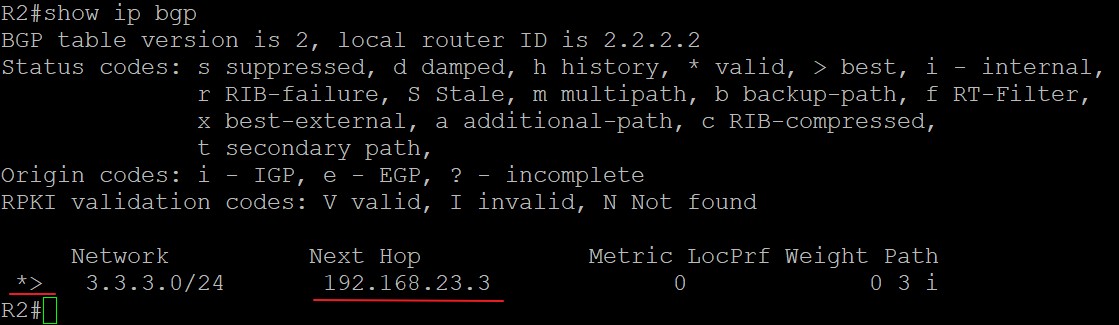
R1收到来自iBGP邻居R2的关于3.3.3.0的BGP路由,由于没有入向BGP策略所以将该路由放入Adj-RIBs-in中:
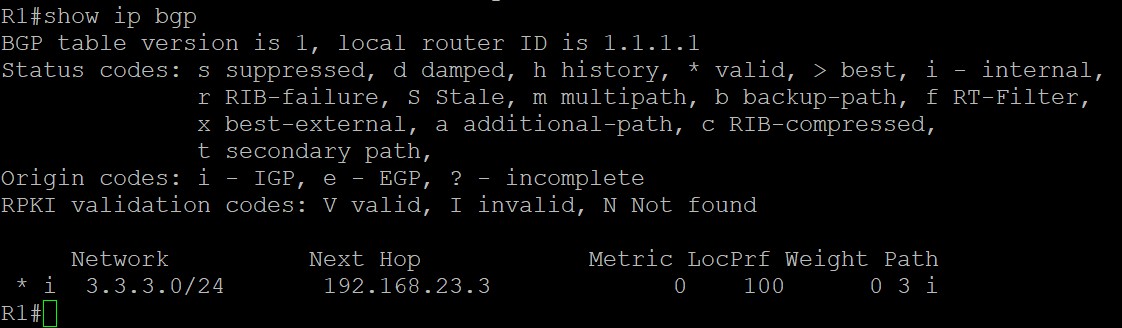
可以看到,这条BGP路由在R1上的下一跳依旧是192.168.23.3,这是因为路由来自iBGP邻居时Next Hop部分在AS内传递时不会发生改变(除非做了策略),这个Next Hop始终指向的是下一个AS,也就是通告该路由的eBGP邻居的接口IP,具体到这个拓扑中就是,R1收到来自iBGP邻居R2的这条路由时,不会对Next Hop部分做更改,3.3.3.0这条路由的Next Hop在AS12内传递时的Next Hop始终是R3和本AS建立邻居的接口的IP地址,192.168.23.3。
但查看R1的路由表会发现,R1路由表中并没有到下一跳192.168.23.3的路由,所以这条路由并不是最优的BGP路由也不会加入路由表:
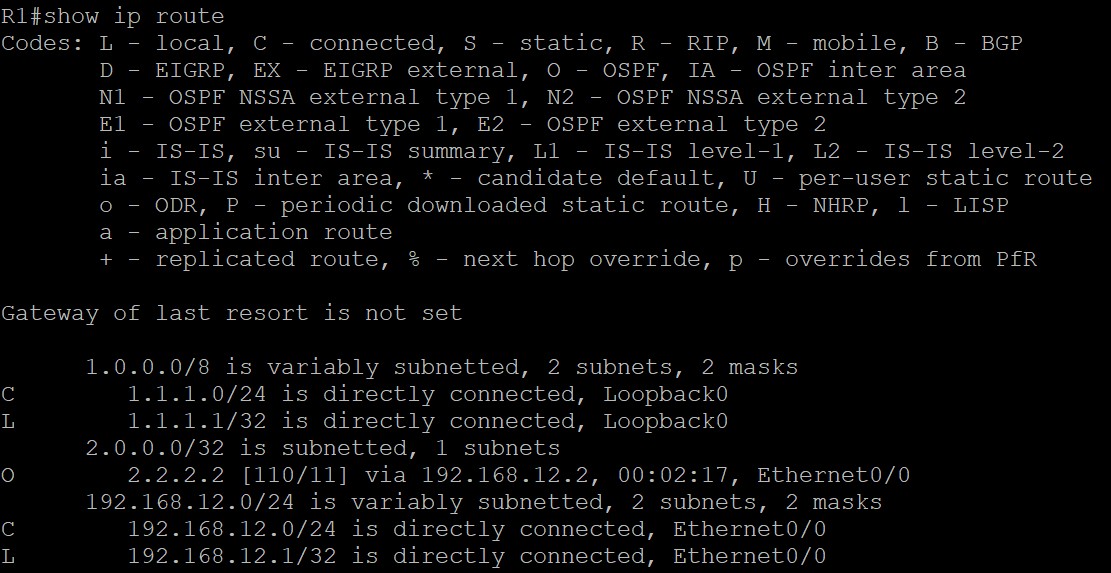
那么,R1即使有到3.3.3.0的路由但这种情况下却没法给该前缀发送数据,如果想给该路由发送数据怎么办呢?可以看到,R1之所以没法给该前缀发送数据是因为下一跳不可达,所以该路由并不是最佳路由也没法加入路由表,只需要将下一跳可达,那么这条路由就能加入路由表,R1也就能给该前缀发送数据了,如何让下一跳192.168.23.3可达呢?有两种方法,一种是将192.168.23.0网段宣告进BGP,另一种现网中在使用的是使用Next-hop-self命令改变这条路由的下一跳地址,这里只具体分析这种方法,在R2上配置:
1 | R2(config)#router bgp 12 |
来看看配置前后BGP表的变化:
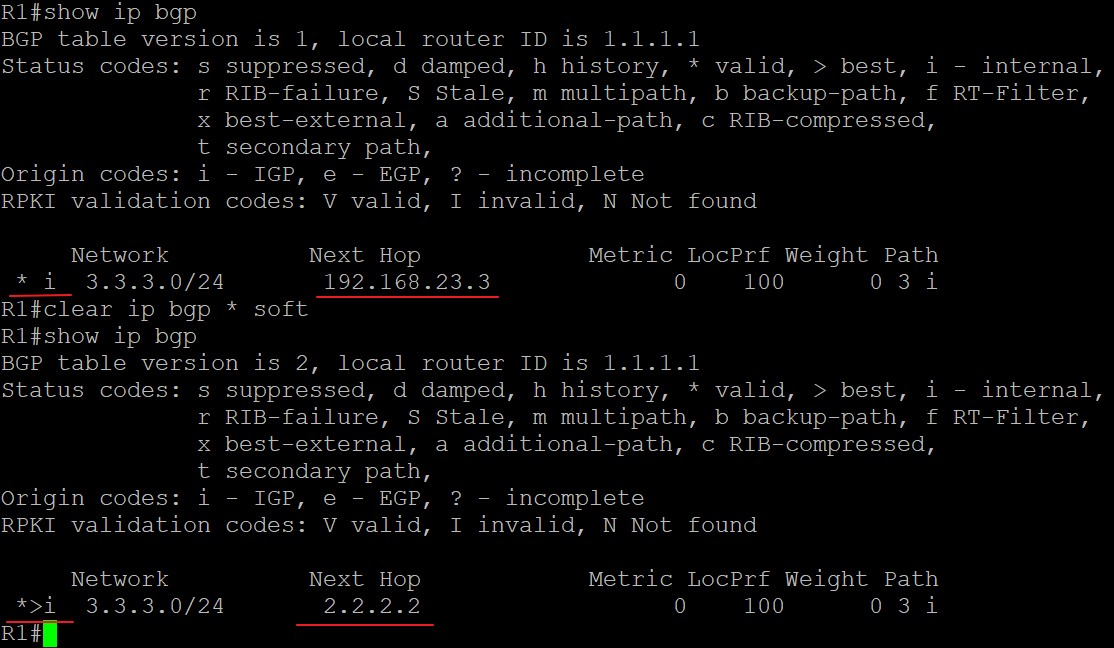
在R2上对邻居R1配置了Next-hop-self命令后,R2上该BGP路由的Next Hop值由不可达的192.168.23.3变为了2.2.2.2这个可达的地址,于是该BGP路由也是Best的,由于没有其他IGP路由,所以直接加入路由表,于是R1可以发送数据到3.3.3.0网段。
Peer Group
当配置BGP邻居时,可能有时每个邻居的配置除了地址以外完全相同,为了避免每个邻居都要重复舒服一边命令,可以使用peer group来简化输入流程。
EBGP邻居实验
当R1分别和R2、R3、R4用Loopback接口分别建立EBGP邻居并且将路由的metric设置为6666时,会发现配置R1时,每个邻居都要配置update-source loopback0和ebgp-multihop2:
1 | R1: |
如果使用peer group的话,可以省掉那些配置相同的部分,不用每个邻居都配置一遍:
1 | R1(config)#router bgp 1 |
R2\R3\R4的配置如下:
1 | R2: |
IBGP邻居实验
TCP层用OSPF打通,为了节省配置直接配置的‘network 0.0.0.0 255.255.255.255 area 0’
1 | R1: |
如何宣告前缀进BGP
宣告前缀进BGP有两个方法,
- 用Network命令;
- 重分布;
Network命令
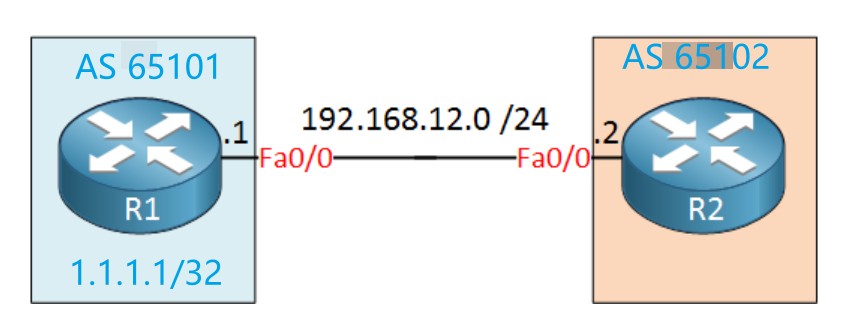
R1:
1 | router bgp 65101 |
R2:
1 | router bgp 65102 |
上面在宣告1.1.1.1/32这条路由进BGP时,必须宣告的和IGP路由表中的路由完全一样才行,也就是说前缀和掩码都必须相同,因为Loopback0的IP地址为1.1.1.1/32,所以在IGP路由表中是:
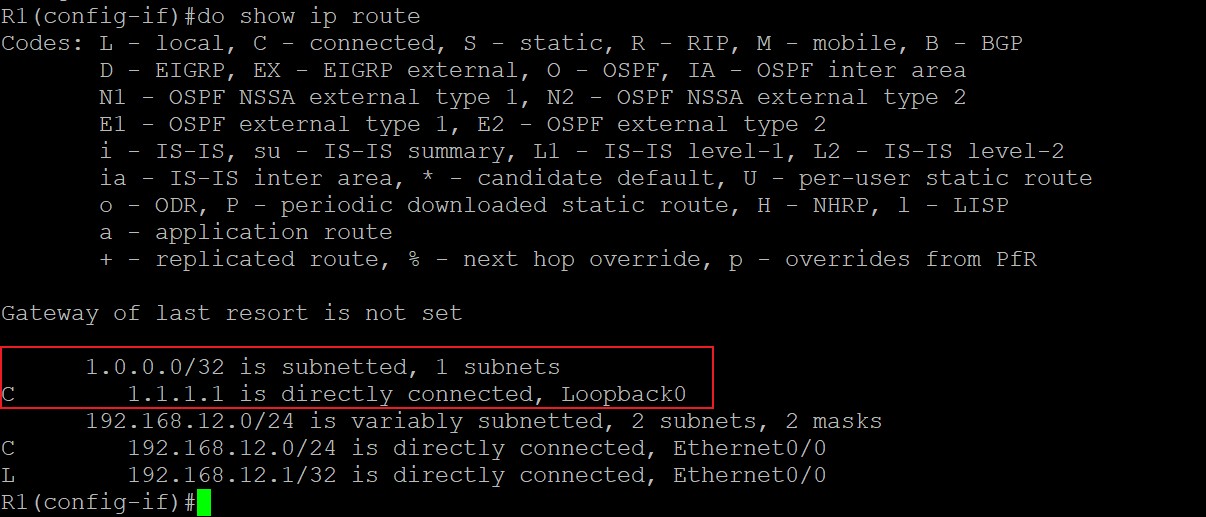
所以应该宣告1.1.1.1掩码为32位进BGP,也就是network 1.1.1.1 mask 255.255.255.255。如果此时network命令后的前缀和路由表中不一样则输入的命令不会有效。如果宣告正确的话如图所示:
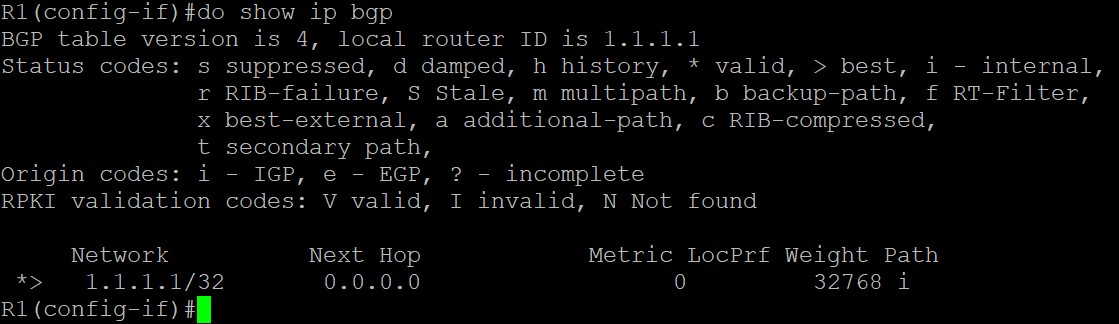
重分布命令
也可以使用redistribute命令将路由重分布进BGP,用比如此时我们在R1上创建一个IP地址为111.111.111.111/32的Loopback接口,将该接口宣告进OSPF协议,并将OSPF协议用‘redistribute ospf1’重分布进BGP进程,会得到以下BGP表:
1 | R1(config-router)#do show ip bgp |
BGP黑洞与同步
实验说明
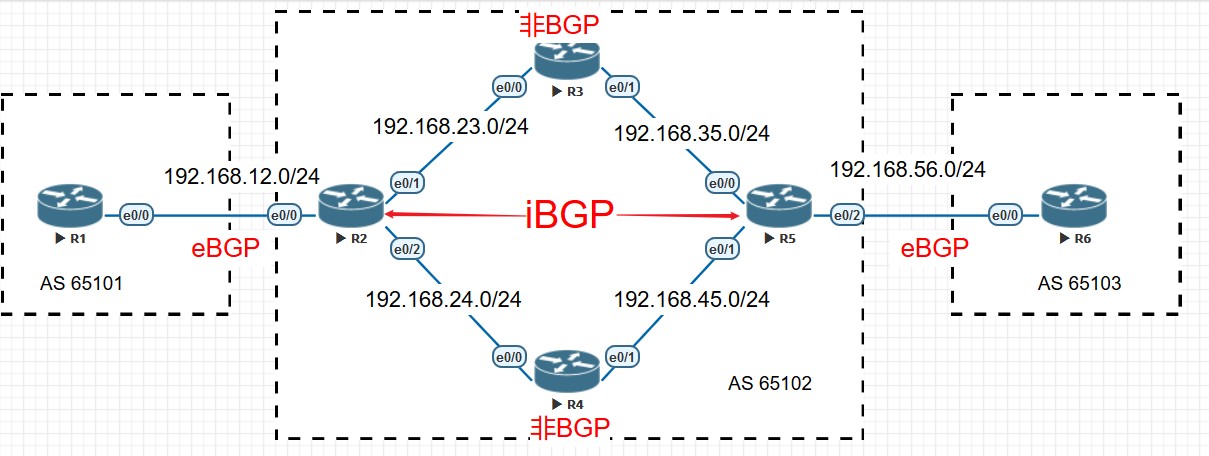
拓扑如上,R1和R2,R5和R6之间为eBGP邻居关系,R2和R5之间为iBGP邻居,R3和R4不运行BGP协议。
基本配置
R1:
1 | interface Loopback0 |
R2:
1 | interface Loopback0 |
R5:
1 | interface Loopback0 |
R6:
1 | interface Loopback0 |
R6的BGP表和路由表:
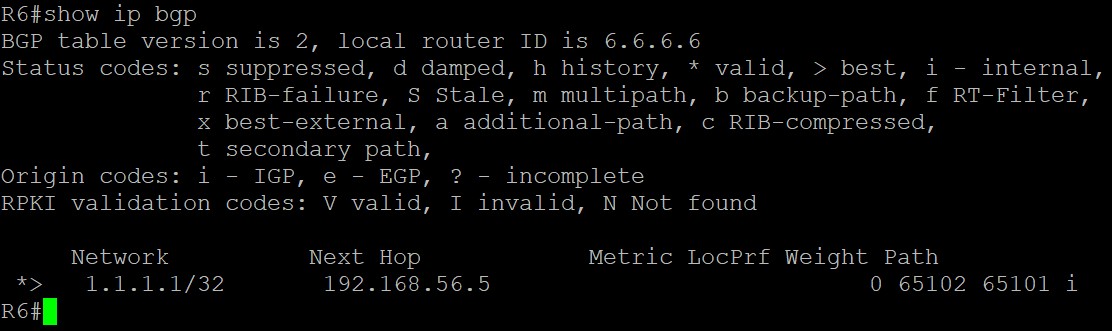
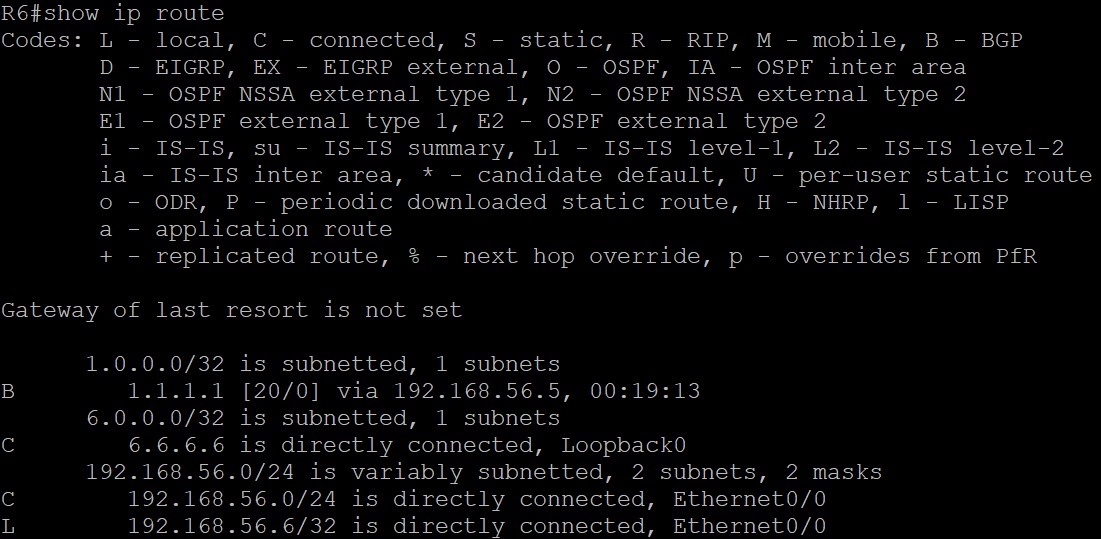
路由分析
中间的AS 65102为Transit AS,AS 65102里的路由器的TCP连接由OSPF协议连通,R1上宣告了一条1.1.1.1/32的路由,宣告给eBGP邻居R2,由R2宣告给iBGP邻居R5,在R2上对邻居R5配置了Next-hop-self命令所以该路由在R5上是最优,可以最终传递给R5的eBGP邻居R6。但要注意,R2将BGP路由更新传递给R5时,是将BGP的update报文放在IP报内经过R3或R4发送给R5的,对于不运行BGP协议的R3和R4来说,这个BGP的update报文都是普通IP包,源目的地址为5.5.5.5和2.2.2.2,这两个地址的路由它们的路由表中有,可以正常转发,它们直接转发而不查看内部:

此时在R6上能否ping通1.1.1.1呢?答案是不能,为什么不能ping通呢?先看R6,R6的路由表中有1.1.1.1/32的路由,下一跳是192.168.56.5,路由表中有到下一跳的路由,从E0/0发出即可:
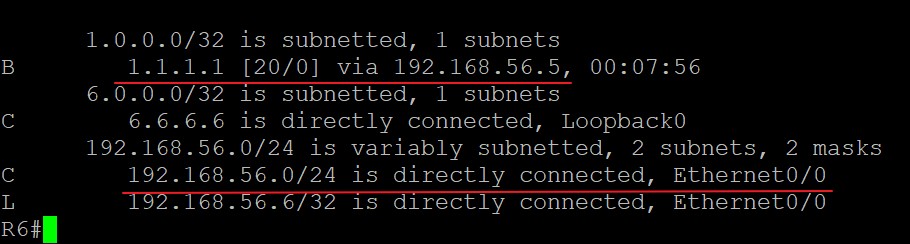
现在Ping包到了R5:
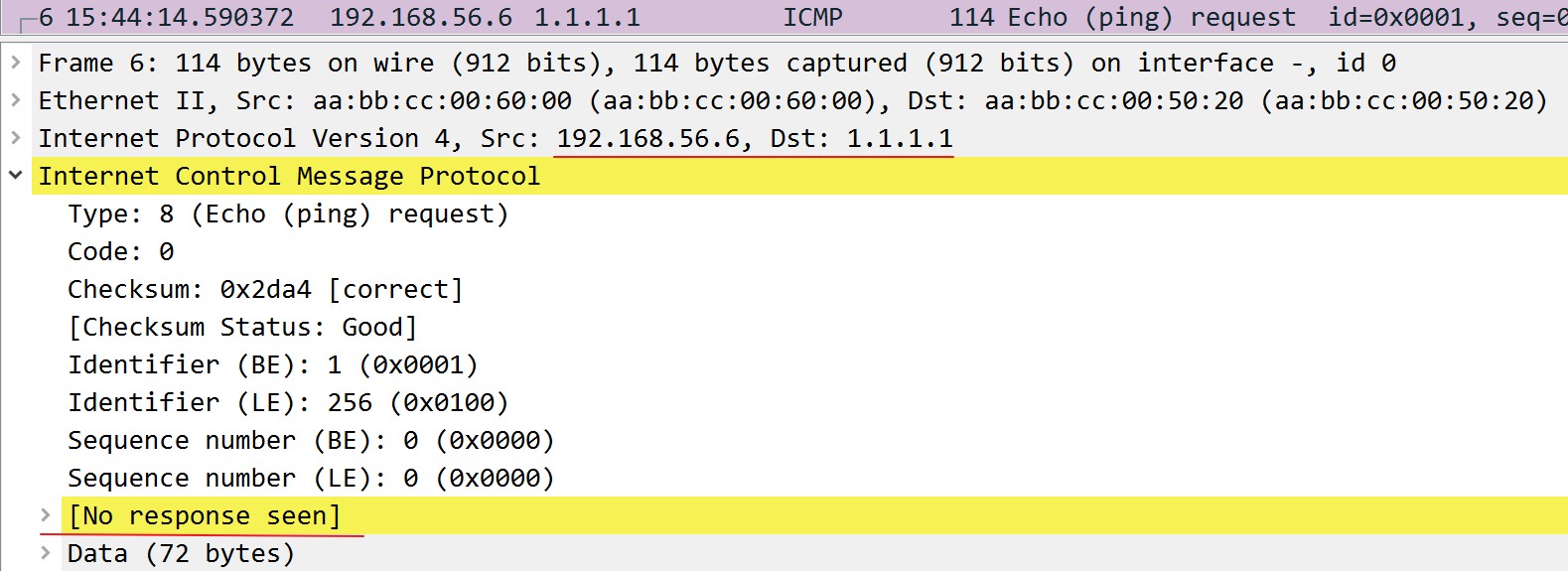
从抓包中可以看到,ping包(ICMP)到了R5以后,目标IP地址是1.1.1.1,而R5的路由表中到1.1.1.1的下一跳是2.2.2.2,而到2.2.2.2的下一跳是192.168.45.4或192.168.35.3,也就是把数据包交给R3或R4,而R3或R4由于不运行BGP,不会知道去往会丢弃掉去往1.1.1.1这个不知道目的地的数据包,所以ping包无法通,至此形成路由黑洞。经过R3去往1.1.1.1网段的ping包抓包如下:

问题产生的原因就是不运行BGP的R3、R4不知道AS外部1.1.1.1如何到达,要解决路由黑洞就要让中间的R2、R3有这个路由,可以采取iBGP全互联,将外部路由重发布进IGP(BGP的庞大路由对IGP来说一般无法搞定),路由反射器、联邦或MPLS解决。
高级特性
联邦(confederation)
使用场景
由于BGP有水平分割原则(运行BGP协议的路由器从一个iBGP邻居处收到的路由更新,不能再传递给其他iBGP邻居),iBGP邻居之间往往无法传递路由,为了解决该问题,除了可以使用full mesh、路由反射器以外,还可以用联邦。当然现网中为了传递iBGP之间的路由,几乎很少使用联邦,99.99%用的还是路由反射,联邦只是相对full mesh来说省事一些。
相关概念
在联邦内部保留联邦外部的Next Hop属性;
公布给联邦的路由的MED属性在整个联邦范围内予以保留;
路由的Local-Preference属性在整个联邦范围内给予保留;
在联邦范围内,将成员AS号压入AS_Path,但不公布到联邦外,并且使用TYPE3和TYPE4的AS_Path;
AS_Path中的联邦AS号用于在联邦内部避免环路;
联邦通过将一个AS“拆分”成多个小AS的方式解决iBGP路由传递的问题,比如下图中的AS345,被“拆分”成了AS 64512和AS64513,R3和R4之间是联邦iBGP关系,R4和R5之间是联邦eBGP关系。在联邦内部,R3和R4都属于AS64512,对于R4来说,R4属于AS64513,但对于联邦外部的路由器来说,R3\R4\R5都是AS345,外部根本不知道有AS64512、64513的存在。
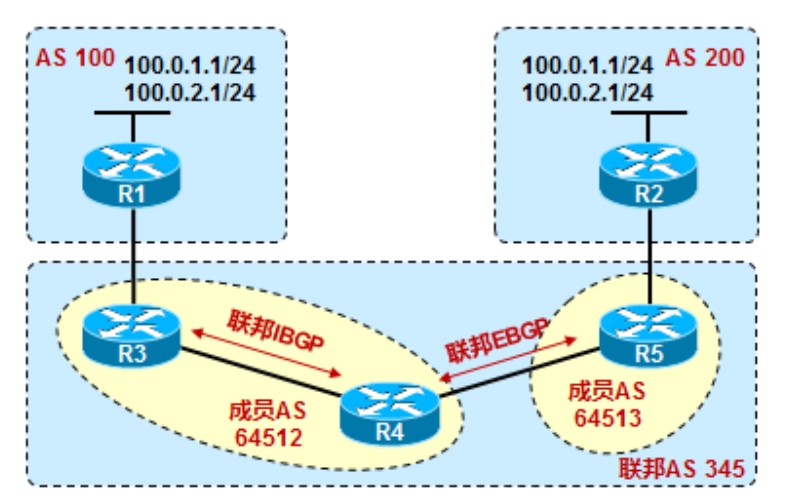
实验
AS2中的所有路由器运行OSPF协议打通TCP的连通性,AS2中又分为2个联邦AS。
OSPF配置
1 | R2(config)#router ospf 1 |
BGP confederation配置
R2:
1 | R2(config)#router bgp 24 |
当配置BGP 联邦时,BGP的AS号要使用所在联邦的AS号,也就是使用24这个子AS号,所以这里配置命令为‘router bgp 24’;
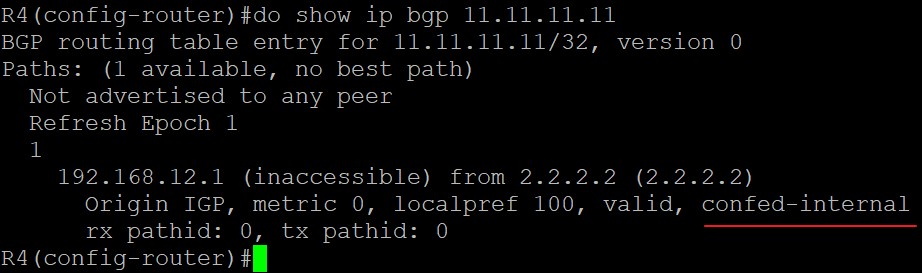
前边说过,联邦的AS_Path只在联邦内部传递,也就是说R2所在的联邦的AS号24只在AS内部传递,那么联邦外的路由器如何知道R2真正的AS号,AS2呢?用命令‘bgp confederation identifier 2’来告诉其他AS的路由器,R2的主AS号为2,配置以后,对于联邦外的AS来说,整个AS就不是AS24了,而是AS2;
接下来要配置R2的其他所有BGP联邦的子AS号,在这里由于只有两个子AS,AS24和AS35,所以R2只需要配置另一个子AS,AS35就行了:bgp confederation peers 35。如果除了AS35以外还有另一个子AS,比如AS78,那么R2配置‘bgp confederation peers 35 78’即可,后面可以跟多个AS号;
R2和R4同在子AS24中,像配置普通的iBGP邻居一样配置即可;R3和R2分别在不同的子AS中,属于联邦的eBGP邻居,所以相比配置R4要多配置一条eBGP多跳的命令,因为eBGP的TTL默认为1跳,但R2和R3使用Loopback接口建立的eBGP邻居,TTL至少要2才能让报文传递到彼此成功建立邻居,所以这里配置‘neighbor 3.3.3.3 ebgp-multihop 2’这条命令。
R3\R4\R5的配置和R2类似:
1 | R3: |
验证阶段
现在在R5上用Loopback接口宣告进BGP一条55.55.55.55/32的路由,看其他路由器上这条路由的显示
1 | R5(config)#interface loopback 5 |
R3关于这条路由的显示:
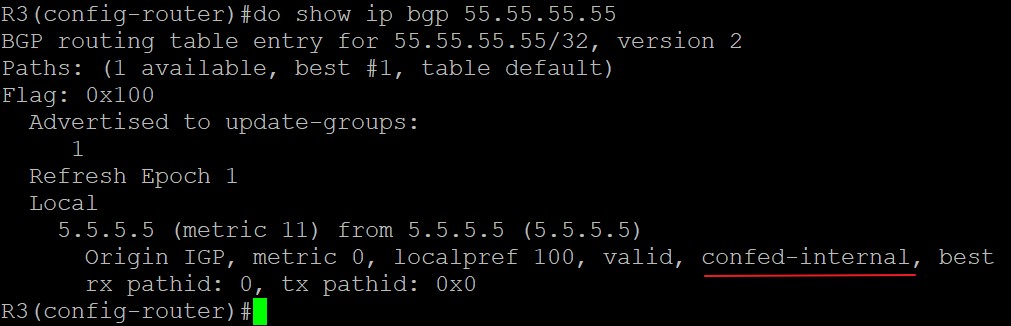
在R3上这条路由中,会显示‘confed-internal’表示该路由来自联邦子AS内部的iBGP邻居,现在来看看R2:
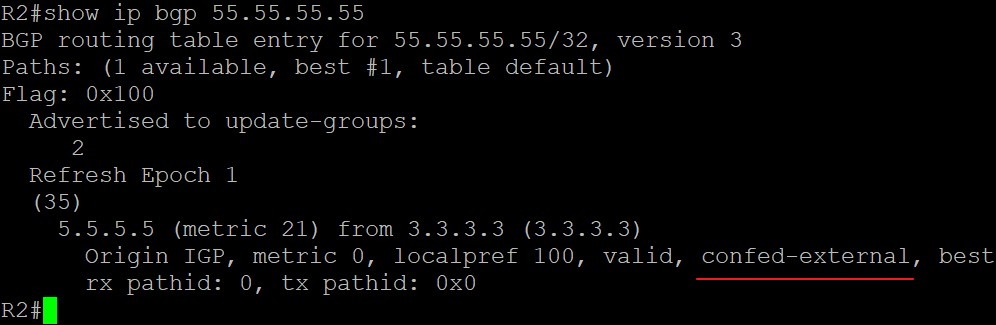
在R2上显示‘confed-external’表示该路由来自联邦子AS的外部eBGP邻居。联邦AS之间的AS_Path类型为‘AS_CONFED_SEQUENCE’,用来在联邦内防环,该属性不会出联邦:
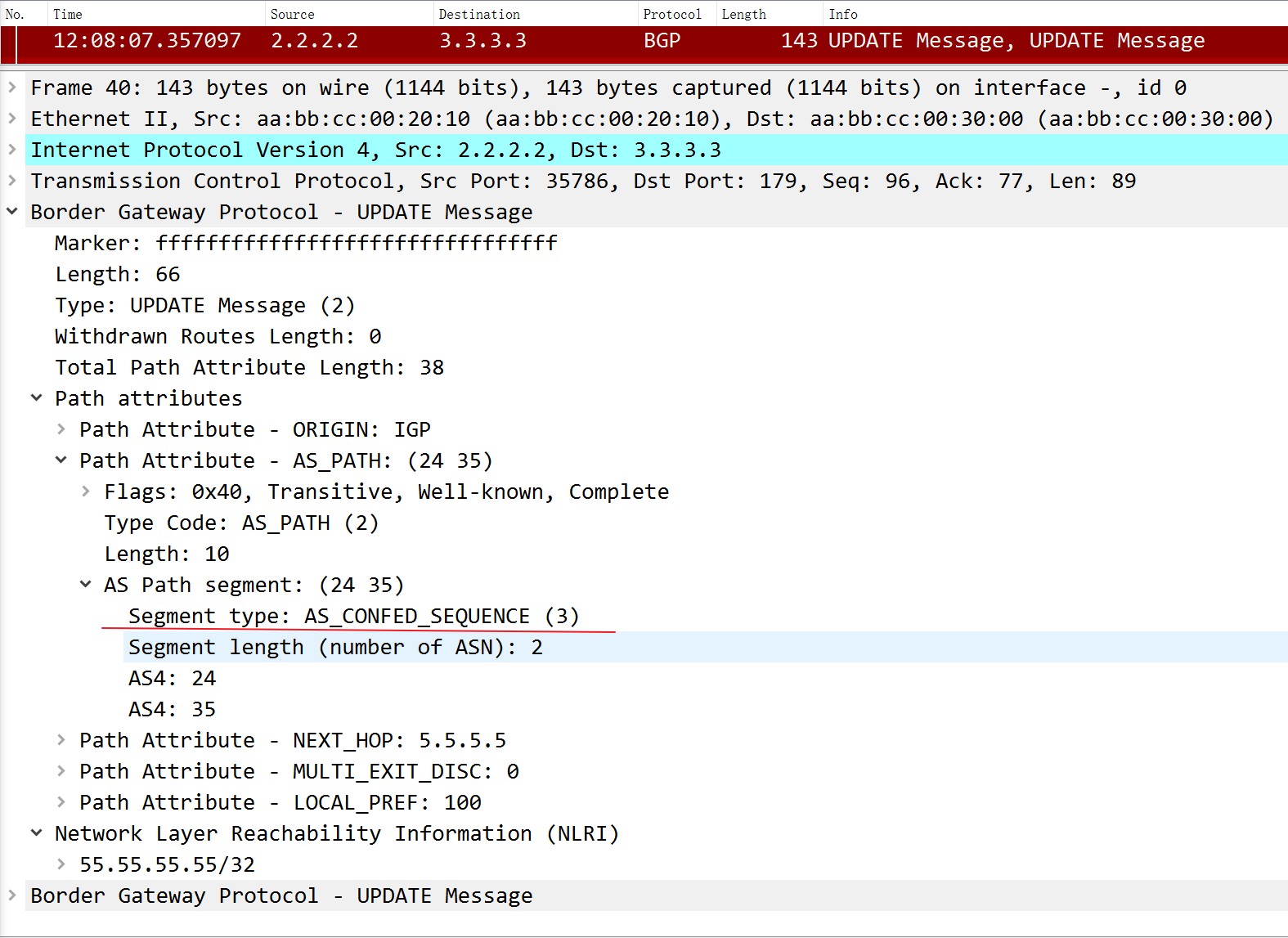
现在让R1和R2之间建立eBGP邻居,看看R1上这条路由的显示:
1 | R1: |
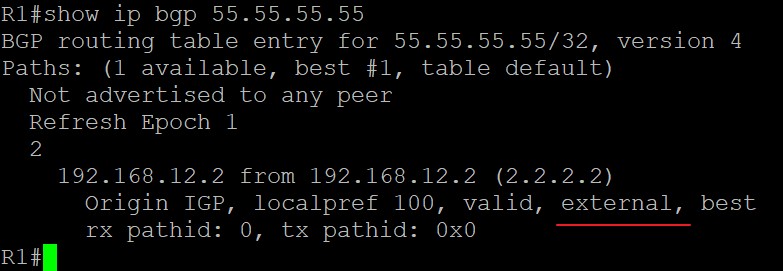
可以看到,55.55.55.55/32这条路由在R1上被看作是一条eBGP邻居传过来的路由,至于联邦内部的AS24和AS35是不会告诉处于联邦外部的R1的:
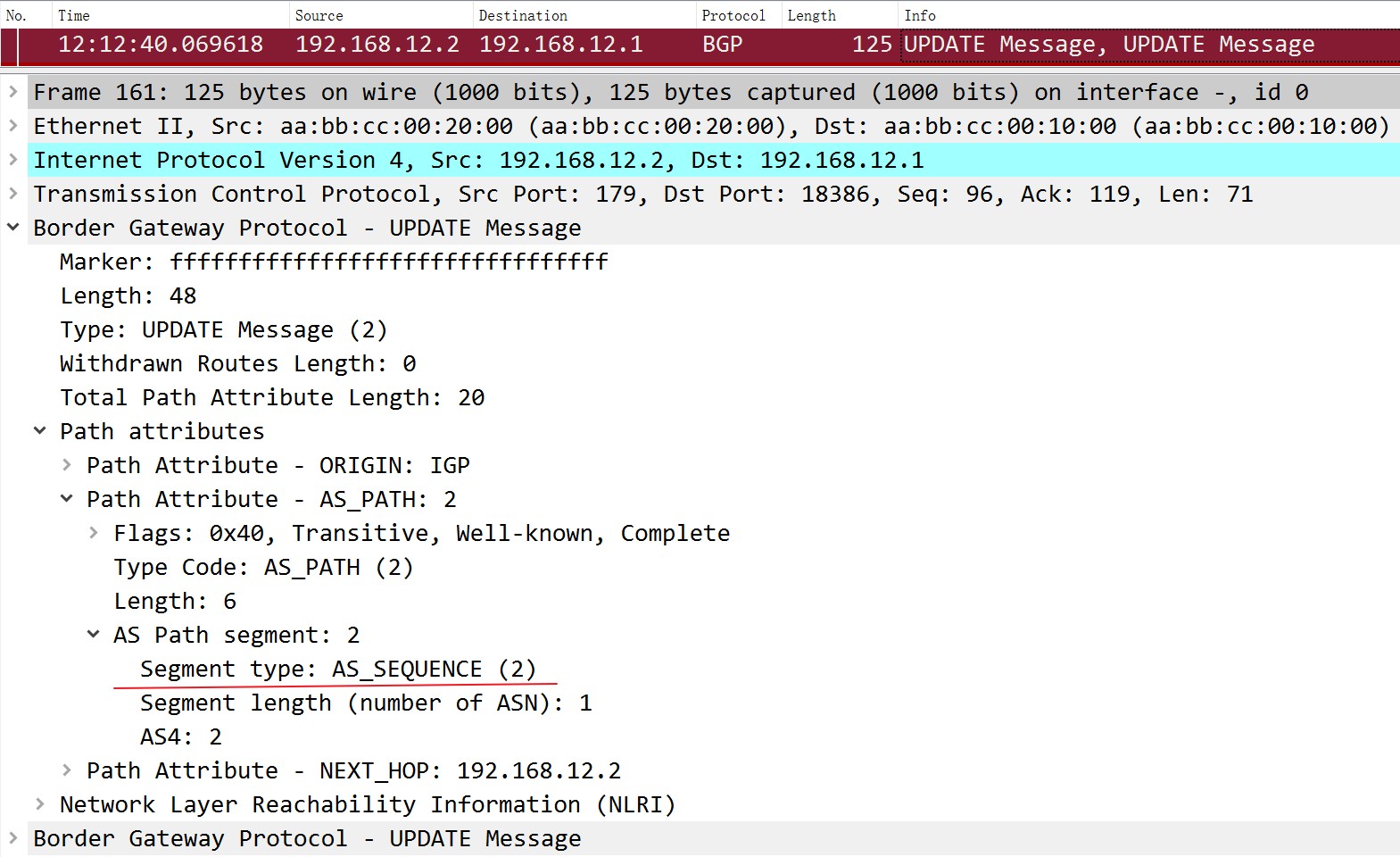
现在来看看在如果在R1上宣告一条路由进BGP后会是什么效果:
1 | R1(config)#int loop 11 |
对于R2来说就是普通的由eBGP邻居发送过来的路由:
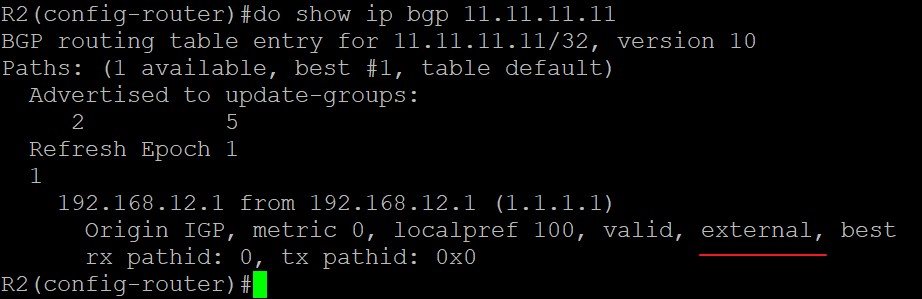
对于R3来说11.11.11.11/32是由联邦eBGP邻居,R2,宣告过来的路由:
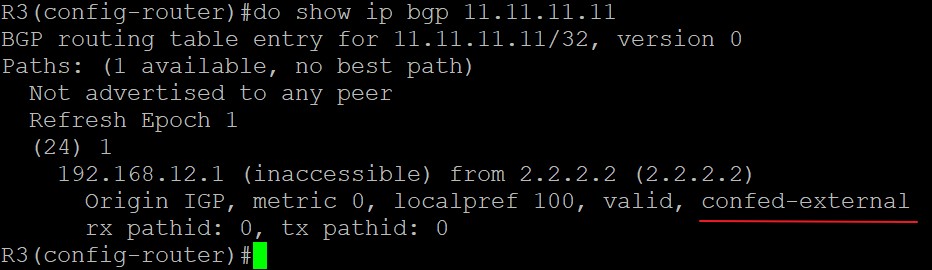
对于R4来说11.11.11.11/32是由联邦iBGP邻居,R2,宣告过来的路由:
路由反射器
基本概念
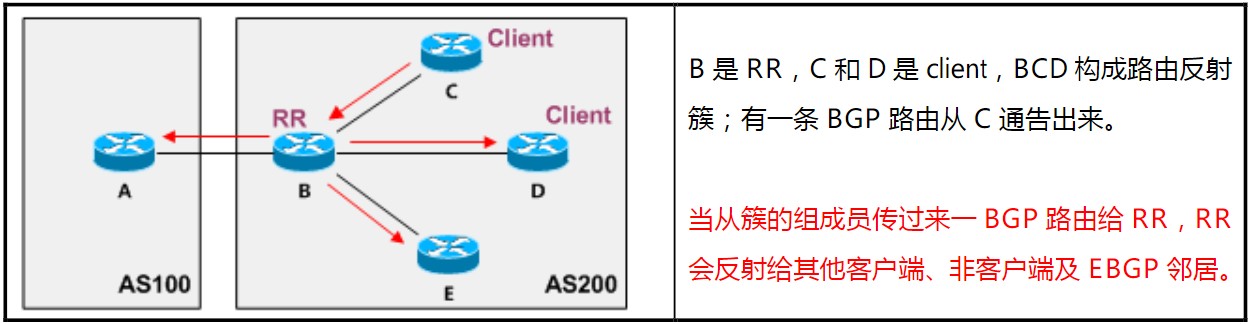
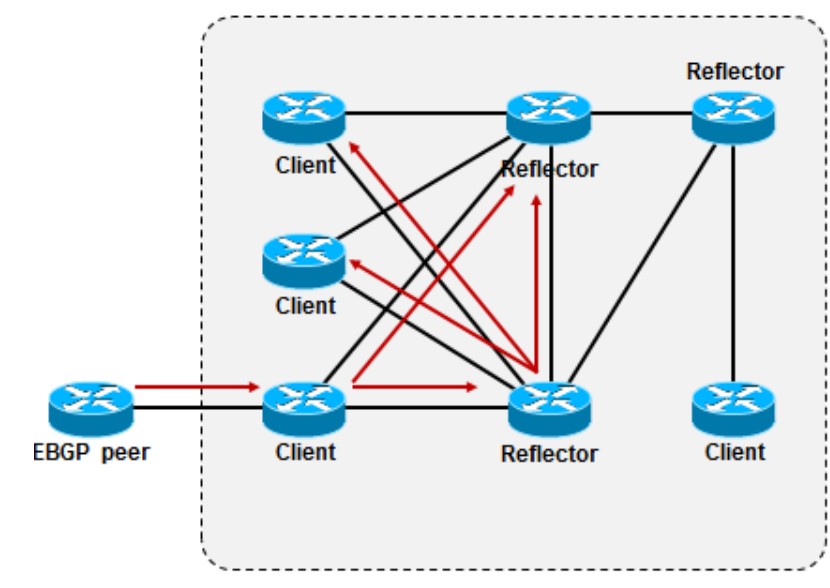
在AS内部,由于存在iBGP水平分割原则,使得AS内部的iBGP邻居之间传递路由十分麻烦,不得不两两建立iBGP连接,使得AS内部的BGP邻居之间形成full mesh(全互联)状态以获得完整的BGP路由更新,然而这是个扩展性非常低的做法,同时也给网络设备带来了负担,因为BGP对设备资源消耗很大,解决iBGP路由扩展问题的两种有效办法是路由反射器及联邦。路由反射器相比于联邦的优势在于,联邦中所有路由器都需要支持并理解联邦机制,而路由反射器只要RR(route reflector)理解反射机制即可,另外路由反射器的实现机制也相对简单一些,所以现网中99%用的都是路由反射器。
思考路由反射器时,将簇当作一个逻辑的整体去考虑,RR和client共同构成反射簇,相关配置在RR上完成,只有它才知道,RR只通告或反射它所知道的最佳路径。
为了维护BGP拓扑,RR在反射路由的时候不修改某些BGP路径属性,包括NH、AS_Path、Local-Preference和MED,并且增加了ORIGINATOR和CLUSTER_LIST用来防环。
路由反射器的反射规律如下:
如果路由是从非client的iBGP对等体学习到的,则反射给所有的client和eBGP邻居;
如果路由是从client学习到的,则反射给所有非client的iBGP邻居以及除了该client以外的所有client;
如果路由是从eBGP邻居学习到的,则反射给所有client和非client的iBGP邻居。
用一句话归纳就是“iBGP邻居非非不传,eBGP邻居反射路由”,也就是iBGP邻居的非client和非client之间不会进行路由反射,但都会反射给eBGP邻居。
规则示例
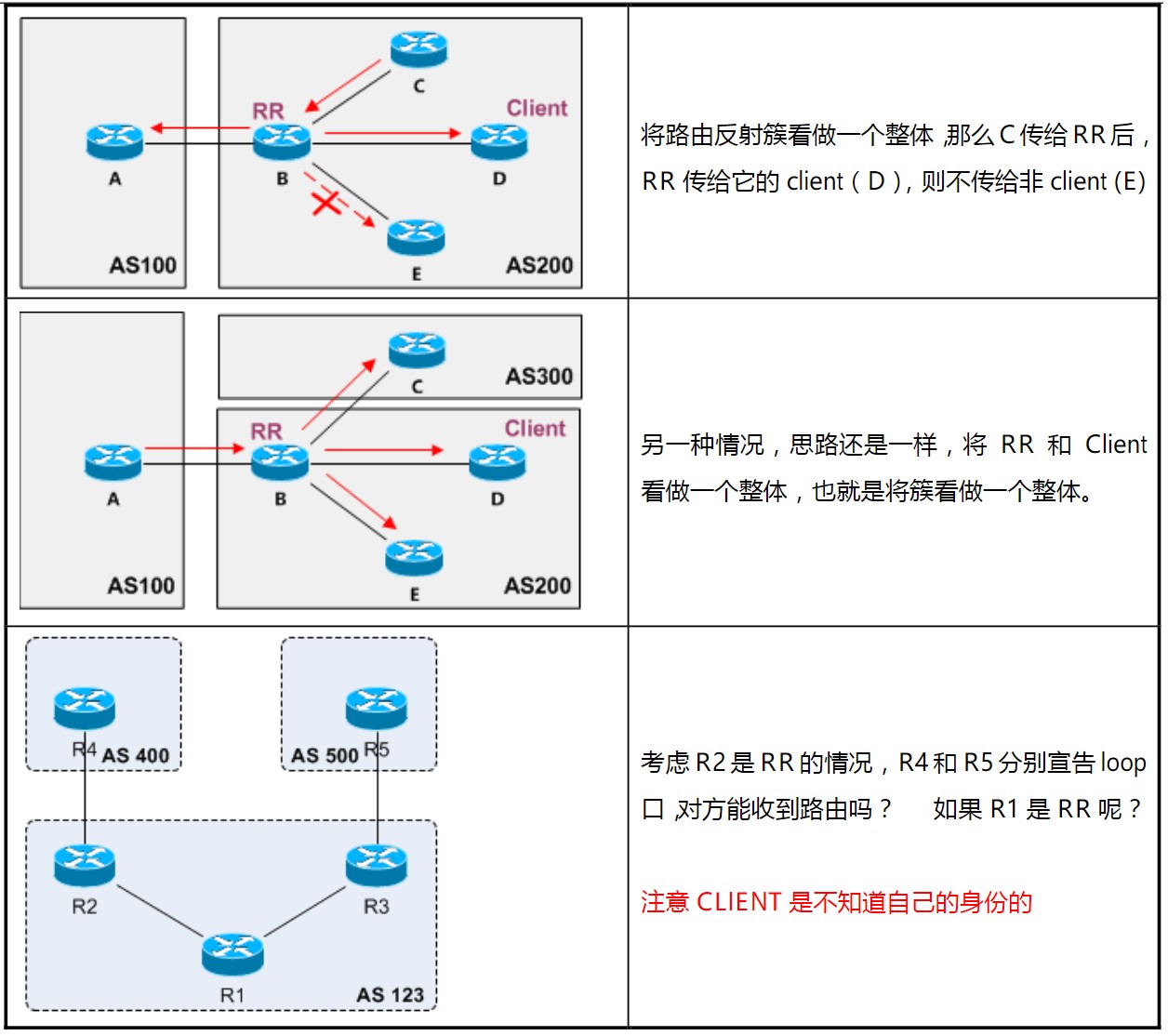
配置命令
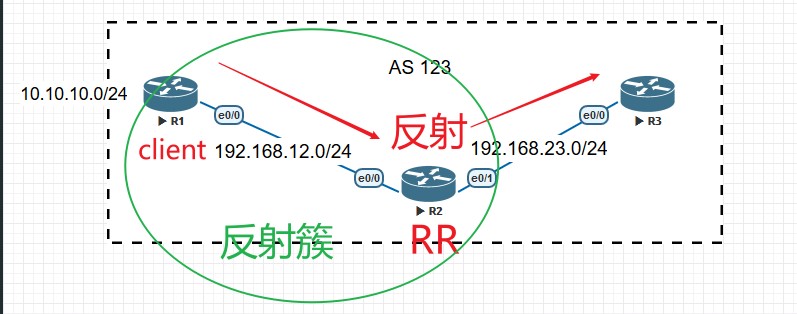
R1\R2之间,R2\R3之间为iBGP邻居,TCP连通性用OSPF打通,R1上宣告一条10.10.10.0/24的路由,由于水平分割原则的存在,R2从iBGP邻居R1那里学到的路由不能发送给R3,所以R3的路由表中没有这条10.10.10.0/24的路由。此时为了打破水平分割原则,在R2上配置路由反射器:
1 | R2(config-router)#neighbor 1.1.1.1 route-reflector-client |
此时在R3上已经有了10.10.10.0/24这条路由:
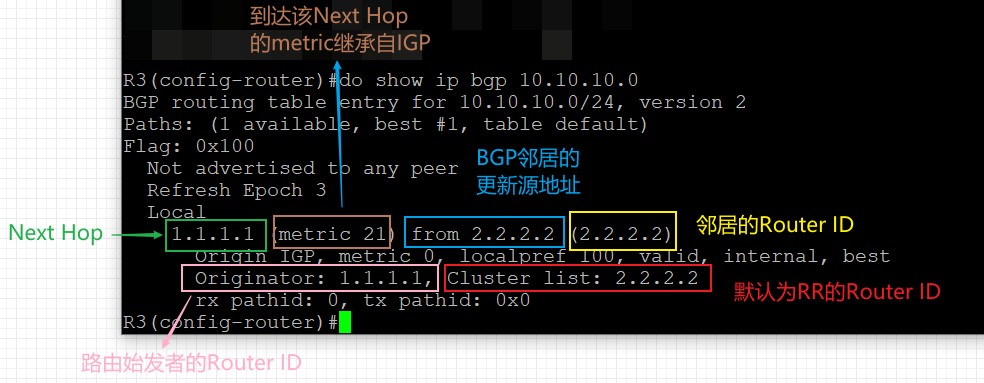
在R3上如果想修改Cluster ID可以用命令‘bgp cluster-id X.X.X.X’进行修改。
上面输出中能看到,这条经过反射的路由多了两个属性,ORIGINATOR_ID和CLUSTER_LIST,下面来看看这两个属性。
ORIGINATOR_ID与CLUSTER_LIST
基本概念
由于AS_Path属性在AS内部不会发生变化,仅当路由离开本AS时才会被更新,而路由反射器打破了水平分割原则,有可能使路由出现环路,所以AS内必须有相对应的防环机制,所以路由反射器使用两个新的属性进行防环,ORIGINATOR_ID和CLUSTER_LIST,二者为路由反射器使用的可选非传递属性,用来防止环路。
- ORIGINATOR_ID是一个路由反射器创建的32bit值,该数值是本地AS中路由发起方的iBGP Router ID,注意发起方未必是这条路由的引入者,如果发起方发现其RID在所接收到的路由的ORIGINATOR_ID中,那么就知道已经出现了路由环路,因此会忽略该路由。
- CLUSTER_LIST是遗传路由传递所经过的路由反射簇(Cluster)的ID,AS内的每个路由反射簇都有一个32bit的簇ID,如果簇中包含了多个RR,则需手工为每个RR配置簇ID。当RR将来自客户的路由反射给非客户时,同时将其簇ID附加到CLUSTER_LIST中,那么就知道出现了环路,则忽略该路由。CLUSTER_LIST属性只用于RR防环,RR只在反射路由的时候才会创建或更新CLUSTER_LIST,而下面几种情况,RR不会创建该属性:1、RR自己始发的路由;2、RR向EBGP邻居发送路由更新时,将会清除所有的CLUSTER_LIST属性;3、当RR从eBGP邻居收到路由,传递给client或非client时,不会创建CLUSTER_LIST。
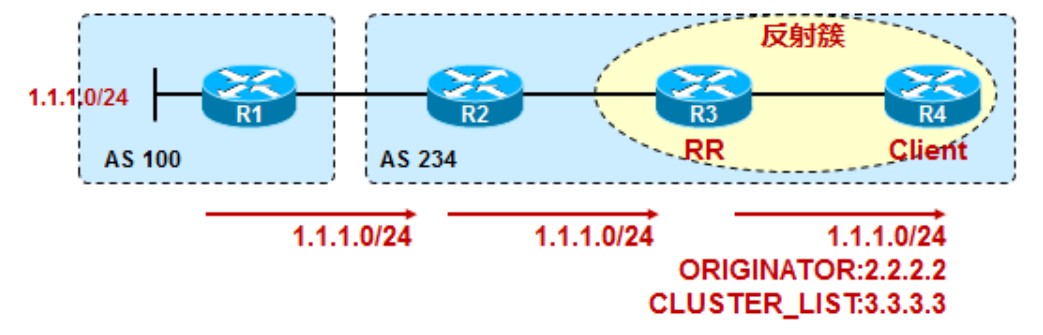
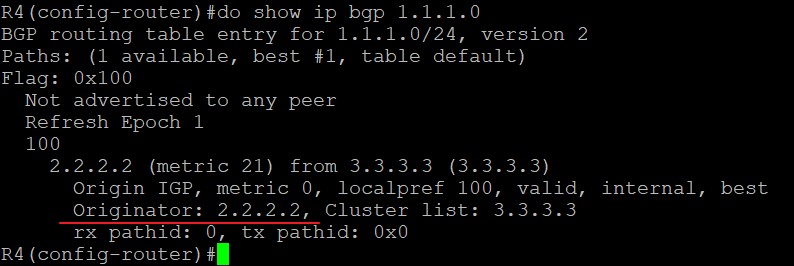
ORIGINATOR_ID取值
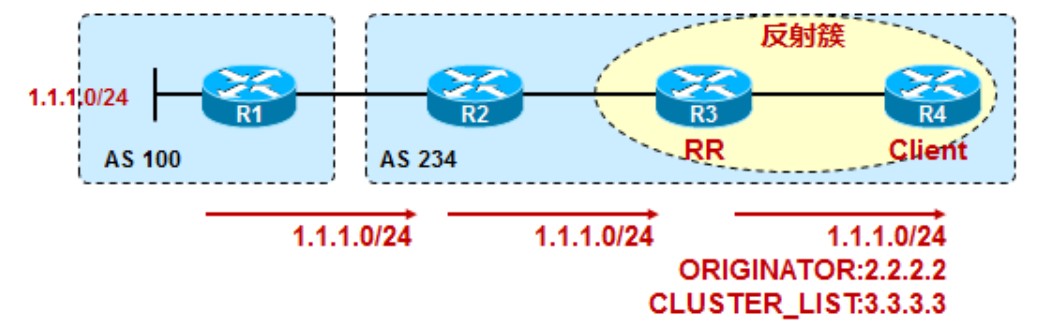
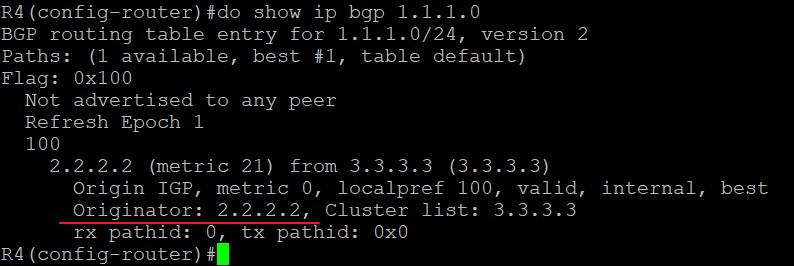
R1位于AS100,与R2是eBGP邻居关系,将1.1.1.0/24的路由传递给R2,R2传递给iBGP邻居R3,但由于水平分割原则,R3不会将从iBGP邻居R2处学到的1.1.1.0/24路由传递给另一个iBGP邻居R4,这种情况下如果想将路由传递给R4,使R3成为RR,R4为R3的client,R3就能将路由传递给R4了,此时身为RR的R3会添加ORIGINATOR_ID和CLUSTER_LIST进路由,其中ORIGINATOR属性为R2的Router ID,也就是2.2.2.2而不是R1的Router ID,1.1.1.1:
CLUSTER_LIST与BGP选路
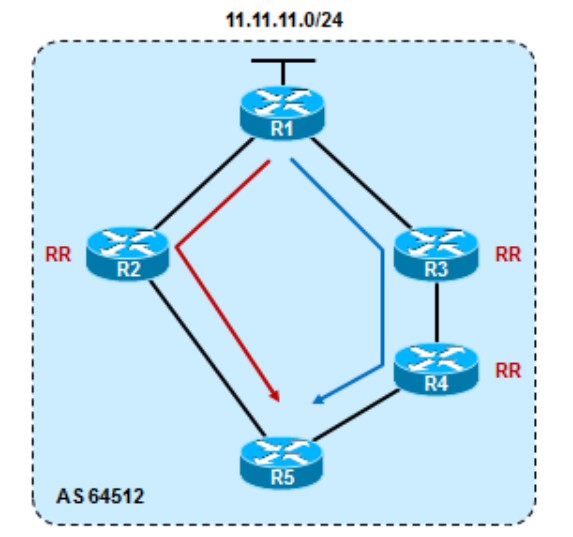
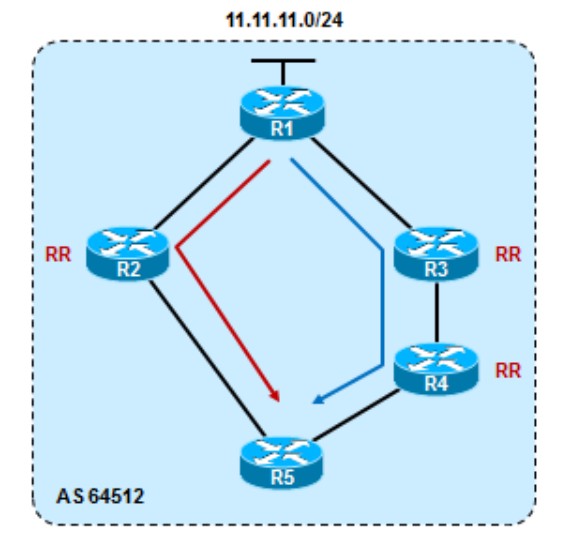
R1宣告11.11.11.0/24进BGP,R5分别通过R2和R4学到这条路由,在其他属性一致的情况下,Cluster list短的路由更优:
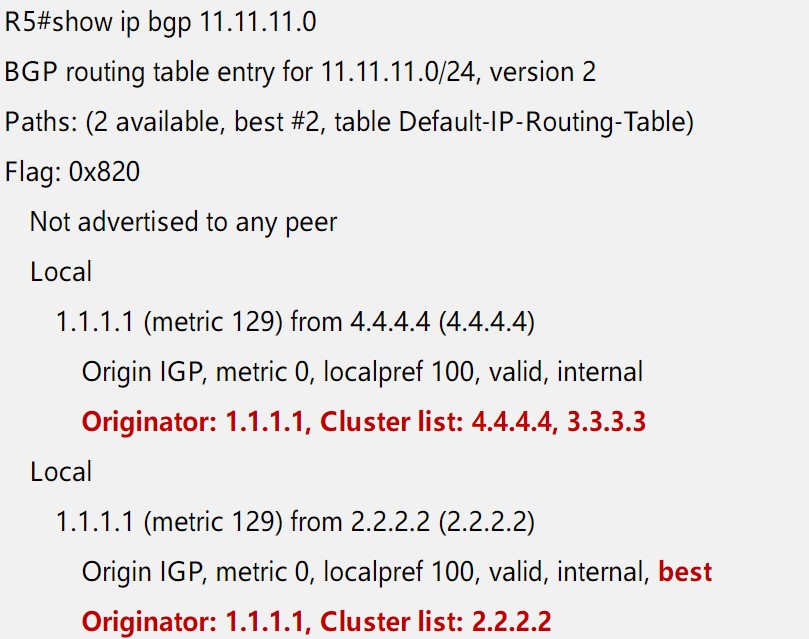
