19-Switch
以太网
基础知识
- Ethernet,以太网发明与20世纪70年代中期,由Xerox公司分部,Palo Alto研究中心开发的,Xerox最早发明的是一个2Mbps的以太网,后来又和Intel以及DEC合作开发出了10Mbps的以太网,俗称Ethernet 2或Ethernet DIX。后来IEEE通过802委员会把Ethernet标准化为IEEE802.3,它和Ethernet2十分相似。在TCP/IP中,以太网IP数据报文的封装格式由RFC894定义格式,IEEE802.3网络的IP数据报文封装由RFC1042定义,当今最常用的封装格式是RFC894定义的格式,通常称为Ethernet 2或Ethernet DIX。
- 管理MAC表。show mac address-table,clear mac address-table,绑定mac地址到一个接口:mac address-table static
以太网的数据链路层
在以太网中,针对不同的双工模式,提供不同的介质访问方法:
- 半双工模式下采用的是CSMA/CD的访问方式。
- 全双工模式下则可以直接进行收发,不用预先判断链路的忙闲状态。
半双工和全双工是物理层的概念,而针对物理层的双工模式提供不同的访问方式则是数据链路层的概念,这样就形成了以太网的一个重要特点,数据链路层和物理层是相关的。
由于以太网的物理层和数据链路层是相关的,针对物理层的不同工作模式,需要提供特定的数据链路层来访问。这给涉及和应用带来了一些不便,为此一些组织和厂家提出把数据链路层进行分层,分为逻辑链路控制子层(Logical Link Control,LLC)和媒体访问控制子层(Media Access Control),这样不同的物理层对应不同的MAC子层,LLC子层可以完全独立。
MAC子层
MAC子层负责如下任务:
提供物理链路的访问;
链路级站点标识:在数据链路层识别网络上的各个站点。
也就是说,在该层次保留了一个站点地址,也就是MAC地址,来标识网络上的唯一一个站点。
链路级的数据传输:从LLC子层接收数据,附加上MAC地址和控制信息后,把数据发送到物理链路上;在这个过程中提供校验等功能。
MAC子层是物理相关的,也就是说,不同的物理层有不同的MAC子层来进行访问。在以太网中,主要存在两种MAC:
- 半双工MAC:物理层运行模式是半双工时提供访问。
- 全双工MAC:物理层运行模式是全双工时提供访问。
这两种MAC都集成在网卡中,网卡初始化的时候一般进行自动协商,根据自动协商的结果决定运行模式,然后根据运行模式选择相应的访问MAC。
MAC地址是烧录在网卡(Network Interface Controller,NIC)的ROM里的
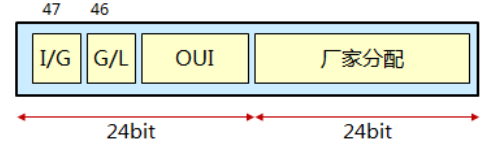
- 高位是Individual/Group位,当它的值为0时,就可以认为这个地址实际上是设备的MAC地址。当它的值为1时,就可以认为这个地址表示以太网中的广播地址或组播地址,或者表示TR和FDDI中的广播地址或功能地址。
- 下一位是G/L位(也叫做U/L,这里的U表示全局)当这一位设置为0时,就表示一个全局管理地址(由IEEE分配),当这一位为1时,表示一个在管理上局部本地的地址(就像在DECnet中一样)。以太网一直使用全局唯一地址。
以太网帧格式
二层以太网的封装格式,能够见到的有四种,分别是TCP/IP协议使用、目前基本大一统的Ethernet II,IEEE的802.3、802.3LLC、802SNAP,常见的封装格式有两种:IEEE802.3和Ethernet II(以太网2),之所以有两种帧封装格式,是因为OSI七层以及TCP/IP两种模型定义了两种不同的封装格式,他们的差别主要是在帧头封装部分,之前规定的结果是控制层面使用802.3格式封装,转发层面的使用以太网2封装,但基本上目前是以太网一统天下,所以在这里就不说关于802.3的相关东西了。对这个有兴趣的可以看看论坛的帖子:Ethernet 802.3 vs. Ethernet II Frame和Ether Frames 802.3 naming conventions,这里贴一段总结的比较好的话:
if you are going to look at an IPv4 or IPv6 communication, it will be practically always encapsulated into Ethernet II frames because those are the most efficient in terms of overhead. 802.3 + LLC frames are used nowadays mostly for older protocols authored by IEEE itself, such as STP/RSTP/MSTP. SNAP frames are often used for vendor-proprietary Layer2 protocols - Cisco uses it for CDP, DTP, VTP and PAgP, to name a few.
如果你观察IPV4和IPV6的通信,它们实际上都是用以太网2进行封装的,因为从开销方面来说,这是最有效的封装方式,802.3+LLC子层的帧格式绝大部分时候出现在IEEE便携的较老的协议上,比如STP/RSTP/MSTP等协议。SNAP帧格式经常出现在厂家私有协议的二层协议中,比如思科在CDP,TDP,VTP和PAGP等协议上。
为什么以太网2格式使用的更广泛呢?
To run TCP/IP over IEEE 802.3, the SNAP format has to be used. That requires 8 bytes of the data field to identify the kind of data the frame is carrying: three bytes for the Logical Link Control, three bytes for the SNAP header, and two bytes for the Protocol Type field. That means the data field shrinks from the standard range of 46 to 1500 bytes down to a range of 38 to 1492. This is the reason most network managers stay with Ethernet II.
在TCP/IP协议上运行IEEE802.3封装时,必须使用SNAP格式,它需要8字节的数据字段来标识帧所携带的数据类型。这8个字节由3个字节的逻辑子层控制、3字节的SNAP报头、2个字节的协议类型字段组成。这意味着能携带的数据部分将从46-1500,缩小到38-1492字节。数据部分缩小是绝大多数网络使用以太网2封装的原因。
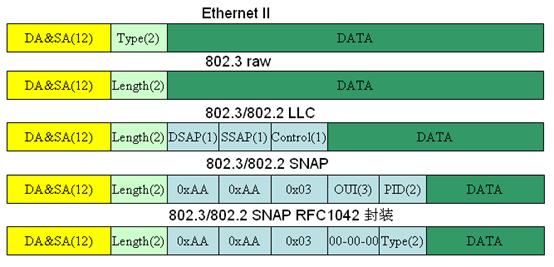

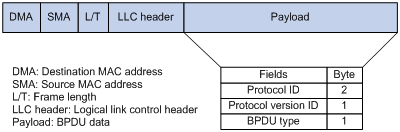
| 前导(Preamble) | 包括7个字节的签到码(一串1、0间隔,用于信号同步)及1个字节的帧起始定界符 |
|---|---|
| 类型(Type) | 802.3使用长度字段,但Ethernet帧使用字段类型来识别网络层的协议。在Ethernet2帧中,两字节的类型字段用于标识数据字段中的高层协议,也就是说,该字段告诉接收设备如何解释数据字段。在以太网中,多种协议可以在局域网中同时共存,因此在Ethernet2的类型字段中设置相应的十六进制值提供了在局域网中支持多协议传输的机制。类型字段取值为0800的帧代表IP协议帧;类型字段取值为0806的帧代表ARP协议帧;类型字段取值为0835的帧代表RARP协议帧;类型字段取值为8137的帧代表IPX和SPX传输协议帧;802.3不能识别上层协议,因此必须与专用的LAN(比如IPX)一起使用。 |
| 数据(Data) | 46-1500字节;在接口下设置的mtu xxx命令,指的就是这个,并且一般不允许手动修改。ip mtu指的是ip报文的最大值。 |
| 帧校验序列FCS(Frame Check Sequence) | 这部分的作用是让接收端在收到数据的时候检查收到的帧是否正确无误,如果校验和结果错了,会丢掉此帧;如果校验和结果正确,再去判断帧的目的硬件地址(MAC地址)是否符合自己的接收条件,看帧校验和是二层解封装后的第一步。以太网使用CRC(Cyclic redundancy check)这种方式校验,所以在以太网里,可以暂且把两者看成是同一个东西,但从概念上来讲,要知道二者是不同的。 |
目前我们所使用到的以太网帧基本都是Ethernet2帧。
以太网接口类型
以太网接口按大类分为二层接口(Layer 2 Switchport)和三层接口(Layer 3 Port),二层接口又分为四种类型,分别是access,Trunk,Tunnel以及Dynamic;三层接口分为两种类型,Switched Vritual Interface(SVI),Native Routed Interfaces。

二层switchport接口共有四种:
- Access Switchports:Access类型接口只能划入一个VLAN里,能且只能传输一个VLAN的流量,比如该接口如果属于VLAN101,那么只能传输属于VLAN101的流量,access接口只会给属于本接口VLAN的流量打上VLAN的标签(TAG)。Access接口一般用来连接主机,如果要将一个接口(比如E0/0接口)配置成access类型并将它划入某个vlan(比如vlan 69),输入以下命令:
1 | interface Ethernet E0/0 |
- Trunk Switchports:Trunk接口可以同时供多个VLAN通信,在默认情况下Trunk接口存在于所有VLAN的database中,Trunk接口同时支持ISL及802.1Q协议。一般Trunk接口用在两个交换机之间、交换机和路由器之间,交换机和服务器之间,这种连接的场景,Trunk接口能让多个VLAN在设备之间通讯,传递数据,如果将E0/0接口配置为Trunk的话,配置如下:
1 | interface Ethernet E0/0 |
- Tunnel Switchports:Tunnel接口是为了Transparent Layer 2 VPN使用。
- Dynamic Switchports:Dynamic接口可以和对端的Dynamic接口动态协商Trunk接口的类型
三层接口公有三种
- Switched Virtual Interface(SVI):
- Native Routed Interfaces:在交换机接口上输入“no switchport”命令后,该端口就从一个二层交换接口变为一个三层路由接口,和路由器的路由接口功能一样,也可以配置IP地址。
•Access Ports: belong to and carry the traffic of only one VLAN
•Trunk Ports: carry the traffic of multiple VLANs and by default is a member of all VLANs in the VLAN database. Both ISL and 802.1Q trunk ports are supported
•Tunnel Ports: designed for service providers who carry traffic of multiple customers across their networks and are required to maintain the VLAN and Layer 2 protocol configurations of each customer without impacting the traffic of other customers. Both 802.1Q tunneling and Layer 2 protocol tunneling are supported
二层交换
功能
- MAC addresses are known from all the incoming frames source addresses.
- Bridges and switches communicate with each other using the STP to remove bridging loops.
- Frames designed for unknown locations are overflowed out to all ports except the one that received the frame.
- It performs the same function as a transparent bridge.
- Frames are forwarded using specialized hardware, which is known as Application-Specific Integrated Circuits (ASIC).
- Layer-2 switches also perform the switching function to re-arrange the data frames from the source to its destination network.
- Layer-2 Switch splits a complicated LAN (local area network) into small VLAN networks.
- 交换机从接收到的数据包的二层报头中获取Mac地址;
- 交换机在彼此通信过程中使用STP协议来消除二层环路;
- 交换机收到未知数据帧后,会将该数据帧泛洪到(发送到)除了接收到该数据帧之外的所有交换机的接口上,比如一个交换机有4个接口,E0/0,E0/1,E0/2,E0/3,从E0/0收到一个目的地址为未知MAC的数据帧后,交换机会将这个数据帧发送到E0/1,E0/2,E0/3上,看是否有设备回应;
- 数据帧由专门的ASIC芯片进行处理,所以处理速度很快;
- 二层交换机会在收到数据以后,将数据中的二层的源、目的Mac地址进行替换,以便发给下一个设备节点;
- 二层交换机将复杂的局域网拆分为小的VLAN网络;
优缺点
优点:
- Helps to forward packets based on unique MAC addresses
- Does not offer any setup or management
- It can be quickly deployed at a lower cost
- L2 switches flow accounting capabilities
- Low latency and improved security
不足:
- The layer 2 switches must break up the collision domains correctly.
- It does not break up broadcast domains by default.
- L2 switches does not allow you to implement any intelligence while forwarding packets.
- Does not helps you to perform switching or IP address-based routing.
- Never given guarantee required bandwidth to VoIP users
三层交换
基本概念
A Layer 3 switch is a switch that performs routing functions in addition to switching. A client computer needs a default gateway for layer 3 connectivity to any remote subnets.
This type of layer helps you to combine the functionality of a switch and a router. It acts as a switch to connect devices that are on the same subnet or virtual LAN.
This type of CISCO network switches support routing protocols. It helps to inspect incoming packets and makes routing decisions based on the source and destination addresses. That is how layer 3 switch acts as both for switch and a router.
三层交换
三层交换的功能
- Define paths based on logical addressing
- Provide Security
- Run layer three checksums
- Process and respond to any option information
- Allows you to update simple Network Management
- Information Base (MIB) information
优缺点
优点:
- L3 support routing between virtual LANs.
- Improve fault isolation.
- Provide ease of security management.
- Reduce broadcast traffic volumes.
- Ease the configuration process for VLANs, as a separate router is not needed between each VLAN.
- Separate routing tables, and as a result, segregate traffic better.
- Offers flow accounting and high-speed scalability.
- Lower network latency as a packet that does not make extra hops to go through a router.
不足:
- The cost of the L3 switch is quite high compared to the Layer 2 switch.
- Layer 3 switch does not offer WAN functionality.
- Multiple tenants and virtualization.
- Does not offer any functionality.
二层交换VS三层交换
| Layer 2 | Layer 3 |
|---|---|
| Layer 2 switching is used to reduce traffic on the local network. | It is mostly used to Implement VLAN. |