冗余RR环境
单RR可能会存在单点故障,因此从冗余性的角度出发,一个簇中可以拥有多台RR,Client与每一台RR都有物理连接并建立BGP对等体关系,在其中一台RR出现故障的情况下,Client仍然有替代连接。因为Client不知道主机是别人的Client,所以RR本身也可以成为别人的Client,使用荣誉RR增加了网络的健壮性,ORIGINATOR_ID和CLUSTER_LIST属性用来在冗余RR中避免环路,可以将两个RR的Cluster ID配置为一样,可以进一步起到防环作用,所有的RR之间建议采取全互联的形式,比如:
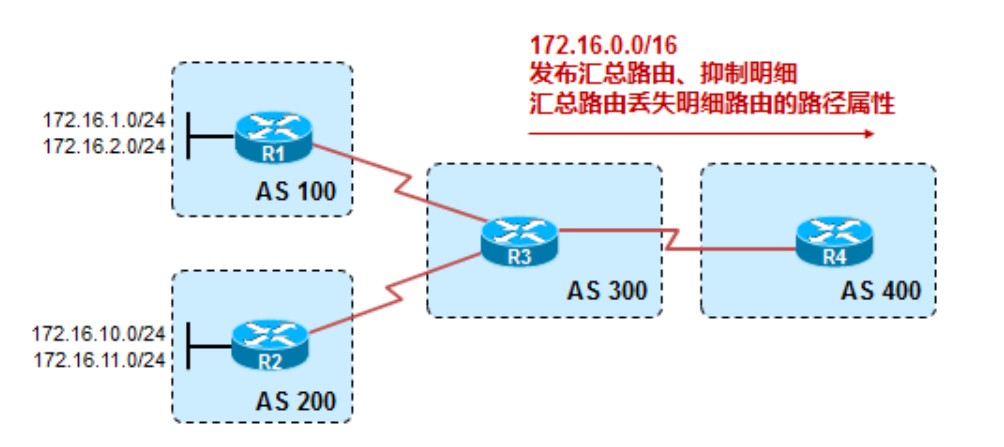
手工汇总
BGP支持自动汇总和手工汇总,但自动汇总存在很多问题,所以建议使用手工汇总。手工汇总的命令为:
1 | aggregate-address address / length [ advertise-map map-name ] [ as-set ] [ attribute-map map-name ] [ summary-only ] [ suppress-map map-name ] |
常见配置为aggregate-address X.X.X.X Y.Y.Y.Y,在不加任何关键字的情况下,同时传递明细路由和汇总路由。
summary-only
加上参数summary-only后,只传递汇总路由,明细路由被抑制不进行传播。这种情况下的汇总路由将丢失明细路由的AS_Path属性,因此可能存在一定的隐患。
基本配置
1 | R1# |
此时在R3上show ip bgp查看BGP表
1 | R3#show ip bgp |
这条172.16.0.0/24的汇总路由,由于是本地产生的,所以Next Hop是0.0.0.0,weight为默认的32768,origin为i,其余的明细路由标记为‘s’,因为有summary-only,因此都被抑制了。
在R4上show ip bgp查看BGP表
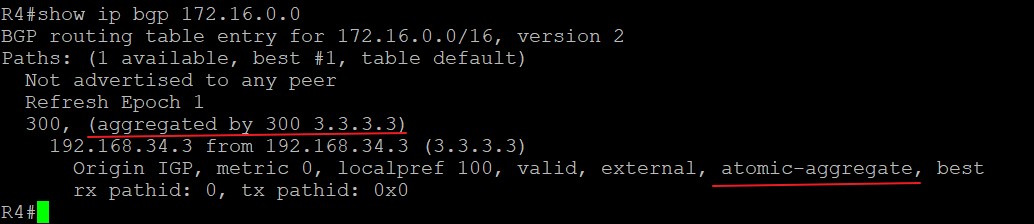
可以看到汇总路由带上了atomic-aggregate属性,用来告知下游路由器,这是汇总路由,丢失了明细路由的属性,同时aggregator属性标识了汇总的地点为AS300内的Router ID为3.3.3.3路由器。抓包如下:
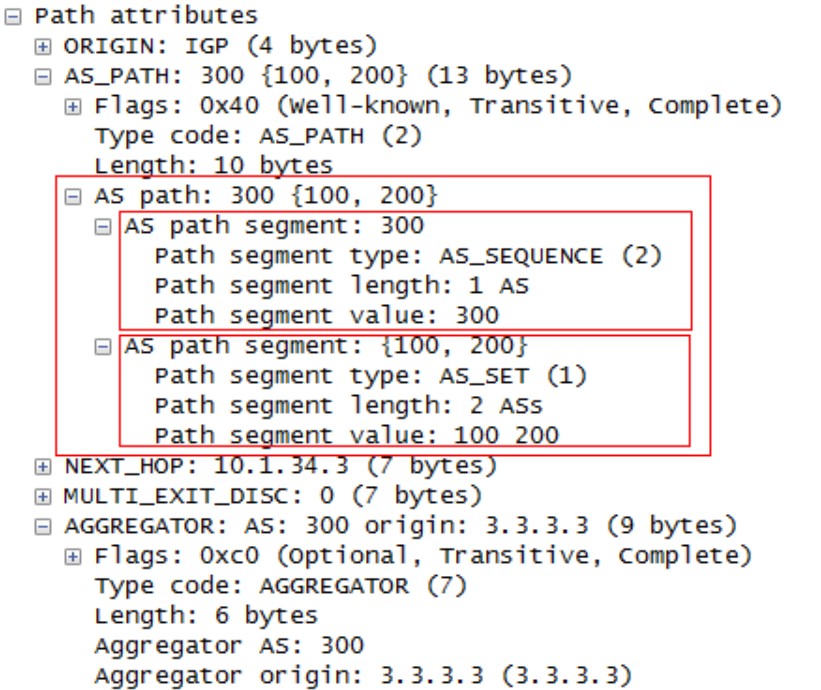
AS-SET
汇总命令加上关键词‘as-set’后,产生的这条汇总路由就可以继承明细路由的某些路径属性,从而规避一些问题。as-set继承明细属性的规则如下:
AS_Path:将收到的所有明细路由的AS号都放在{}中,计算AS_Path长度时,带{}的AS只被算作一个AS号;
Origin:继承最差的Origin属性;
Community:继承所有明细路由的Community,形成一个列表;
MED:不继承;
LP:取明细路由中LP最大值;
Next-Hop:汇总路由为0.0.0.0,因为汇总路由由本地产生。
在R3上将汇总的配置命令替换为‘aggregate-address 172.16.0.0 255.255.0.0 as-set summary-only’,刷新BGP以后R3上的BGP表为:
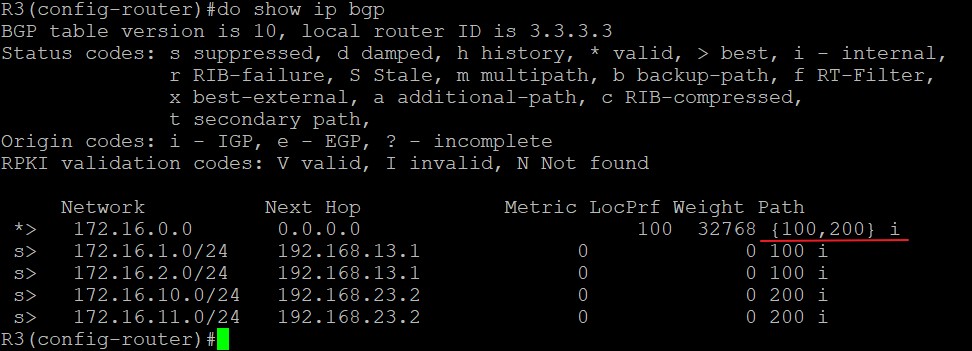
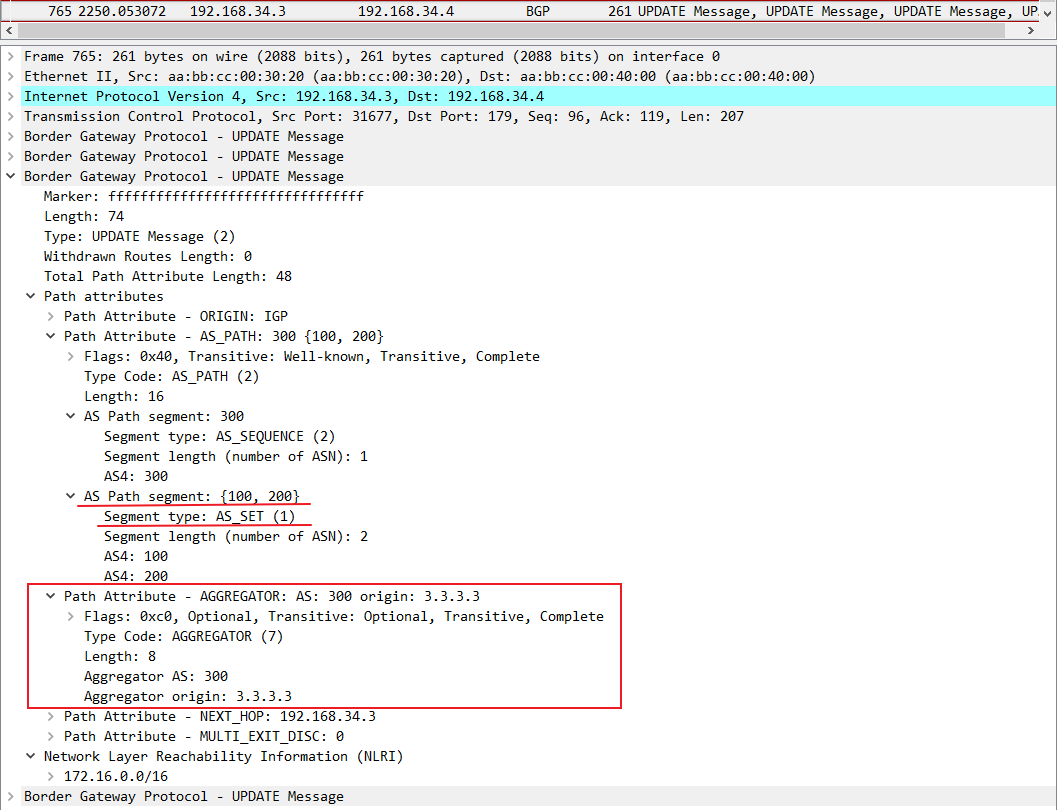
可以看到R3上这条汇总路由的AS_Path继承了明细路由的AS_Path,以{100,200}的形式呈现,这样能起到放缓作用,而且不会由于丢失明细路由的AS_Path而带来隐患,注意这里{}内的AS_Path类型是AS_SET,是无序的AS列表。
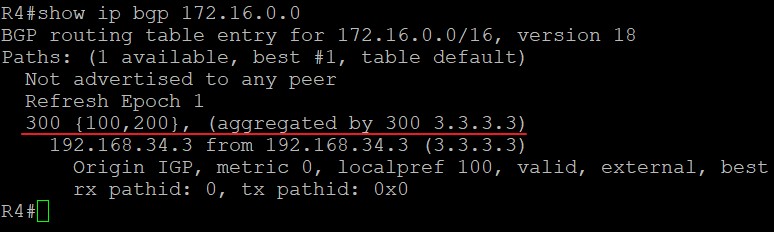
可以看到由于配置汇总路由时使用了AS-SET的关键字使得汇总路由得以继承明细路由的部分属性,因此产生的路由仍然保留有AGGREGATOR属性,但没有atomic-agg属性了,因为有了AS-SET关键字以后明细路由的属性都得以保留,不需要通告下游路由器这条路由的属性丢失,自然也就不需要atomic-agg属性了。
在R4上抓取R3发给R4的BGP update报文:
suppress-map xxxx as-set
用于宣告聚合路由及抑制特定的明细路由,后边跟上的route-map XXX里route-map匹配(permit)的路由将被过滤,其他放行。抑制列表虽然调用route-map,但route-map只用于匹配路由,不能设置路由属性,也就是不能使用set命令。
实验1
1 | R1: |
R3在配置汇总抑制列表前的BGP表为:
1 | R3(config-router)#do show ip bgp |
现在来配置汇总和抑制列表:
1 | ip prefix-list 1 seq 5 permit 11.11.11.0/24 |
这种配置下,除了汇总路由,明细路由的11.11.11.0/24会被干掉,放行其他明细路由:
1 | R3(config-router)#do show ip bgp |
如果将上面有关汇总的配置改为:
1 | ip prefix-list 1 seq 5 permit 11.11.11.0/24 |
等于route-map不匹配(deny)任何条目,因此所有明细路由都会被放行。
如果将配置改为:
1 | ip prefix-list 1 seq 5 deny 11.11.11.0/24 |
效果也是不匹配任何路由,所有明细路由被放行。
如果将配置改为:
1 | route-map SUPPRESS permit 10 |
则明细全都被干掉,不放行任何明细。
如果将配置:
1 | route-map SUPPRESS deny 10 |
则放行所有明细。
实验2
可以在BGP中用‘邻居地址+route-map’实现相同功能,但用route-map实现的话,最后是隐含干掉any的,而suppress-map则不同。比如也在R2上进行汇总然后干掉明细的11.11.11.0/24的话,R2配置如下:
1 | ip prefix-list 1 seq 5 permit 11.11.11.0/24 #抓取11.11.11.0/24这条要过滤掉的路由 |
实验3
基本配置:
1 | R1 |
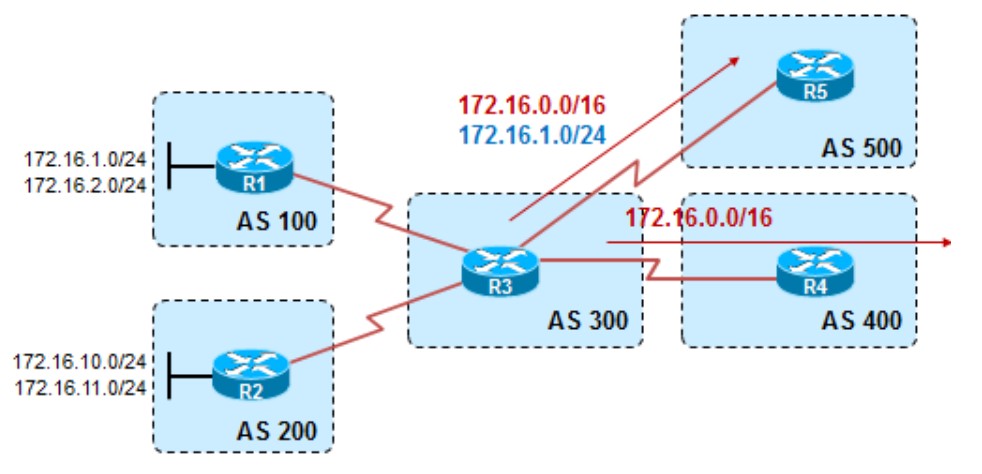
现在要求在R3上做汇总,将路由汇总为172.16.0.0/24,传给R5的除了汇总路由以外还有172.16.1.0/24这条明细路由,而传给R4的路由只有汇总路由。总体思路是,由于有四条明细路由而只想让R5知道其中一条明细路由,所以这里使用as-set搭配summary-only进行汇总,先将所有明细路由都抑制掉,然后再对特定的邻居R5使用非抑制列表,将需要传递给R5的那条明细路由传递给R5。
R3的配置:
1 | ip prefix-list 1 seq 5 permit 172.16.1.0/24 #抓取路由172.16.1.0/24 |
attribute-map
attribute-map命令可以修改汇聚路由的属性,比如汇聚路由的origin、metric等,但该命令仅仅对汇总路由产生作用,对明细不起效。
在R2上将明细路由汇总为192.168.0.0/16并修改其属性。
1 | router bgp 12 |
汇总前和汇总后的BGP表对比
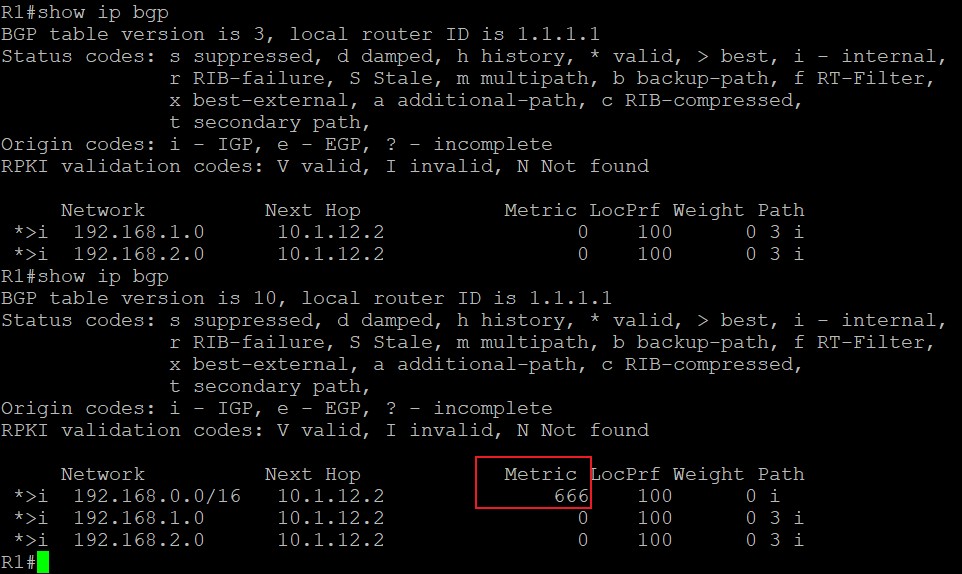
但此时再看R3的路由表:
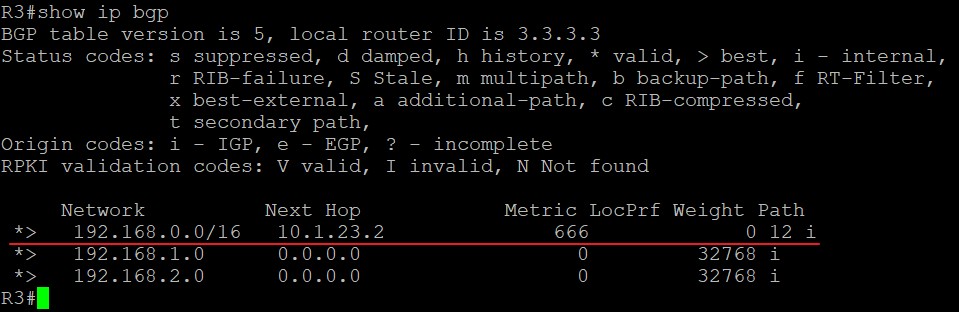
由于R2和R3是eBGP邻居,所以汇总这条路由也传递给了R3,有可能造成路由环路,必须过滤掉:
1 | access-list 1 deny 192.168.0.0 0.0.255.255 |
advertise-map
当advertise-map与summary-only命令合用时,aggregate-address的汇总路由下面的明细路由均会被抑制,同时如果advertise-map匹配的条目中的明细路由如果全部挂掉,则汇总路由也会消失,但只要advertise-map匹配的明细中有一条路由还在,那么汇总路由就会在,并且汇总路由仅会继承advertise-map匹配的明细路由的BGP路径属性。结合下面这个实验具体说明advertise-map的作用。
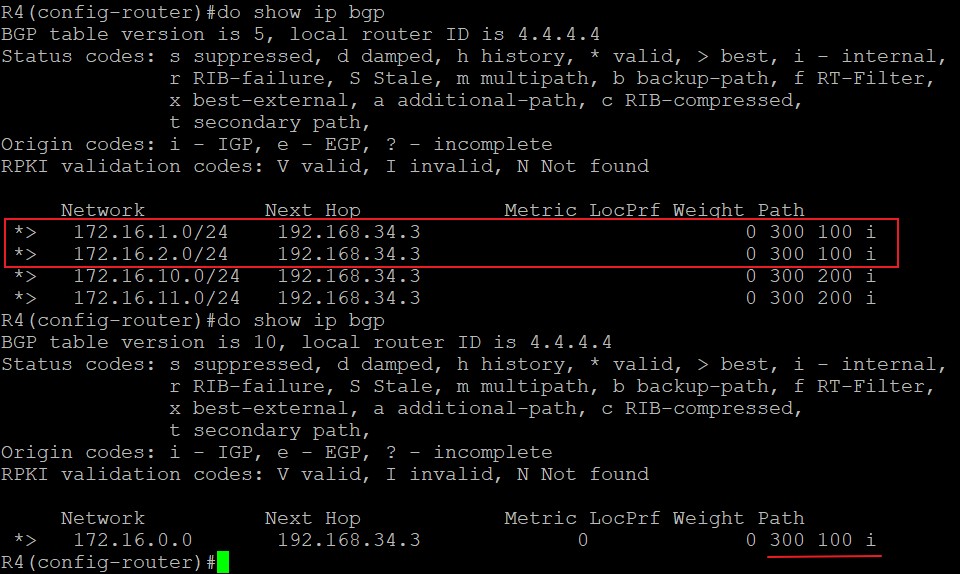
实验1
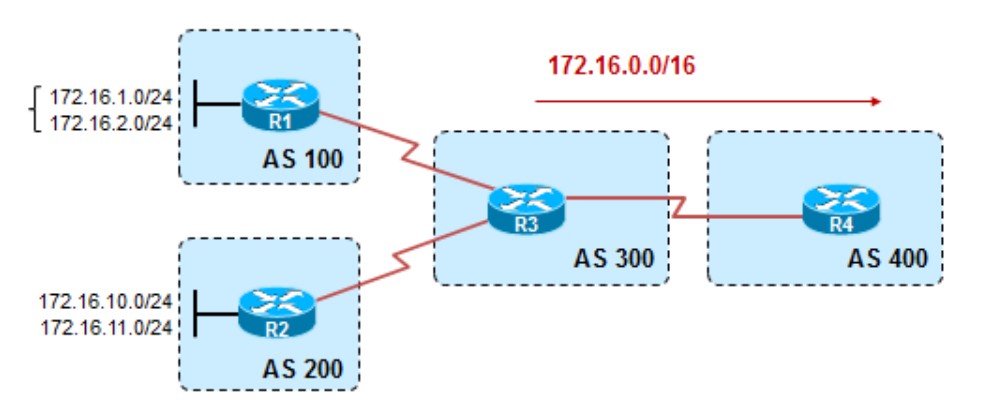
1 | ip prefix-list 1 permit 172.16.1.0/24 #抓取1.0和2.0两条明细路由 |
手动汇总时的advertise-map调用了抓取了1.0/24和2.0/24的route-map,所以明细路由均会被压制,汇总路由仅会继承route-map TEST所匹配的明细路由的属性,由于route-map TEST匹配的明细路由是来自AS100的R1的1.0/24和2.0/24,所以汇总路由的Path属性中只继承了1.0和2.0的AS_Path,也就是300和100。只要1.0和2.0其中有一条存在,汇总路由就会存在,如果1.0和2.0都挂掉,那么汇总路由也会不存在。
实验2
R3宣告192.168.1.0和2.0进BGP进程,同时将1.0的community设置为no-adv,设置为no-adv以后,1.0路由从R1传递给R2后,不会再传递给R1,因为community为no-adv的路由不会再宣告给其他邻居:
1 | access-list 1 permit 192.168.1.0 |
在如上配置以后,R2能学到1.0和2.0两条路由,而R1只能学到2.0,学不到community为no-adv的1.0路由。
- 当R2配置了‘aggregate-address 192.168.0.0 255.255.0.0’后,R1能学到汇总路由及明细路由2.0;
- 当R2配置了‘aggregate-address 192.168.0.0 255.255.0.0 as-set’后,R1只能学到2.0路由而无法学习到汇总路由,原因是因为1.0携带了no-adv的community,当汇总路由加了关键字‘as-set’后,汇总路由会继承明细路由1.0的community,因此汇总路由也携带了no-adv的community,不会发送汇总路由到R1:
1 | R1#show ip bgp |
- 如果在上面的基础上在R2上进行如下配置:
1 | access-list 11 deny 192.168.1.0 |
上面的配置大概意思是说,汇总路由继承2.0的属性,而不继承192.168.1.0的属性,也就是不再有1.0的no-adv的community属性,所以汇总路由可以传递给R1。
配置以后R1的路由表如下:
1 | R1#show ip bgp |
Route Dampening
基本概念
那些时有时无的不稳定路由称作路由翻滚,当路由翻滚出现在BGP中时,会导致邻居之间反复的发送update报文,从而增加设备的硬件资源消耗。BGP Dampening这个特性存在的意义是,减少那些翻滚路由的传播的同时,不会影响那些稳定路由的收敛。使用BGP dampening以后,会减少路由的硬件资源消耗并且增强网络总体的稳定性,稳定的路由会持续宣告给其他路由器,而翻滚的路由则会被抑制等它稳定后再进行传播。
具体步骤是,当路由翻滚出现后,给它分配一个惩罚值,翻滚越多惩罚值越大并且不断地积累。同时惩罚值又以一定的速率降低,每一个半衰期结束,如果在半衰期时间内路由不再翻滚的话,惩罚值会变为原来的一半。如果惩罚值超出了预先设置的阈值,也就是抑制阈值,路由会被抑制,也就是这条路由不再对外不发布,直到N个半衰期以后,惩罚值降低到另一个阈值,也就是低于重新使用阈值后,才会解除对路由的抑制。
必须注意的是,Route Dampening只对eBGP路由生效,而对iBGP路由无效。
1 | 惩罚值: 每次摆动增加1000 |
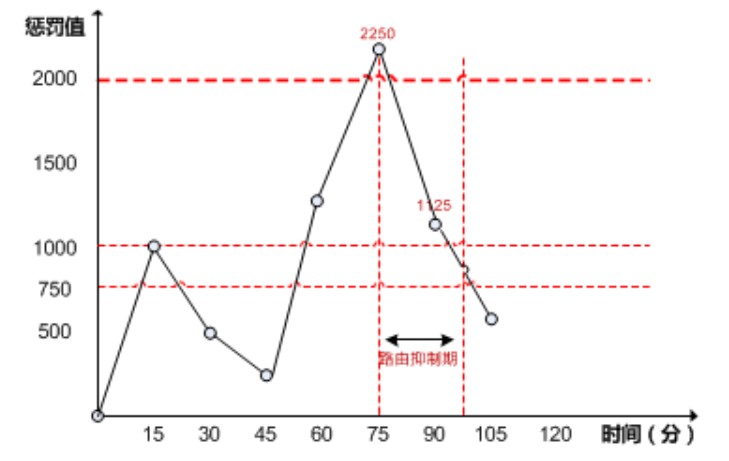
正常情况下,所有路由的惩罚值都是0,惩罚值是瞬间增加的,例如某条路又出现翻滚后,则惩罚值瞬间会增加到1000,这时会有半衰期,也就是15分钟,15分钟后如果该路由没有出现翻滚,则惩罚值降低为一半,降低到500, 再经过15分钟变成250,这时如果路由又一次发生抖动,惩罚值再加1000,变成1250,在此之前,这条路由正常使用。如果在中间又抖动了一次,惩罚值再加1000,变成2250,超过了阈值规定的2000,则这条路由将被抑制,不更新也不使用,这段时间路由进入了抑制期。如果15分钟内这条路由不再翻动了,则惩罚值降低为一半,也就是1125,但仍然被抑制,只有当该路由的惩罚值降低为750,小于重新使用的界限(1000)时,路由会再次被启用。
相关命令
1 | show ip bgp dampening parameters #查看关于dampening的相关参数,比如各种阈值的设定和半衰期的时间 |
路径属性
BGP路由器通常会收到多条去往同一路由前缀的BGP路由,像IGP一样,这时就需要进行路径选择流程,选出最佳路径。但不像IGP一样只有一到两个属性用来选路,比如RIP是跳数小的路径更优,OSPF是Cost值小的路径更优,而BGP有很多属性用来决定一条路径是否更优:
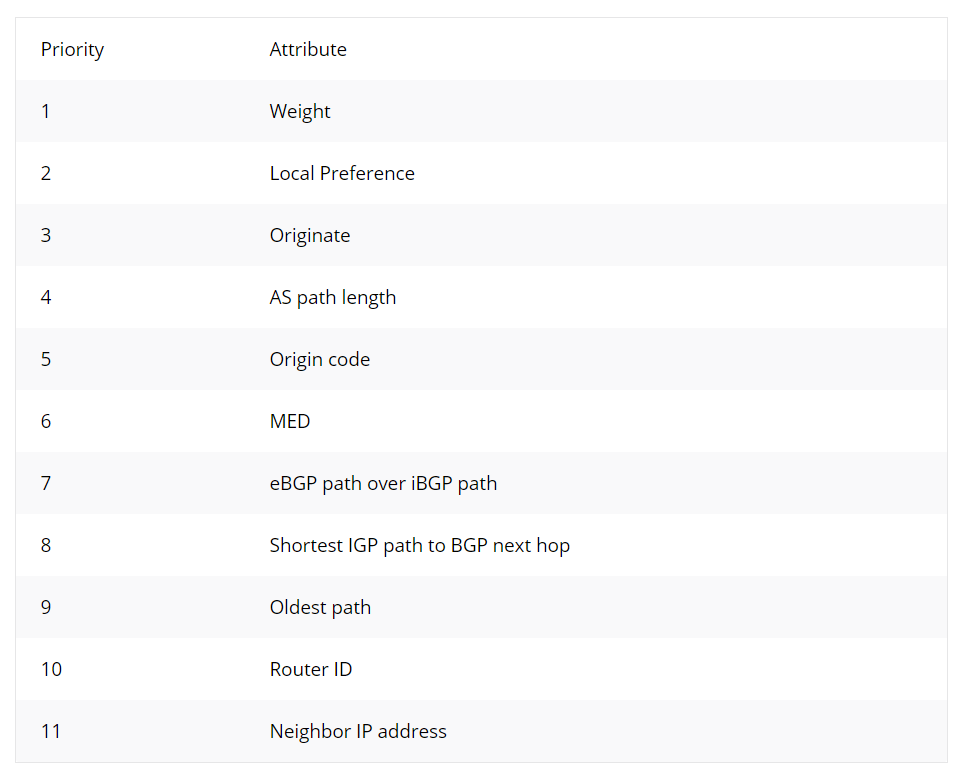
这些属性又分为公认属性(Well-known)和可选属性(Optional),公认属性又分为公认必遵(Well-known mandatory)和公认自决(Well-known discretionary);可选属性又分为可选传递(Optional transitive)和可选非传递(Optional non-transitive):
属性定义
Origin
理论知识
公认必遵属性,明确了路由更新的来源,一共有三种:
IGP,在BGP表中用‘i’表示,通过BGP的network命令宣告进BGP,也就是起源于IGP,因为BGP network命令宣告的路由必须在路由表中存在;
EGP,在BGP表中用‘e’表示,通过EGP协议重发布而来,现在已经没有EGP协议使用,因此不会见到e开头的路由;
Incomplete,在BGP表中用‘?’表示,通过其他渠道学习到的,路由来源的信息不完全,通常是由其他路由协议重分布进BGP的路由,当然整个不完整不表示这条路由可能会失效而是说路由的起源信息不完整;
这三种来源路径之间的优选原则是IGP>EGP>Incomplete。
起始属性可以通过命令修改:
route-map ORI permit 10 #先配置route-map;
match ip address 1 #确定要对哪些路由的origin属性进行修改;
set origin incomplete\igp #将origin属性修改成incomplete或igp;
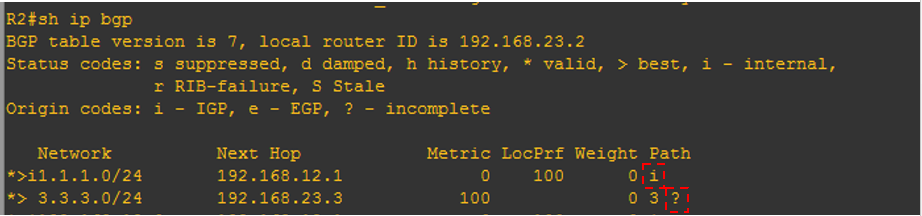
实验验证
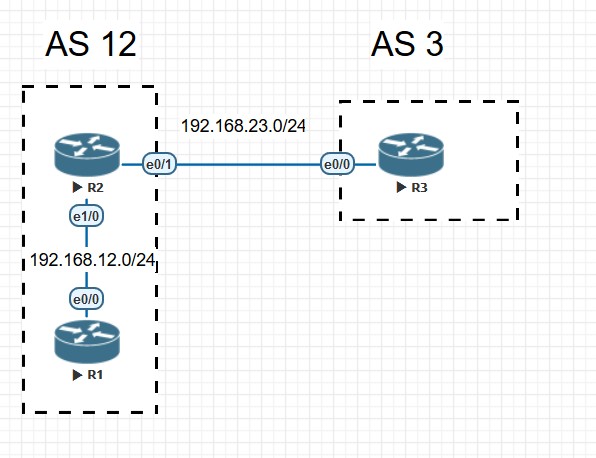
R2和R3是eBGP邻居,R3上宣告一条3.3.3.0/24的路由到R2,现在要在R2上对这条BGP路由的origin属性进行更改,由之前的‘i’改为‘?’。R2更改origin属性之前的BGP表:
之前BGP邻居的配置这里就不写了,只看和改变origin属性有关的配置,改变origin的配置可以在R2上的in方向,也可以在R3上out方向,我们在R2的in方向上配置:
1 | 先用ACL匹配需要改变origin的这条路由: |
AS_Path
定义
公认必遵属性,描述到达目标网络要经过的AS号序列,最重要的作用是防止BGP路由环路,如果BGP speaker发现自己的AS号出现在接收到的BGP路由更新的AS_Path中,那么说明可能有路由环路,路由器会忽略该路由更新。另一个重要作用,是在BGP选路过程中,作为AS跳数的丈量,AS_Path中包含的AS个数越少,表示距离目的网络更近,在其他路径属性相同的情况下,AS_Path越短越优先,先添加的AS号在右边,后添加的AS号在左边。AS_Path属性包含在建立邻居时的update报文中:
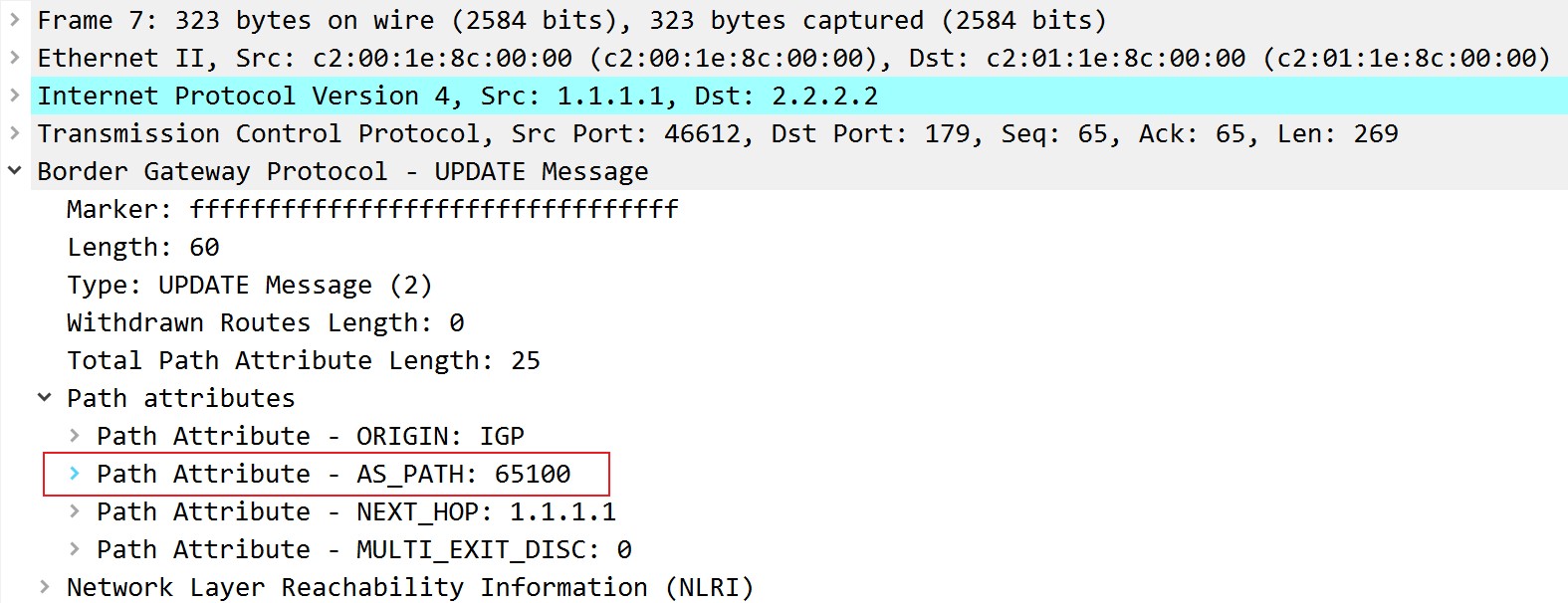
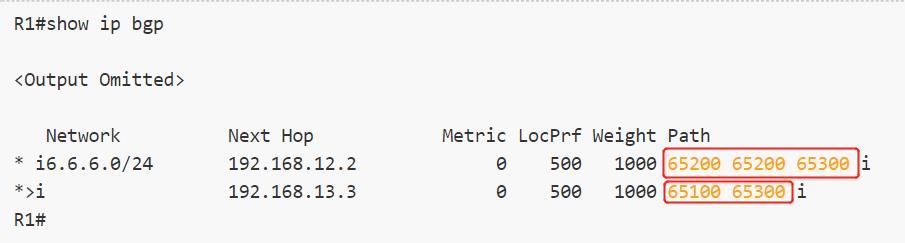
在BGP表中的Path部分也是AS_Path,例如去往6.6.6.0/24的最佳BGP路由,也就是下一跳是192.168.13.3的这条,先经过了AS65300,然后经过AS65100最后发送到本AS:
分类
Four types of AS segments are supported within the AS_PATH in Cisco IOS-
- AS_SET - Unordered set of ASes a prefix in the UPDATE message has traversed
- AS_SEQUENCE - Ordered set of ASes a prefix in the UPDATE message has traversed
- AS_CONFED_SET - Unordered set of Member AS numbers in the local confederation that the UPDATE message has traversed
- AS_CONFED_SEQUENCE - Ordered set of Member AS numbers in the local confederation that the UPDATE message has traversed
AS_Path共分为四类:
- AS_SEQUENCE:RFC1771中的英文定义是‘ordered set of ASs a route in the UPDATE message has traversed’,就是按照该BGP路由经过AS的顺序有序列出来的有序AS列表,这里要注意,如果一个AS号在AS_Path部分越靠右,表示这条路由越早经过这个AS,比如下图中到6.6.6.0/24这条BGP路由,下一跳为192.168.13.3的这个,AS65300在最右边,表示该路由从AS65300发出,然后经过AS 65100到达本AS:
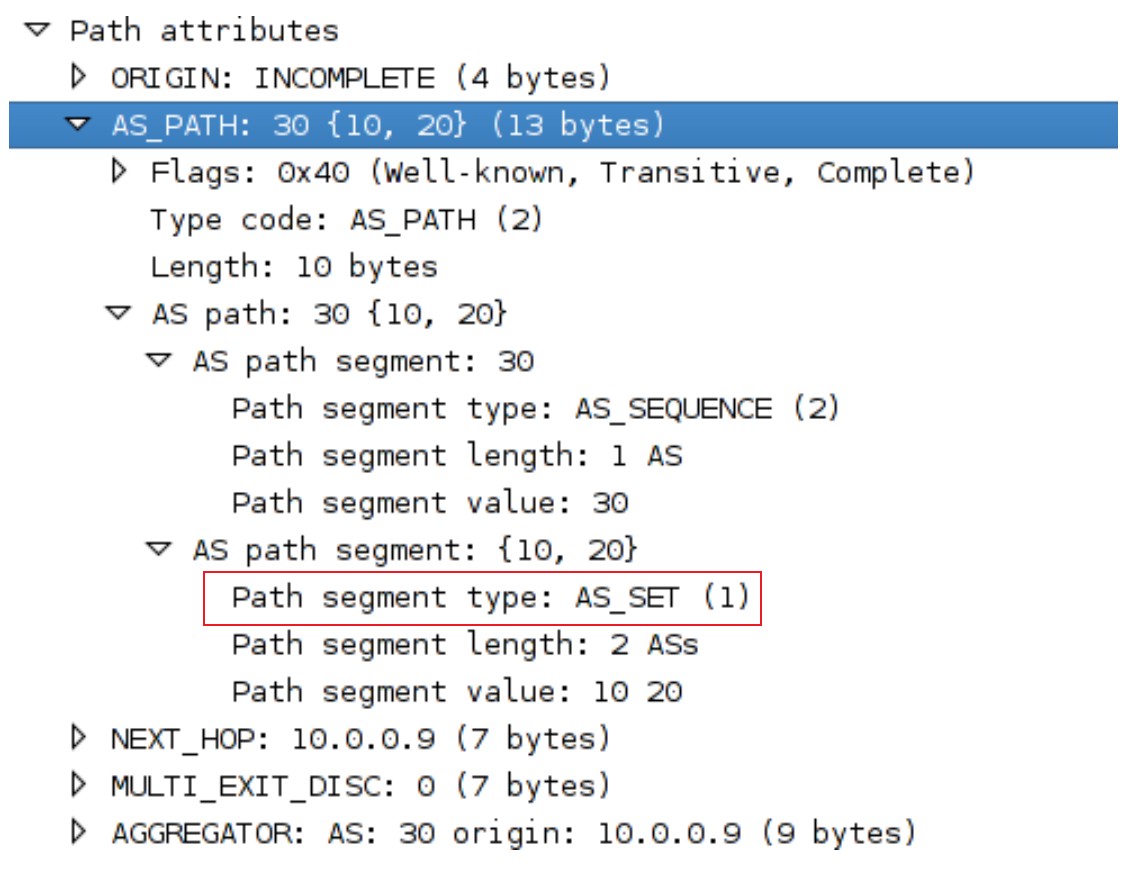