| In Layer 2, switching packets are rerouted from the source to the destination port. | In Layer 3 switching, switches use a little time to check data packets before finding the best available route to direct data packets to the destination port. |
| Layer 2 uses the Address Resolution Protocol (ARP) to discover other devices’ MAC addresses. | Layer 3 devices utilize IP addresses for routing within Virtual LANs (VLANs). |
| Layer 2 switch comes with a little tendency of switching packets from one port to another. | Layer 3 switching helps devices to communicate outside the networks as well. |
| Layer 2 switch does simple switching by finding and maintain a table of MAC addresses. | Layer 3 switch is a specialized device that is designed for routing of data packets through IP addresses. |
| Item | Layer 2 Switch | Layer 3 Switch |
|---|---|---|
| Routing Function | Mac address only | Supports higher routing such as static routing and dynamic routing, |
| VLAN Tagging Based on IP Address | No | Yes |
| Inter-VLAN | No | Yes |
| Application | Pure Layer 2 domain | Aggregate multiple access switches |
- Layer2 is the process of using devices and MAC addresses on a LAN to segment a network.
- A Layer 3 switch is a switch that performs routing functions in addition to switching.
- Layer 2 switches perform the switching function to re-arrange the data frames from the source to its destination network.
- Layer 3 switches define paths based on logical addressing.
- Layer 2 switches are used to reduce traffic on the local network, whereas Layer 3 switches mostly used to Implement VLAN.
- The advantage of Layer 2 switches is that it helps to forward packets based on unique MAC addresses
- The advantage of Layer 3 switches offers flow accounting and high-speed scalability.
- The main drawback of Layer 2 switches is that it does not allow you to implement any intelligence while forwarding packets.
- The main drawback of the Layer 3 switch does not offer WAN functionality.
二层交换
VLAN
基本概念
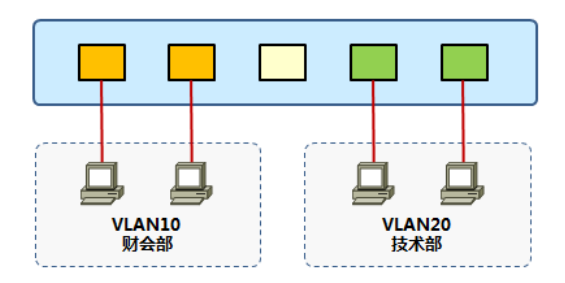
一个VLAN中所有设备都是在同一广播域内,不同的VLAN为不同的广播域;
VLAN之间相互隔离,广播不能跨越VLAN传播,因此不同VLAN之间的设备一般无法相互访问,不同的VLAN间需通过三层设备实现相互通信;
一个VLAN一般为一个逻辑子网,由被配置为此VLAN成员的设备组成;
VLAN中成员大多基于交换机的端口分配,划分VLAN就是对交换机的接口划分;
VLAN工作域OSI参考模型的第二层;
VLAN是二层交换机的一个非常根本的工作机制;
VLAN分类
- Standard vlan:标准VLAN,标准VLAN的范围为1-1005,其中VLAN1为cisco默认vlan,VLAN1位默认的以太网接入VLAN,也就是说在刚开机没做任何配置的情况下,所有接口默认划入VLAN1;VLAN1为802.1Q的本生VLAN,在VLAN1上传输的数据是不带TAG的,也就是说用802.1Q协议时如果收到一个不带TAG的数据,那么设备会默认这个数据属于Native VLAN(本生VLAN,默认情况下为VLAN1,也可以手动修改,将其他VLAN设置为本生VLAN);VLAN1无法被删除,无法被VTP协议修剪,但可以手动从VLAN中修剪掉;为了安全起见,VLAN1不应该在生产环境的网络中使用。其中VLAN1002-1005为令牌环或FDDI使用,它们无法被删除,不应该在生产环境中使用这几个VLAN。
- Extended vlan:扩展VLAN,扩展VLAN的范围为1006-4094,只有在VTP使用v3版本或者VTP配置为Transparent模式的时候才能使用,其中一些VLAN不允许被使用。
- Internal vlan:内部VLAN,保留以供内部使用,不过各个厂家对于内部VLAN范围的规定各有不同。
VLAN通信原理
为了提高处理效率,交换机内部的数据帧一律带有VLAN Tag,以统一方式处理。当一个数据帧进入交换机端口时,如果没有带VLAN Tag,并且该端口上配置了PVID(Port VLAN ID),那么该数据帧就会被标记上端口的PVID,如果该数据已经带有了VLAN Tag,那么即使端口已经配置了PVID,交换机不会再给数据帧标记VLAN Tag。默认情况下,整台交换机的所有端口均属于同一个广播域。
PVID是端口缺省VLAN ID的意思,即一个端口缺省属于的VLAN。
由于端口类型不同,交换机对帧的处理过程也不同,下面将根据不同的端口类型分别介绍。
Access接口处理帧过程
Access端口处理VLAN帧的过程如下:
收到二层帧。
判断帧是否有Vlan Tag:如果没有Tag,则标记上Access端口的PVID,进行下一步处理;如果有Tag,则比较帧的VLAN Tag和端口的PVID,如果两者一致则进行下一步处理,如果不一致则丢弃帧。
二层交换机根据帧的MAC地址和VLAN ID查找VLAN配置信息,决定从哪个端口把帧发送出去。
交换机根据查到的出接口发送数据帧:
当数据帧从Access端口发出时,交换机先剥离帧的VLAN Tag,然后再发送出去;
当数据帧从Trunk端口发出时,直接发送帧;
当数据帧从Hybrid端口发出时,交换机判断VLAN在本地端口的属性是Untag还是Tag,如果是Untag,会先剥离帧的VLAN Tag,再发送;如果是Tag,则直接发送帧;
Trunk端口处理帧过程
Trunk端口处理VLAN帧的过程如下:
收到一个二层帧。
判断帧是否有VLAN Tag。如果没有Tag,则标记上Trunk端口的PVID,进行下一步处理。如果有Tag,则判断该Trunk端口是否允许VLAN帧进入。允许进入则进行下一步,否则丢弃帧。
二层交换机根据帧目的MAC地址和VLAN ID查找VLAN配置信息,决定从哪个端口把帧发送出去。
交换机根据查到的出接口发送数据帧:
当数据帧从Access端口发出时,交换机先剥离帧的VLAN Tag,然后再发送出去;
当数据帧从Trunk端口发出时,直接发送帧;
当数据帧从Hybrid端口发出时,交换机判断VLAN在本地端口的属性是Untag还是Tag,如果是Untag先剥离帧的VLAN Tag,再发送,如果是Tag,直接发送帧;
Protected Port
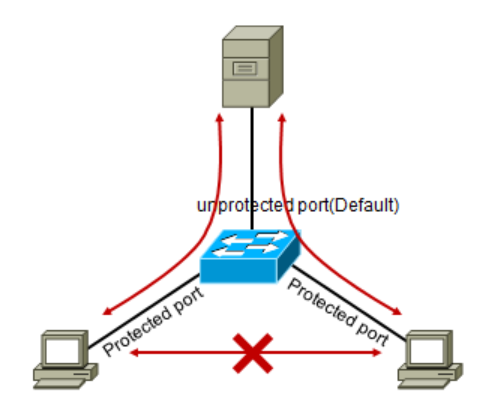
Protected Port虽然同处一个VLAN,但Protected Port接口之间彼此无法相互通信;
Protected Port智能与unprotected port(默认)互相通信;
Protected Port特性无法跨交换机实现;
将端口配置为Protected Port的命令为:
1 | switchport protected |
Trunk
概述
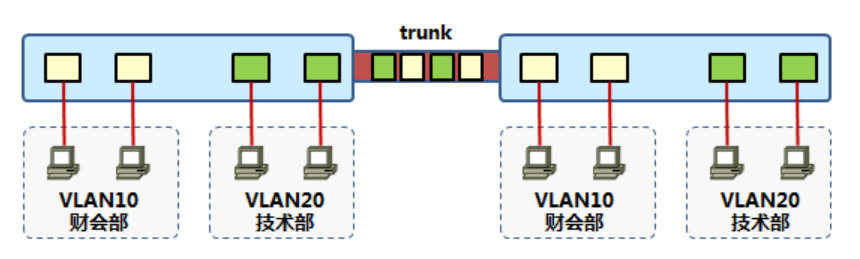
当一条链路,需要承载多VLAN信息时候,需使用trunk来实现;
Trunk两端的交换机需采用相同的干道协议;
一般见于交换机之间或交换机与路由器、服务器之间;
封装协议
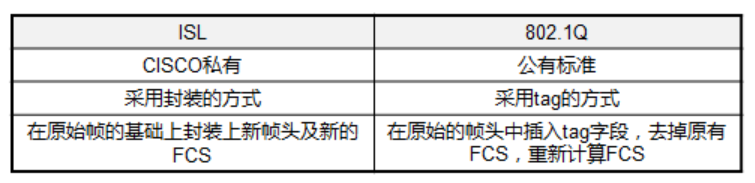
ISL是思科私有的VLAN封装协议,只有在全思科网络环境下才可能使用,但已经很少见到了,基本是DOT1Q(802.1Q)一统江湖,所以接下来不会涉及到ISL的知识。
对于那些大于1500字节但小于2000字节的帧,Dot1Q的MTU为1522。
DOT1Q的VLAN范围是1-4094个VLAN。
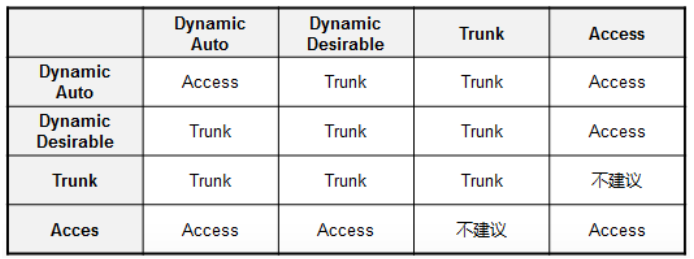
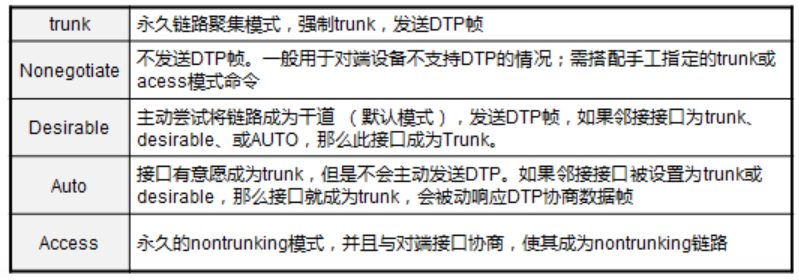
链路聚集模式:
Trunk:永久链路聚集模式,强制trunk,发送DTP帧;
Nonegotiate:永久链路聚集模式,必须手动将邻居配为干道,不发送DTP帧,一般用于对端设备不支持DTP的情况;
Desirable:主动尝试将链路设置成干道(Trunk,默认为该模式),发送DTP帧,如果邻接接口为Trunk\Desirable\AUTO,那么此接口成为Trunk;
Auto:接口愿意成为Trunk,如果临街接口设置为Trunk或Desirable,那么接口就成为Trunk;
Access:永久的Nontrunking模式,并且与对端接口协商,使其成为nontrunking链路;
Dot1Q
帧格式
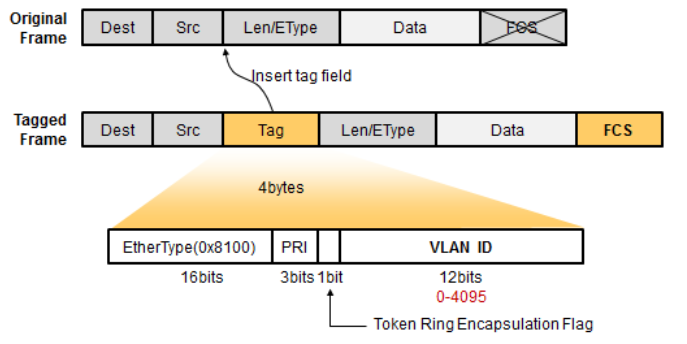
802.1Q(Dot1Q)为共有协议,默认情况下,在802.1Q Trunk上,对所有的VLAN打Tag,除了Native VLAN,交换机根据以太网帧头信息来转发数据包。
802.1Q Tag包含四个字段,含义如下:
EtherType:长度为2字节,表示帧类型,当取值为0X8100时表示802.1Q Tag帧,如果不支持802.1Q的设备收到EtherType为0X8100的帧,会将其丢掉;
PRI:Priority,长度为3比特,表示帧的优先级,取值范围为0-7,值越大优先级越高,用于当交换机阻塞时,优先发送优先级高的数据包;
CFI:Canonical Format Indicator,长度为1比特,表示MAC地址是否为经典格式,CFI为0时说明是经典格式,CFI为1时表示为非经典格式,用于区分以太网帧、FDDI(Fiber Distributed Digital Interface)帧和令牌环网帧。
VID,VLAN ID,长度为12比特,表示该帧所属的VLAN,在VRP中,可配置的VLAN ID取值范围为1-4096。
优缺点
缺点是破坏了原始以太网帧的格式而且要重新计算FCS。802.1Q支持4096个VLAN,最大帧长度为1518+4=1522。
Native Vlan
在802.1Q的Native vlan是不打标签的,使用Dot1Q的交换机把所有未标记的Frame转发到Native vlan中。
Native VLAN所属的帧在经过Trunk时不打标签;
Native VLAN在Trunk两端必须匹配,否则会出现VLAN流量互串;
默认的Native vlan是vlan 1;
为了安全起见,建议将一个生僻的非vlan1的vlan定位Native vlan;
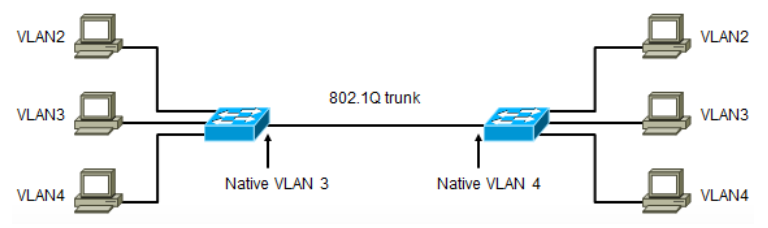
上面拓扑中,两台交换机Trunk 两端Native vlan不一样,会有什么问题?首先两端的vlan2通信肯定是没问题的:VLAN2的PC发出的数据,到达左边交换机以后会打上VLAN2的Tag,然后经过中间802.1Q的Trunk链路时,不会对数据进行改变,到达右边交换机时,由于数据有Tag,Trunk端口会判断该端口是否允许属于该VLAN的数据进入,答案是允许进入,因为右侧也有vlan2,然后交换机会根据数据帧的VLAN ID,属于vlan2,从属于VLAN2的端口发出,由于右边属于VLAN2的端口连接的是PC,因此该端口应该是Access端口,带有VLAN2 tag的数据从access口发出时,交换机会先剥离掉VLAN2的Tag,然后发送给PC,两端完成通信。
但两端属于VLAN3和VLAN4的PC通信就有问题了,先看VLAN3:从VLAN3的PC发出的数据帧到达左边交换机后,由于是Access接口,所以会打上VLAN3的Tag,然后从Trunk接口发出的时候,由于Native vlan是vlan3,Native vlan在通过trunk接口时不打标签,因此从trunk发出数据帧时,不带标签。这个不带标签的数据帧到达右侧交换机后,由于右侧交换机的Native vlan是vlan 4,交换机会认为该数据是属于vlan4的,通信就出现问题了。属于vlan4的PC通信也是类似情况。
Native vlan相关命令:
1 | 在Trunk接口上设置native vlan: |
vlan范围
| vlan范围 | 作用 |
|---|---|
| 0,4095 | 保留,系统使用 |
| 1 | cisco默认vlan |
| 2-1001 | for Ethernet Vlans给vlan使用 |
| 1002-1005 | Cisco默认为FDDI及Tokenring定义 |
| 1006-4094 | 只能为Ethernet使用,在一些特殊平台被保留使用 |