- AS_SET:RFC1771中的英文定义是‘unordered set of ASs a route in the UPDATE message has traversed’,就是无序的将该BGP路由所经过的AS号无序列出来的一个无顺序的AS列表。一开始的时候我觉得,AS_Path不就是用来表示经过了哪些AS的嘛,肯定是要用上面提到的AS_SEQUENCE这种有序的排列类型的AS_Path啊,为什么还要有AS_SET这种无序的AS列表呢?后来才明白,AS_SET是在路由汇总时使用的,具体的参见后面实验部分。下图括号中的100,300就是AS_SET类型的AS_Path,但由于AS_SET是无序的,所以从中无法看出该路由是先经过了AS 100还是AS 300:
- AS_CONFED_SEQUENCE:和之前的AS_SEQUENCE用法完全一样,都是有顺序的AS列表,区别在于列表中的AS号属于本地联邦中的AS号:
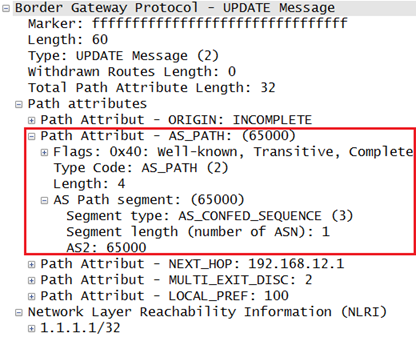
- AS_CONFED_SET:和之前的AS_SET用法完全一样,都是无序的AS列表,区别在于列表中的AS号属于本地联邦中的AS号。
生成&修改AS_Path
When a BGP speaker advertises a prefix it learned from another BGP speaker, it modifies the prefix’s AS_PATH attribute based on location of BGP peer to which the prefix will be sent i.e. iBGP or eBGP peer-
- The AS_PATH attribute is *not* modified when a prefix is advertised to an iBGP peer
- The AS_PATH attribute is modified as follows when a prefix is advertised to an eBGP peer-
- if the first path segment of the AS_PATH is of type AS_SEQUENCE, the local system prepends its own AS number as the last element of the sequence.
- if the first path segment of the AS_PATH is of type AS_SET, the local system prepends a new path segment of type AS_SEQUENCE to the AS_PATH, including its own AS number in that segment
- if the AS_PATH is empty, the local system creates a path segment of type AS_SEQUENCE, places its own AS into that segment, and places that segment into the AS_PATH.
生成
当BGP路由生成一条BGP路由时,起源路由器会将该路由用update报文通告给其他邻居:
- 当通告给eBGP邻居时,这个update报文中会包含着类型为AS_SEQUENCE的AS_Path,路由器会将它的AS号放入该AS_Path中;
- 当通告给iBGP邻居时,这个update报文中AS_Path部分将为空,因为路由发送给iBGP不会修改AS_Path属性;
修改
当运行BGP协议的路由器将一个从其他路由器学到的前缀宣告给另一个BGP邻居时,路由器是否修改前缀的AS_Path属性取决于通告的路由器是iBGP邻居还是eBGP邻居:
当BGP路由前缀被通告给iBGP邻居时,AS_Path属性不会被修改;
当BGP路由前缀被通告给eBGP邻居时,AS_Path属性会被修改:
- 如果AS_Path已经有数值且该数值类型为AS_SEQUENCE时,路由器会将它自己的AS号加到序列的左侧,因为靠左侧的AS编号是最新经过的AS;
- 如果AS_Path已经有数值且该数值类型为AS_SET时,路由器会为AS_Path添加一段包含自己AS号在内,属性为AS_SEQUENCE的新序列,这个AS_SEQUENCE新序列和之前的AS_SET相互独立,但AS_SEQUENCE和之前的AS_SET是有先后之分的,下图中的AS_PATH表示路由先经过了{10 20}这个类型为AS_SET的AS,然后经过了30这个类型为AS_SEQUENCE的AS:
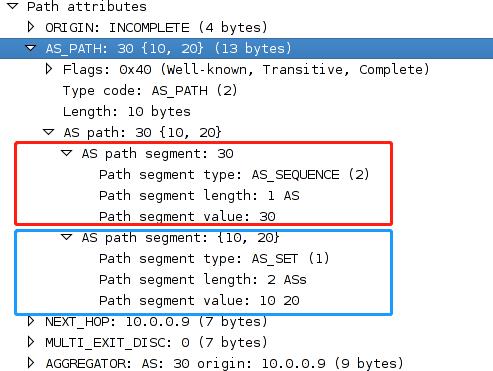
- 如果AS_Path值为空,路由器会创建一个属性为AS_SEQUENCE的序列并将自身的序列号加入其中。
这也意味着如果要修改AS_Path属性,必须在AS边界路由器上执行策略。
实验
AS_SEQUENCE
R1发给R2的update中的AS_Path:
R1和R2之间是eBGP邻居,所以该update在离开AS100时,会生成类型为AS_SEQUENCE的AS_Path序列,并将自己的AS号,也就是100,放入其中。
R2发给R3的update中的AS_Path:
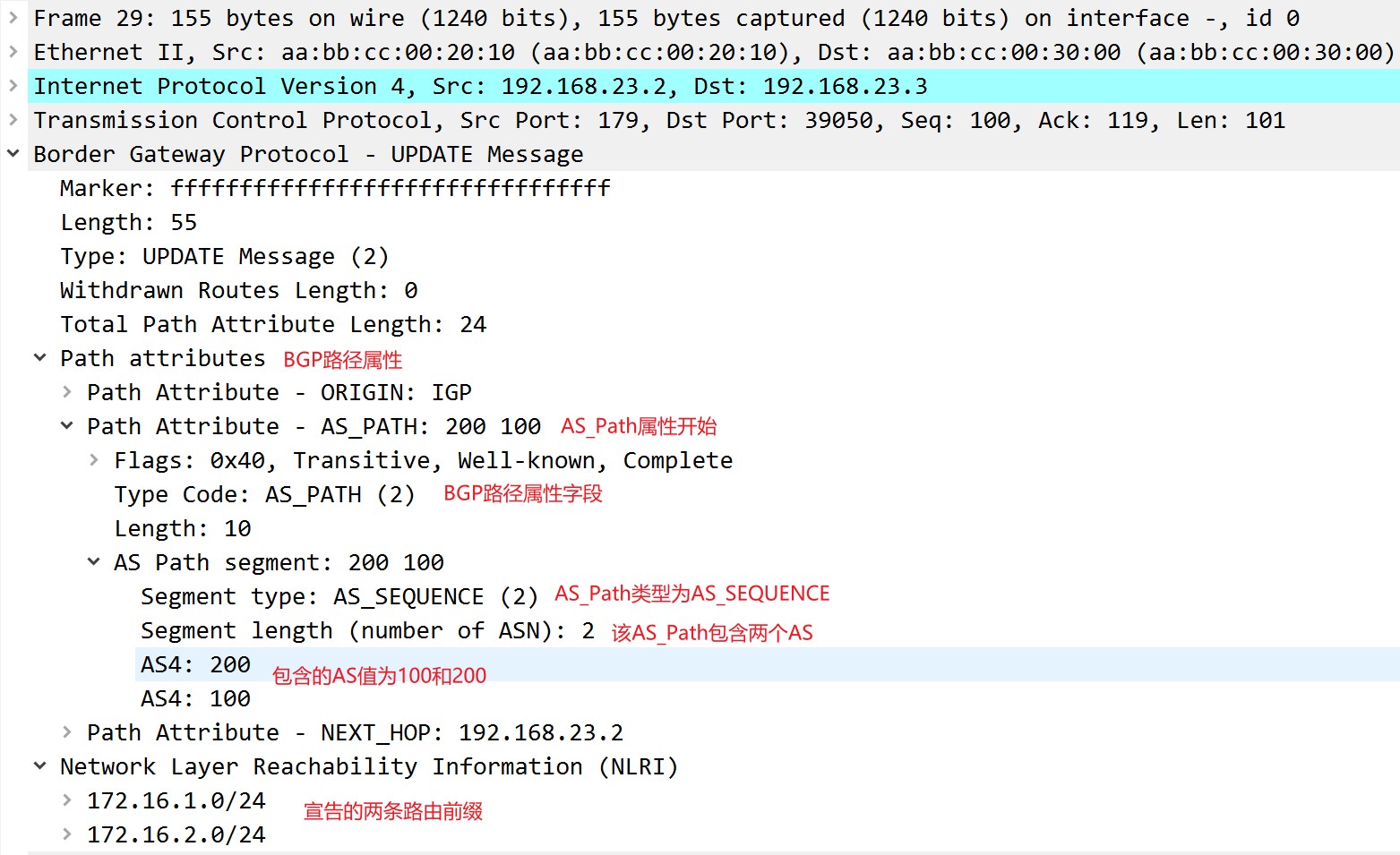
R2和R3之间是eBGP邻居,且该update中已经有了类型为AS_SEQUENCE的AS_Path,这个AS_Path值为100,这时R2会将它自己的AS号,200,加到序列号的左侧,也就是加到100的左侧。
AS_SET
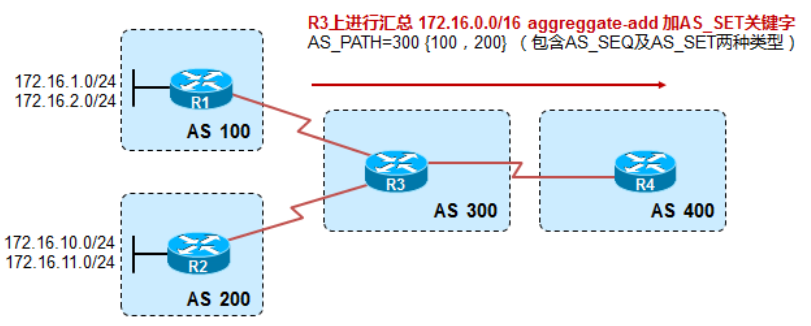
R1和R3、R2和R3、R3和R4之间都是ebgp邻居,R1上用loop 1和loop 2两个环回口宣告172.16.1.0/24和172.16.2.0/24的两条BGP路由,R2上用loop 1和loop 2两个环回口宣告172.16.11.0/24和172.16.10.0/24的两条BGP路由,在R3上用aggregate-address as-set命令汇总,由于在汇总时带了AS_Set命令,产生的这条汇总路由可以继承明细路由的某些路径属性,比如AS_Path、Origin、Community等,具体参见后面路由汇总部分,现在我们只观察AS_Path部分。
基本配置:
R1:
1 | interface Loopback0 |
R2:
1 | interface Loopback1 |
R3:
1 | interface Ethernet0/0 |
R4:
1 | interface Ethernet0/0 |
R4上的BGP表如下:
1 | R4#show ip bgp |
先看最上面172.16.0.0这条汇总路由的update:
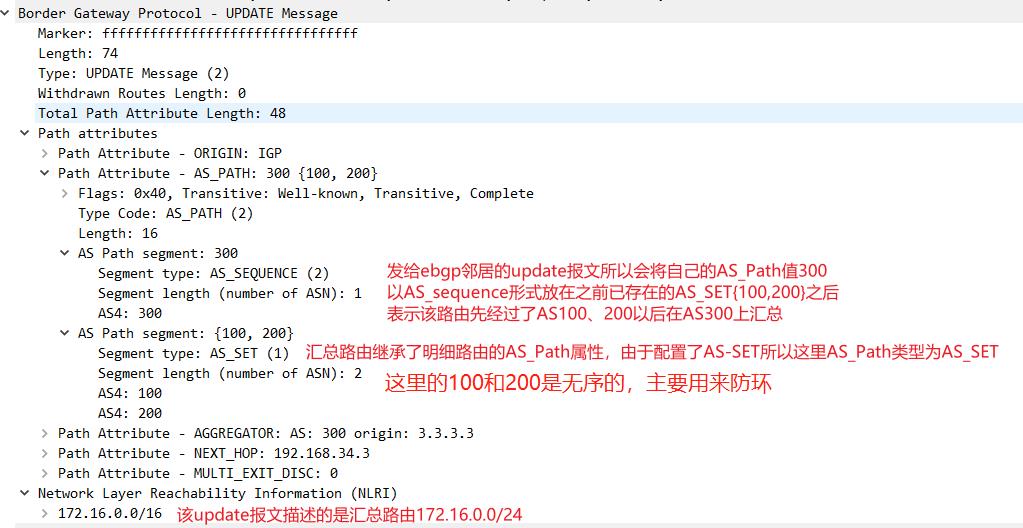
这条汇总路由的AS_Path部分包含两部分,值为300的为AS_SEQ 类型,用来标识路由起源,它是有序的;值为{100,200}为AS_SET类型,用来标识汇总前的明细的AS列表,它是无序的,用来防环。
如果你做实验并抓包了会发现,update中除了172.16.0.0/16这条汇总路由以外,携带了明细路由,这些明细路由的AS_PATH类型都是AS_SEQ 类型:
修改AS_Path
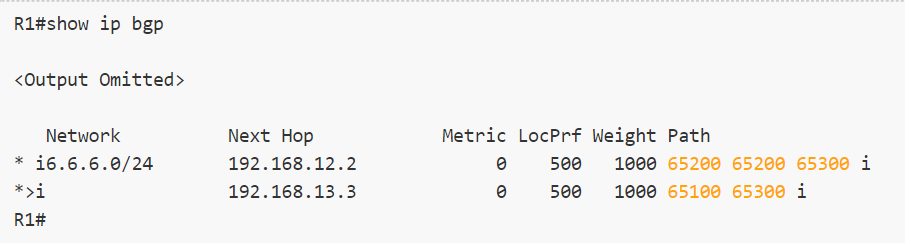
R1和R3、R2和R3之间都是EBGP邻居,R1和R2上均宣告一条1.1.1.0/24的BGP路由,目前R3上的BGP表如下:
1 | R3(config-router)#do show ip bgp |
可以看到目前到1.1.1.0/24选择的是从R1到达,如何通过控制AS_PATH来影响选路呢?可以在R1上做策略:
1 | ip prefix-list 1 seq 5 permit 1.1.1.0/24 |
这样配置后,R3上从R2学到的关于1.1.1.0的路由中的AS_PATH就由‘100 i’变成了‘100 6666 i’,当然这种操作在现网中还是不建议,因为6666这个AS并不存在,虽然加长了AS_PATH但带入了一个根本不存在的AS,所以可以用‘et as-path prepend 100 100 100’这种重复本AS的方式加长来实现目的同时避免不必要的麻烦。当然也可以在R3上对R1使用route-map:
1 | R3: |
做完配置后,R3上从R1学到的关于1.1.1.0的路由的AS_Path就会变成‘6666 100 i’,这是因为R3收到1.1.1.0的时候,AS_Path已经是‘100 i’了,而新加入的AS号只能在左边插入:
1 | R3(config-router)#do show ip bgp |
使用策略修改AS_Path只能在BGP路由器上对其eBGP邻居执行,是因为AS_Path只有在AS边界才会发生改变,因此如果对iBGP邻居做AS_Path的策略修改是无效的。
Next-hop
定义
Next-hop是公认必遵属性,描述了到目的地的下一跳路由器。
传递规则
路由传递自eBGP邻居
如果BGP 路由传递自EBGP peer,那么这条BGP路由的NH就是通告者的接口IP,EBGP邻居一般使用对方的直连接口IP互指neighbor,但如果是采用Loopback接口建立的EBGP邻居,则NH就是EBGP邻居的更新源地址(一般情况下EBGP邻居不适用Loopback接口建立邻居)。
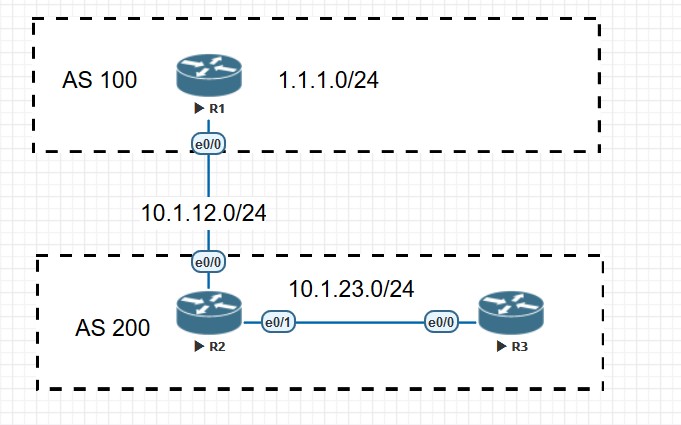
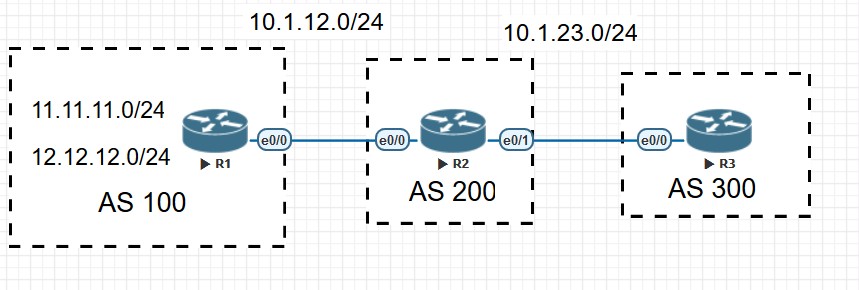
比如上面拓扑中的R1和R2为EBGP邻居,R1上宣告了一条1.1.1.0/24的BGP路由,该路由通过update报文传递给R2,由于R1和R2建立邻居使用的是直连接口,该直连接口的IP地址为10.1.12.1,所以在R2的BGP表中,该路由的下一跳为10.1.12.1,也就是说要去往1.1.1.0/24的数据,发送给10.1.12.1,也就是发给R1就行了,看到这,是不是感觉BG在nexthop方面很像之前的RIP呢?这是因为两者都是距离矢量路由协议,都是基于传闻传递的路由,而不是状态链路路由协议,所以不知道整体拓扑的连接情况,所以红茶三杯在讲BGP的时候曾经说过,BGP其实很像RIP协议,只不过多了很多的特性和属性,这个说法一个原厂大佬朋友也很赞同。
路由传递自iBGP邻居
同AS的路由器引入了某路由
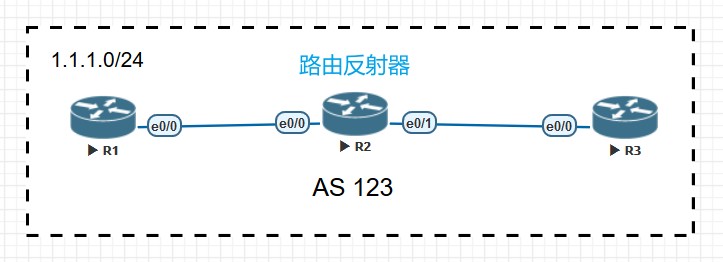
R1、R2、R3都在AS 123内,R1\R2,R2\R3之间为iBGP邻居都用直连接口建立,R1\R2之间网段为192.168.12.0/24,R2\R3之间网段为192.168.23.0/24,R1上宣告了一条1.1.1.1/32的BGP路由,并将其宣告给了iBGP邻居R2,如果这时不做额外的配置,那么由于水平分割原则(从一个iBGP邻居处收到的路由条目不会再传递给另一个iBGP邻居),那么R2不会将1.1.1.1/32这条路有宣告给R3,如果此时在R2上配置了路由反射器,打破了水平分割原则,所以R3能收到这条路由,在R3上这条路有的Next Hop依旧为R1的更新源地址,也就是R1和R2建立邻居的地址,192.168.12.1:
1 | R3(config-router)#do show ip bgp |
路由传递自iBGP邻居,描述的是AS外的目的地
从外部AS传递进来的路由,Next Hop为通告该路由的eBGP 邻居,且整个Next Hop会随着路由在AS内部传递而不发生改变,除非做了策略,否则始终指向的是下一个AS(通告该路由的eBGP 论据接口IP)。下面来看个例子:
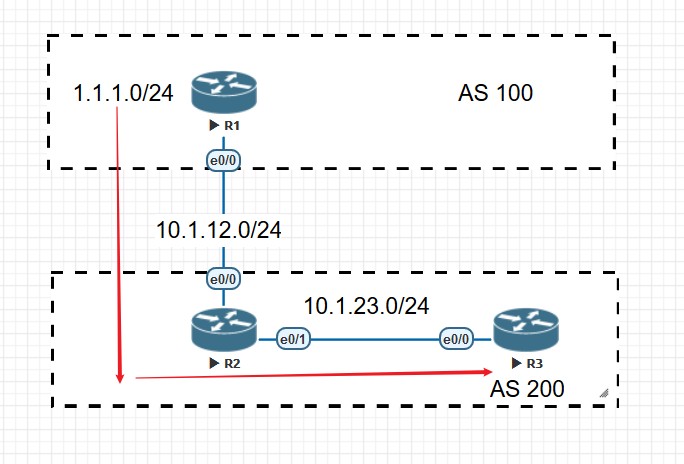
R1\R2为eBGP邻居,R2\R2为iBGP邻居,在R1上宣告一个1.1.1.0/24的路由,该路由宣告给R2,再由R2宣告给R3,来看这条路由在R3上的Next Hop:
1 | R3(config-if)#do show ip bgp |
可以看到,R3上关于该路由的Next Hop和在R2上一致,始终是R2建立eBGP邻居的那个IP:
1 | neighbor 10.1.12.1 remote-as 100 |
路由传递自iBGP邻居,并由AS内BGP路由引入
如果是通过aggregate-address命令被注入的,那么Next Hop等于执行汇总的路由器的更新源地址;
如果是通过network或重发布注入的,那么在注入前,该前缀的IGP下一跳将成为BGP的Next Hop;
如果本地的BGP宣告者成为了下一跳地址,那么在本地BGP RIB中的下一跳字段就是0.0.0.0;
Next-hop-self命令
由于next hop在传递给EBGP邻居时会改变,而传递给iBGP邻居时不会改变所以在建立iBGP邻居时,这样导致法网iBGP邻居的路由下一跳不可达从而不会加入路由表,此时可以用‘neighbor 1.1.1.1 next-hop-self’命令将传递给iBGP邻居路由的下一跳设置为自己,使得BGP路由的下一跳可达,具体用法及实验参照邻居建立中iBGP邻居部分。
Local-Preference
基本概念
Local-Preference是公认自决属性,默认值为100,只用于iBGP邻居之间,决定离开AS的最优路径,一般用于控制本AS的出口设备。
- Local-Preference就是本地优先级,当一个AS收到一个去往同意目的地的,但经过两个AS的路由,在其他BGP路由属性完全一致的情况下,根据两条路由的local-preference决定,值越大越优,比如下图中的路由器D,从C和E两个路由器都收到了去往172.20.0.0的路由,但E发过来的路由属性中Local-Preference值大于C发过来的路由属性,所以去往E的路由更优:
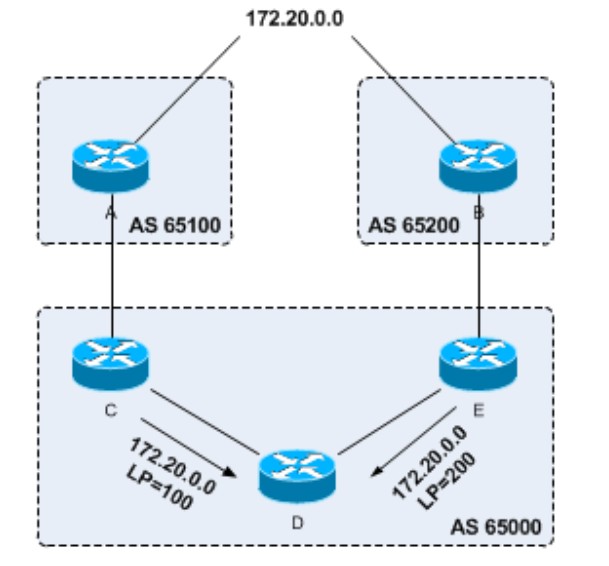
Local-Preference只能在AS内部的iBGP邻居之间传递,而不会传递给其他eBGP邻居,Local-Preference除非做了策略,否侧在AS内的iBGP邻居之间传递时不会丢失,如果eBGP邻居之间收到的路由的路径属性中携带了Local-Preference的话,会触发notification报文造成BGP会话中断,但可以在AS边界路由器上使用IN方向策略;
Local-Preference在向eBGP邻居发送路由更新时,不能携带LP属性,对方收到该eBGP路由的LP值为空,也就是说路径属性中根本没有LP这个字段,但它会在本地为这条路由赋一个默认值,也就是100,然后再传递给自己的iBGP邻居;
本地network命令及重发布命令发布的路由,LP值默认为100,并能在AS内向其他iBGP邻居传输,传输过程中除非部署了策略,否则LP值不会发生变化;
修改默认LP值的命令为:bgp default local-preference XXX。
实验及抓包
基础实验
R1发送给R2的update抓包中可以看到,eBGP邻居之间的路由属性中没有Local-Preference属性:
R2发送给iBGP邻居R3的update报文抓包中可以看到,iBGP邻居之间的路由属性中有Local-Preference属性,这里没有用策略修改,所以默认值是100:
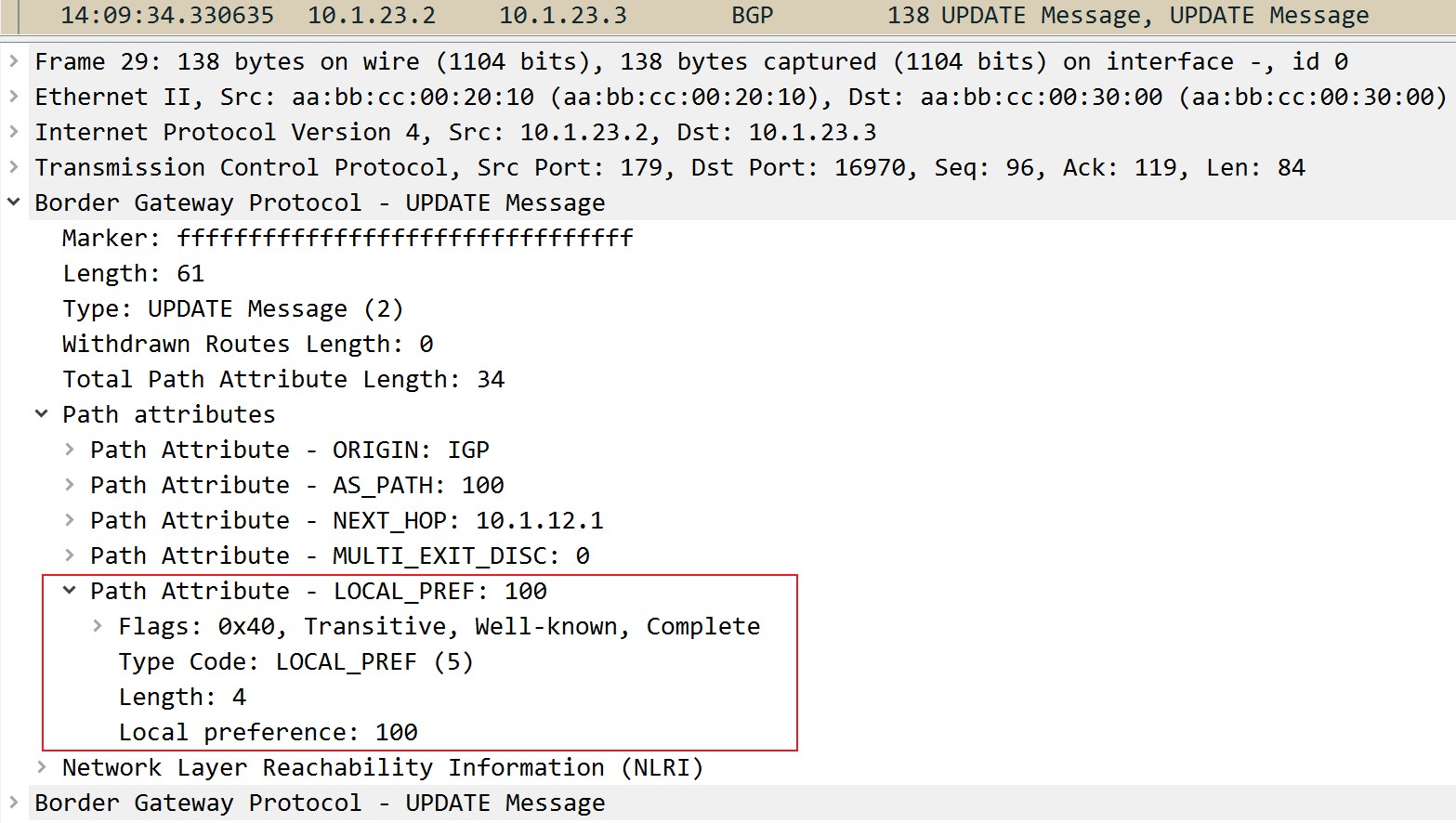
单独修改LP
拓扑和上一个实验相同,区别在于R1上除了宣告1.1.1.0/24以外,也宣告了111.111.111.0/24,在R3上的BGP表中如下:
1 | R3(config-router)#do show ip bgp |
从上面的BGP表中可以看到,默认情况下,两条路由在R3上的Local-Preference都是100,现在我们在R2上对111.111.111.0/24的路由做策略,让这条路由的LP变为200:
1 | R2: |
R3上的BGP表:
1 | R3(config)#do show ip bgp |
MED
基本概念
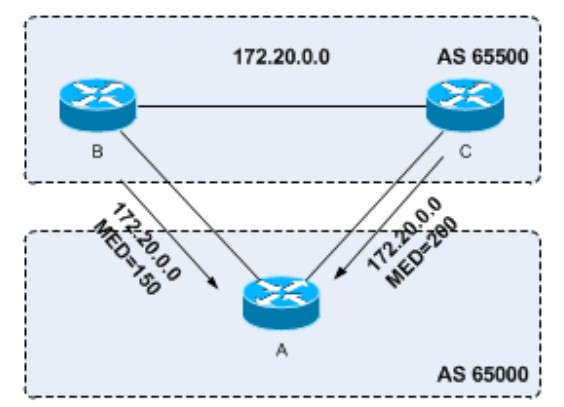
MED是可选非传递属性,当其他属性相同时,MED值越小越优,用于AS之间影响路由,一般用于控制进入本AS的入口设备,思科设备默认MED=0,默认情况下只比较来自同一邻居AS的BGP路由的MED值,如果同一个目的地的两条路由来自不同的AS则不进行MED值的比较。下图中路由器A从路由器B和C上都收到了172.20.0.0这条路由,B和C在同一AS所以比较MED值,由于B这条路由的MED值更小所以更优,故A会选择路由器B的路由:
设置方法
将IGP路由引入BGP时关联Route-map进行设置;
对BGP 邻居使用IN\OUT方向的Route-map进行设置;
非Route-map方式:
- 使用network或redistribute方式将IGP路由引入BGP时,MED将继承IGP路由的Metric(直连路由及静态路由的Metric为0);
- 使用aggregate-address方式引入路由则MED为空;
MED传递
当BGP路由通告给eBGP邻居时:
- 如果该BGP路由是本地始发的,也就是在本路由器上通过network或redistribute引入的,则发送给eBGP邻居时携带MED值;
- 如果该BGP路由是从其他BGP邻居雪莱的,则将该路由通告给eBGP邻居时不携带MED(路由属性中没有MED部分),换句话说,就是MED不会被传出本AS;
当BGP路由通告给iBGP邻居时,一定会携带MED值,如果接收或产生的路由的MED为空,那么在向iBGP邻居通告时,将MED设置为0。
总的来说就是MED在iBGP邻居之间传递没有问题,不会丢失,但在eBGP邻居之间传递要看路由是否起源于自己,起源于自己就带MED,不起源于自己就不带MED。
MED继承
network本地从IGP路由协议学到的路由进BGP,MED值继承IGP协议中的metric;
network本地直连接口的网段进BGP,MED值为0;network本地静态路由进BGP,MED值为0;
redistribute本地从IGP路由协议学到的路由进BGP,MED值继承IGP协议中的me
redistribute本地直连接口网段进BGP,MED值为0;redistribute本地静态路由进BGP,MED值为0。
其他配置命令
bgp always-compare-med
默认情况下,只有来自相同AS的外部路由才比较MED值,但如果配置了这条命令,即使是来自不同AS的路由,也会比较MED。如果配置了该命令,那么建议在整个AS中都这么配置,以避免路由选择环路。
bgp bestpath med missing-as-worst
如果某路由MED属性丢失,一般的做法是给MED默认设置为0,但如果配置了这条命令,再收到没有MED值的路由,会将该路由的MED值设置为最大,也就是4294967295。
set metric-type internal