DTP
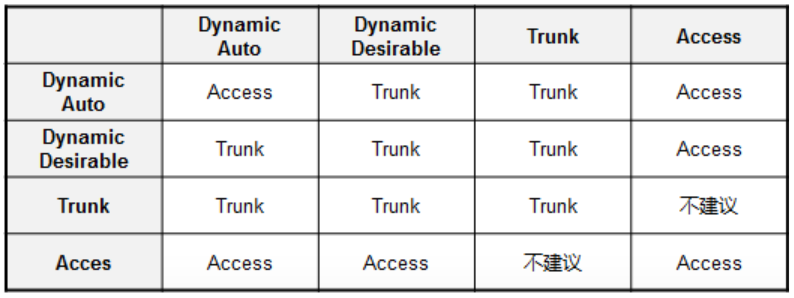
DTP全称为Dynamic Trunking Protocol,翻译成中文就是动态中继协议,是思科私有协议,用于协商两个支持VLAN的交换机之间链路上对的中继,以及用于协商要使用的中继封装的类型。Trunk可以通过手工静态配置或通过DTP协商而来,在实际配置Trunk链路时,为了避免出现问题,还是尽量直接手工配置(比如使用switchport mode trunk或switchport mode access),避免用DTP协商。
DTP协议通过DTP Message尝试帮助端口沟通并建立Trunk 链路,DTP有两个模式,分别是Desirable和Auto,简单来说Desirable就是主动模式,Auto就是被动模式,具体如下:
Trunk配置命令
1 | 将接口设置为Access模式: |

1 | SW1(config)# interface fast0/23 |
VTP
VTP的全称是Virtual Trunking Protocol,也是思科的私有协议,主要用于VLAN管理。在有VTP的情况下,在某一台交换机上配置完VLAN后,该所有的VLAN信息能够自动同步到其他所有交换机上,省去了很多配置。VTP共有三个版本,version1、2、3,其中version1和2在设计上有些缺陷,可能会让交换机的vlan出现灾难性的问题,比如可能所有交换机上的VLAN信息都被清除掉,所以尽量谨慎使用VTP协议。
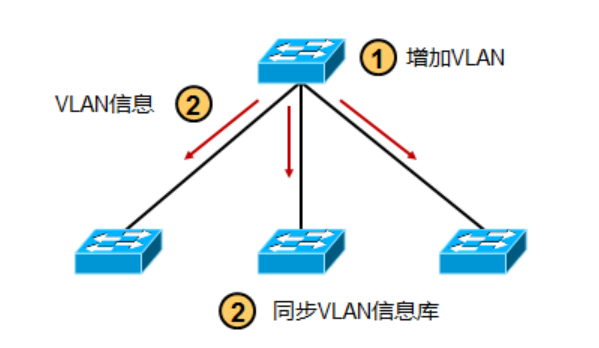
VTP类型

VTP的运作
VTP协议通过组播地址0100-0CCC-CCCC在Trunk链路上发送VTP公告;
VTP Server和Client以修订号作为同步的基础,会将修订号最高的信息同步到自身设备上;
VTP协议每隔5分钟发送一次VTP通告或在有变化发生时通告;
VTP配置
1 | 配置VTP域名 |
VTP的问题
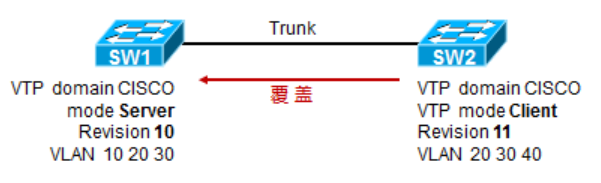
两台交换机,如果VTP Client的配置修订号(Revision11)比Server的高,那么Client也是能够将Server的vlan信息覆盖的,这种情况下可能会出现问题,比如一台新接入网络的交换机,之前的vlan信息没有清除,配置修订号比现网使用的其他交换机的配置修订号高,此时它就会将现网中原本配置好的vlan信息冲掉,造成灾难性的后果。

上图中Server及Client的配置修订号相同,但vlan信息则不同,这时会报错,提示md5 digest checksum mismatch。
VTP Pruning
VTP Pruning中文翻译成VTP修剪,VTP协议能确保处于VTP域中的所有交换机都能拥有所有的VLAN信息,但有些时候,VTP会制造一些不必要的流量,那些无用流量会充斥着整个网络:
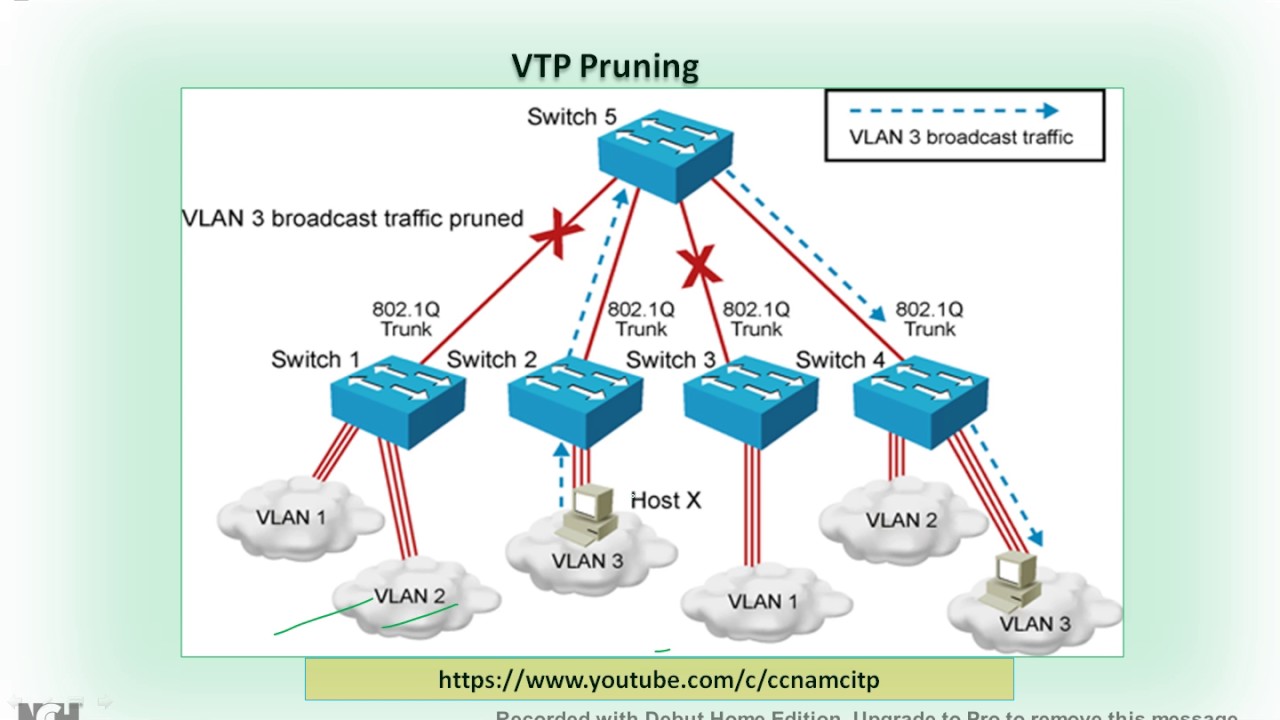
比如上图的拓扑中,Switch1中只有VLAN1和VLAN2,经过修剪后,VLAN3的流量就不会在Switch1上出现,被修剪了,减少了不必要的流量。
VTP的配置非常简单,只需在VTP Server中输入‘vtp pruning’即可自动搞定,整个VTP domain中的交换机都会自动激活该功能。
MTU
MTU全称是Maximum Transmission Unit,中文翻译为最大传输单元,在思科IOS上,interface X接口模式下:
- MTU ?:指的是二层的MTU,是接口MTU,指的是不含二层帧头的、Payload的MTU,整个MTU一般是不能手工修改的,这个相当于Juniper的Default IP MTU,Default IP MTU(1500字节)=TCP Header(20字节)+IP Header(20字节)+TCP Segment Length(1460字节)。这样一来,思科路由器支持的二层数据帧最大值就是1500的Payload加上二层帧头及二层FCS:目的MAC地址(6字节)+源MAC地址(6字节)+类型字段(2字节)+FCS(4字节),所以总数是1518字节。相当于Juniper的Default Media MTU[1518字节,1500 (Default IP MTU) + 14(encapsulation overhead,6字节的目的MAC+6字节的源MAC+2字节的帧类型)]但不包含FCS部分(4字节)。
- IP MTU?:指的是三层的MTU,这个值可以手工修改,但最大值必须小于接口的二层MTU值,也就是要小于1500,这个MTU指的是三层IP包的总大小,如果接口发出的包大于这个接口的IP MTU则这个IP包将被分片。

比如上图中,R1的F0/0接口的IP MTU为1500,现在去ping 1.1.1.2 repeat 1 size 1500,会发现R1直接将一个ICMP包发出去了,没有分片,报文如下:
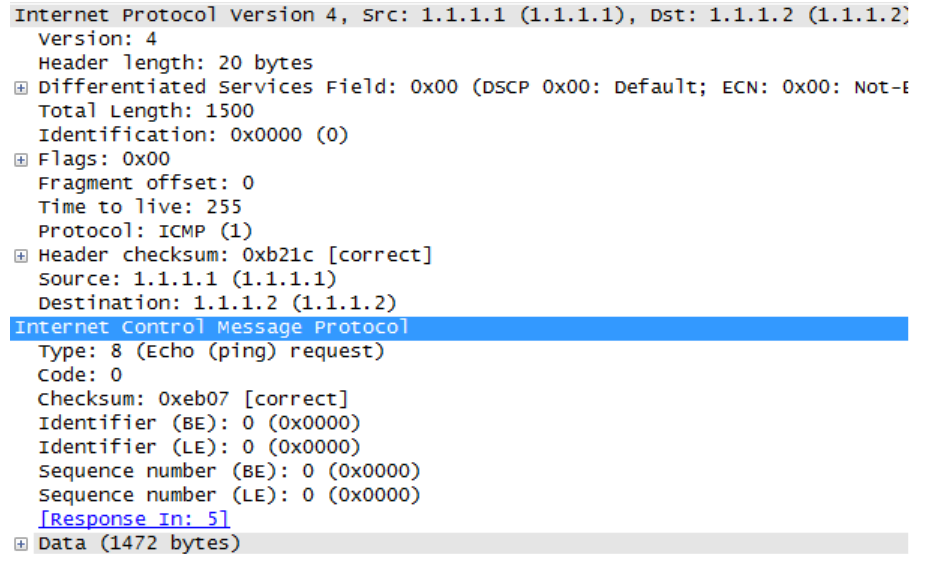
从报文中可以看到,IP包的大小为1500字节。其中IP报头20字节,ICMP报头8字节,ICMP Data 载荷1472字节,刚好1500字节,因此在思科IOS设备上,ping 后面跟着的size指的就是发出去的IP包整个大小。如果在R1上ping 1.1.1.2 repeat 1 size 1501,则由于这个IP包大于MTU1500,会被分片,然后在R2上这两个分片被重组。
Trunk VS Access

私有VLAN
基本概念
私有VLAN全称是Private VLAN,中文是私有VLAN;
将一个VLAN划分成几个单独的VLAN,这些VLAN都是用同一个IP网段;
可以提高安全性,降低子网数量,提高IP利用率;
尽管网络设备处于同一个子网中,但它们属于不同的Pvlan,Pvlan之间的通信还是必须通过默认网关来实现;
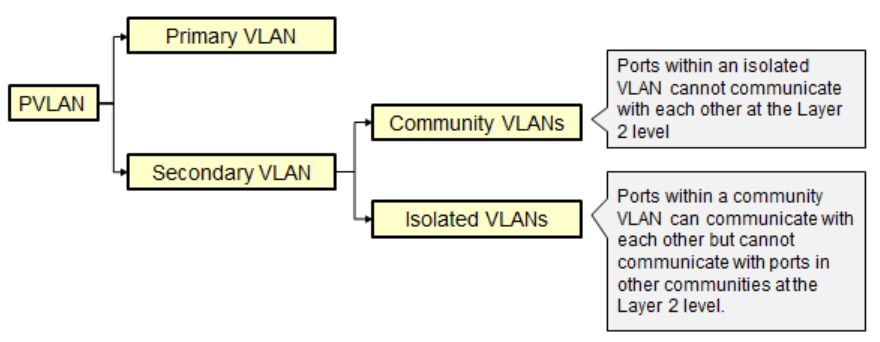
每个Pvlan包括一个主VLAN以及多个辅助VLAN。所有的辅助VLAN都映射到主VLAN;
辅助VLAN分为团体VLAN和隔离VLAN;
相同的团体VLAN能够相互通信,但是团体VLAN之间必须通过设置SVI或者路由器接口才能通信,也就是要通过三层才能通信;
相同的隔离VLAN内部以及隔离VLAN之间都是不能够相互通信的,只能与混杂接口通信;
一个主VLAN只能有一个Isolate VLAN;
混杂端口能够与Pvlan中的任何设备通信,不管对方是处于主VLAN还是辅助VLAN;
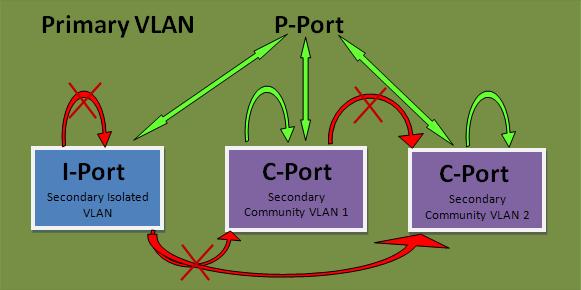
PVLAN端口类型
Isolated:中文翻译为隔离端口,隔离端口只能与混杂端口通信,不能与其他类型端口通信;
Promiscuous:中文翻译为混杂端口,可以和所有类型的端口通信;
Community:中文翻译为公共端口,与公共vlan相关的任何交换机端口都可以相互通信,并与混杂端口通信;
注意事项
Pvlan必须配置在透明模式的交换机上,禁止将第三层的VLAN接口配置为辅助VLAN,VTP并不支持Pvlan,所以必须手动在各个交换机上配置VLAN信息。
Pvlan配置命令
1 | 创建主VLAN |
实验
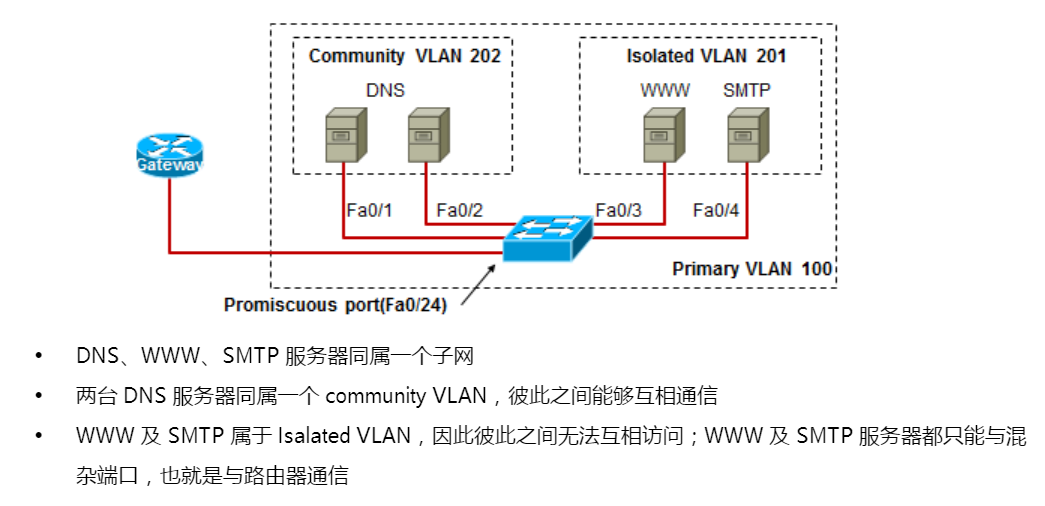
1 | sw(config)#vtp transparent |
Spanning-tree
协议概述
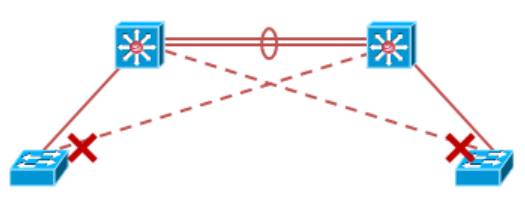
如果接入层交换机单链路上联,会存在单点故障,如果任意一个汇聚交换设备宕机,将直接导致下联的接入层网络挂掉;
如果接入层交换机采取双链路上联到两台汇聚设备,构成一个物理链路冗余的二层环境,可以解决单链路故障问题,但二层存在环路问题;
生成树可以解决二层环路问题,通过生成树协议,在逻辑上将特定的端口Block,从而实现物理上存在冗余链路,而二层上又组织环路的产生;
当拓扑发生变化的时候,生成树协议能够探测到这些变化,并且及时自动的调整接口状态,从而适应网络拓扑的变化,实现链路冗余;
协议基础
生成树种类
| 协议 | 共有or私有 | 别称 | 描述 |
|---|---|---|---|
| STP(PVST) | 公有 | 802.1 D | |
| PVST+ | 思科私有协议 | 包含了Portfast、uplinkfast、Backbonefast特性 | |
| RSTP | 公有 | 802.1 W | 集成了PVST的功能并公有化 |
| MST | 公有 | 802.1 S |
BPDU结构及参数
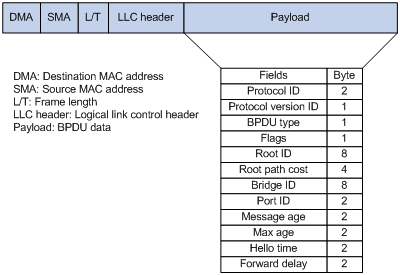
BPDU全称为Bridge Protocol Data Units,翻译成中文是网桥协议数据单元,里面包含了有关生成树协议的帧。也就是交换机用来在彼此之间传输STP信息的帧,一个网络中应该只有Root交换机(根交换机)发送BPDU,不过当交换机刚启动时,它会认为自己试根交换机,而发送BPDU,知道它收到一个包含Bridge ID较小的BPDU,才知道自己在Root switch的选举中失利而停止发送BPDU。BPDU默认2秒发送一次,接收到的BPDU会被存储20秒(Max-age),也就是说如果交换机超过20秒没收到BPDU,就会判断Root交换机已经挂掉,会再次认为它自己试Root交换机,再次发送BPDU。
Root ID:网桥ID,长度8字节,由网桥优先级(2字节)+网桥MAC(6字节)构成,缺省优先级为32768,取值范围从0-65535,前4bit表示优先级,后8bit作为system ID,为协议扩展使用,越小越优,取值是4096的倍数。
Port ID:端口ID,长度2字节,由端口优先级(1字节)+端口ID(1字节)组成,缺省优先级为128,组织范围从0-255,越小越优。思科交换机端口ID中的优先级默认为128(优先级8bit)。
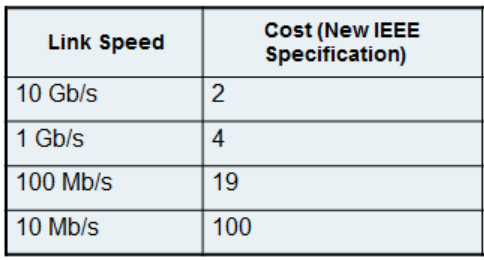
Cost:路径开销,表示从本交换机到达根交换机路径的总开销,越小越优,和端口带宽有关:
802.1D协议
基础知识
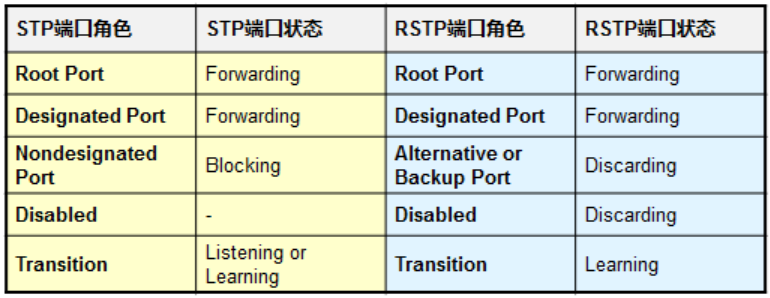
端口类型
根端口(RP,Root Port):对象是非根设备,每个非根设备有且仅有一个,除了根以外,离根最近的端口,用来接收来自根交换机的BPDU;
指定端口(DP,Designated Port):每条链路上有且仅有一个DP。离根最近,也就是cost最小,用来发送BPDU。一般来说根交换机的端口都是DP,因为离根最近且用来发送BPDU。
非制定端口(None Designated Port):每个环形拓扑有且仅有一个,用来阻塞数据防止环路。
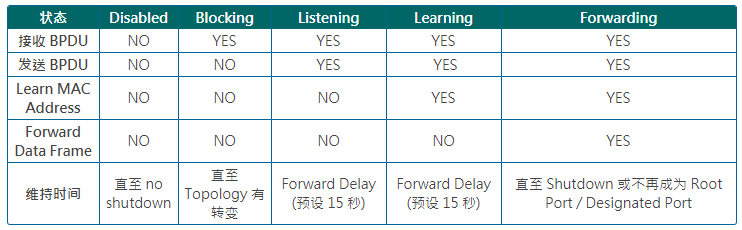
端口状态
| 状态 | 说明 |
|---|---|
| Disable | 无效连接,忽略所有接收到的数据包 |
| Block | 仅接收BPDU数据包 |
| Listen | 接收及传送BPDU数据包 |
| Learn | 接收、发送BPDU数据包,并且学习MAC地址 |
| Forward | 接收、发送BPDU数据包,学习MAC地址,发送数据 |
选举规则
简单版:根桥ID、根路径开销、发送者BID、发送接口BID,越小越优先;
具体版:选举根交换机(Root Switch)、选举根端口(Root Port)、选举指定端口(Designated Port),具体参见后文‘STP的运行’部分。
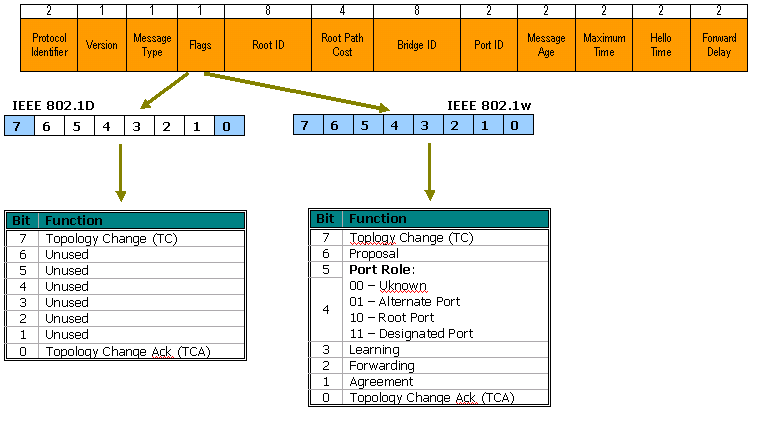
BPDU报文
BPDU有两种类型,配置BPDU以及TCN BPDU,由于交换机在一开始又叫网桥,所以字段中的Bridge其实指代的就是交换机。在网络收敛后的正常情况下,交换机只会从它的Root Port上收到配置BPDU,但绝对不会主动发送配置BPDU给根交换机。
报文格式
配置BPDU
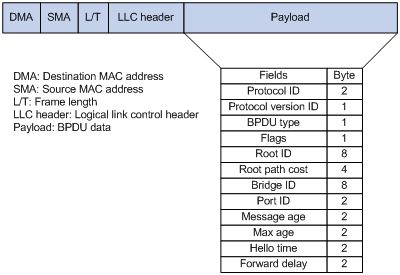
| 字节 | 字段 | 描述 |
|---|---|---|
| 2 | 协议Protocol ID | 代表上层协议,BPDU,当协议为802.1D时该值总为0 |
| 1 | 版本Protocol Version ID | 802.1D的该值总为0 |
| 1 | BPDU种类BPDU Type | 配置BPDU值为0X00,TCN BPDU值为0X80 |
| 1 | 标志Flags | Flags位有两种可能:Topology change(TC)位,表示在通往根桥的路径被中断了。此时由根交换机TC位置1的配置BPDU,通告下游交换机链路发生了变化,涉及的交换机如何在端口上进行相应的改变;Topology change acknowledge(TCA)位,当该位置1时,表示确认收到了TC位置1的配置BPDU; |
| 8 | 根IDRoot ID | 根ID字段会列出2字节的优先级以及6字节的MAC地址ID来表示根桥。当交换机刚启动的时候,这个字段和交换机的根桥ID相同,因为一开始生成树协议还未选举完毕,每台交换机都认为自己就是根桥,随着选举的完毕,最低根桥ID将取代本地根桥ID,以识别根交换机。 |
| 4 | 路径开销Root Path Cost | 路径开销,表示从本交换机发送配置信息到根桥的开销,每台交换机的路径开销都不同。 |
| 8 | 网桥IDBridge ID | 网桥ID包含着本设备网桥优先级和MAC地址ID。这个字段可以让根交换机了解BPDU的来源,也可以用来识别从交换机到跟交换机的多条路径。当跟交换机从其他交换机收到多条不同路径开销的BPDU时,它会知道有两条不同的路径并使用开销较低的那条。 |
| 2 | 端口IDPort ID | 端口ID表示发送生成树相关信息的端口号,这个字段允许检测和纠正交换机产生的环路。(优先级+端口号) |
| 2 | 消息寿命Message age | 从根桥发出BPDU之后的秒数,代表着这个BPDU存活了多长时间,每经过一个网桥都减1,所以它本质上是到达根交换机的跳数。 |
| 2 | 最大寿命Max age | 当一段时间内未收到任何BPDU,生存时间到达MAX Age时,交换机会认为该端口连接的链路发生故障,也可以理解为这个BPDU的最大寿命,默认时间为20秒。 |
| 2 | Hello时间Hello Time | 根交换机发送BPDU之间的间隔时间,默认为2秒。 |
| 2 | 转发延迟Forward Delay | 在监听和学习状态所停留的时间间隔。默认15秒。 |
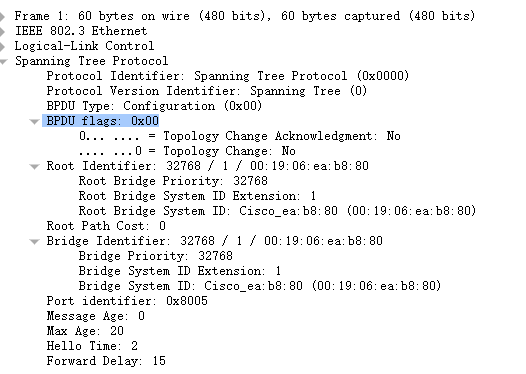