用在route-map中,当用route-map匹配某些条目且使用了该set命令后,比如在out方向上向邻居应用了带set metric-type internal的route-map命令以后,被匹配的这些路由条目更新给邻居后,BGP的MED属性会继承这些路由在本地IGP的metric值。
bgp bestpath med confed
配置这条命令后,在选路时,路由器只比较具有带有AS_CONFED_SEQ属性的条目,此命令用于联邦路由器,同时weight及LP属性比MED具有更高的优先级。
bgp deterministic-med
用于确保来自相同的AS的不同对等体通告的路由先进行MED比较。
此命令和bgp always-compare-med的关系如下:

如果两条命令都关闭:则按缺省的从上往下的顺序进行比较 ,则 1、2 先比较,2 优选(因为 2 具有更小的 RID); 然 后 2 与 3 比较,2 为 external,所以 2 优选。
如果打开bgp always-compare-med:则 1、2 先比较,1 优选(因为 1 具有更小的 MED) ;由于 1、3 在一个相同的 AS 中,所以再次比MED,选 3。
如果打开deterministic-med,路由前缀的信息按AS重新分组:

- 如果都打开,则2、3 同 AS 内先比较,2 的 MED 小所以优选;2 与 1 再比较,由于开了 always-compare-med 所以比 MED,2 的 MED 小,所以 2 为最佳路径.
Default-metric X
修改MED值的缺省值,但此命令对直连路由不生效,直连路由的MED仍为0
COMMUNITY
基本概念
community属性为可选传递。
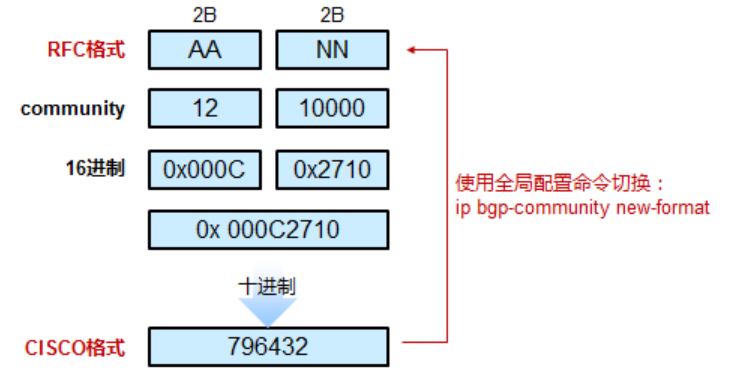
community属性是一组4个8位组的数值,RFC1997规定前2B表示AS号,后2B表示基于管理项目设置的标识符,格式为AA:NN,32位的BGP community被分成了两部分,前16位一般用来标识使用该community的AS号,后16位一般用来标识作用。而CISCO默认显示格式为NN:AA,可使用全局配置命令,ip bgp-community new-format将思科默认格式改为RFC格式。
例如将AS12的某条路由的community值改为10000,RFC采用十六进制表示community属性,而CISCO采用十进制。RFC格式为12:10000,十六进制为0X000C2710,再转换为十进制796432:
用于简化路由策略的执行,可以将某些路由分配一个特定的community属性,之后可基于community值而不是每条路由进行BGP属性的设置了。community属性对邻居起作用。具体如何执行呢?让我们用一个北美ISP举例:
1 | -------------------------------------------------------- |
上边是一个过去的北美ISP的配置,用来说明如何使用community属性来简化配置。如果该ISP将一条前缀打上3356:90的标签,那么这条前缀的local preference将被设定为90,如果将路由打上标签64983:0,则该路由在发送到欧洲的邻居对等体之前将复制自身AS三次。这么做就不用每次对一条路由做策略时都需要配置相同的route-map了,只需要将路由前缀打上相应的TAG划分到相应的community中就能实现相应的路由操作。
community属性是可选传递,在设置后,同时需要向邻居发送(SEND),邻居才能真正收到这个community,而且要每个邻居设置一次,举例看一下:
如果R1上针对11.11.11.0/24设置了community,那么必须在R1上配置‘neighbor 10.1.12.2 send-community’那么R2才能收到这个community,但如果R2上不对R3配置send-community,这个community R3是不知道的,必须在R2上对R3设置‘send-community’R3才能收到这个community。配置send-community是思科和华为的做法,juniper默认不用配置就能传递community。
除了上面这个community,还有一个扩展community(extended community),具体在MPLS VPN部分会具体写这个,不要混淆两者。
基本概念实验
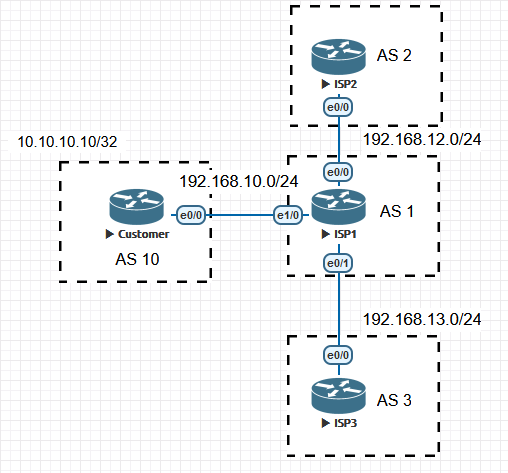
左边的customer路由器连接到ISP1上,位于北美的ISP1又分别连接了ISP2和ISP3,假设ISP2是位于欧洲的服务器,当ISP1发送路由更新到位于欧洲的ISP2上之前,需要先将本地的AS号复制四次,这里用community进行配置,将这些发送给欧洲的路由前缀的community值设置为64984:0。
基本配置
1 | Customer#show running-config | section bgp |
此时ISP1已经从Customer路由器上学到了路由:
1 | ISP1(config-router)#do show ip bgp |
配置customer
首先使用前缀列表抓取10.10.10.10/32这条需要进行配置的路由,假设这条前缀要发送给位于欧洲的ISP2,在customer上赋予community值方便在ISP1上进行操作:
1 | Customer(config)#ip prefix-list LOOPBACK permit 10.10.10.10/32 |
接下来用route-map来设置BGP的community,所有符合前缀列表的路由将被赋予community值,也就是64984:0,因为发送给欧洲的路由前缀的community值设置为64984:0。
1 | Customer(config)#route-map SET_COMMUNITY permit 10 |
现在来对ISP1使用这条route-map,赋予发往ISP1的路由community值:
1 | Customer(config)#router bgp 10 |
对ISP1配置了send-community是因为community为可选传递属性,路由器不会自动发送community到邻居。
配置ISP1
接下来在ISP1上用配置community:
1 | ISP1(config)#ip community-list 1 permit 64984:0 |
首先配置community列表,该列表和access-list以及prefix-list很像,但只用于BGP的community上,这个community-list 匹配的是由customer发过来的community值为64984:0的路由前缀,其实也就是抓取的10.10.10.10/32这条路由。接下来用route-map设置将这条路由的AS号复制四次:
1 | ISP1(config)#route-map PREPEND_EU permit 10 |
接下来将这条route-map应用到邻居ISP2的出方向上:
1 | ISP1(config)#router bgp 1 |
验证配置
在customer上软刷新BGP后在ISP1上可以看到它已经收到了BGP 的community值,最后一行的‘Community: 4258791424’:
1 | ISP1#show ip bgp 10.10.10.10 |
可以看到ISP1确实收到了community但并没有按照AA:NN的格式显示,是因为思科默认使用自己的格式显示,而不是使用RFC格式,在ISP1上配置‘ip bgp community new-format’后会恢复成RFC格式:
1 | ISP1#show ip bgp 10.10.10.10 |
再来看ISP2上该配置是否生效了,对比ISP3上的这条路由发现配置生效了:
1 | ISP2#show ip bgp |
如果以后Customer要发送其他路由到位于Europe的ISP2路由器,那么只需要在Customer上将之前配置的抓取路由的前缀列表进行适当更改,匹配上那条新路由即可。
常见命令
No-advertise
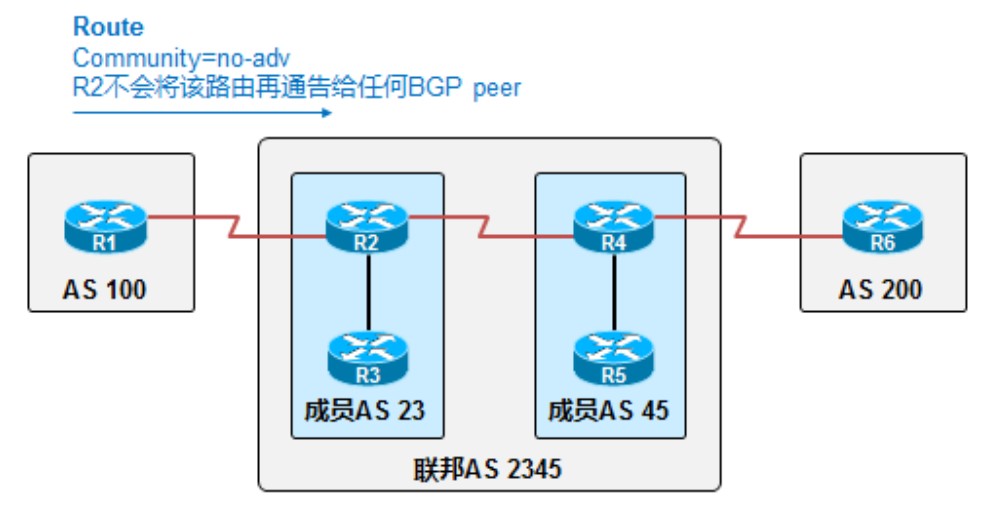
当为一条前缀配置了no-advertise命令时,收到这条前缀的BGP路由器,R2,会将这条前缀存储在自己的BGP表中,而不会向其他邻居宣告这条路由。用下图中的拓扑举个例子,如果在R1上配置了no-advertise这条community的命令,则R1传给R2的路由,R2不会再发给任何BGP对等体邻居。
No-export
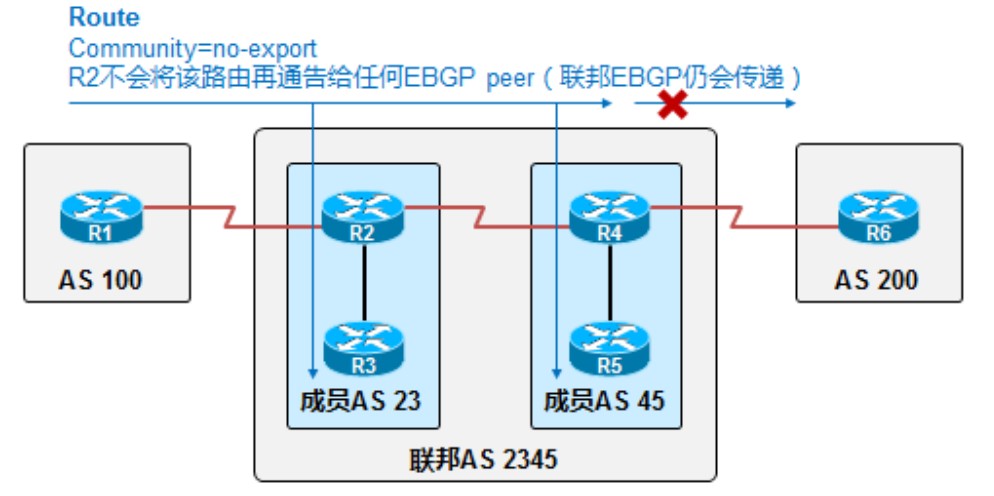
当为一条前缀配置了no-export命令时,收到这条前缀的BGP路由器R2只会将这条路由宣告给iBGP邻居而不会宣告给任何eBGP邻居(会传递给联邦eBGP邻居)。用上图中的拓扑举个例子,如果在R1上配置了no-export这条community的命令,则R1传给R2的路由,R2只会传递给在AS 2345内部的路由器,也就是只传给R3\R4\R5,但不会传递给eBGP邻居R6。
Local-as
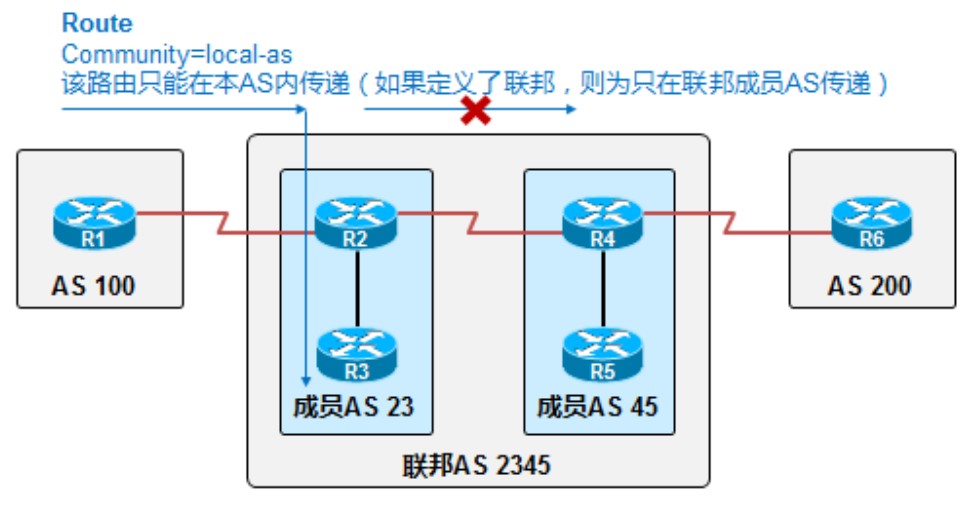
local-as和之前的no export有些类似,区别在于当为一条前缀配置了local-as命令时,如果定义了联邦,只会在联邦AS内部传递不会传递给联邦eBGP邻居。用上图中的拓扑举个例子,如果在R1上配置了local-as这条community的命令,则R1传给R2的路由,R2只会传递给联邦iBGP邻居R3,但不会传递给联邦eBGP邻居R4。
为路由分配community
在R1上为路由11.11.11.0/24分配community 100:11,并且传递给R2,那么R1上配置如下:
1 | ip prefix-list 1 seq 5 permit 11.11.11.0/24 #抓取需要分配community的前缀 |
一条前缀路由可携带多个community形成一个列表,如果要针对特定路由在原有的community基础之上再增加一个community,则在route-map中set community时,增加additive关键字即可,比如R1在上面配置的基础上加上如下配置:
1 | route-map COMMUNITY permit 10 |
最后route-map的结果如下:
1 | R1(config-route-map)#do show run | s route-map |
community-list
基本概念
ip community-list和ACL类似,ACL用来抓取前缀,ip community-list用来抓取community的值,和ACL类似,community-list也有标准和扩展之分,1-99为标准,100-199为扩展,标准ip community-list 后面只能跟XX:NN的格式,而扩展的community-list可以使用正则表达式匹配路由,下面扩展community-list后面的regexp是正则表达式的意思,在笔记的其他章节会涉及到:
1 | p extcommunity-list standard list-name { deny | permit } generic { transitive | nontransitive } aa4 : nn |
当使用扩展community-list且后面接了正则表达式的情况下,设备是否配置了ip bgp-community new-format会影响community-list匹配的结果。
删除特定值
前面说过,一条路由允许携带多个community值,构成一个community列表,那么如果不是要删除全部的community值,而是想删除1个或几个community值,例如一个带有12:11、12:1111以及no-export的community列表,要删除其中的no-export的话:
1 | ip community-list 1 permit no-export #匹配要删除其中的no-export的community值 |
如果要删除多个但不是所有community值的话,则可在一个community-list中写多条:
1 | ip community-list 1 permit no-export |
然后在用set comm-list 1 delete去删除,这里必须注意community-list必须写多行,如果在一行里写多个community,比如ip community-list 1 permit no-export 12:1111则不生效,删除不了这两个值。
示例1
在上面实验的基础上,R1传递给R2的11.11.11.0/24的路由,携带了community值,100:11,这个值可以在R2上用ip community-list进行匹配,从而可以进一步在route-map中使用这个community-list去设置策略。我们先在R2上用community-list去匹配100:11,通知添加一个no-export的community到该路由。
R2的配置如下:
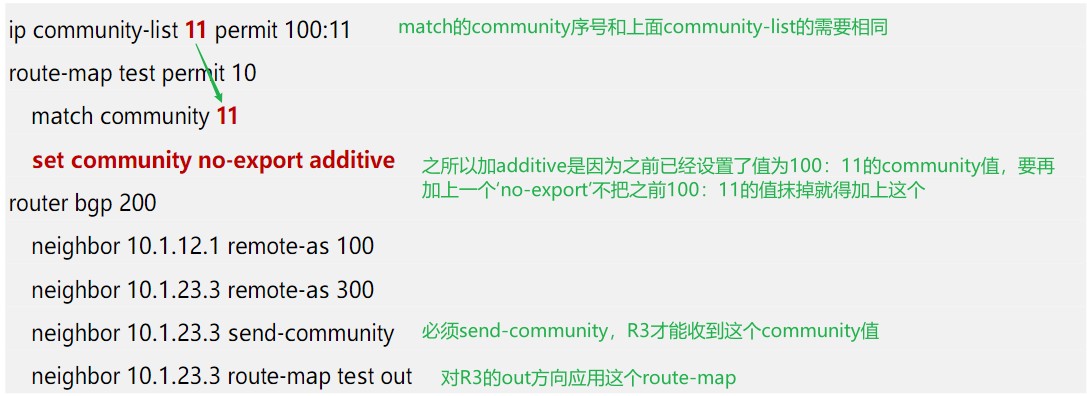
R3上关于11.11.11.0这条路由:
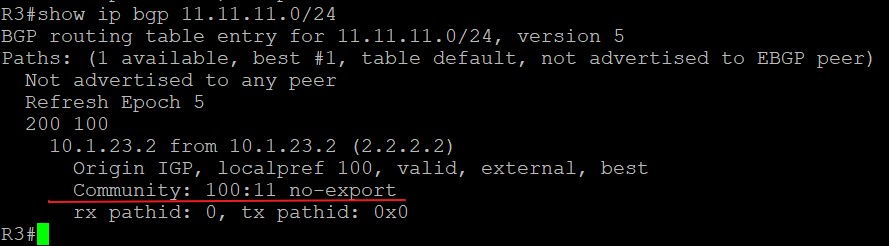
示例2
在上面例子的基础上,11.11.11.0/24路由前缀所携带的community属性为‘100:11 no-export’,看以下的community-list是否能匹配到这条路由:
1 | ip community-list 11 permit 100:11 |
1 | ip community-list 11 permit 100:11 no-advertise |
1 | ip community-list 11 permit 100:11 |
示例3
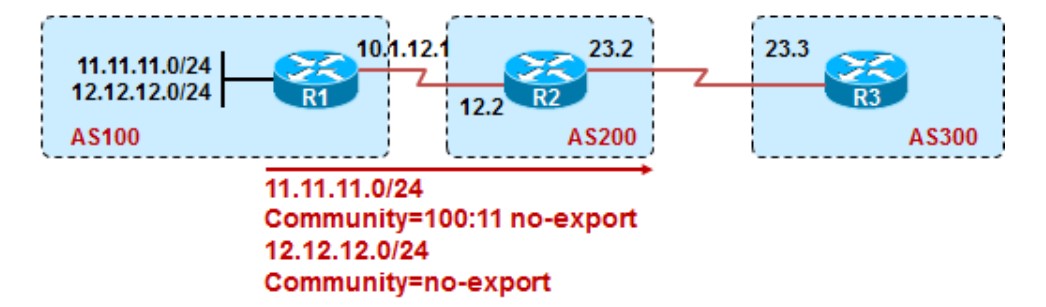
在上面实验的基础上,12.12.12.0/24也携带了no-export的community值:
1 | R1: |
如果我们只希望匹配community值为no-export的路由,该如何呢?如果是直接匹配no-export的话,不仅会匹配到12.12.12.0/24,也会匹配到community值为100:11 no-export的11.11.11.0/24这条路由,这里要用到exact-match的关键字了,在R3上配置:
1 | ip community-list 11 permit no-export |
如果不加exact-match关键字,则该community-list将匹配11及12的路由,加了以后,则只匹配community为no-export的路由,不能多也不能少。
示例4
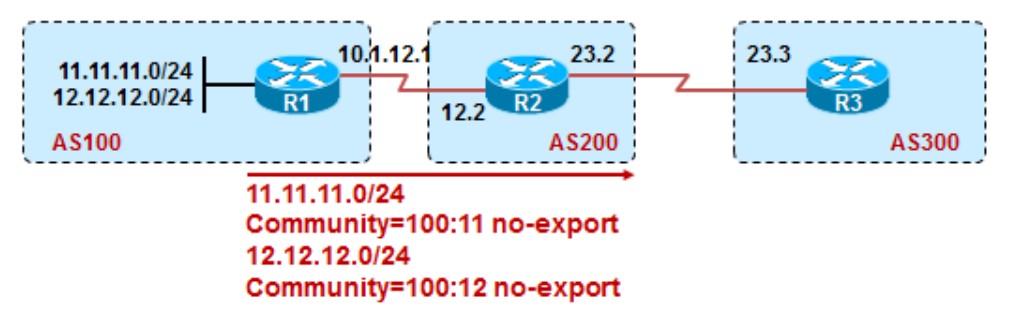
R2收到R1传过来的两条路由,分别携带的community属性如上,这里我们只想删除11.11.11.0/24所携带的no-export属性,这里有两种办法。
*方法一:*
1 | R2: |
ip community-list 11 permit 100:11 no-export,这条名称为11的标准community-list用来匹配community值为100:11 no-export的对象,在这也就是抓取11.11.11.0/24这条路由;
ip community-list standard del permit no-export,这条名称为del的标准community-list用来匹配community值为no-export的对象;
match community 11,表示匹配名称为11的community-list,也就是11.11.11.0/24这条路由;
set comm-list del delete,表示将11.11.11.0/24这条路由中no-export的对象删除,之前这条路由的community有100:11和no-export两个,删除掉no-export后只剩下100:11了;
neighbor 10.1.12.1 route-map test in,在邻居10.1.12.1的in方向上使用route-map test;
如果想把11.11.11.0/24路由的100:11以及no-export两个community值都删除,则修改del的这条community-list即可:
1 | ip community-list standard del permit no-export |
1 | R2: |
Atomic_Aggregate及aggregator
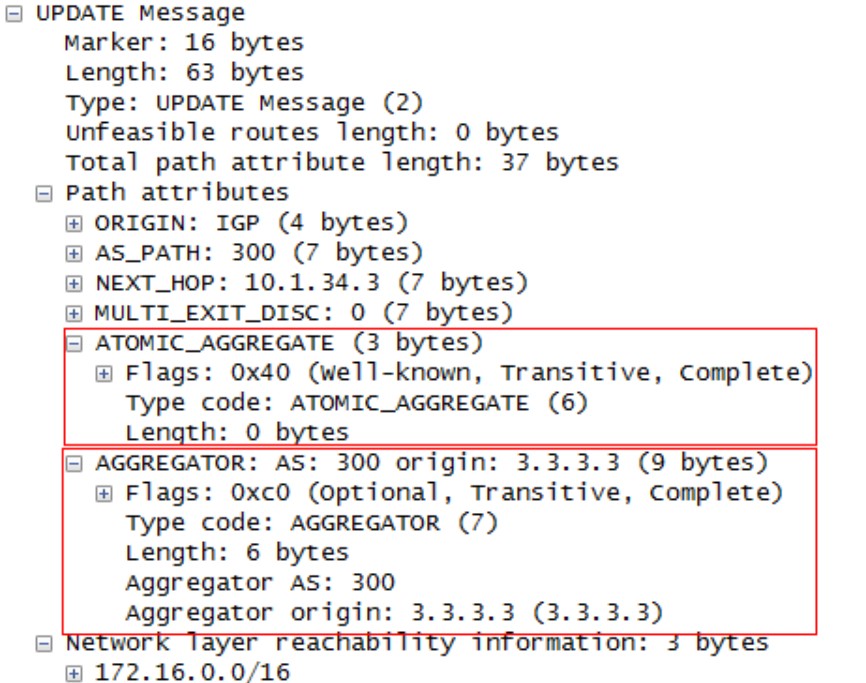
Atomic_Aggregate是公认自决属性;Aggregator是可选传递属性。
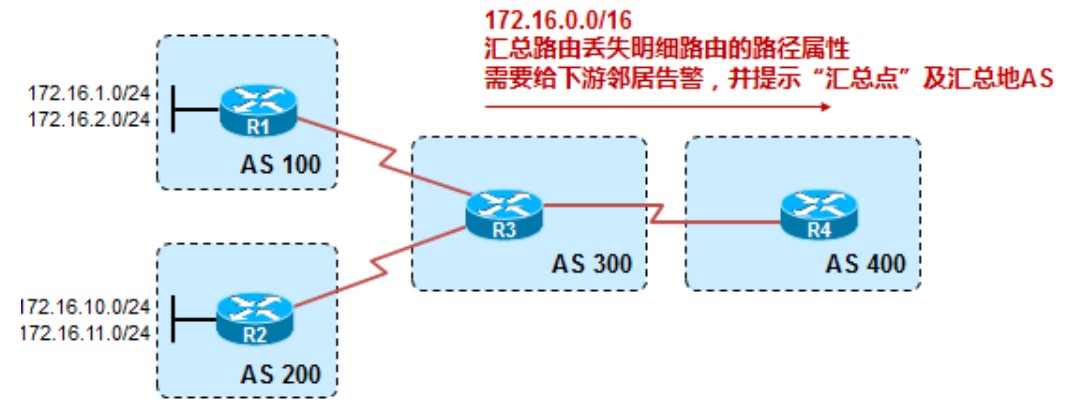
R1和R2均发布了路由,R3上对这些明细路由进行了汇总,汇总成172.16.0.0/16,汇总路由被R3传递给了其他BGP邻居,然而这条汇总路由丢失了明细路由的所有属性,其中的AS_Path最关键,因为一旦丢失了明细路由的AS_Path属性,这条汇总路由就极有可能产生路由环路。因此有必要让R3警告下游的BGP邻居,告诉它们两点,其一,这是一条汇总路由,其二汇总路由发生的地方,也就是汇总路由的始发AS和始发路由器。
在R3上配置‘aggregate-address 172.16.0.0 255.255.0.0’或‘aggregate-address 172.16.0.0 255.255.0.0 summary-only’进行汇总时,R4上关于汇总路由如下:
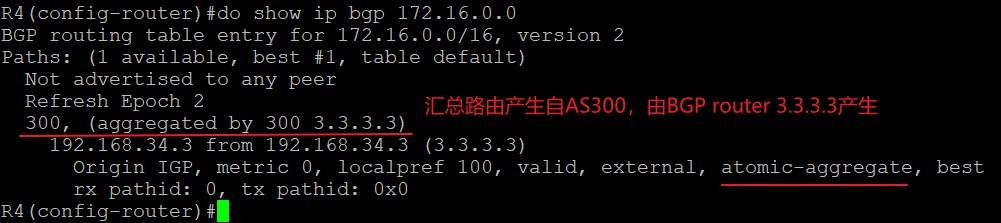
抓包如下:
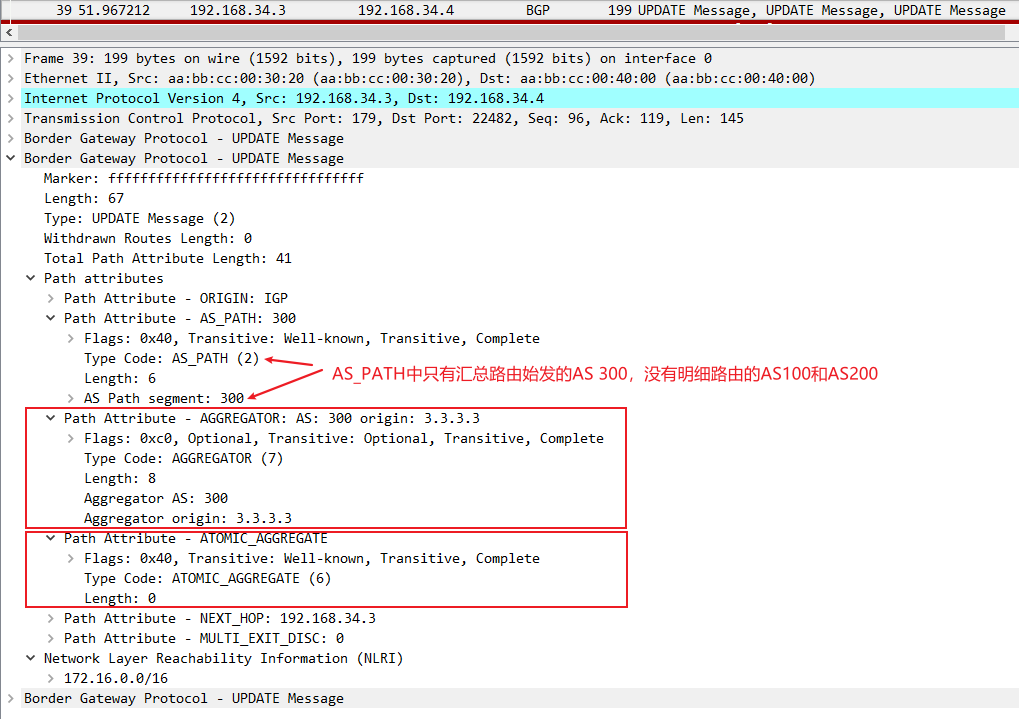
其中Aggregator是可选传递属性,用来标识路由是在AS300的路由器3.3.3.3上经过汇总的;Atomic_Aggregate是公认自决属性,由于配置路由汇总时没有带上AS_SET命令,所以AS_PATH中只有路由被汇总路由器的AS号300,有可能会将汇总路由传回明细路由的AS100或200从而产生环路,所以在汇总路由不携带明细路由的AS_PATH时,需要加上atomic_aggregate属性警告下游BGP peer,这是一条汇总路由,局和路径丢失了某些信息,可能不是去往目的地的最佳路径(The purpose of the attribute is to alert BGP speakers along the path that some information have been lost due to the route aggregation process and that the aggregate path might not be the best path to the destination.)