如果英文还不错可以到这个网页看一下,老外做了一个BPDU每个字段的解释以及抓包的页面,很详细。
TCN BPDU
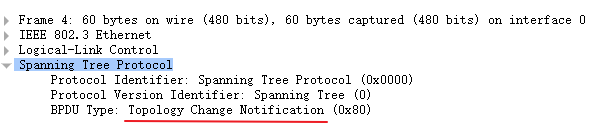
Configuration BPDUs -are originated by the Root Bridge and flow outward along the active paths that radiate away from the Root Bridge.
Topology Change Notification BPDUs - flow upstream (toward the Root Bridge) to alert the Root Bridge that the active topology has changed.
Type - Determines which of the two BPDU formats the frame contains (Configuration BPDU or TCN BPDU).
Type of BPDU can be one of the following
0x00 (Binary: 0000 0000) Configuration BPDU
0x80 (Binary: 1000 0000) Topology Change Notification (TCN) BPDU
Robert, A non root switch originates a TCN BPDU in two conditions:
=It transitions a port into the Forwarding state and it has at least one Designated Port.
=It transitions a port from either the Forwarding or Learning states to the Blocking state.
These situations construe a change in the active topology and require notification be sent to the Root Bridge. Assuming that the current bridge is not the Root Bridge, the current bridge begins this notification process by sending TCN BPDU out its Root Port. It continues sending the TCN BPDU every Hello Time interval seconds until the TCN message is acknowledged
Now the second part of the question :
Difference between TC message type and TC flag
Flags- are Used to handle changes in the active topology and is a field of COnfig BPDU
Flags can be :
LSB = Topology Change (TC) flag
MSB = Topology Change Acknowledgment (TCA) flag
In a nutshell, the FLAG is set to Topology Change (TC) by the Root Bridge/Switch to notify the downstream bridges/switches who are involved and need to know regarding the change.
https://community.cisco.com/t5/switching/bpdu-message-types-and-flags/td-p/1004067
The designated bridge acknowledges the TCN by immediately sending back a normal configuration BPDU with the topology change acknowledgement (TCA) bit set
https://community.cisco.com/t5/switching/tcn-acknowlegement-in-stp/td-p/2390425
配置BPDU
配置BPDU用来在交换机之间交换配置信息,用于生成树协议的计算,比如选举根交换机、DP或RP接口等,每隔两秒发送一次(Hellotime字段),以组播形式发送到01:80:C2:00:00:00这个地址,在DP上发送。
在网络刚开始运行,生成树进行初始化的时候,所有的交换机都会从所有的端口上发送配置BPDU,所有的交换机都会认为自己是根交换机,随着配置BPDU的泛洪和收集,根据BPDU中所包含的信息,所有交换机PK出来个结果,Root交换机被选出来了。在此之后Root以默认的2秒为周期发送BPDU,所有的非Root交换机从自己的根端口收到BPDU,再从自己的指定端口产生BPDU发出,有点像我们从Root倒一盆水下来,水顺着这颗无环的树,从上往下不断的流,另外被Block的非制定端口会源源不断的收到连路上的BPDU并一直监听,当其在一定时间内没有再收到BPDU,则认为链路出现了故障,开始进入了新的收敛阶段。
“When a switch receives a configuration BPDU that contains superior information (lower bridge ID, lower path cost, and so forth), it stores the information for that port. If this BPDU is received on the root port of the switch, the switch also forwards it with an updated message to all attached LANs for which it is the designated switch.
If a switch receives a configuration BPDU that contains inferior information to that currently stored for that port, it discards the BPDU. If the switch is a designated switch for the LAN from which the inferior BPDU was received, it sends that LAN a BPDU containing the up-to-date information stored for that port. In this way, inferior information is discarded, and superior information is propagated on the network.”