如果在R3上汇总命令中加上as-set关键字,则汇总路由就继承了明细路由的AS_Path属性,没有丢失AS_PATH信息,就不需要加上Atomic_Aggregate属性了,汇总时加上AS_SET的抓包如下:
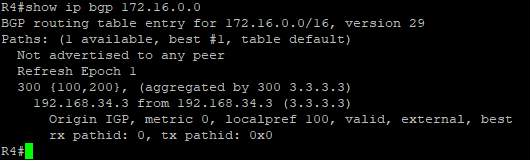
R4上关于172.16.0.0的输出中也没有了Atomic_Aggregate,具体如下:
总结
Aggregate是可选传递属性,用来标识路由在哪个AS的哪个路由器上进行过汇总,只要是汇总路由就会携带Aggregate属性;Atomic_Aggregate是公认自决属性,用来提醒沿途路由器,聚合路由丢失了某些属性,可能不是最佳路径。在汇总时如果不使用AS_SET命令,则汇总路由不携带明细路由的AS_Path,这时候执行汇总的路由器会将用Atomic_Aggregate属性来提醒其他路由器。如果汇总时使用了AS_SET命令,则明细路由的AS会用AS_SET形式保存在汇总路由的AS_Path中,没有丢失属性,所以这时汇总路由不携带Atomic_Aggregate属性。
思科设备的对汇总路由的默认做法是,汇总路由默认不携带明细路由的所有AS_Path信息,如果汇总时没有使用AS_SET命令,则汇总路由必携带Atomic_Aggregate属性;而juniper的做法和思科完全相反,汇总路由默认会携带所有明细路由的AS_Path,这意味着用来提醒属性丢失的Atomic_Aggregate属性不是必须有的。
ORIGINATOR_ID和CLUSTER_LIST
基本概念
由于AS_Path属性在AS内部不会发生变化,仅当路由离开本AS时才会被更新,而路由反射器打破了水平分割原则,有可能使路由出现环路,所以AS内必须有相对应的防环机制,所以路由反射器使用两个新的属性进行防环,ORIGINATOR_ID和CLUSTER_LIST,二者为路由反射器使用的可选非传递属性,用来防止环路。
- ORIGINATOR_ID是一个路由反射器创建的32bit值,该数值是本地AS中路由发起方的iBGP Router ID,注意发起方未必是这条路由的引入者,如果发起方发现其RID在所接收到的路由的ORIGINATOR_ID中,那么就知道已经出现了路由环路,因此会忽略该路由。
- CLUSTER_LIST是遗传路由传递所经过的路由反射簇(Cluster)的ID,AS内的每个路由反射簇都有一个32bit的簇ID,如果簇中包含了多个RR,则需手工为每个RR配置簇ID。当RR将来自客户的路由反射给非客户时,同时将其簇ID附加到CLUSTER_LIST中,如果CLUSTER_LIST为空则创建一个,如果反射路由器发现其本地簇ID出现在了其受到的CLUSTER_LIST中,那么就知道出现了环路,则忽略该路由。CLUSTER_LIST属性只用于RR防环,RR只在反射路由的时候才会创建或更新CLUSTER_LIST,而下面几种情况,RR不会创建该属性:1、RR自己始发的路由;2、RR向EBGP邻居发送路由更新时,将会清除所有的CLUSTER_LIST属性;3、当RR从eBGP邻居收到路由,传递给client或非client时,不会创建CLUSTER_LIST。
ORIGINATOR_ID取值
R1位于AS100,与R2是eBGP邻居关系,将1.1.1.0/24的路由传递给R2,R2传递给iBGP邻居R3,但由于水平分割原则,R3不会将从iBGP邻居R2处学到的1.1.1.0/24路由传递给另一个iBGP邻居R4,这种情况下如果想将路由传递给R4,使R3成为RR,R4为R3的client,R3就能将路由传递给R4了,此时身为RR的R3会添加ORIGINATOR_ID和CLUSTER_LIST进路由,其中ORIGINATOR属性为R2的Router ID,也就是2.2.2.2而不是R1的Router ID,1.1.1.1:
CLUSTER_LIST与BGP选路
R1宣告11.11.11.0/24进BGP,R5分别通过R2和R4学到这条路由,在其他属性一致的情况下,Cluster list短的路由更优:
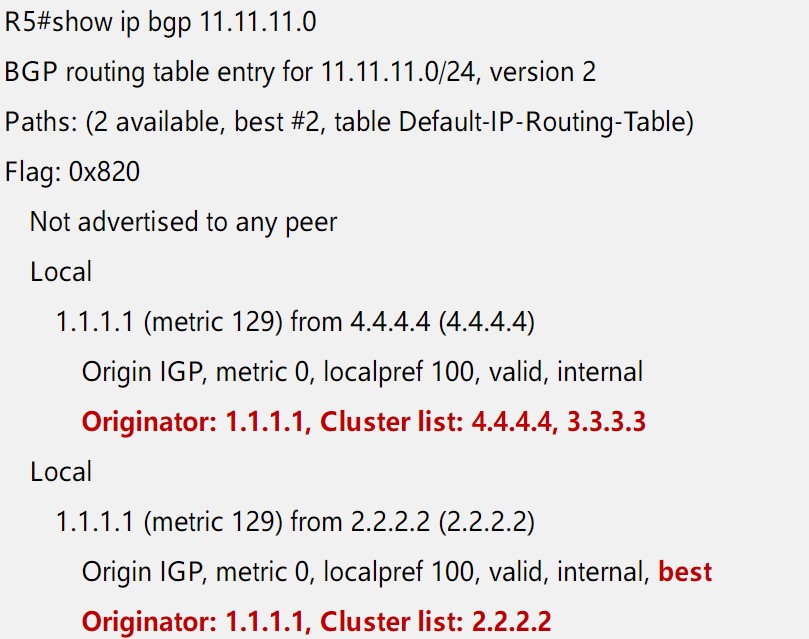
冗余RR环境
单RR可能会存在单点故障,因此从冗余性的角度出发,一个簇中可以拥有多台RR,Client与每一台RR都有物理连接并建立BGP对等体关系,在其中一台RR出现故障的情况下,Client仍然有替代连接。因为Client不知道主机是别人的Client,所以RR本身也可以成为别人的Client,使用荣誉RR增加了网络的健壮性,ORIGINATOR_ID和CLUSTER_LIST属性用来在冗余RR中避免环路,可以将两个RR的Cluster ID配置为一样,可以进一步起到防环作用,所有的RR之间建议采取全互联的形式,比如:
Weight
weight属性为思科私有,作用范围是本路由器,该值既不会被包含在update报文中,也不会传递给任何BGP邻居,只在路由器本地产生影响,中文翻译为权重值,越大越优先。取值范围为0-65535。如果路由是从其他BGP邻居学过来的,则weight值为默认的0;如果路由是从本地network产生的,则weight值为32768;本地重发不的直连接口路由或静态路由的weight为32768;本地汇总产生的BGP路由weight值为32768。
协议配置
建立邻居
1 | network X.X.X.X mask Y.Y.Y.Y route-map NNNN |
在IGP中,network命令用于确定要发送和接收路由更新的接口,以及通告哪些直连的网络;
在BGP中,network命令与BGP在哪些接口上运行无关。仅仅是讲本地某个网络注入到BGP里,该路由我们称为可靠的。也就是说,只有路由表中有这个路由条目,且它不在BGP表中,才能使用network命令讲它注入到BGP表中。比如下面这个路由器的路由表中,有10.0.0.0/24这条路由,才能在BGP中用network 10.0.0.0 mask 255.255.255.0这条命令来宣告,将它注入进BGP中。而不能注入一条路由表中没有的路由,比如这个路由器中没有192.168.1.0/24这条路由,所以就不能network这条路由进BGP。再比如路由表中有192.168.0.0/24的路由,如果network 192.0.0.0也不成功。
后边的route-map NNNN,就是对前边宣告路由进行属性上的操控。
1 | neighbor X.X.X.X remote-as Y.Y.Y.Y |
neighbor 的这个地址必须是IP可达的。
邻居身份验证
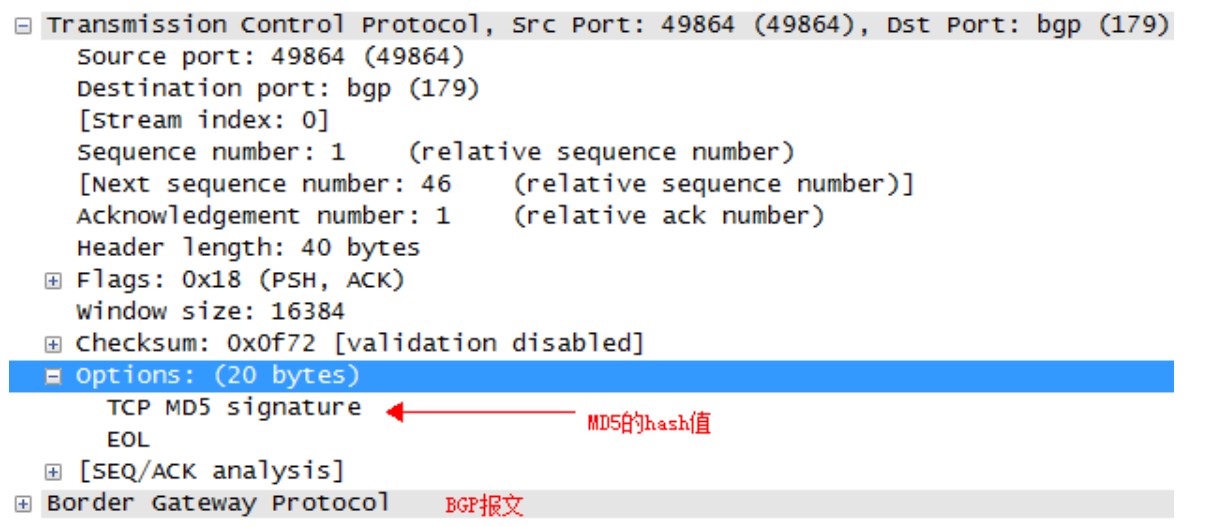
BGP支持MD5身份验证,要在BGP对等体邻居之间的TCP连接上启用MD5身份验证,使用命令如下:
1 | neighbor X.X.X.X password YYYY |
同一个BGP连接,密码必须一致,不同的邻居可设置不同的密码。认证配置完毕后,将通过对等体之间的TCP连接传输所有的数据端进行验证,注意这只是基本的身份验证功能并不是加密,抓包如下:
重置BGP连接
硬重置
硬重置意味着将所有的BGP邻居的TCP连接以及BGP邻居状态都重新复位。
clear ip bgp * //表示将所有邻居的TCP、BGP连接都重新复位;
clear ip bgp * {neighbor-address} //表示将特定邻居的TCP、BGP连接重新复位,比如如果配置clear ip bgp * 1.1.1.1,表示将邻居1.1.1.1的TCP、BGP连接重新复位。
软重置
和硬重置不同,软重置不会拆重建邻居的TCP或BGP连接,而是浸出法更新的操作以便让新的路由策略生效。软重置可以单独用于出站或入栈策略,也可以同时用于出站入站策略。
clear ip bgp * soft //对所有的邻居的出站及入站进行软重置
clear ip bgp soft out //出站软重置,会重新发送update消息给所有邻居;
clear ip bgp soft in //入站软重置,本地重新发送route-refresh给所有BGP邻居;
clear ip bgp {neighbor-address} soft in/out //对特定邻居使用软重置;
执行入站软重置的方法有两种:
Soft Reconfiguration
这种重置方式的中文叫‘使用存储的路由更新信息的软重置’,是一种相对老一些的软重置方式,使用这种方式进行软重置,需要在输入命令前先使用命令neighbor x.x.x.x soft-reconfiguration inbound才可以进行软重置。在BGP进程中使用以上命令会将x.x.x.x邻居发来的最原始、未经过滤变更的BGP路由存储在本地内存中,当配置入站方向的软重置后(输入命令clear ip bgp * soft 【in】),路由器不再向邻居发送更新请求,而是直接对在内存中存储的那些原始未经改变的BGP路由执行新配置的入站策略,以此来防止出发大批量的路由更新而造成资源的浪费,但这种操作仍然比较消耗内存,因此在性能不太好的设备上使用时要非常谨慎。
Dynamic Inbound Soft Reset
这种重置方式的中文叫‘动态入站软重置’,英文‘Route Refresh capability’说的也是它,在2000年发布的RFC2918中正式规定,思科从IOS 12.1开始全面支持入站路由的动态软重置,目前在用的几乎所有路由器都支持动态入站软重置。这种软重置的能力不需要进行任何的命令配置,在BGP邻居建立时会预先协商好,当输入命令clear ip bgp * soft 【in】【out】(没错,和前一种软重置触发的命令相同)时,路由器会自动向所有支持这个特性的邻居发送route-refresh报文,要求这些邻居重新发送它们的路由宣告。
如何知道邻居设备是否支持这种新的软重置呢?看show ip bgp neighbors X.X.X.X的显示中的‘Route refresh’后的部分,带new的就是支持不配置直接刷新的:

软重置总结
第一种软重置方式由于内存消耗过大已经被第二种方式替代,目前几乎所有在网运行BGP的路由器都支持第二种更新的方式进行软重置,无需配置任何命令,遇到软重置时提示让你配置‘soft-reconfiguration inbound’的,说明邻居只支持老的刷新方式,不过一般很难遇到了。所以如果你觉得看到两种软重置有点懵逼,忽略第一种直接看第二种就好。如果想进一步搞明白,推荐看帖子1、帖子2和帖子3,我上面的内容摘抄\翻译自这。
查看邻居支持的特性
使用命令‘show ip bgp neighbot x.x.x.x | section Neighbor capabilities’查看邻居X.X.X.X支持的BGP特性,例如:
1 | R2#show ip bgp neighbors 192.168.23.3 | section Neighbor capabilities |
BGP表含义
BGP表就是上面说的Loc-RIB(Local Routing Information Base),用命令‘show ip bgp’查看:
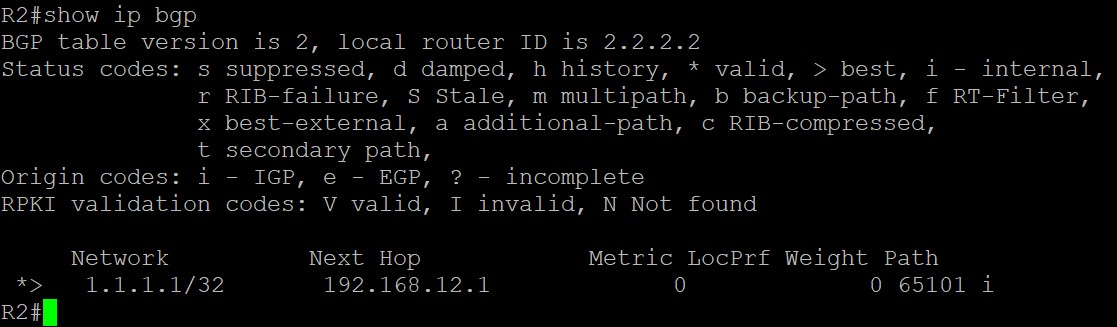
可以看到,R2的BGP表中有一条1.1.1.1/32的路由,前面的*和>是神么意思呢?
- *****表示这条路由是有效的,BGP可以使用它,只要路由器从其他BGP邻居收到一条路由就表示这条路由有效,和下一跳能否到达没有关系,一个帖子里关于valid是这么说的:The prefix is marked as valid if received from a peer or locally originated. The next hop reachability doesn’t affect this flag.那什么情况下,一条BGP路由无效呢?那个帖子里说:When a path is dampened among other conditions. In such a case, the prefix is not received anymore from the peer. It is kept for the sake of conserving the history information and is not marked as valid.大概意思是说,当一条路由在被阻断的情况下就无效了,比如这条路由不再从邻居那边收到,但为了保存历史信息,会被标记成无效留下来;
- >表示这条路由被选为BGP中的最优(但不代表着它一定是路由表中最优的):
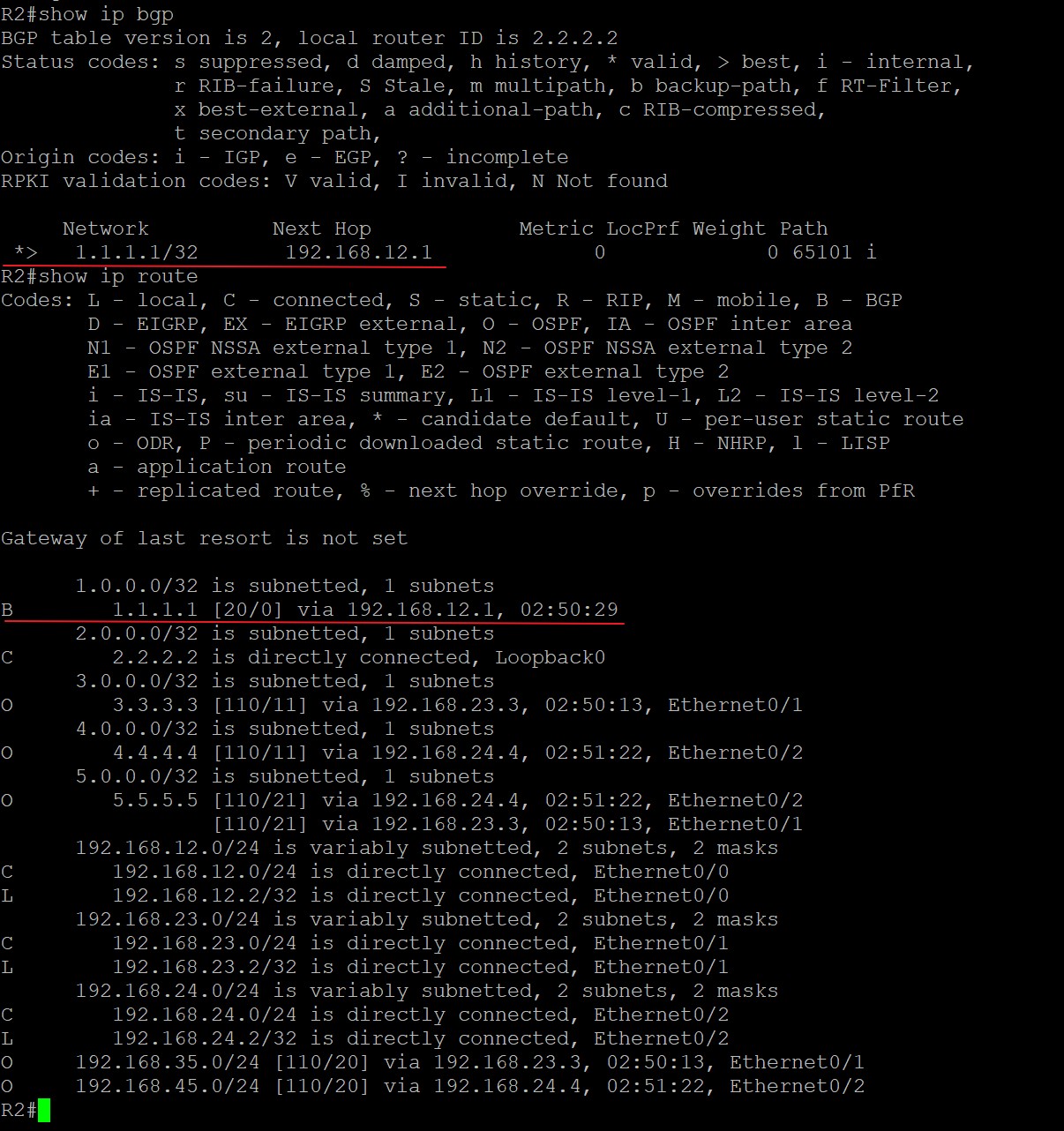
那么不是最优的BGP路由如何表示呢?前面没有>符号的就不是最优路由,例如下面:
Next Hop,表示去往目标网络下一跳发给谁,在最上面图中的next hop部分值为192.168.12.1,表示在R2上通过BGP去往1.1.1.1/32,需要把数据发给192.168.12.1即可。如果这部分值为0.0.0.0呢?表示该路由始发于本路由器,所以不需要发给别的地址,故该部分值为0.0.0.0;
后面几个值,Metric、LocPrf、Weight以及Path都是BGP的属性,用来选取最佳路径,会在后面具体解释;
最后面还有一个‘i’,这是BGP的origin code,就是路由更新的来源,一共有三种途径,其中‘i’表示通过BGP中的network命令注入到BGP中的,也就是起源于IGP,因为BGP通过的network命令宣告进入的必须在IGP的路由表中;其中‘e’是由EGP这种早期的协议重发布而来,该协议现网中已不再使用;其中‘?’表示从其他渠道学习到的,也就是该路由来源的信息不完全,重发布路由的origin都是这个标记;
BGP表中开头部分还有个‘BGP table version’表示BGP表的版本号,每当最佳路径产生变化时,BGP表的版本号会随之增加。
Status Codes中还有一些其他的代码:s是suppressed,翻译成中文是被抑制,表示BGP知道该路由前缀但不会对它进行通告,通常发生在该路由前缀是路由汇总中一部分的时候;d是damped,翻译成中文是衰减,表示BGP不会宣告这条路由前缀,因为该路由频繁翻滚(路由一会儿存在过一会儿又消失),标志为d的路由会被限制传播范围,这个特性有三个作用,一是减少路由器因为路由翻滚而带来的高负载,二是增加路由稳定,三是防止路由长时间的震荡。;h是history,翻译成中文是历史,表示BGP学到过这条路由但目前该路由不存在;r是RIB-failure,表示BGP学到过这条路由但并未将它加入路由表中,这种情况常见于有其他AD管理距离更低的路由协议也学到了该路由时;S是Stable,表示过期的路由,用于不间断转发,当远程BGP邻居返回时,必须刷新此条目。
关于思科的valid
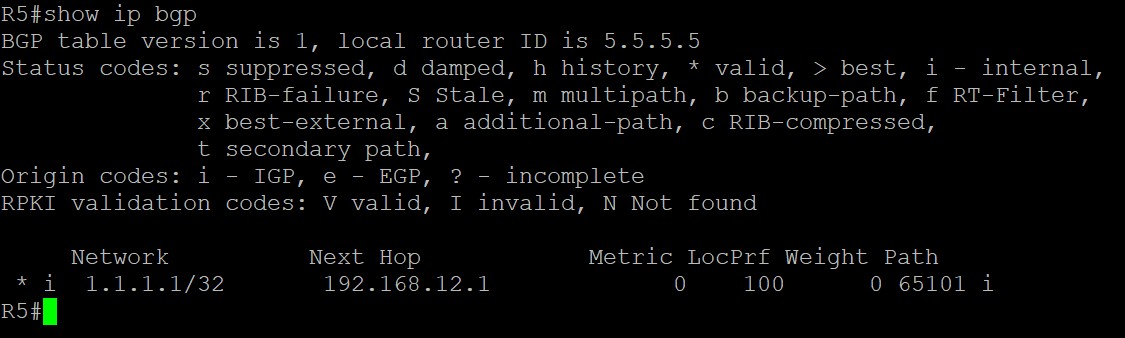
思科设备关于BGP路由的valid,也就是是否有效这个,它和华为或Juniper的做法都不一样,Juniper和华为是需要这条BGP路由下一跳可达才会标记valid,而思科的BGP路由下一跳即使不可达也不影响这条路由的valid(The prefix is marked as valid if received from a peer or locally originated. The next hop reachability doesn’t affect this flag.),比如下图中,3.3.3.0/24这条路由是valid,也就是有效的,但它的下一跳192.168.23.3在路由表中并不存在,这并不影响它是否是valid,每个厂家关于路由协议都有自己的理解,所以在不同厂家设备对接的时候一定要了解这些差异,具体出处在这个帖子:
关于思科的‘>-best’
BGP表中的Best表示这条路由是BGP表中的最优,而不代表它一定就是路由表中的最优。决定一条BGP路由是否是路由表中的最优有两个过程,第一个过程是BGP表维护过程,大概就是BGP表中去往同一目的地的候选路由进行比较,选出一条BGP表中的最优路由,这个过程比的是BGP的属性,比如AS_PATH或MED这种,如果在BGP的路由表中最优则会有>的标识,标识它是BGP表中的最优,如果去往目的地只有一条BGP路由,那么它不需要比较,直接就是BGP表中的最优;第二个过程是由路由表维护过程,BGP中带>符号最优的这条BGP路由和IGP路由进行比较,如果IGP路由协议中有和BGP路由去往同一个前缀的路由,则Best的BGP路由和IGP路由进行比较AD值,AD值越小的越优,AD值小的进入路由表;如果IGP路由协议中没有和BGP路由去往同一个前缀的路由,则BGP的Best路由直接进入路由表中。这部分笔记出自于这个帖子。
show ip bgp summary
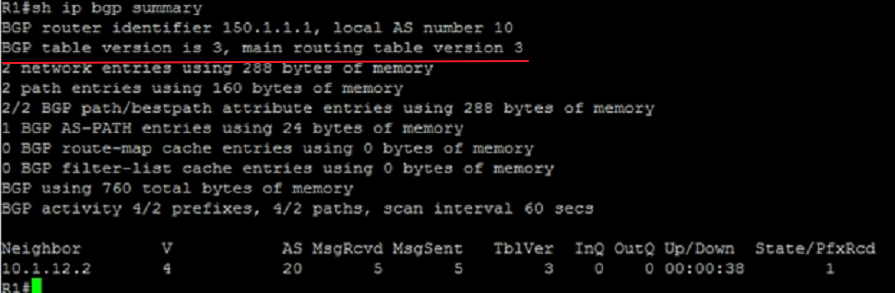
BGP table version,每当BGP表发生变化时,这个数字+1;
main table version,被注入到主路由表中的最后一个table version;
AS,邻居的AS号;
MsgRcvd:从邻居那里收到的消息数;
MsgSent:发送给该邻居的消息数;
TblVer:发送给该邻居的最后一个bgp table的version;
InQ:来自该邻居的等待处理的消息数;
OutQ:队列中等待被发送到该邻居的消息数;
State:BGP当前的会话状态,可能有Idle、Opensent等,如果状态为admin表示该邻居被管理型Shutdown,当处于establish状态时,不会显示状态提示,而显示一个表示PfxRcd的数字,也就是上图中所示的状态,表示从该邻居处收到的前缀条目,图中表示从邻居10.1.12.2收到了1个路由前缀。
BGP Policy Accounting
基本概念
BGP Policy Accounting能对BGP 邻居发送来的IP流量进行度量或流量统计。Policy accounting is enabled on an input interface, and counters based on parameters such as community list, autonomous system number, or autonomous system path are assigned to identify the IP traffic.
在R2上抓取R1发过来的去往30.30.30.0/24的流量
1 | ip prefix-list 30 permit 30.30.30.0/24 |
1、设定进行审计的条件:
1 | Device(config)# ip community-list community-list-number {permit | deny} community-number |
1、定义要统计的感兴趣流量,并设置流量索引,Communitu-list、AS_PATH或者 AS号等参数都可以用于抓取感兴趣流量
2、将IP流量归类,在BGP进程中使用route-map关键字关联上面定义好的route-map。BGP将基于route-map中定义的规则对路由表中的路由进行归类,其实就是把感兴趣流量归类到traffic-indexzh中
1、需要进行流量可以根据BGP的community或AS_Path属性进行分类。如果用community属性进行分类,则需要用ip community-list列表来抓取流量;如果用AS_Path属性进行分类,则需要用ip as-path access-list列表来抓取流量。
2、创建route-map来匹配之前配置的community-list或AS_Path list,并为收集到的流量信息设置存储桶的名称。
3、用route-map中的set traffic-index命令来规定如何将那些被route-map匹配的数据包进行分类
BGP路由重发布
BGP重发布到IGP
讲BGP路由重发布到IGP时,默认不重新发布IBGP路由,只重发布EBGP路由,在MPLS VPN环境的PE没有这个限制。如果想让IBGP路由也被重发布的话,需要使用命令‘bgp redistribute-internal’。
OSPF重发布进BGP
1 | router bgp X |
默认情况下,只会将OSPF中O以及OIA的路由重发布进BGP。
1 | redistribute ospf 1 external 1 external 2 |
只重发布OSPF的外部路由E1、E2进BGP
1 | redistribute ospf 1 external 1 |
只重发布OSPF的外部路由E1进BGP
1 | redistribute ospf 1 nssa-external 1 nssa-external 2 |
只重新发布OSPF的NSSA路由进BGP
其它常用命令
show ip bgp neighbors {address} received-routes
显示从指定邻居收到的所有BGP路由,也就是本地入站策略执行前的原始路由
show ip bgp neighbors {address} routes
显示从指定邻居那里收到的所有路由,是上一条命令的子集,这里显示的是执行入站策略后剩下的路由
show ip bgp neighbors {address} advertised-routes
显示通告给特定邻居的所有BGP路由
neighbor maximum-prefix XX
限制从邻居处接受的前缀的最大数,如果超出了这个数字,路由器就会关闭与该邻居的BGP连接,在应用clear ip bgp xxx之前都不会再次建立BGP会话
neighbor maximum-prefix XX restart 2
当从邻居处收到的前缀数量超过XX这个数字,断开与邻居的BGP连接,2分钟后才能重新连接
Neighbor maximum-prefix 300 90% warning-only
当从邻居处接受的前缀数量超过了最大数字,300,的90%时(默认值为75%),生成一条消息日志
BGP决策
决策过程总览
在一个既有IGP又有BGP的环境中,路由决策分为两个部分,一个是BGP表的决策过程,一个是路由表的决策过程。BGP表的决策过程大概就是BGP表中去往同一目的地如果有多条BGP路由,要选出一条最优路由,这个过程比的是BGP属性的优先程度,比如AS_PATH或MED这种,如果一条BGP路由在BGP路由表中最优则会有>的标识,标识它是BGP表中的最优,如果去往目的地只有一条BGP路由,那么它不需要比较,直接就是BGP表中的最优;第二个过程是由路由表决策过程,BGP中带>符号最优的这条BGP路由和IGP路由进行比较,如果IGP路由协议中有和BGP路由去往同一个前缀的路由,则Best的BGP路由和IGP路由进行比较AD值,AD值越小的越优,AD值小的进入路由表;如果IGP路由协议中没有和BGP路由去往同一个前缀的路由,则BGP的Best路由直接进入路由表中。这部分笔记出自于这个帖子。
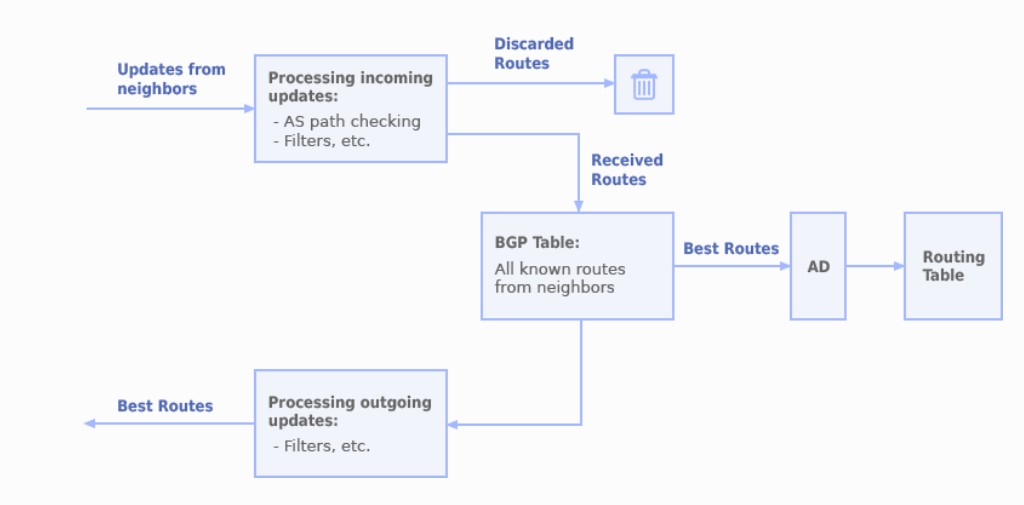
BGP路由信息库
BGP路由信息数据库,BGP Routing Information Base (RIB),包含三个部分:
ADJ-RIBS-IN:存储来自对等体邻居的、未经处理的消息,所包含的路由都是可用路由。说白了就是邻居发来的原始的路由信息是什么样的,原封不动的保存在Adj-RIBs-In中。通过命令 show ip bgp neighbor x.x.x.x received-routes查看Adj-RIBs-In。
Loc-RIB:存储着去往每个目标地址的最佳BGP路由。大体过程是,BGP路由器通过对ADJ-RIBS-IN中的路由使用它入向路由策略,那些符合入向策略的策略路由中,如果有多条路由去往同一目标地址的,则需要经过BGP的路由决策过程,从它们中选出最优(BEST)的放入Loc-RIB中并标记上>符号,如果去往该目标地址只有一条路由,则直接将路由放入Loc-RIB中并标记上>符号。
ADJ-RIBS-OUT:宣告给对等体邻居的路由,这些路由条目通过update报文发送给邻居,通告给邻居的是最优的路由。通过命令show ip bgp neighbor x.x.x.x advertise-routes来查看Adj-RIBs-Out。
可以说,BGP的RIB有以上这三个不同的数据库,或者说RIB是由以上三个部分构成的一个单独的数据库。
The BGP Routing Information Base (RIB) consists of three parts:
Adj-RIBs-In: Stores unprocessed routing information that has been learned from BGP Updates received from peers. The routes contained in Adj-RIBs-In are considered feasible routes.
Loc-RIB: Contains the routes that the BGP speaker has selected by applying the decision process to the routes contained in Adj-RIBs-In. These routes populate the routing table (RIB) along with routes discovered by other routing protocols.
Adj-RIBs-Out: Contains the routes that the BGP speaker advertises to its peers in BGP Updates. The outgoing routing policies determine what routes are placed in Adj-RIBs-Out.
These three parts of the RIB may be three distinct databases, or the RIB may be a single database with pointers to distinguish the three parts.
BGP决策过程
BGP表处理、决策过程
Phase 1 calculates the degree of preference for each feasible route in the Adj-RIBs-In. It is invoked whenever a router receives a BGP Update from a peer in a neighboring AS containing a new route, a changed route, or a withdrawn route. Each route is considered separately, and a nonnegative integer is derived that indicates the degree of preference for that route.
Phase 2 chooses the best route out of all the available routes to a particular destination and installs the route in the Loc-RIB. It is invoked only after phase 1 has been completed. Loops are also detected in Phase 2 by examining the AS_PATH. Any routes with the local AS number in the AS_PATH are dropped.
Phase 3 adds the appropriate routes to the Adj-RIBs-Out for advertisement to peers. It is invoked after the Loc-RIB has changed, and only after phase 2 has been completed. Route aggregation, if it is to be performed, happens during this phase.
从邻居处收到的所有BGP路由原封不动的保存到Adj-RIBs-In中,去往同一目的地可能存在多条BGP路由,所以从多条BGP路由中选出一条最优的BGP路由。
每当路由器收到由邻居AS对等体发来的BGP update(注意,update中可能有新路由,变更现有路由或撤销原有路由)报文后,就会计算所有Adj-RIBs-In中可用BGP路由的优先级,算出来的优先级是一个整数(非负数的),这个值代表着这条路由的优先程度,这个优先程度是BGP用来对每条路由进行排序的依据,列出哪条路由是最优,哪条路由是次优。
在计算完所有Adj-RIBs-In中路由的优先级后,在那些既符合入向策略且下一跳可达的路由中,选出一条BEST的路由(在BGP表中标记上>,表示它是BEST最优的),将这条最优路由放入Loc-RIB中。一条BGP路由的下一跳如果不可达,则它不能成为最优。如果去往目标地址有多条路由则用优先级选出一条最优的,如果去往该目的地址只有一条路由,则该路由即为最优BGP路由。这些被计算优先级的路由是Adj-RIBs-In中的所有未经本地策略改变的。本阶段除了选出最优的路由以外也会进行路由防环的检测,路由器会查看收到路由的AS_PATH,如果本路由器所处的AS号在新收到路由的AS_PATH中,则会丢弃该路由,因为有本AS的AS_PATH号意味着路由曾经到过本AS,为了防止环路必须丢弃该路由。
在完成了上一步骤后,将选出来的最优且无环的路由放入Adj-RIBs-Out中,宣告给对等体邻居。如果配置了路由汇总,也会在本阶段进行。
路由表决策过程
由BGP表决策过程选出来的BEST的BGP路由,将参与路由表的决策过程,如果有去往同一目的的IGP路由,则比较最优BGP路由和IGP路由的AD值,谁小谁加路由表;如果没有其他去往相同目的地的IGP路由,则BGP路由直接为最优。
属性优先级判定
总体规则
当到达同一个目标地址有多条BGP路由时,由BGP路由属性来判断优先选择哪条BGP路由,如果两条路由的某个属性能分出哪条更优先时,则停止比较,如果两条路由的一个属性相同无法比出结果,则比较下一个属性,例如路由A和路由B这两条路由去往同一个目的地,先比较Weight值,如果路由A的weight值更大,则路由A为最优,停止比较;如果路由A和B的Weight值相同无法比较出谁更优,则比较下一个属性值,Local Preference,以此类推,直到有一个属性能分出胜负后,停止比较。这个比较过程是在Adj-RIBs-In中做的。
那么这个属性优先级排定和之前说的每条路由计算出一个非负数的优先级有什么联系呢?这个帖子中是这么说的:‘The BGP decision process is an integral part of the process that assigns the degree of preference to each prefix for its ranking. It may help to think of it in this way: the process for degree of preference reads each entry of the Adj-RIBs-In and the process for degree of preference uses the BGP decision process on that prefix and uses the results of the BGP decision process to assign the ranking.’大概意思是说,这个属性优先级判定是前面提到的,给Adj-RIB-in中所有路由计算优先级的一部分,计算优先级的过程会读取Adj-RIBs-in中的每条路由信息并用属性优先级判定过程来决定一条路由的优先级程度,然后决定哪条BGP路由为最优。
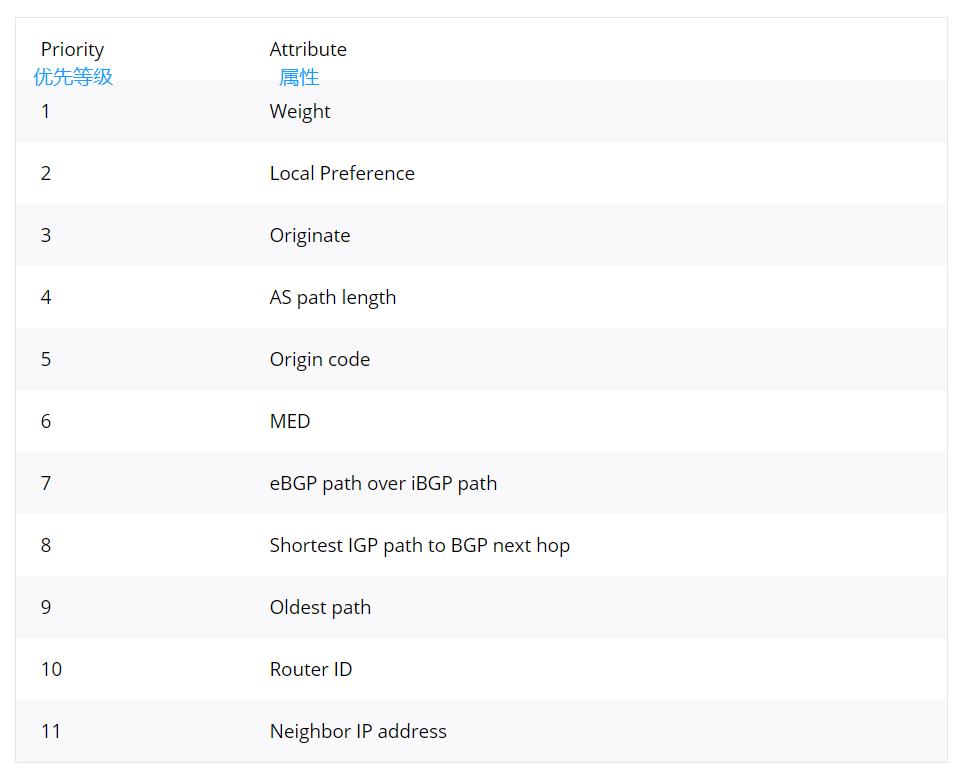
- Weight值是思科IOS专有属性,Weight值越大越优先,Weight值只在本路由器上有意义,在一个路由器上对Weight值进行更改,不会传递给其他路由器,不会影响其他路由器上的Weight值。
- 如果Weight值相等,那么LOCAL_PREF值大的路由更优先。
- 如果LOCAL_PREF值相等,那么优先选择起源于本地的路由(例如在本路由器使用network或aggregate命令宣告的),即下一跳是0.0.0.0的路由(在BGP表中,当前路由器宣告的BGP路由下一跳为0.0.0.0),优先顺序从高到低为:default-originate(针对每个邻居配置)、default-information-originate(针对每种地址簇配置)、network、redistribute、aggregate-address;
- 如果LOCAL_PREF相同并且没有起源于本路由器的路由,则比较AS_PATH长度,越短越优先。路由聚合时使用AS-SET后产生的AS_PATH列表中{}里的AS号长度只选一个AS号的长度,比如如果AS_PATH中有{100 300 500}则只算一个AS号的长度,如果AS_PATH中有{100 300 500} 400,则算两个AS号长度。在联邦内的AS_PATH列表中的()的AS号长度不做计算依据。如果配置了bgp bestpath as-path ignore这条命令,则跳过比较AS_PATH这步。
- 如果AS_PATH长度相同,则比较ORIGIN属性,IGP>EGP>Incomplete。
- 如果ORIGIN属性相同,则比较MED,越小越优先。一般情况下属性值比到这一步只可能是,需要比较的路由都来自同一个AS的不同EBGP邻居。可以配置bgp always-compare-med这条命令使得即使来源于不同的AS也进行MED比较。
- 如果MED也相同,则EBGP路由优于联邦EBGP路由,联邦EBGP路由优于IBGP路由。
- 如果上一步也依旧无法比较出是否优选,则优选到BGP NEXT_HOP更近的路由,该路由在AS内部是去往下一跳IGP度量值最小的路由。严格来说应该说,一台路由器从本AS的两个BGP邻居各收到一条路由,这两条BGP路由具有相同的路由前缀,首先这两条BGP路由的Next hop是不相同的才具有可比性,这时候比较本地到达这两个Next_hop的IGP的度量值,谁的Metric小,就优选谁。
- 如果有多条来自同一个相邻AS的路由并通过Maximum-paths命令激活了负载均衡属性,则将所有开销相同的路由加入Loc-RIB。
- 如果所有路由都来自EBGP邻居,则优选最先收到的EBGP邻居传来的路由,降低路由翻滚的影响。最老的EBGP邻居意味着可能是最稳定的BGP邻居,因此在这条规则中做了优选。这条比较规则主要针对EBGP路由起效,但现在基本不再使用,因为不确定性比较强。如果配置了‘bgp bestpath compare-routerid’命令后则跳过本原则。
- 如果没有激活负载均衡,优选Router ID最小的,在使用了路由反射器的情况下,优选ORIGINATOR_ID小的。
- 如果在使用了路由反射器的情况下ORIGINATOR_ID相同,则优选CLUSTER_LIST小的路由。
- 如果路由CLUSTER_LIST依旧相同,则优选IP地址小的邻居发送过来的路由。
weight越大越优
基本概念
weight属性为思科私有,作用范围是本路由器,该值既不会被包含在update报文中,也不会传递给任何BGP邻居,只在路由器本地产生影响,中文翻译为权重值,越大越优先。取值范围为0-65535。如果路由是从其他BGP邻居学过来的,则weight值为默认的0;如果路由是从本地network产生的,则weight值为32768;本地重发不的直连接口路由或静态路由的weight为32768;本地汇总产生的BGP路由weight值为32768。
如何操控
*方法1*
如果想对weight值进行更改,那么应该在本路由器上进行配置:
1 | neighbor {ip address|peer-group_name} weight XXXX |
例如,C从A和B都学到了1.1.1.0/24这条BGP路由,在不对weight值进行操控的情况下,这两条路由在C上的weight值都是0,因为该路由是从其他邻居那学过来的,weight值默认为0,此时我如果想让从B学到的路由更优选,则配置可以配置‘neighbor B weight 200’,那么从B获得的路由1.1.1.0/24的路由的weight值为200,为Best路由,被C优选:
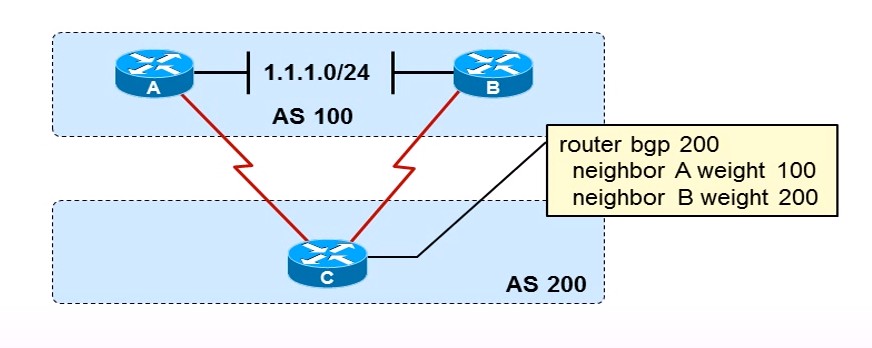
但按照上面的方式进行配置也有另一个问题就是,简单的将从B宣告过来的所有路由的weight值都设置成为了200,如果A和B也同时宣告过来一条2.2.2.0/24的路由,C想优选从A发过来的这条2.2.2.0/24路由按上面的配置则无法做到,此时需要用到下面这条命令:
1 | neighbor X.X.X.X filter-list 1 weight XXX |
这条命令是将邻居X.X.X.X发送过来的,且被Filter-list 1 匹配的条目的weight值设置为XXX。这条命令可以对同一个邻居使用多次,也就是对不同的路由设置不同的weight,但命令‘neighbor 1.1.1.1filter-list 1’在同一个邻居的in 或out方向,只能使用一次,这两条命令有很大区别。
*方法2*
使用route-map进行修改,达到去往100.0.1.0/24走左边的R3路由器,而去往100.0.2.0/24走右边的R5路由器。
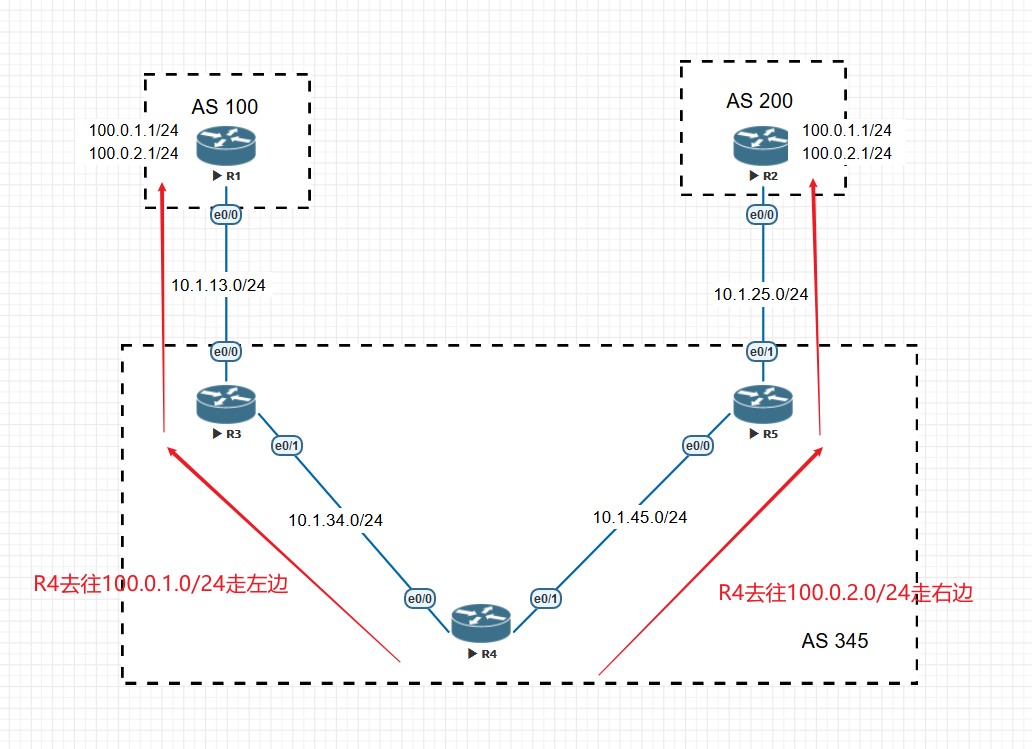
这时候我们可以将R3传来的100.0.1.0/24路由的weight值设置为10,将R4传来的100.0.2.0/24路由的weight值设置为10,这样就能达成要求:
1 | ip prefix-list 1 seq 5 permit 100.0.1.0/24 |
配置完以后,用show ip bgp 查看:
1 | R4(config)#do show ip bgp |
此时达成了题干要求,但这么配置是否是最优的呢?并不是,因为R3和R5都有去往1.0和2.0的路由,互为备份,如果按照上面的配置方式,一旦R3或R5某一方向的链路出现问题,假设这里是R1和R3之间的链路出现问题:
1 | R1(config-router)#neighbor 10.1.13.3 shutdown |
那么此时R4的路由表为:
1 | R4(config)#do show ip bgp |
也就是去往100.0.1.0/24的路由完全没有了,为什么会这样呢?是因为在R4上配置的route-map为:
1 | R4: |
route-map的结尾默认有一条deny any,没匹配上的路由就会被deny掉,route-map1中只匹配了100.0.1.0/24这条路由,所以虽然R3发送了两条BGP路由到R4,但R4上的入向策略将没被route-map 1匹配到的2.0/24路由给deny掉了,所以R4只从R3收到了route-map1匹配到的1.0/24这条路由。同理R4入向策略过滤掉的route-map2没匹配到的1.0路由,R4从R5上只收到了2.0/24这条路由,所以不管是R3方向或R5方向上的链路中断,则R4上没有备份路径。所以如果想要两个方向互为备份路径应该如何配置呢?需要对R4上配置的route-map进行更改:
1 | R4: |
配置完的新route-map对1.0/24和2.0/24都进行了匹配,R4可以从R3和R5上都收到两条BGP路由:
1 | R4(config-route-map)#do show ip bgp |
Local-Preference越大越优
基本概念
Local-Preference是公认自决属性,默认值为100,只用于iBGP邻居之间,决定离开AS的最优路径,一般用于控制本AS的出口设备。
- Local-Preference就是本地优先级,当一个AS收到一个去往同意目的地的,但经过两个AS的路由,在其他BGP路由属性完全一致的情况下,根据两条路由的local-preference决定,值越大越优,比如下图中的路由器D,从C和E两个路由器都收到了去往172.20.0.0的路由,但E发过来的路由属性中Local-Preference值大于C发过来的路由属性,所以去往E的路由更优:
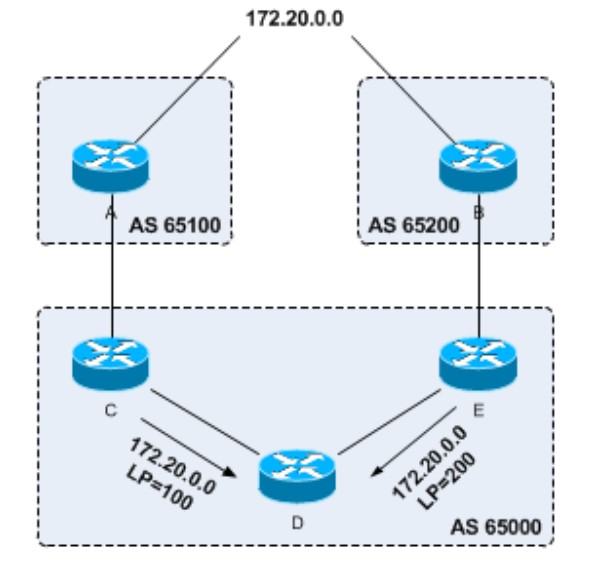
Local-Preference只能在AS内部的iBGP邻居之间传递,而不会传递给其他eBGP邻居,Local-Preference除非做了策略,否则在AS内的iBGP邻居之间传递时不会丢失,如果eBGP邻居之间收到的路由的路径属性中携带了Local-Preference的话,会触发notification报文造成BGP会话中断,但可以在AS边界路由器上使用IN方向策略;
Local-Preference在向eBGP邻居发送路由更新时,不能携带LP属性,对方收到该eBGP路由的LP值为空,也就是说路径属性中根本没有LP这个字段,但它会在本地为这条路由赋一个默认值,也就是100,然后再传递给自己的iBGP邻居;
本地network命令及重发布命令发布的路由,LP值默认为100,并能在AS内向其他iBGP邻居传输,传输过程中除非部署了策略,否则LP值不会发生变化;
修改默认LP值的命令为:bgp default local-preference XXX。
如何操控
使用route-map来修改本地优先级,实验拓扑如下,使用LP来操控路由,使得R4去往100.0.1.0/24走R3方向且LP=200,去往100.0.2.0/24走R5方向且LP=200。
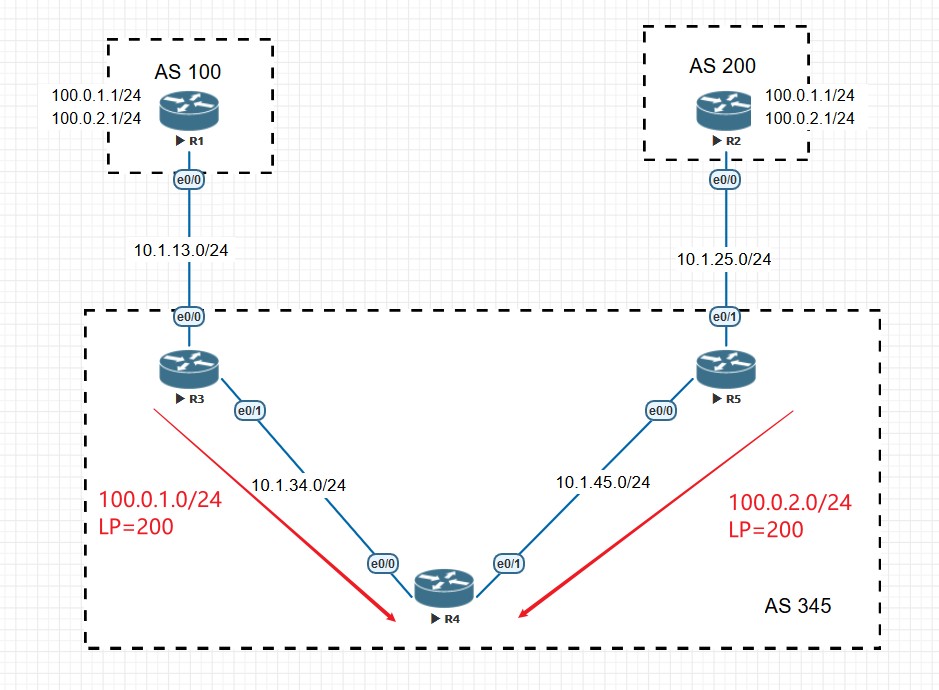
由于LP在IBGP邻居之间可以传递,所以这里既可以在R4的In方向上使用route-map来操控LP,也可以在R3和R5上对R4的OUT方向使用route-map来操控。
*方式1:*
先看在R4的In方向上使用route-map:
1 | R4: |
route-map LP1和LP2后面之所以写了两个空的permit 20,是因为route-map最后都默认有一个deny any,如果不写空的permit 20,则其他路由会被deny掉,无法传到R4上,也就没法达到备份路径的效果。R3从R1(R5从R2)获取的eBGP路由中的LP值为空,到了R3\R5后被赋予了默认值100,这个值不被route-map改变的话,传到邻居R4后还是默认值100。
配置完结果如下:
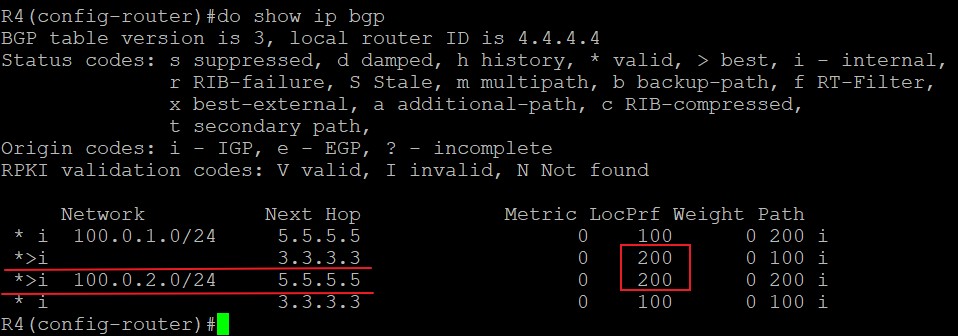
为什么会这样选择最优路由呢?因为weight值相同,不起源于本地的路由默认weight值都是0,所以比较LP值,而LP值不相同,拥有200LP值的路径被优选,因为LP值越大越优先。
*方法2:*
在R3和R5上分别对out方向的R4使用route-map来操控LP,因为R4和R3\R5都为ibgp邻居关系,而LP在IBGP邻居之间是可以传递的。配置如下:
1 | R3: |
配置后结果如下:
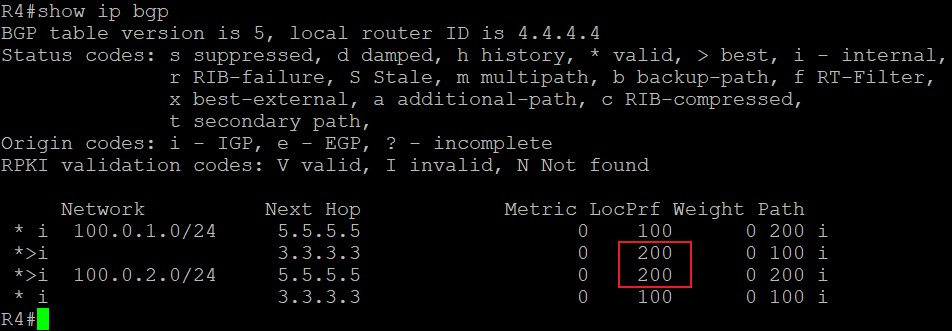
优选本地起源路由
基本概念
优选起源于本地的路由,也就是那些在本路由器上network、aggregate或redistribute的,也就是下一跳是0.0.0.0的路由,因为在BGP表中,起源于当前路由器的路由,下一跳为0.0.0.0。
实验验证
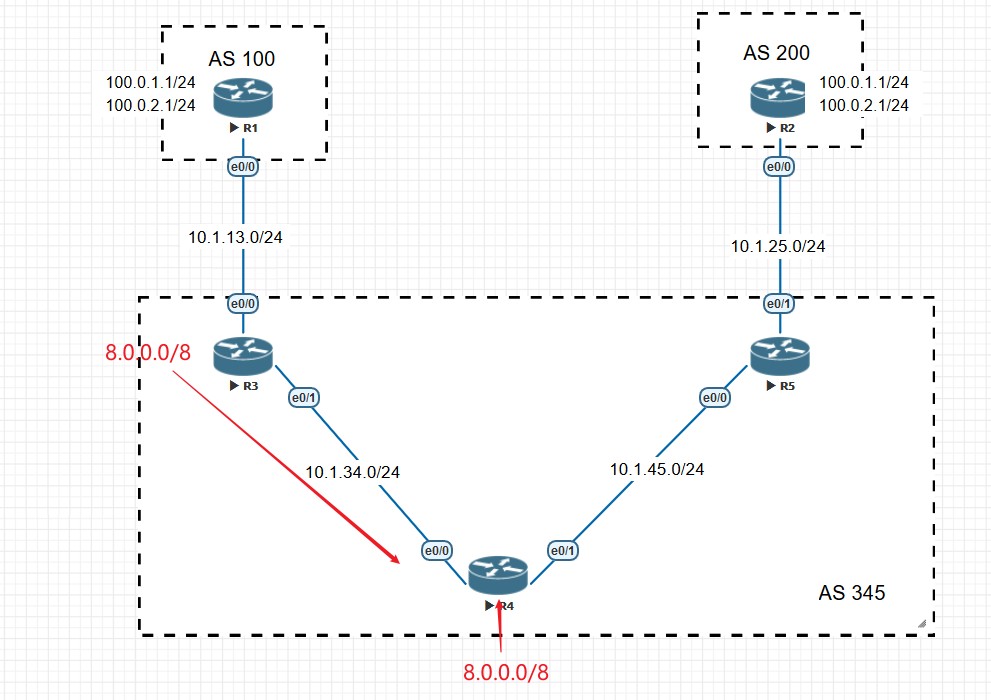
R3上宣告一条8.0.0.0/8的BGP路由,R4上network一条同样的8.0.0.0/8的路由,来验证起源于本地的路由是否被优选。
1 | R3: |
但此时必须注意,虽然R4上优选了起源于本地的路由,但要知道,这两条路由不是上来就用‘优选起源于本地的路由’这条规则来比较,而是先要比Weight值,然后比较Local-Preference,比较完前两个才使用‘优选起源于本地的路由’这条规则来比较。这里也按照这个顺序进行比较,先看Weight值,由于起源于本地路由默认的weight值为32768,所以在第一部比较出来了就不会再用其他规则进行比较,这里用route-map将weight值改成一样的来验证。
1 | R4: |
如此配置以后,再查看R4的BGP表发现,此时R4上8.0.0.0的Weight值为0:
1 | R4(config-router)#do show ip bgp |
这时R4优选了本地起源的路由,因为首先比较的Weight值相同,接下来比较的Local-Preference值也相同,都为默认的100,起源于本地这条LP也是100具体见下图,接下来是起源于本地的路由更优,所以选择了本地那条下一跳为0.0.0.0的路由。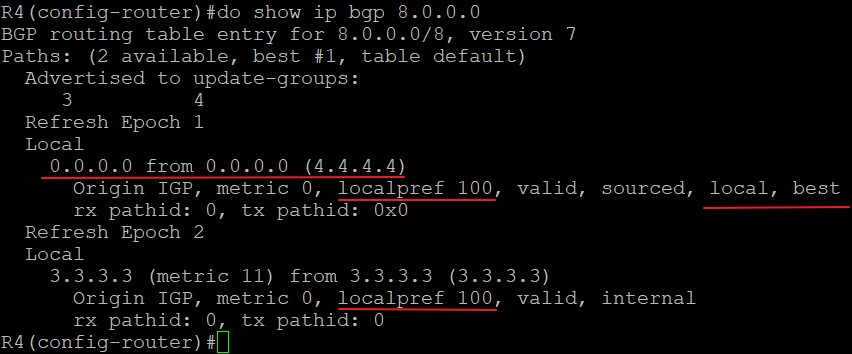
AS_PATH越短越优
基本概念
AS_PATH是公认必遵属性,描述到达目标网络所要经过的AS号序列,最重要的作用是防环。当且仅当update报文被发送给其他的AS(也就是EBGP peer)时,BGP路由器才会将其AS号追加在AS_PATH中。也就是如果要修改AS_PATH属性,则必须在AS边界路由器上执行,对IBGP邻居去执行修改AS_PATH的策略是无效的。
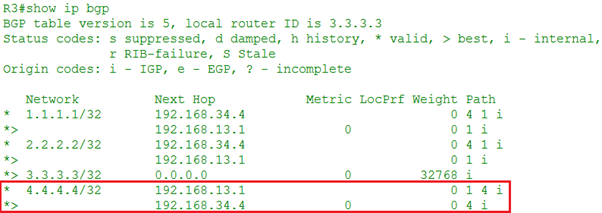
例如在上面的BGP表中,去往4.4.4.4/32的路由有两条,要对这两条路由进行比较,看谁更优先,首先看这两条路由的weight值,都为0,所以比较下一个属性,local-preference,虽然BGP表中为空,但两者在本地都被赋予了默认值100,所以继续比较下一项,看两者谁是起源于本地的,由于两条路由的Nexthop都不为0.0.0.0,意味着两条路由都不起源于本地,所以继续比较下一项AS_PATH,越短越优,下一跳为192.168.34.4的这条路由只经过了一个AS(AS4),短于经过了两个AS(AS4-AS1)的下一跳为192.168.13.1的路由,所以AS_PATH短的被优选。
如果做了聚合路由时,使用AS-SET关键字后产生的AS_PATH列表中的{},无论里边有几个号码,只算做一个AS号的长度,比如如果800 {200 100}只算两个AS号的长度,{200 100 300 400}也只算一个AS号的长度。
如果做了联邦,则联邦AS的AS号不算做长度计算的依据,也就是如果AS_PATH为(65412 65413)100,只算一个AS号的长度。
实验验证
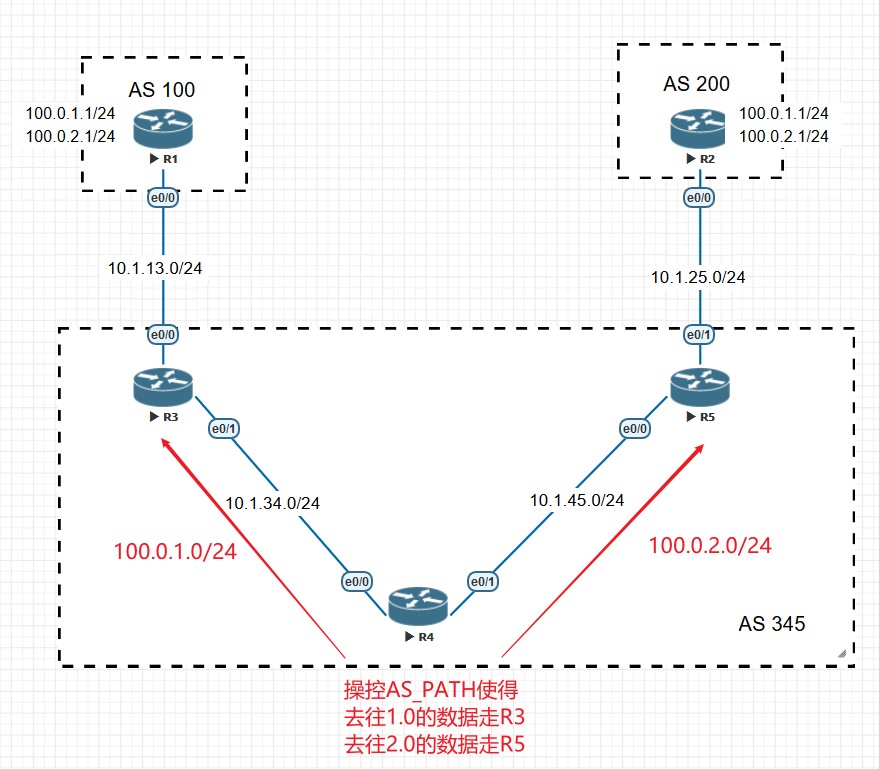
由于AS_PATH只在update报文发送给其他AS时才发生变化,这意味着修改操控它必须在AS边界路由器上执行策略,所以既可以在R1\R2的out方向上对AS345的EBGP邻居修改,也可以在R3和R5的In方向上进行修改。
*方法1:*
方法1采用在R1\R2的out方向上做策略:
1 | R1: |
此时R4上BGP表如下:
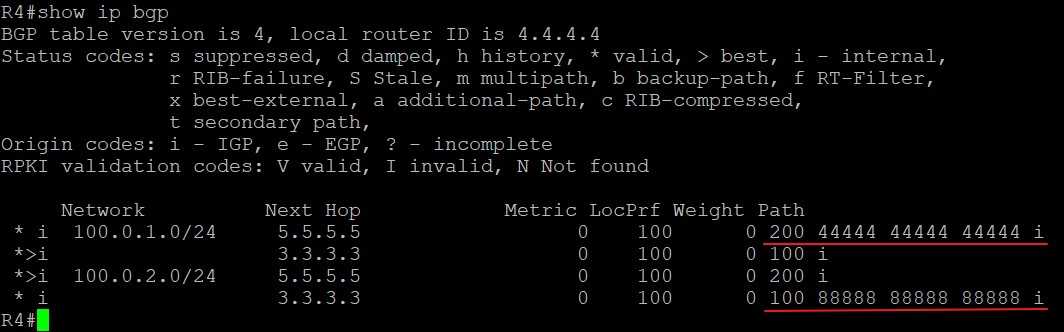
由于从R3和R4都收到了去往100.0.1.0/24和100.0.2.0/24的路由,这时需要选择最优路由,先看Weight值越大越优,由于所有路由都不是本地起源所以都为默认值0,所以比较下一个属性,Local-Preference越大越优,由于LP不会通过EBGP邻居传递,所以两条起源于外AS的路由在本AS内的LP为空,本AS路由器会赋予相同的默认值100,所以比较下一个属性,优选起源于本AS的路由,由于路由都不起源于本AS,Nexthop不为0.0.0.0,所以比较下一个,AS_PATH小的优选。这时划红线的两条路由的AS_PATH较长所以不被选择,路由器会选择AS_PATH较短的两条路由。
*方法2:*
从R3和R5上配置in方向的route-map对AS_PATH进行操控。
1 | R3: |
*方法1对比方法2:*
两种办法都能达到操控路由的目的,最显著的区别在于AS_PATH在R4上的表现,在R1上操控AS_PATH然后对out方向EBGP邻居使用route-map的话,AS_PATH是‘100 88888 88888 88888 i’,而在R3的in方向对邻居使用route-map的话,AS_PATH是‘88888 88888 88888 100 i’。之所以结果不同是因为route-map是在Adj-RIBs-IN上使用的,而传给邻居的BGP路由是Adj-RIBs-Out中的,out中的路由传递给eBGP邻居之前加上本AS的号码。
在R1上操控AS_PATH然后对out方向EBGP邻居使用route-map,route-map的操控结果在Adj-RIBs-IN上已经发挥作用,route-map生效后路由变成了‘88888 88888 88888 i’,i是表示该路由通过network注入的本AS,接下来通过route-map添加的AS号88888在左边,因为AS_PATH中越靠右表示更先经历该AS,靠左边表示晚一些经过该AS。由于去往该目标地址只有这一条路由,该路由为最优,所以带有‘88888 88888 88888 i’AS_PATH的路由进入了Loc-RIB和Adj-RIBs-Out中,接下来要将该路由发送给EBGP邻居,所以要在AS_PATH中靠左的位置加上本AS的号码,最后AS_PATH为‘100 88888 88888 88888 i’。
在R3上操控AS_PATH然后对EBGP邻居in方向使用route-map,route-map的操控结果在Adj-RIBs-IN上发挥作用,Adj-RIBs-IN中存储的是邻居发送过来的无更改的路由,这时R1发过来的路由在AS_PATH中已经加上了AS100的号码,也就是‘100 i’然后route-map对AS_PATH进行操控,加上了88888这个AS号码,后加入的AS号要在靠左的地方,所以最后AS_PATH为‘88888 88888 88888 100 i’。
比较Origin Code
基本概念
Origin code的优先排序为:I(IGP)>E(EGP)>?(Incomplete),由于EGP协议已经不再使用,所以可以简单的将该规则记为IGP>Incomplete,IGP表示路由起源于IGP,由network命令引入BGP。?表示是从其他渠道学习到的,该路由来源的信息不完全,一般是由重发布引入的。可以在show ip bgp中的path最右边看到origin code。一般不建议使用origin code对BGP选路进行操控。
实验验证
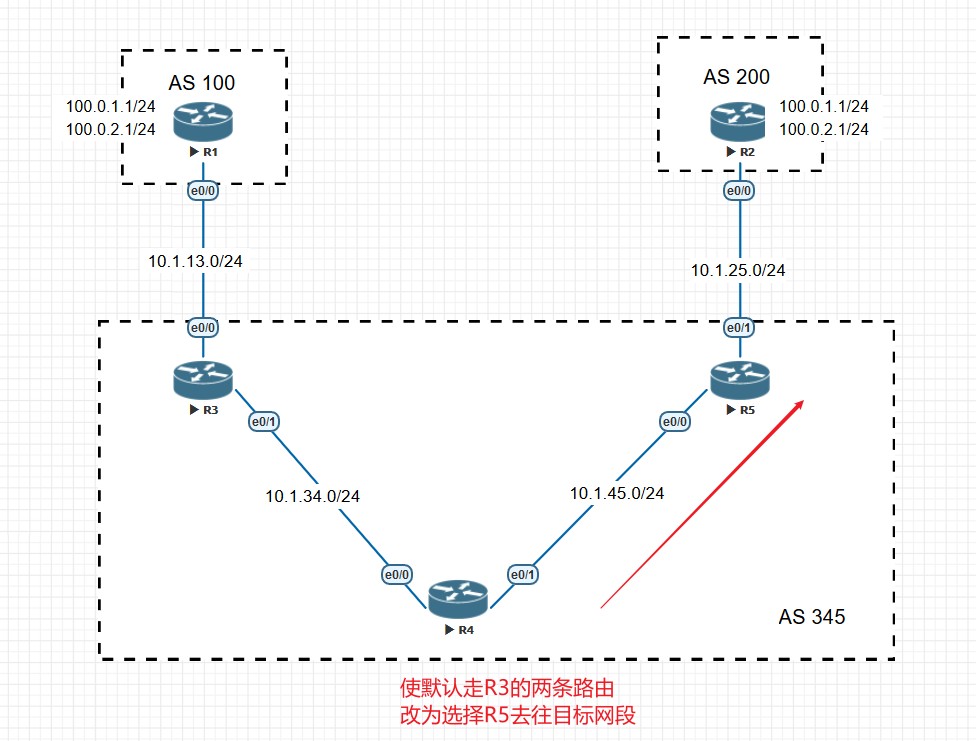
在不进行任何配置的情况下,R4上去往100.0.1.0/24及100.0.2.0/24会通过R3走,本实验通过操控origincode使得两条路由改走R5方向去往目标网段。可以在R1上不使用network的方式发布两条路由而改为使用重发布方式将两条路由引入BGP,也可以在R1上使用route-map的方式进行操控,还可以在R3的out方向用route-map操控,抑或可以在R4的in方向上进行修改。
方法1:
首先使用在R1上network时修改origin的方式,在R1上配置:
1 | route-map ORIGIN permit 10 |
配置完R4的路由表为:
1 | R4#show ip bgp |
此时要选出最优路由依旧得从头开始比较,Weight值的话,两者相同都是0,因为都不是首发于本地的路由,默认weight值为0;Local-Preference比较,由于路由宣告自其它AS,LP不在EBGP邻居之间传递,所以用默认值100;两条路由都不是起源于本地,nexthop都不是0.0.0.0;AS_PATH比较,两边的AS_PATH长度值都是2;比较origin code,I>?,所以优选走R5方向。
方法2:
在R3上对R4的out方向使用route-map更改origin code从而达到在R4上优选R5路径的目的。
1 | ip prefix-list ORIGIN seq 5 permit 100.0.1.0/24 |
此时要选出最优路由依旧得从头开始比较,Weight值的话,两者相同都是0,因为都不是首发于本地的路由,默认weight值为0;Local-Preference比较,由于路由宣告自其它AS,LP不在EBGP邻居之间传递,所以用默认值100;两条路由都不是起源于本地,nexthop都不是0.0.0.0;AS_PATH比较,两边的AS_PATH长度值都是2;比较origin code,I>?,所以优选走R5方向。
MED越小越优
基本概念
MED为可选非传递属性,一般用于AS之间的BGP选路,用来影响进入本AS的流量。默认情况下,要比较MED值仅在所有备选路由来自同一AS才会比较MED,也就是说同一个目的地的两条路由来自不同AS时,不进行MED值的比较。MED只在直接相连的AS间影响业务,只在AS内传递MED值,不会跨AS传递,思科设备MED值默认为0。
MED设置方法:
将IGP路由引入BGP时关联route-map进行设置;
对BGP peer应用IN/OUT方向的route-map进行设置;
非route-map方式:1、使用network或redistribute方式将IGP路由引入BGP时,MED将继承IGP路由的Metric(直连路由及静态路由的Metric为0);2、使用aggregate-address方式引入路由,则MED为空。
实验验证
通过更改MED值,使得原来优选R3方向的路由优选走R5方向。
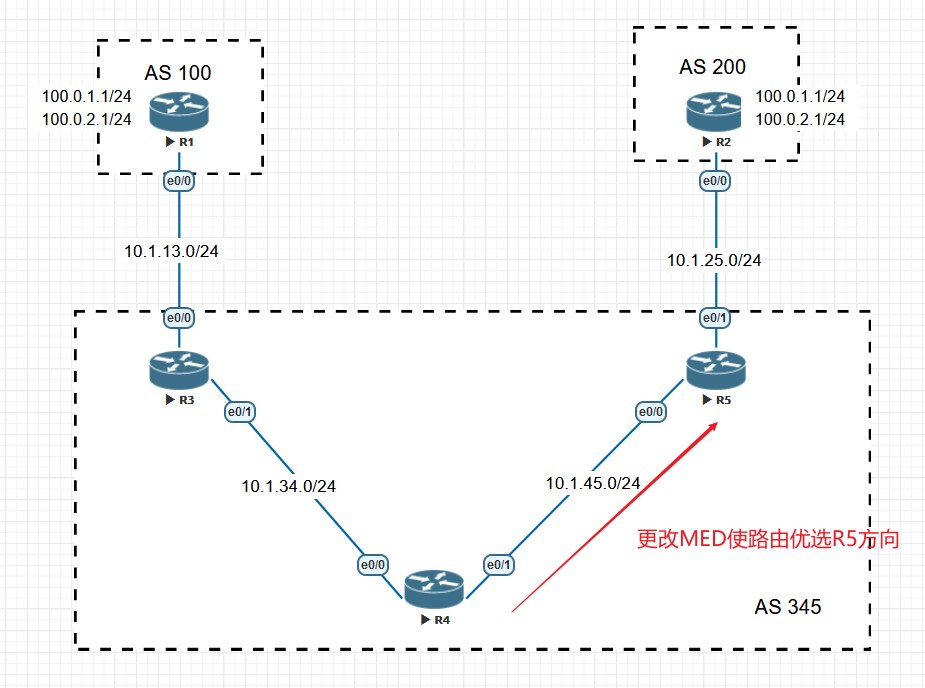
在R4上进行配置:
1 | R4: |
可以看到配置已经生效,在Weight值相同,Local-Preference相同,都不是起源于本地的路由,AS_PATH长度相同,Origin Code相同的情况下,比较MED时,路由并没有优选MED更小的R5方向,这是为什么呢?因为默认情况下,来源于不同AS_PATH路由不比较MED值,具体来说就是来源于R3方向的路由AS_PATH中显示它是来自AS100,来源于R5方向的路由AS_PATH中显示它来自AS200,这种情况下是不比较MED的:

如果想用MED来为两条路由分出优先与否,则需要配置上‘bgp always-compare-med’这条命令。
1 | R4(config)#router bgp 345 |
配置完命令后,来自不同AS的路由也开始比较MED值,越小越优,所以路由会优选R5方向。
优选EBGP邻居的路由
基本概念
优选EBGP邻居发来的路由(相比较IBGP邻居学过来的),在联邦EBGP和IBGP中优选联邦EBGP邻居。
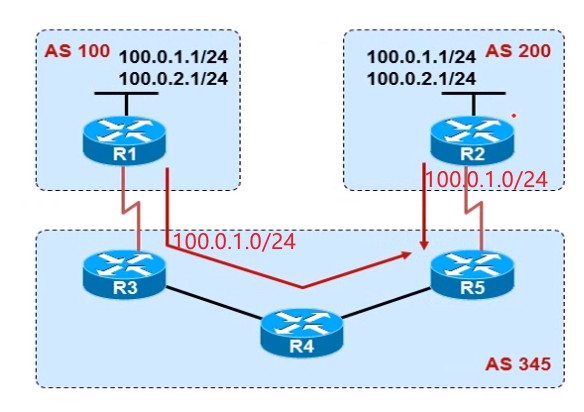
例如上图中,R5同时从R4及R2收到关于100.0.1.0/24的路由,在前几个比较条件都无法分出谁优选的情况下(Weight值相同,LP值相同,都不是起源于本地的路由,AS_PATH长度都为1,Origin Code都是i,MED值都为0),会优选来自R2的路由,因为R5和R2之间是EBGP邻居,优先于R5和R4的IBGP邻居发来的路由。
实验验证
由于水平分割原则的存在,R4无法将从ibgp邻居R3处学到的路由发送给另一个ibgp邻居R5,为了打破水平分割原则,这里将R4配置成路由反射器,使R3的路由能够发送给R5:
1 | R4: |
这时R5已经从R4处学到了100.0.1.0/24,这时Weight值相同都为0,Local-Preference也相同为0,路由都不起源于本地,AS_PATH长度相同都为1,Origin Code都为 i 也相同,MED值都为0,接下来由于R2方向学到的路由为EBGP路由所以优选这条。
优选到NEXTHOP最近的
基本概念
当路由器从两个BGP邻居各收到一条路由,这两条BGP路由有相同的路由前缀,首先这两条BGP路由的NEXT_HOP必须是不相同的,否则不具有可比性,这时候会比较到达这两个NEXT_HOP的IGP度量值,谁的Metric小,就选谁。
比如R4从R3和R5都收到了关于100.0.1.0/24的路由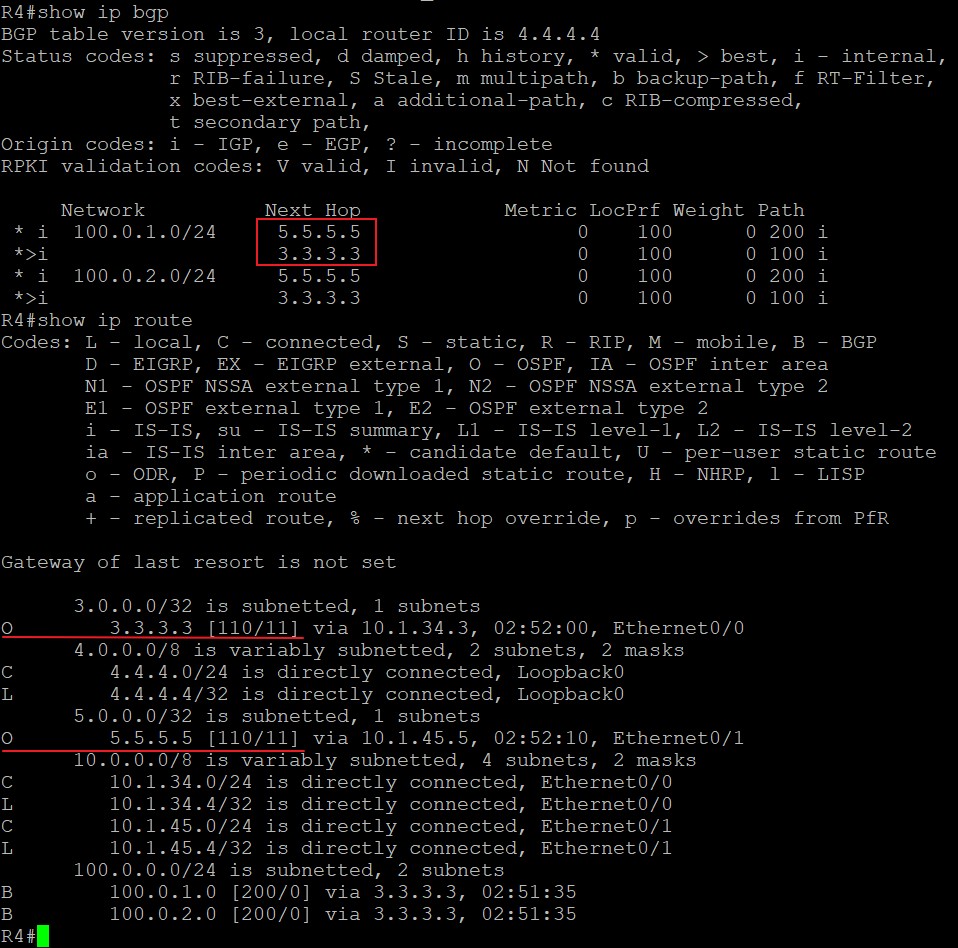 :
:
两条路由一条NEXTHOP是3.3.3.3,一条是5.5.5.5,R4会比较到这两个NEXTHOP的IGP路由的metric值,越小越优,在上图中到两个NEXTHOP的metric相同,都是11。

实验验证1
用上面的拓扑,操控NEXTHOP的metric值,使得R4用该规则优选R5方向的路由,由于要操控的是IGP的metric值,所以可以将R4连接R3接口的COST值调大,那么R4到达NH 3.3.3.3的metric值就变大了,R4就会优选R5这条BGP路径因为到达NH 5.5.5.5的metric值较小。

在对配置改动之前,e0/0接口的cost值是10。
1 | R4(config)#int e0/0 |
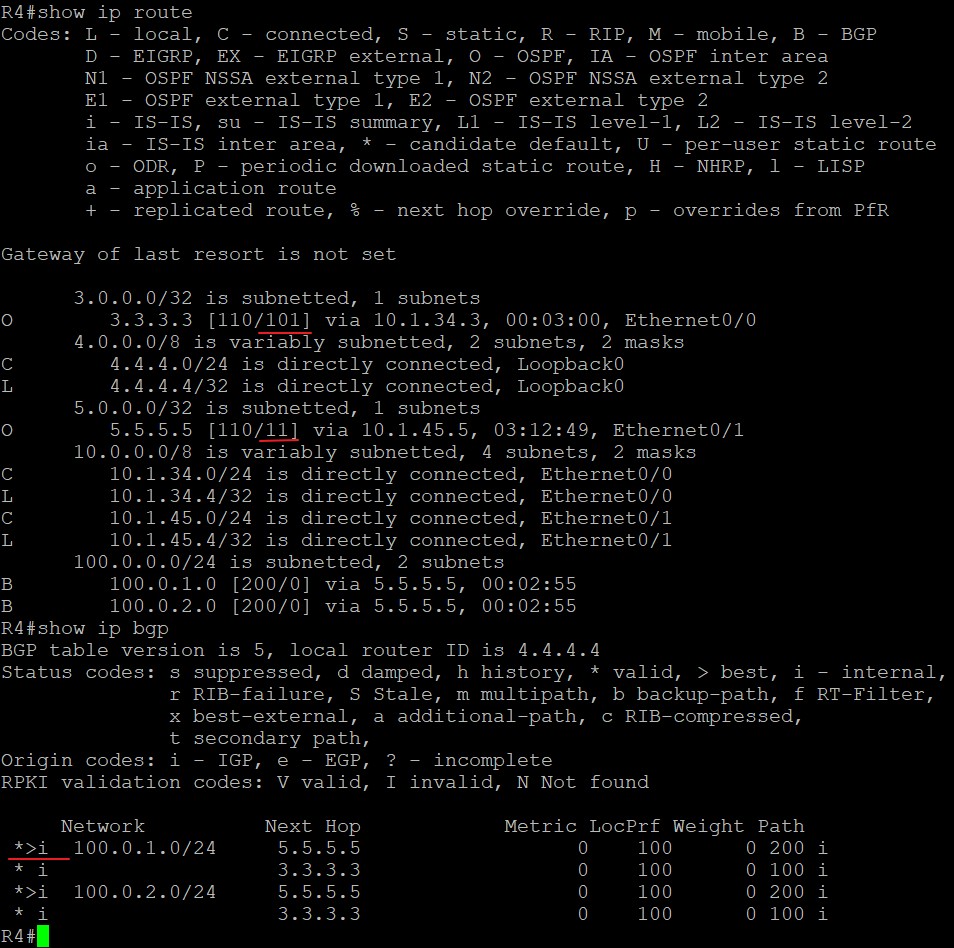
改完COST值后,还是得从第一条BGP比较规则一条一条往下看,Weight值相同为默认的0,Local-Preference相同为默认的100,两条路由都不起源于本地,AS_PATH长度相同都为2,Origin Code相同为i,MED相同为0,路由属性相同都是ibgp邻居出来的路由,现在比较到Next Hop的IGP的Metric值,到3.3.3.3的metric值为101,到5.5.5.5的metric值为11,优选到Next Hop的metric值小的5.5.5.5。
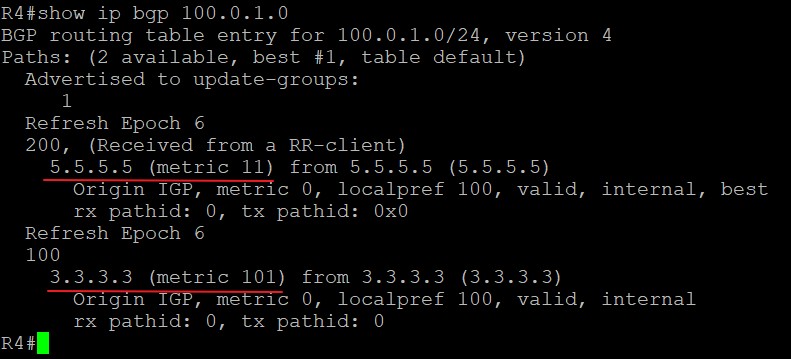
用show ip bgp 100.0.1.0来查看metric更为直观一些。
实验验证2
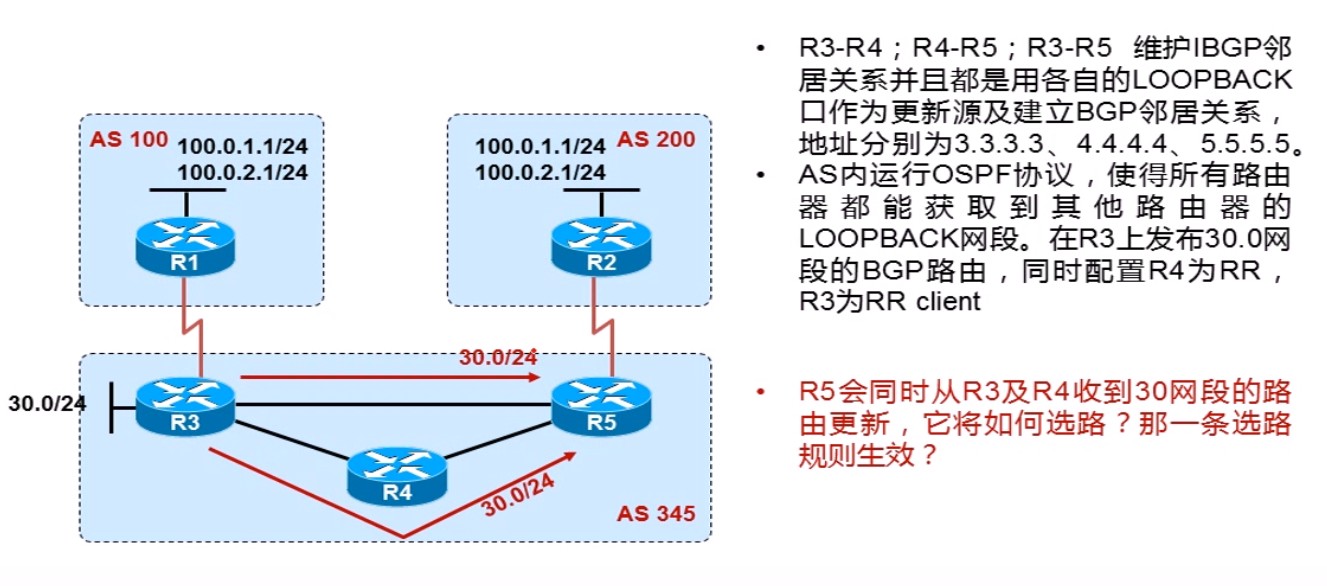
1 | R5: |
这时R5会从第一条规则开始比较,Weight值相等都为默认的0,Local-Preference相等都为默认的100,都不是起源于本地的路由因为nexthop不为0.0.0.0,AS_PATH长度相同,Origin Code相同都为i,MED相同都为0,都是IBGP邻居发来的路由,貌似优选到NextHOP最近的这条能逼出来,因为一个感觉上路由一个从R3直接发过来,另一个经由R4反射过来,实际上是这样吗?来看R5的路由:
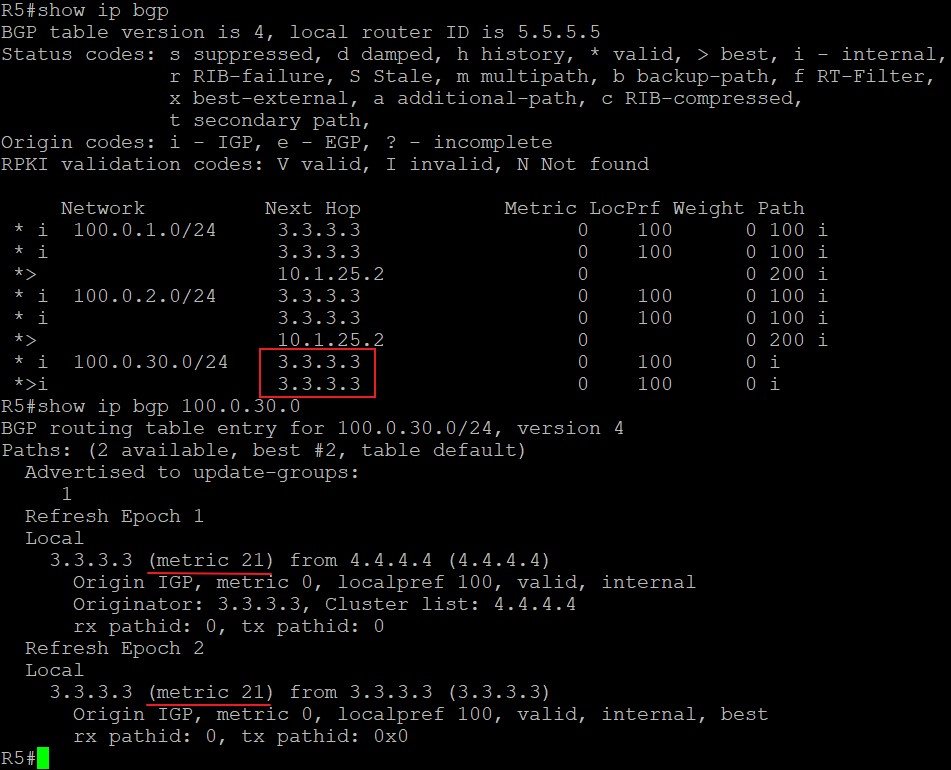
为什么两条路由的下一跳都是3.3.3.3呢?
先看R3发过来这条。因为R3和R5是ibgp邻居关系,配置了next-hop-self,如果不配置的话下一跳是10.1.13.1,R5上没有这个地址,下一跳不可达没有资格选为最优,必须配置next-hop-self。从R3发过来的这条BGP路由的IGP的metric为21。
然后看R4反射过来的这条。由于R4是路由反射器,在反射的时候不改变下一跳,R3和R4使用loopback建立邻居,所以下一跳也是3.3.3.3。
两条路由Next hop相同,所以相对应的IGP的Metric也相同。这条依旧比不出来,真正发挥作用的是后面的‘如果多条路径始发路由器ID或路由器ID相同,那么优选Cluster-Iist最短的路径’。
BGP负载均衡
基本概念
当前面的8条选路原则都无法优选出最优路由时,并且在BGP进程下面配置了负载均衡的命令:‘Maximum-path【ibgp】n’(n的取值范围为2-6,如果不关联ibgp关键字,则只会对External路由执行等价负载均衡,也就是只对EBGP路由负载均衡。如果要对internal路由做负载均衡,则需关联ibgp关键字。)那么将执行等价负载均衡,也就是将这些等价的路径都放入IP路由表使用,但是要注意,虽然这些路径在本地都用了,但最终只有一条BGP路径是BEST最优的。
具备等价负载均衡条件的候选路径需满足如下条件:
- 必须有相同的路径属性,如Weight、LP、AS_PATH(不仅是长度,整个AS_PATH包括所经过的AS号都要相同)、Origin Code、MED及IGP的Distance值;
- 每一条路径的下一跳都不相同。
如果路由器没有配置maximum-paths,那么将进行到下一条选路原则进行比较。
IBGP负载均衡实验
将之前的拓扑进行一部分更改来看负载均衡。
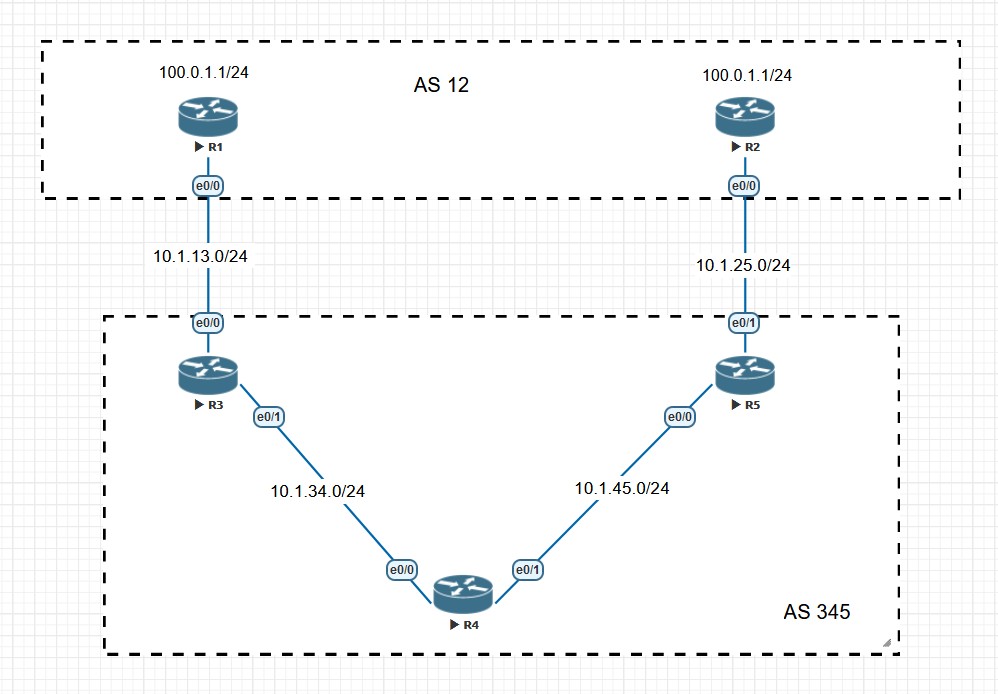
配置等价负载均衡之前,R4关于100.0.1.0/24的路由如下:
1 | R4#show ip bgp 100.0.1.0/24 |
可以看到R4从R3和R5分别收到一条去往该网段的路由,这两条路由具有相同的路径属性,Weight值为0、LP为100、AS_PATH都是AS12长度为1、Origin Code为i、MED为0,到达下一跳IGP路由的Distance值也相同,所以此时可以配置等价负载均衡。
1 | R4(config)#router bgp 345 |
这里为什么要配置成‘maximum-paths ibgp 2’呢?因为R4这两条路由都是由IBGP邻居宣告而来,如果不配置关键字‘ibgp’的话,只会对EBGP路由生效。配置过后效果如下:
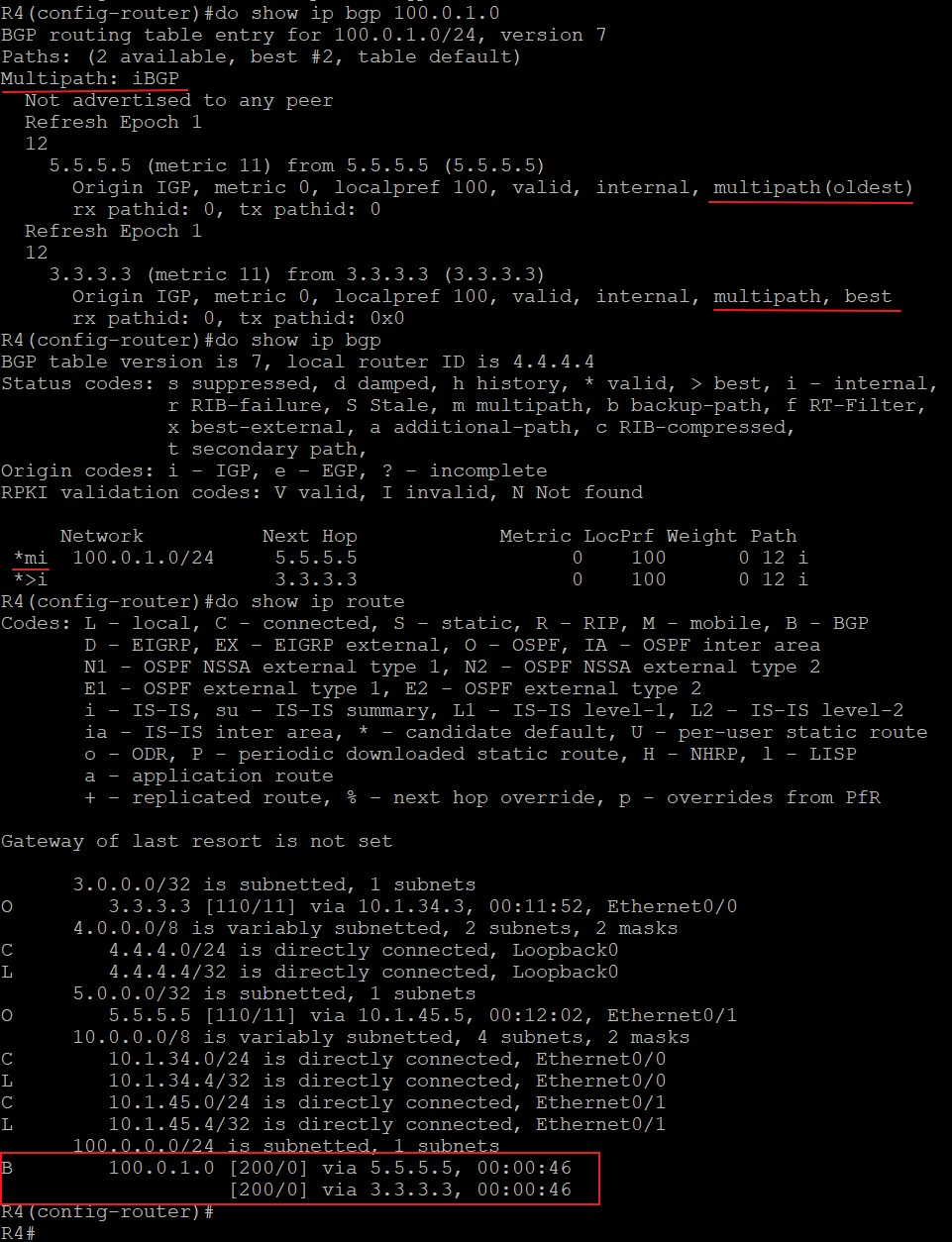
从BGP表中也能看出来,虽然是等价负载均衡,但只有一条路由有Best的标志,也就是说R4只会将这条Best的路由更新给邻居,而不会讲两条负载均衡的路由同时告诉邻居。
查看100.0.1.0这条路由具体信息可知,这两条路由之间的流量比是1:1。
EBGP等价负载均衡
优选最老的EBGP邻居传来的路由
这条选路规则主要针对EBGP路由起效,但现在基本不用这条来操控路由,因为不确定性太大。最老的EBGP邻居意味着可能是最稳定的BGP邻居,所以在这里做了优选。如果配置了‘bgp bestpath compare-routerid’命令后,将跳过该规则,如果多条路径具有相同的router ID也会跳过本规则,因为这意味着这些路由都是由同一台路由器发过来的。下图中的‘Up/Down’部分显示的就是BGP邻居建立的具体时间。
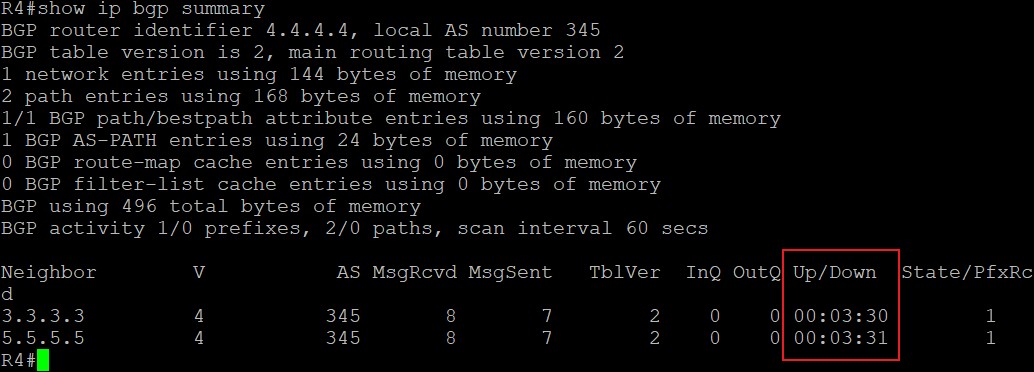
优选RID最小的BGP邻居的路由
基本概念
RID是路由器上的最大IP地址,一般配置成环回地址,也可以通过bgp router-id命令手工设置。如果一条路径包含RR属性,路由产生者ID(Originator)将在最优路径选择过程中代替RID。
实验验证
R4从R3和R5分别获得一条去往100.0.1.0/24的路径:
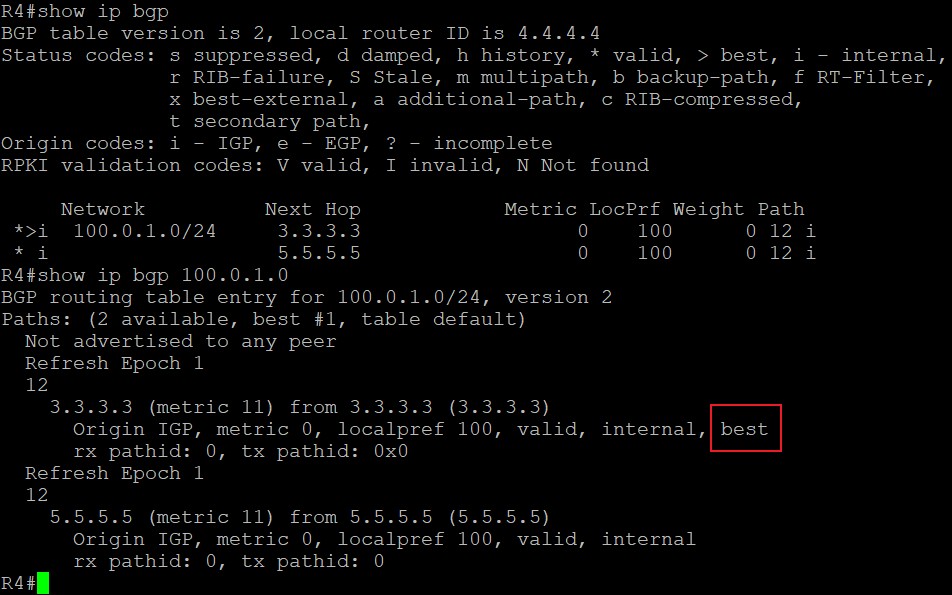
从输出结果可以看到,R4优选的R3发来的路由,用BGP选路规则依次比较两条路由。Weight值两者相同都为默认的0,Local-Preference两者相同都为默认的100,两条路由都不是起源于本路由器NEXTHOP都不为0.0.0.0,AS_PATH长度相同,Origin Code相同都为i,MED值相同都为0,都由IBGP邻居宣告而来,到Next hop距离相同,没有负载均衡,不是EBGP路由所以不会优选最老的EBGP邻居发过来的路由,Router ID不相同,R3的Router ID为3.3.3.3,小于R5的Router ID5.5.5.5,优选R3的路由,比较完毕。
补充实验
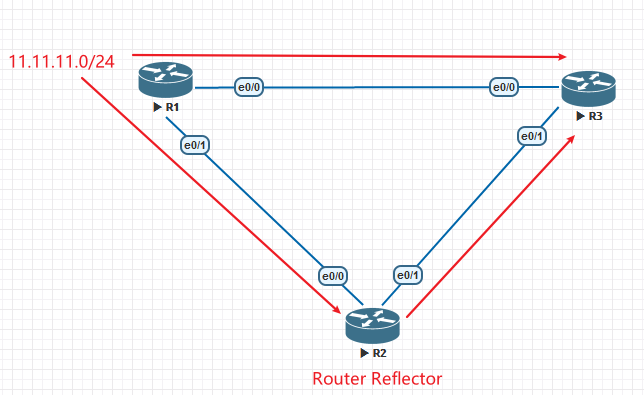
R1\R2\R3三者为IBGP邻居,都在AS123中,互相之间使用loopback接口建立邻居,R2为RR,将R1上宣告的路由11.11.11.0/24反射给R3,此时R3分别从R1和R2分别各获得一条去往11.11.11.0/24的路由,此时分析哪条路由为最优。
基本配置:
1 | R1: |
下面使用规则对两条路由进行分析,Weight值相同都为默认的0,Local-Preference相同都为默认的100,都不起源于本地,AS_PATH长度相同,BGP的Origin Code相同都为i,MED相同(metric)都是0,两者都是IBGP邻居发来的所以没法优选EBGP邻居,到NEXTHOP最近的会被优选两者的NEXTHOP都是1.1.1.1所以相同,没有配置负载均衡,由于是IBGP邻居不能用建立邻居时间规则来优选路由,看起来优选Router ID最小的这条规则发挥了作用,因为一个router ID是1.1.1.1,一个router ID是2.2.2.2,但实际上并不是这样。当使用了RR的时候,Originator值将代替Router ID的值,最终两条路由的下一跳都是1.1.1.1。用show ip bgp 命令看得更清楚:
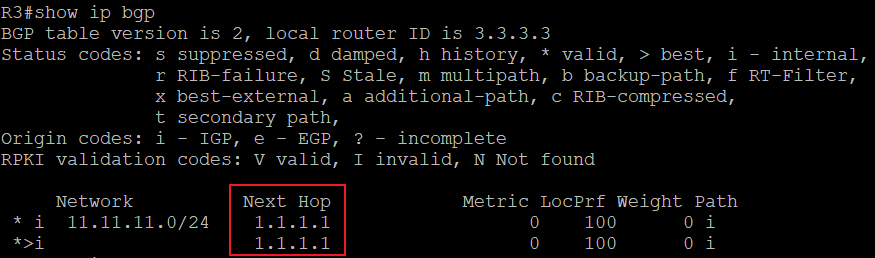
优选Cluster_List最短路由
基本概念
Cluster_List是路由反射器使用的可选非传递属性用来防止环路,在反射路由的时候才会创建或更新Cluster_list,这个值是路由传递时经过的路由反射簇的ID,长度32bit。
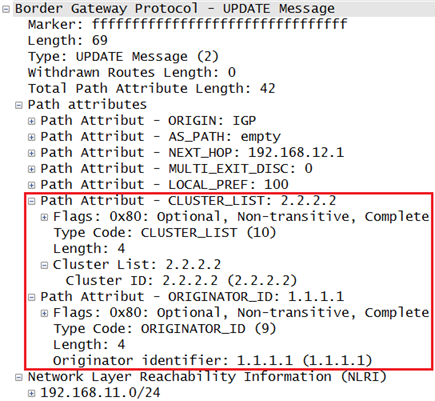
实验验证
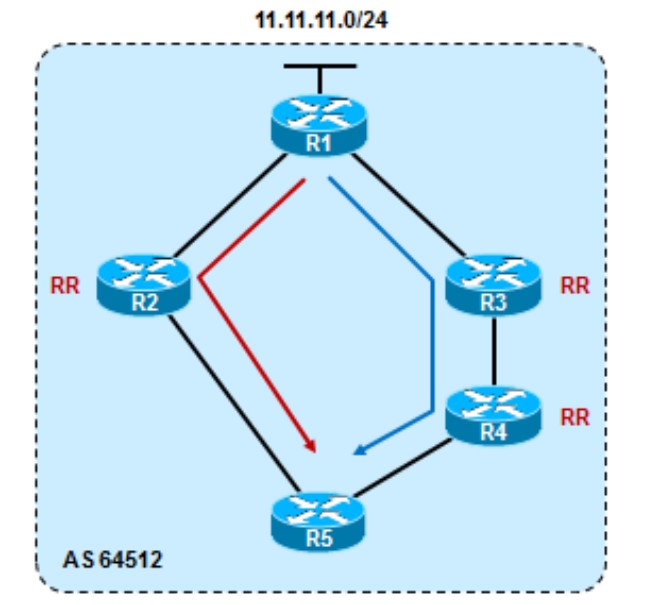
R1\R2\R3\R4\R5两两为ibgp邻居,R1上宣告11.11.11.0/24的路由进BGP,在R5上会从R2和R4分别收到一条去往该目的地的路由,R2\R3\R4都为RR,观察R5上如何优选去往11.11.11.0/24的路由。
基本配置:
1 | R1: |
R5上关于11.11.11.0路由:
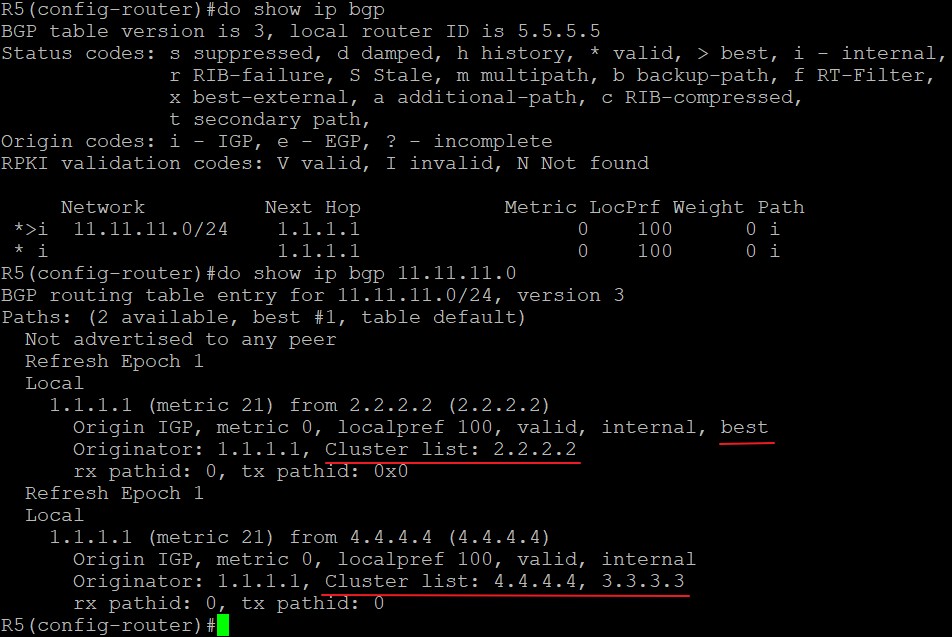
用BGP选路规则对路由进行比较。Weight值相同都是默认的0,Local-Preference值相同都是默认的100,都不是起源于本地的路由,AS_PATH长度相同都是本AS内的路由,Origin Code都为i,MED值相同都为0,都是IBGP邻居传过来的路由,到NEXTHOP的距离相同,没有配置负载均衡,由于是IBGP路由所以不比较是否是最老的EBGP邻居,由于都有RR所以Router ID都是最初被反射的R1的Router ID都是1.1.1.1,Cluster list长度不同,从R2过来这条长度为1从R4过来这条长度为2,所以优选Cluster list长度短的R2这条路由。
优选邻居IP地址小的路由
如果前面12条规则都无法优选出路由,那么只能比较邻居的IP地址,就是配置BGP命令时‘neighbor X.X.X.X remoteYY’中的这个X.X.X.X的地址。
非等价负载均衡
实验环境
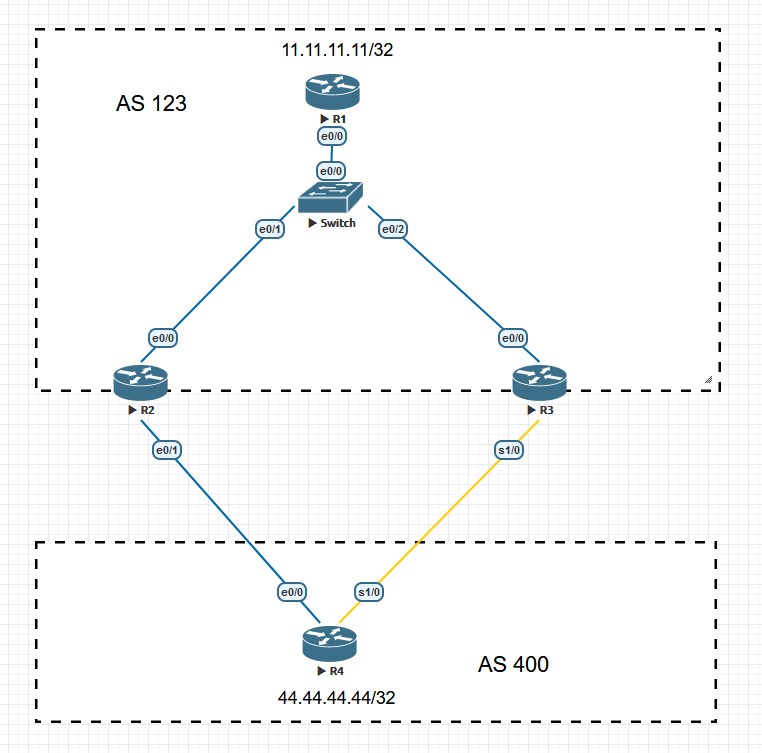
AS123内的三台路由器运行OSPF,通告各自互联接口以及Loopback 0接口,loopback0接口地址为X.X.X.X/32,X为设备编号,IBGP邻居关系基于loopback接口建立,R1在BGP中通告11网段路由,R4在BGP中通告44网段路由。
eBGP非等价负载均衡
R4如何优选路由
由于R4从R2及R3都收到了关于11.11.11.11的路由,所以接下来比结合之前的路由决策看看为什么优选:
1 | R4#show ip bgp |
Weight值相同都为0因为两条路由都不起源于本地而不起源于本地路由的Weight值默认为0,Local-Preference为默认的100由于从eBGP邻居发来所以不带这个属性在R4上为默认值100,两条路由都不起源于本地,AS_PATH长度相同都为1,Origin Code相同都为i,MED相同都为0,性质相同都为eBGP邻居发来的路由,NEXTHOP的距离相同,没有配置负载均衡,由于不是EBGP路由所以‘优选最老EBGP邻居’这条不适用,优选Router ID小的由于R2的Router ID2.2.2.2小于R3的Router ID3.3.3.3,所以优选下一跳是10.1.24.2这边。
配置非等价负载均衡
由于R3方向带宽比较小,所以即使R4需要双出口也不能做负载均衡,因为两边带宽差别比较大,所以这种情况下用非等价负载均衡更为合适。
R4配置:

这里使用的是BGP的link bandwidth特性,借助的是BGP的一个扩展community来实现的,配置该属性以后,R4将会根据带宽来考量R2\R4这两个EBGP邻居,当从R2\R4收到路由时,会给收到的路由黏贴上一个扩展的community属性,这个community属性和接口的带宽是有关联的,会为BGP的非等价负载均衡提供进一步的信息。dmzlink-bw这条命令只能去指向一个EBGP邻居,不能配置给ibgp邻居。
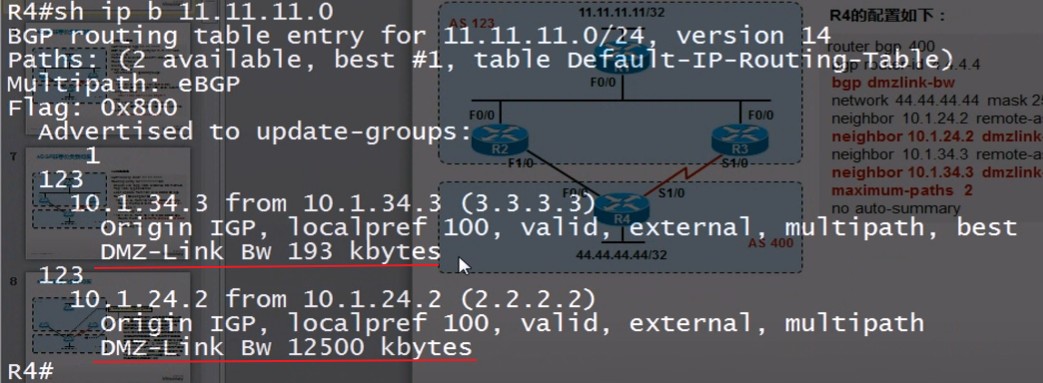
上面标红的的DMZ-LINK BW ……就是这个community属性,这个值是接口带宽除以8计算得来。
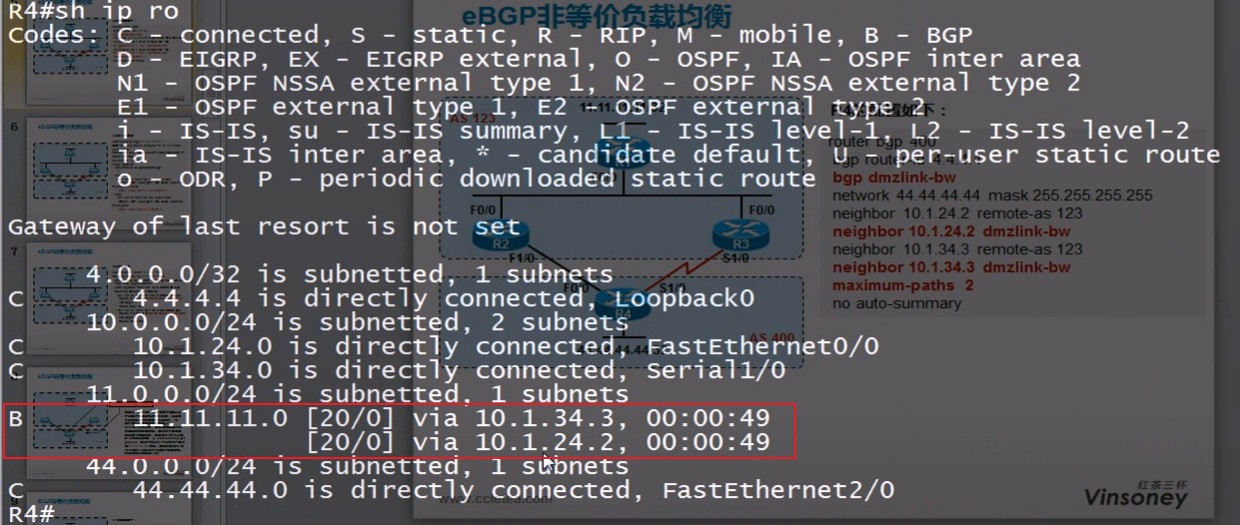
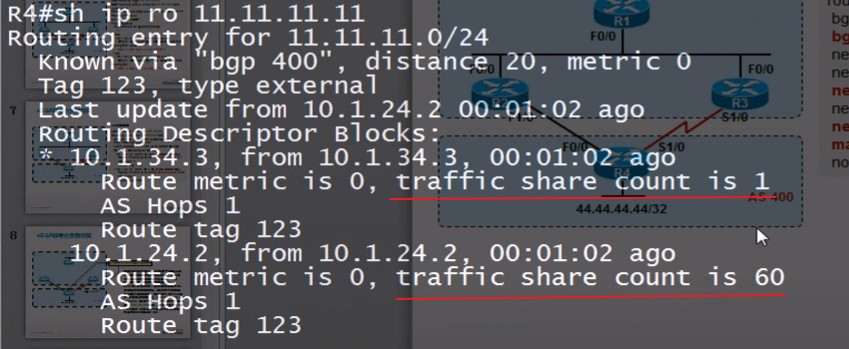
用show ip route 可以看到,路由表中已经负载均衡,进一步看11.11.11.11这条路由会发现,两者形成了非等价负载均衡,比例是60:1,但注意由于CEF的存在,CEF的默认的负载均衡是基于目标地址而不是基于每个数据包的,实际上市基于源、目的地址对的负载均衡,也就是到一个目的地址只走固定的线路:
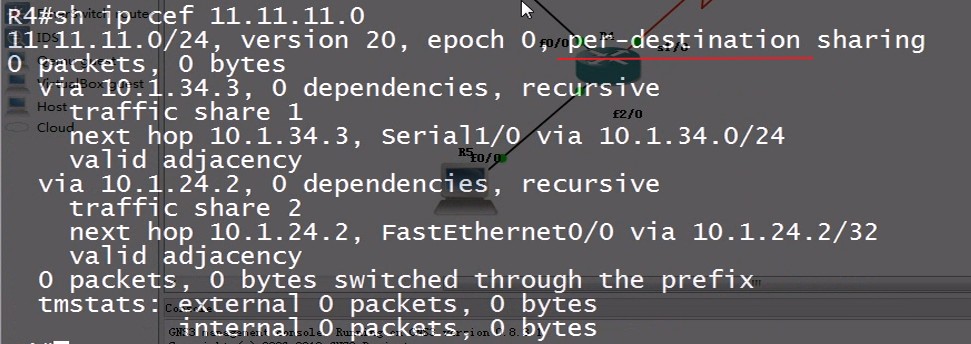
所以要在R4的E0/0和S1/0两个接口上配置‘ip load-sharing per-packet’命令,配置后去往目标地址的数据包才会基于比例分路线走。
iBGP的非等价负载均衡
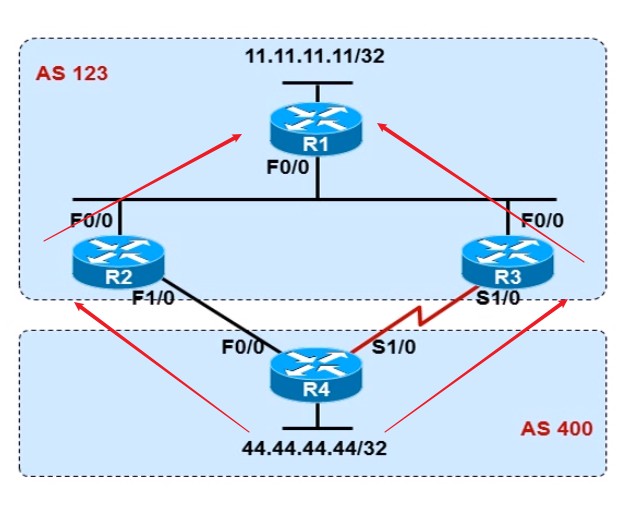
R1从R2和R3都能获取到44.44.44.44/32这条路由,但由于之前提到过的,R4两条链路带宽差别比较大的情况,R1去往R4也不适合使用等价负载均衡,而更适合使用非等价负载均衡才能让带宽有效利用。所以在R2和R3上进行配置,使得R4根据带宽黏贴在路由上的扩展community属性,能传给R1,执行非等价负载均衡。
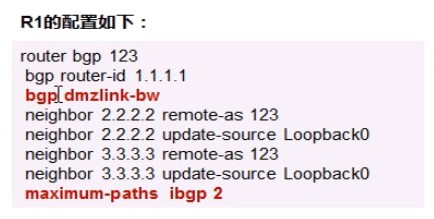
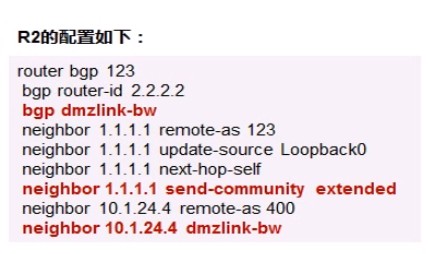
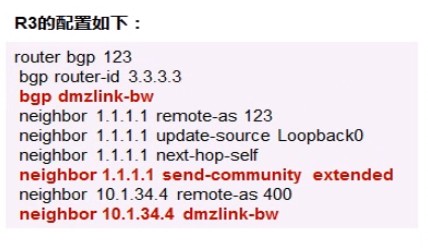
总结
通过利用BGP的Link Bandwidth特性,能够在AS边界路由器外部链路带宽不等价的情况下,实现BGP路由的非等价负载均衡。改特性通过在BGP进程的IPV4或VPNV4地址簇中使用‘bgp dmzlink-bw’命令激活。这个特性搭配BGP multipath特性,即可实现非等价负载均衡。
BGP Link Bandwidth 特性用于在扩展community属性中通告一条AS出口链路的带宽。
这个特性配置在一台AS边界路由器上,指向其EBGP邻居,那么此时该特性所描述的就是该路由器与其EBGP邻居之间的链路带宽。而且该链路带宽信息(使用扩展community描述)除了AS边界路由器自己使用(用于本地的非等价负载均衡),还可以像AS内的ibgp邻居传递,使得AS内部其他路由器也能使用该community做非等价负载均衡,当然前提是得配置send-community extended命令才行。
激活Link Bandwidth的预备条件:
激活maximum-paths特性;
当要向ibgp邻居通告Link Bandwidth特性时,需send-community extended;
CEF或dCEF必须在所有彩玉该特性的路由器上打开。
Link Bandwidth特性的限制:
该特性只能配置在BGP晋城的IPV4或VPNV4地址簇下;
BGP只能够在Link Bandwidthcommunity中通告与eBGP邻居直连的链路(接口)带宽;
在IPV4及VPNV4地址簇中,ibgp及eBGP负载均衡都是支持的,但IBGP\EBGP负载均衡却只能在VPNV4地址簇中才能够支持,也就是ibgp与eBGP的负载均衡。
BGP策略
正则表达式
正则表达式的组成
原子字符
基本概念
| . | 匹配任何单个的字符,包括空格,比如a、b、c、1、2、3都可以被.匹配到 |
|---|---|
| ^ | 一个字符串的开始 |
| $ | 一个字符串的结束 |
| _ | 下划线 任意的一个分隔符如^、$、空格、tab、逗号、{ 、} |
| | | 管道符,表示逻辑或的关系 |
| \ | 转义符,用来将紧跟其后的控制字符转变为普通字符 |
示例
| ^$ | 匹配那些为空的字符串,因为起始字符和结束字符中间没有任何东西,用到AS_PATH控制列表中就是匹配那些AS_PATH为空的路由,也就是那些起源于本AS的路由,因为路由在发送给相邻AS时才会加入AS_PATH,所以起源于本AS的路由AS_PATH部分为空 |
|---|---|
| ^51_ | 匹配那些以51开始后面有一个空格的字符串,比如51 66,51 100,51 888,用到AS_PATH控制列表中就是匹配那些和本AS相连最后经过AS51的路由,也就是那些从邻居AS51发来的路由 |
| _51$ | 匹配那些以51结尾且前面有个空格的字符串,比如100 51,666 51,用到AS_PASH中就是那些起源于AS51路由 |
| 51 | 匹配那些51前后各有一个空格的字符串,比如100 51 200,666 51 888,用到AS_PATH中就是那些穿越过AS51的路由 |
| ^a.$ | 匹配一个以a开始,任意单一字符结束的字符串,如a0,a!,aa,ab等 |
| ^100_ | 匹配一个以100开始,后面跟一个分隔符的字符串,只限制了开始的字符,并没限制后边跟了多少。如100、100 200、100 300 400、100 200 500 600等,‘_’用来匹配AS号之间的空格。如果在匹配AS_PATH的时候,用^100_来匹配的话,表示匹配那些最后经过AS100的路由,也就是相邻AS号是100的路由。 |
| ^100$ | 匹配100,如果在匹配AS_PATH的时候,表示匹配只经过AS100的路由 |
| 100$|400$ | 匹配一个以100或400结束的字符串,前面有几个字符并没有规定,比如100、1400、300 400、131400、1100等都匹配这个正则表达式 |
| ^(65000)$ | \是转义符,正则表达式会把\后面的当做常规字符而不是有特殊功能的字符去对待,该正则表达式仅仅匹配(65000),一般用于匹配联邦中的AS_PATH,联邦中的AS_PATH是用小括号括起来的 |
| [123].[7-9] | [123]表示匹配123中的一个任意数字,可以是1,2或3。‘.’表示匹配任何单个字符或空格,[7-9]表示匹配7到9中的人一个数字。所以167,258,3 7,118等都符合正则表达式 |
| 100 | 由于并没配置开始和结束字符,只要字符串里有100的就可以被匹配上,比如1100,100666,abc100cba等 |
乘法字符
基本概念
一个乘法字符可以应用于一个单字符或多个字符,不能单独使用必须搭配常规字符使用,如果应用于多字符,需将字符串放入()中。由于?和*两个字符都有出现0次的所以一定要谨慎使用,因为可能正则表达式会匹配到无穷多个结果,也就是所有都被匹配到,可能失去了使用正则表达式的意义。
| * | 匹配前面字符0次或多次出现,如果a*,表示匹配a、aaa、aaaa |
|---|---|
| + | 匹配前面字符1次或多次出现 |
| ? | 匹配前面字符0次或1次出现 |
示例
| ^(abc)?$ | 匹配abc出现0次或1次,也就是匹配abc或abc根本不出现,可能匹配到无穷多个结果,慎用 |
|---|---|
| ^abc?$ | 匹配ab在前面,后面的c出现1次或0次,也就是ab或abc |
| ^abc*d$ | 匹配abd、abcd、abccd、abcccd、abccccd等,只要c在abd中间出现0次或多次都可以 |
| ^abc+d$ | 匹配abcd、abccd、abcccd等,只要c在abd中间出现1次或多次都可以 |
| ^abc?d$ | 匹配abd、abcd |
范围字符
基本概念
| [] | 表示一个范围,只匹配包含在范围内的字符之一。可以在一个范围的开始使用^来排除范围内所有字符,也可以使用下划线 _ 来指定一个区间 |
|---|---|
示例
| ^[abcd]$ | 匹配只要出现了a、b、c、d的内容,[]表示包含在范围内字符之一,所以a\b\c\d四者之一都匹配这条 |
|---|---|
| [a-c 1-2] | 匹配a、a1、b1、xyz2、nc2等内容,之所以能匹配很多结果是因为正则表达式没有写开始和结束符号,意味着只要任意一部分符合正则表达式即可 |
| [^act]$ | []中加入^符号表示排除范围内所有字符,[^act]就是排除所有包含a\c\t的,后面加上表示结束的$符号,整体连起来表示排除所有以a\c\t结尾的内容 |
使用as-path access-list匹配路由
基本概念
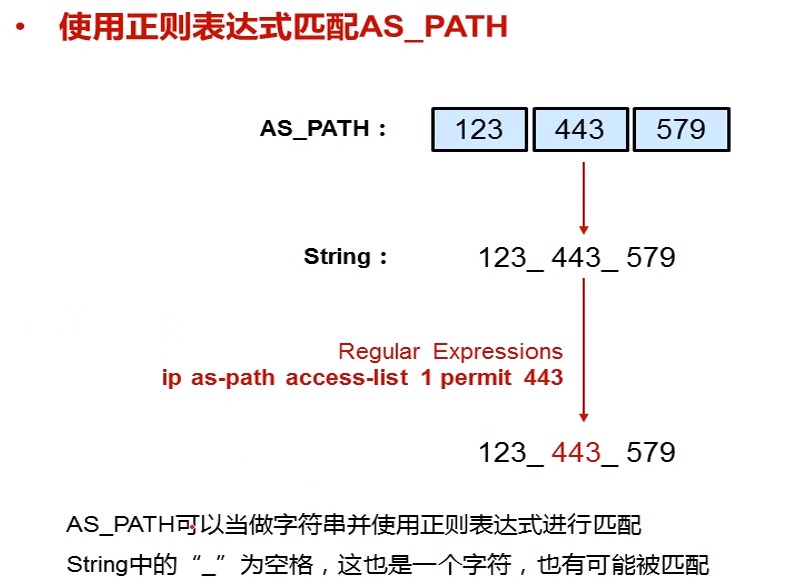

一条路由的AS_PATH如果经过了123、443、579这三个AS,那么在底层它的AS_PATH是‘123_443_579’的形式存在,正则表达式‘443’就能匹配这条路由。as-path access-list中也默认隐含拒绝所有,也就是deny any。
| ^$ | ^表示开始,$表示结束,开始连接着结束表示中间没有任何东西,在AS_PATH访问列表中则表示匹配不包含任何AS号的AS_PATH,也就是匹配本AS内的路由,因为始发于本AS的路由没有进过任何AS,AS_PATH部分为空,只有离开本AS的时候AS_PATH才会有内容 |
|---|---|
| .* | 点代表任意字符,表示出现0次或多次,也就是任意字符可以出现0次或多次,所以就是匹配所有,等同于any,由于AS_PATH access list末尾隐藏了deny any,所以如果不想所有都被deny掉,结尾可以跟一个permit . |
| ^100$ | 匹配100这个AS_PATH |
| ^100_ | 表示以100开始的字符串,也就是100 200、100 555 666等等都匹配,在AS_PATH访问控制列表中则表示匹配那些从AS100直接发到本AS的路由,因为100在AS_PATH中最靠左说明AS100和本AS直接连接 |
| _100$ | 匹配以100结束的AS_PATH,也就是匹配那些起源于AS100的路由,因为在AS_PATH中最靠右的AS号表示最先经历的AS,也就是起源AS |
| 100$ | 匹配那些包含100这个数字在内结束的AS_PATH,比如1100、666100,这个和上面的区别在于是否有前面的‘_’,这个符号代表空格,有没有空格差别很大 |
| ^10[012349]$ | 匹配100、101、102、103、104、109这几个AS_PATH |
| ^10[^0-6]$ | 匹配除了100-106以外的AS_PATH |
| ^10. | 匹配100-109以及10这些AS_PATH,因为‘.’也包含空格 |
| ^(100|200)$ | 匹配包含100或200的AS_PATH |
| 12(_34)?_56 | 匹配12 56及12 34 56这两个AS_PATH |
| ^[0-9]+$ | ‘[0-9]’表示任何在0-9之间的数字都可以被匹配,‘*’表示重复出现1次或多次,0-9重复出现1次或多次则表示任何数字,也就是匹配任何一个数字,包括但不限于1,123,1235,12363434等,‘^’表示开始,‘$’表示结束,当把这些都组合到一起时候表示,匹配单一的一个数字,这个数字可以是任何数,放到AS_PATH访问控制列表中表示任何直接连接到本AS的AS_PATH中只有单个AS的路由,换句话说就是那些起源自直连AS的路由,因为AS_PATH中只有一个数字的话,表示路由只经过一个AS后就传到了本AS且和本AS直连 |
| ^([0-9]+)_51$ | ‘_51$’表示路由起源AS为51,‘([0-9]+)’表示0-9可以出现1次或多次,也就是任意的和本AS相连的AS号都能匹配,‘_’表示空格,连起来表示匹配起自AS51,AS51在与本AS直连的AS后面,大概就是‘本AS-任意AS-AS51’这样连接的 |
| ^51_([0-9]+)$ | ‘^51_’表示路由经过的最后一个AS是AS51,‘([0-9]+)’表示任意多个任意的AS号,也就是路由AS_PATH最后的经过的一个AS为51,倒数第二个AS可以是任意的,所以在AS_PATH访问控制列表中是匹配那些和AS51直连的AS发来的路由,而AS51又和本AS直连 |
配置示例1
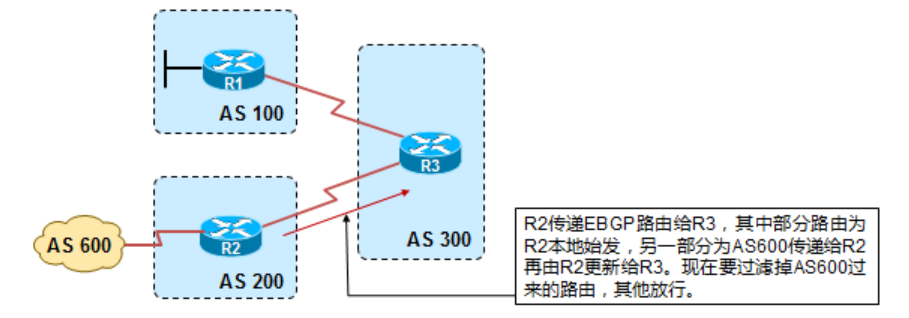
基本配置:
1 | interface Loopback10 |
在R2上一共配置了3个loopback接口,loopback10和11用来模拟从AS600发来的路由,loopback 12用来代表本AS起源的路由,来验证过滤效果。配置ip 前缀列表匹配需要增加AS_PATH的路由,也就是172.16.10.0/24和172.16.11.0/24,创建route-map来对匹配的两条路由的AS_PATH进行操控,用prepend命令为AS_PATH重增加600这个AS来模拟从AS600发来的路由,此时R3上路由表为:
1 | R3(config-if)#do show ip bgp |
现在要在R3上进行配置,目标是过滤掉所有从AS600发过来的路由,总体思路是,先用AS_PATH访问控制列表匹配AS_PATH中最近一个是600的那些路由,然后用rfilter-list从in方向上过滤掉:
1 | ip as-path access-list 10 deny _600$ |
‘_600&’这个正则表达式匹配的是与本AS相连,起源于AS600的路由,前面加上deny就是将从AS600发来的路由过滤掉,后面的‘permit .*’就是放行所有其他路由,这个as_path访问控制列表就是讲从AS600发来的路由过滤掉,并放行其他路由。如果写完正则表达式以后不知道匹配的路由是否是自己想要的,可以用命令‘show ip bgp regexp xxxx’来验证:
1 | R3(config-router)#do show ip bgp regexp _600$ |
从上面验证的结果可以看出,该正则表达式的结果就是我们想要的,然后在对邻居R2的in方向上用filter-list应用AS_PATH访问控制列表,此时再看R3的路由表,已经达到了我们想要的结果:
1 | R3(config-router)#do show ip bgp |
配置示例2
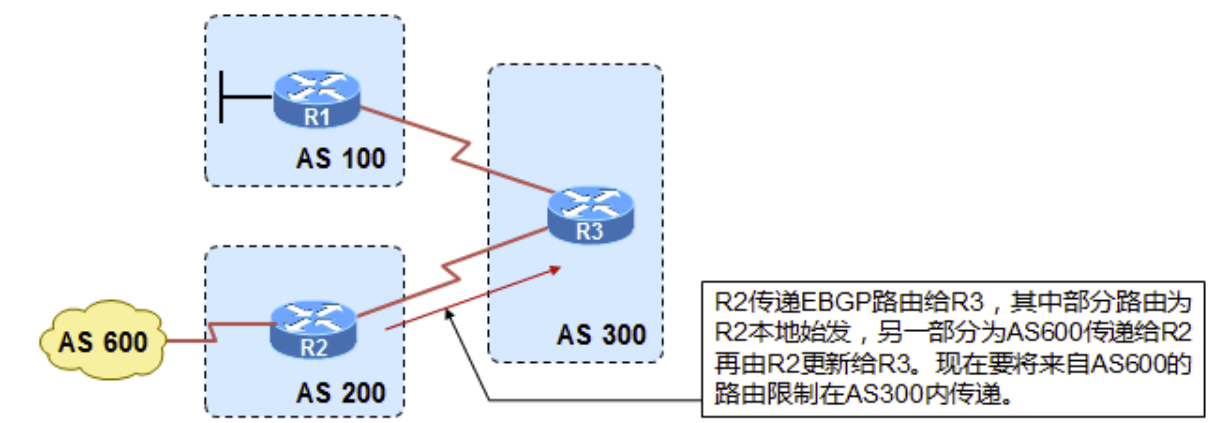
1 | ip as-path access-list 1 permit _600$ |
配置示例3
如上图所示,AS100和AS203,302,401,500为邻居,这时AS100想匹配那些起源于直连的AS(比如AS203,302,401,500)的路由以及那些起源于直连本AS的邻居AS(比如AS202,301,400)的路由。
用正则表达式匹配这些路由最简单直接的办法就是写出来那些需要匹配的AS号然后进行匹配,我们要匹配的AS有:
1 | 203 |
在现有拓扑连接情况下要匹配这些AS只需要将他们都写入正则表达式即可,也就是写7行匹配语句,每一行如上所示,这样就能匹配所有需要的AS,但如果以后拓扑发生变化,不只有这7个AS的话正则表达式就无法匹配所有需要匹配的AS了,比如如果AS100新加了一个邻居,AS666,那么之前的正则表达式就匹配不到这个AS666了,而起源于这个AS的路由也是需要被匹配到的,因为它也是AS100的直连AS。所以考虑到拓扑的扩展可能性,必须匹配到所有可能的路由就不能这么写。
我们知道,正则表达式得有开始和终结符号,所以‘^’和‘$’是肯定要有的;
由于匹配的目标有两个,一个是起源于直连AS的路由,另一个是起源于直连AS的邻居的路由。起源于直连AS的路由的AS_PATH只有一个AS号,暂时写为‘^X$’,X表示任意的AS号;起源于直连AS的邻居的路由有两个AS号,暂时写为‘^X X$’;
接下来要确定‘X’这个任意的AS号如何用正则表达式匹配,因为X表示一个AS号,而AS号中肯定没有数字、括号、逗号这种特殊字符,所以它肯定是一个数字,又因为我们不知道这个数字具体是什么,它可能有一个或多个单独的数字组成,比如可能是5,10,123或1010,它代表了0-9之间所有可能的数字,这些数字可能出现1次或多次,所以用‘[0-9]+’来表示这个X,因此正则表达式可以写成:
1 | ^[0-9]+$ |
但这么写是不是就是最佳的表示方式呢?并不是,第一行和第二行的区别在于,第二行多了一个‘[0-9]+’,而第一行没有这个‘[0-9]+’,换句话说,‘[0-9]+’存在了0次或1次,而‘?’正好能表示字符出现 0次或1次,因此可以将这个正则表达式优化为:
1 | ^[0-9]+ ([0-9]+)?$ |
如何验证
在配置完正则表达式以后可以使用命令‘show ip bgp regexp’来检查所匹配的路由是否和想要的相一致,也可以用该网页检查,不过是英文版的,但有详细的正则表达式说明。
在cisco IOS中的应用
show 和more的输出中,可使用管道符‘|’搭配正则表达式来过滤输出结果,输入‘|’的方式为‘shift+\’,‘\’在回车键的上边。
1 | R3#show run | ? |
管道符后面可以接多种的限制词语,比如begin XXX就是以XXX开始的;include XXX就是显示包含XXX在内的shou run语句;section XXX就是包含XXX的章节比如:
1 | R3#show run | section router |
BGP过滤器
Prefix-list
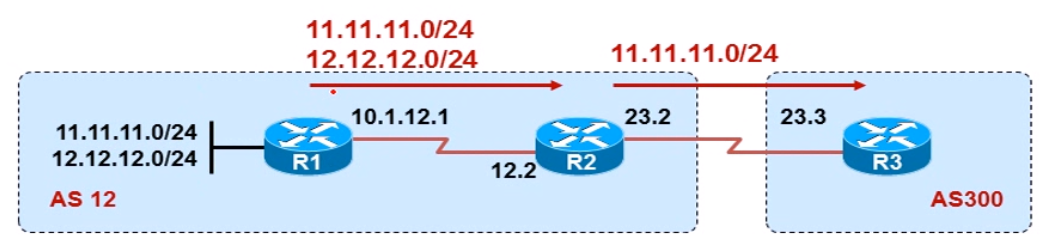
在R2上用prefix-list只过滤掉12.12.12.0/24的路由,放行其他路由
1 | R2: |
0.0.0.0/0 le 32等同于any,当然在R1的out方向进行过滤也没问题。
Distribute-list
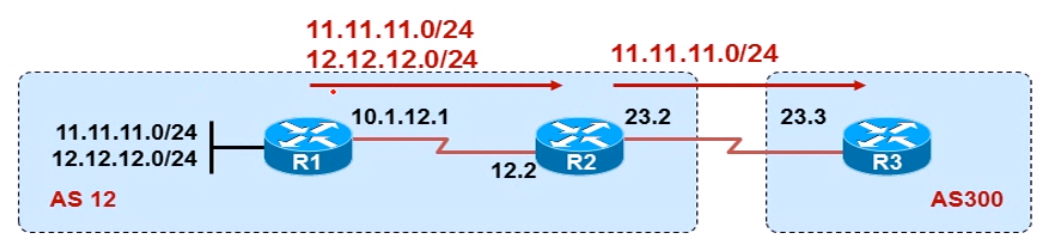
拓扑依旧,在R2上用distribute-list只过滤掉12.12.12.0/24的路由,放行其他路由
1 | 配置方式1: |
Route-map
关联network命令
1 | ip prefix-list 11 seq 5 permit 11.11.11.0/24 |
分别用前缀列表11以及12抓取11.11.11.0/24,12.12.12.0.0/24,然后分别写两个route-map,对两条路由赋予community属性,然后将route-map挂在network命令后边,在宣告的时候直接打上community,也可以对邻居的out方向使用route-map。然后对邻居R2配置send community命令,使得community能够发送给R2,而后配置bgp-community new-format命令将显示的格式调整到RFC默认格式。
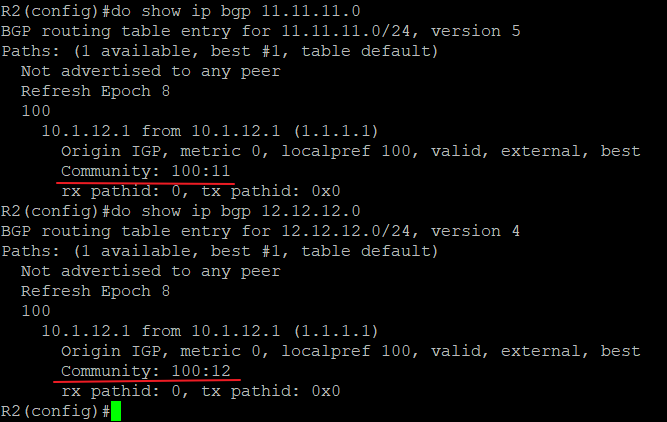
但必须注意的是,在network后面使用route-map影响的是所有的BGP邻居,如果除了R2以外还有其他邻居,比如R3,则这个community也会发给R3。如果只想对特定的邻居发送community,最好将route-map挂在neighbor命令后。
关联neighbor命令
拓扑和之前相等,此时在R1上进行配置,对R2传递路由时设定11.11.11.0/24的MED值为1000;12.12.12.0/24的MED值为2000
1 | R1: |
由于route-map最后有deny any的隐藏项,所以最后还是加上了‘route-map MED1 permit 30’的语句,放行其他路由,以防以后宣告的其他路由被deny掉无法传递到R2。
1 | R2上输出验证route-map中的MED(metric)是否配置成功 |
关联重发布命令
1 | redistribute ospf 1 route-map RP |
Unsuppress-map
R1和R2为BGP邻居,R1上宣告了两条路由,1.1.1.0/24核1.1.2.0/24,在R1上进行路由汇总,将路由汇总为1.0.0.0/8,抑制明细,但希望放行1.1.1.0/24这条路由:
1 | R1: |
在R1上进行完路由汇总以后,由于要放行其中一条明细路由,所以用unsuppress-map进行操作,unsuppress-map 后面跟的route-map中被匹配到的路由不会被抑制
先写一条前缀列表匹配(抓取)需要放行的路由‘ip prefix-list 1 seq 5 permit 1.1.1.0/24’;
由于unsuppress-map后面需要跟route-map,所以写一个匹配路由的route-map,里面只用match语句匹配该路由即可,不需要接set语句;
对邻居192.168.12.2使用unsuppress-map命令后面接之前写好的那条匹配了路由的route-map;
最后的R2上查看BGP表查看配置效果:
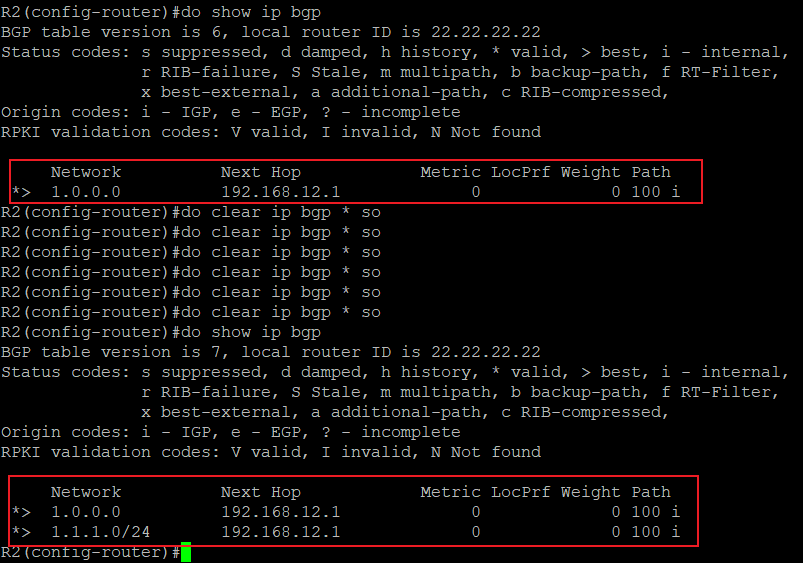
默认路由
静态路由方式
在路由表中如果有‘ip route 0.0.0.0 0.0.0.0 XXX’的静态路由,在BGP进程中可以使用‘network 0.0.0.0’将此路由注入BGP进程,使得BGP中也有默认路由,该方法在BGP中引入默认路由会被传递给所有BGP邻居。
neighbor XXX default-originate
基本概念
本在BGP中配置‘neighbor XXX default-originate’则会向特定的邻居XXX传递默认路由,此配置无需路由表中存在默认路由,有点类似OSPF的default-originate always命令。
实验验证
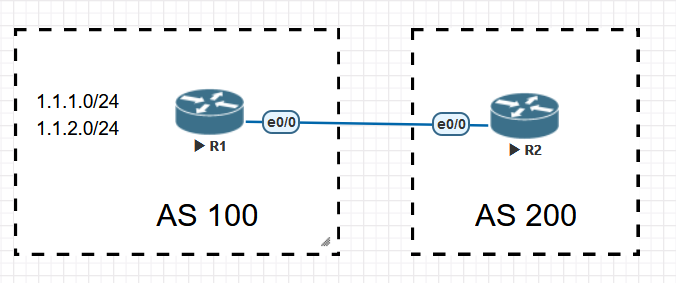
R1和R2为ebgp邻居,R1向R2下发一个默认路由,使得R2的默认路由指向R1,且要保证默认路由始终有效。
1 | R1: |
只要R1的loopback接口1.1.1.1不down,R1就始终会向R2下发默认路由。
default-information originate
在本地配置一条静态的默认路由,如‘ip route 0.0.0.0 0.0.0.0 null0’,默认情况下,BGP在重新发布静态路由的时候不允许注入默认路由,除非在BGP进程中配置‘default-information originate’:
1 | ip rouet 0.0.0.0 0.0.0.0 null0 |
BGP排错步骤
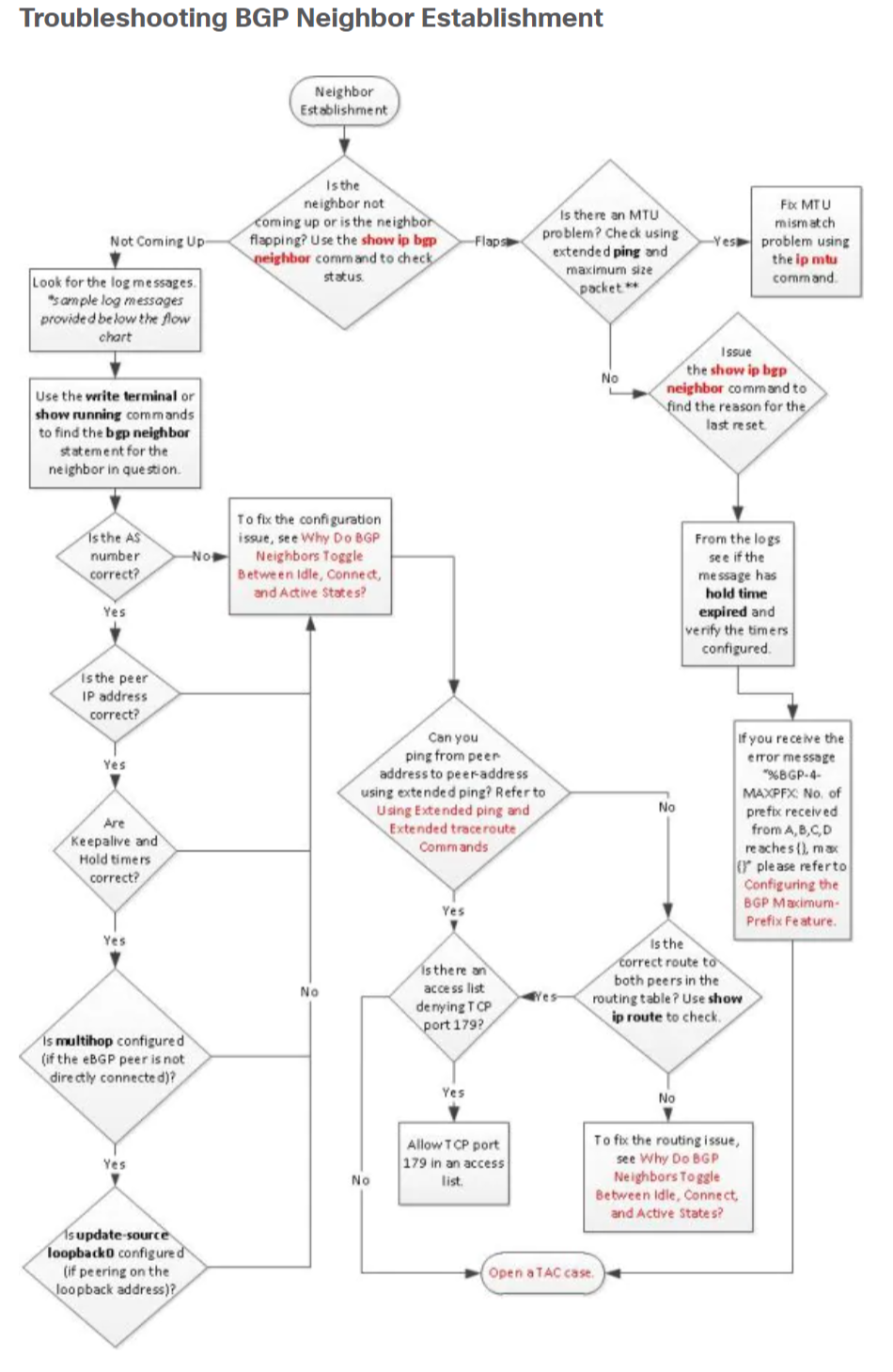
引用文章
Demystifying BGP Session Establishments
BGP Route Dampening: obsolete or still used in the industry?
Understanding BGP Regular Expressions
BGP 技术笔记
BGP Address Family Identifiers (AFI) and Subsequent address family identifiers (SAFI)
 wechat
wechat alipay
alipay