当交换机收到一个包含着更优信息(更低的根桥ID,更少的路径开销或者其他)的配置BPDU后,交换机会储存该端口的信息,如果这个BPDU是从根端口上收到的,交换机还会将那个更优的BPDU信息,由DP端口(Designated port指定端口)通过update信息发送给其他连接的交换机。
如果交换机收到的配置BPDU比它自身存储的BPDU更差,它会丢弃收到的BPDU。如果交换机收到更差的BPDU的接口为DP,那么它还会通过该DP端口将更优的BPDU发送出去,这样一来较差的BPDU信息被丢弃而更优的BPDU会在网络上传播开。
TCN BPDU
TCN BPDU在网络拓扑变化时产生。Type字段为0X80。
当网络拓扑发生变化的时候,最先意识到变化的交换机会从根端口发送TCN(Type字段为0X80)到上一层交换机(朝向根交换机的方向),然后一直到根交换机,用来警告根交换机,拓扑发生了变化。
一台非根桥交换机会在两种情况下发送TCN BPDU:
- 当这台交换机的一个接口进入转发状态,而且它至少有一个DP口时;
- 当这台交换机的一个接口从转发或学习状态进入封闭状态;
以上这两种情况说明拓扑发生了变更,并且需要让根桥知道。
STP的运行
总体步骤
STP采用四步来解决二层环路问题:
在一个交换网络中选举出一个Root Bridge,也就是选举出一个根交换机;
在每个非交换机上,选举出一个根端口(RP,Root Port);
为每个网段选举一个指定端口(DP,Designated Port);
阻塞非指定端口;
比较原则
STP需要网络设备互相交换信息来检测桥接环路,该消息就是之前说过的BPDU,网桥协议数据单元,阻塞端口也会不断收到BPDU,以保证故障发生的时候,仍然可以计算出一颗新的STP生成树。要理解STP工作的过程,非常重要的一点是要理解BPDU中各字段的含义,因为这些都是STP赖以工作的根本。
生成树构造一个无环路拓扑时,总是使用相同的四步来判定:
最低根桥ID,交换机根桥ID由优先级+MAC地址构成,先比较优先级后比较MAC地址;
到根桥的最低路径成本;
最低的发送者网桥ID;
最低的发送者端口ID;
交换机使用这四步来保存各个端口收到最佳的BPDU的一个副本,每个BPDU到达时,都会按照这四步来进行检查,看收到的BPDU和端口保存的BPDU哪个更优,如果收到的BPDU更优,则会更新端口保存的BPDU。
当一个交换机开始工作后,它的每个端口都是每2秒发送一个BPDU(BPDU中的Hello time字段),当一个端口收到一个比现在发送的更优的BPDU时,本地端口会停止发送,如果在一段时间内(默认为20秒,Forward Delay字段)后它不再收到来自邻居的更优的BPDU,则它将会再次发送自己的BPDU。因此对于802.1D来说,根桥会不停的向所有接口发送BPDU,而非根桥会从自己的根端口收到BPDU,并且从自己的指定端口发送该BPDU,非指定端口是不会发送BPDU的,只会监听。
注意事项
根桥的角色是可抢占的;
桥ID中的MAC,是交换机的背板MAC,端口ID中的MAC是交换机的端口MAC,查看交换机上的所有Mac,可以用命令‘show interface | include bia’;
二层交换机的端口MAC就是在这里使用的;
案例分析
案例1
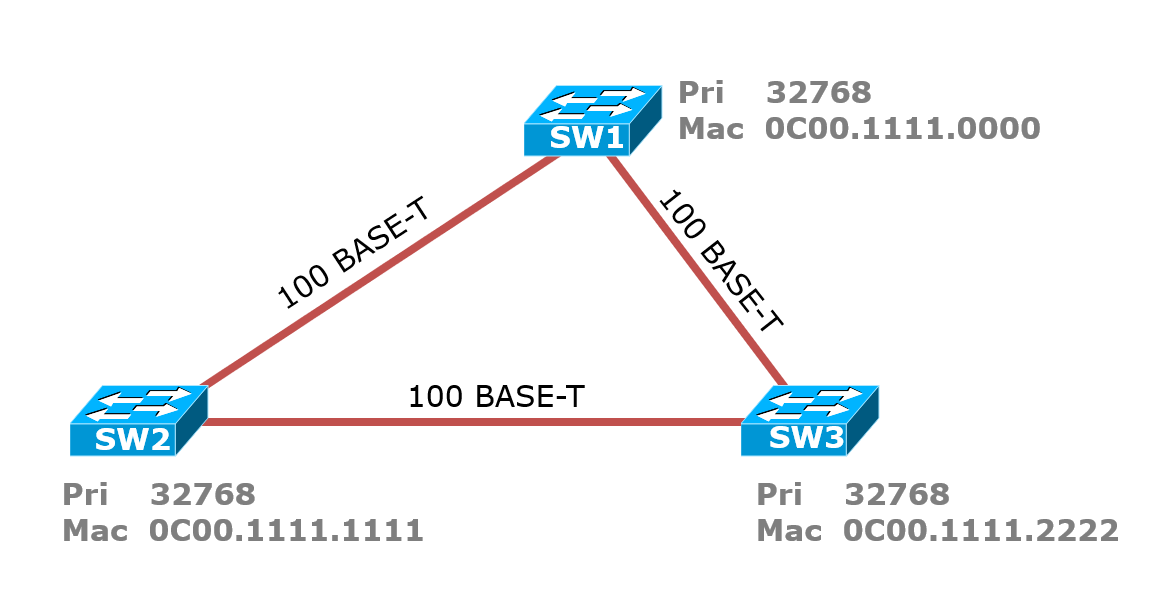
选举Root根桥:先比较优先级,优先级都是32768相同,所以比较MAC地址,从左往右一位一位的比较MAC地址,最小的0C00.1111.0000胜出,所以SW1为根桥;
选举RP根端口:所有的非根交换机上都要选择出一个根端口,根端口就是离根桥最近的开销最小的端口,用于接收BPDU信息,由于SW1是根端口,所以SW2、SW3和SW1相连的端口是RP;百兆链路的开销为19,SW2和SW1相连的端口开销为19,SW2和SW3相连的接口开销为19+19=38,所以SW2上联SW1的接口为根端口;
选举DP指定端口:每一个网段上都有一个DP,指定端口就是cost最小,用来发送BPDU的端口,一般来说根桥的端口都是根端口,因为根桥的BPDU最优,需要往外发送自身的BPDU,所以SW1上的两个端口为DP;SW2和SW3之间的链路上,谁是DP呢?最低根桥ID相同,因为根桥ID都是SW1的BPDU,相同,这时这两个端口到达根交换机的开销相同,所以比较发送BPDU交换机的ID,也就是比较优先级-MAC地址,优先级相同,MAC地址小的SW2胜出,所以SW2上和SW3相连的接口为DP。
选举非指定端口:SW3上和SW2相连的接口既不是DP也不是RP,所以是非指定端口,被Block掉;
结果为:
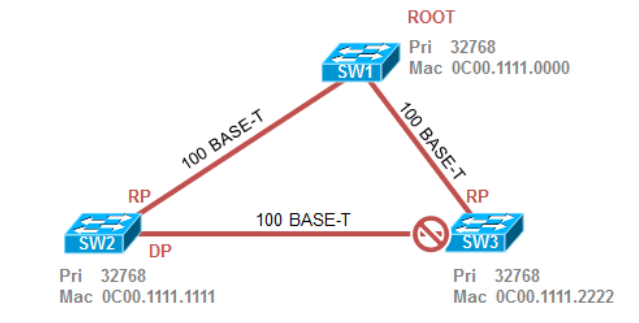
案例2
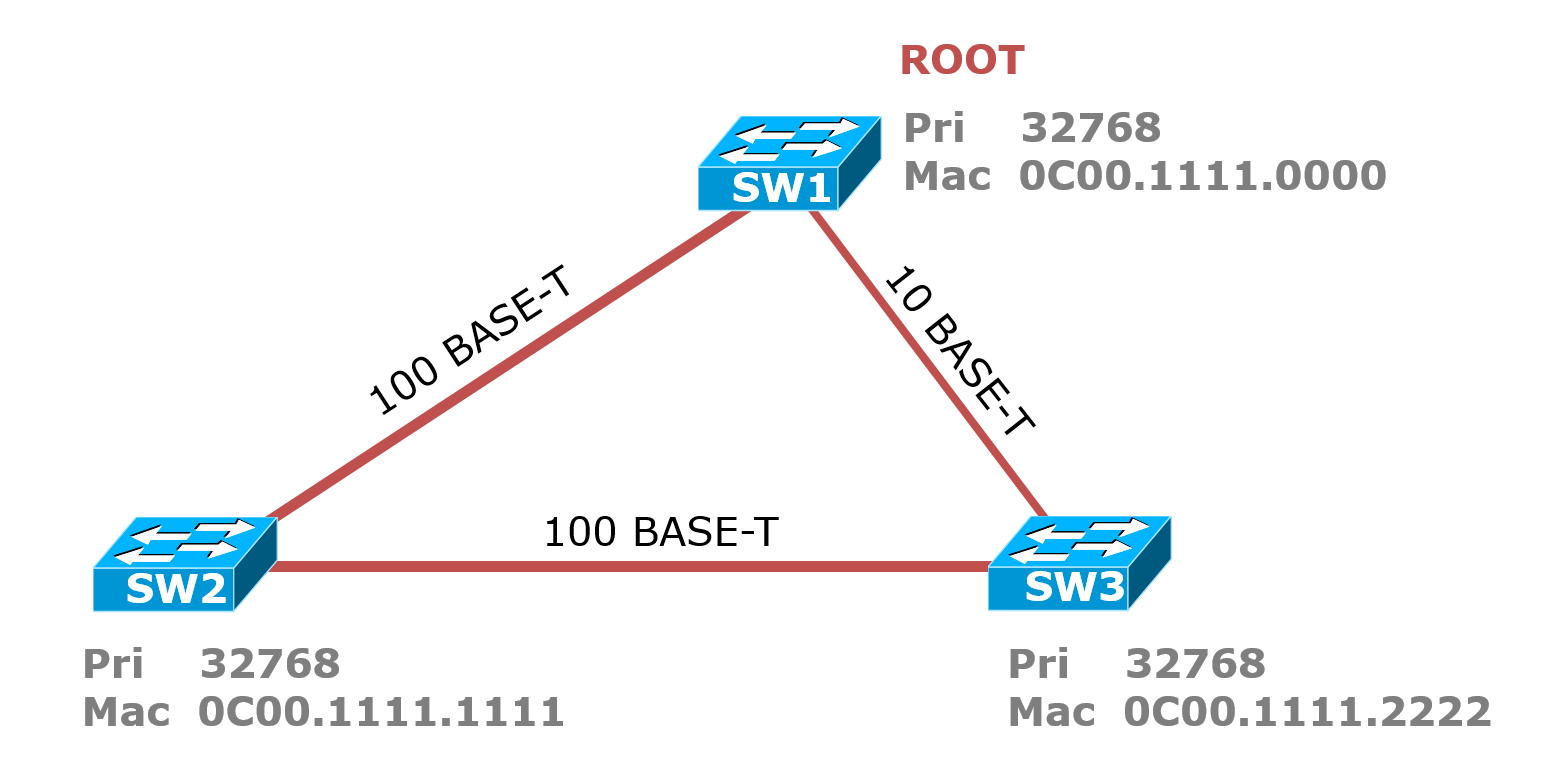
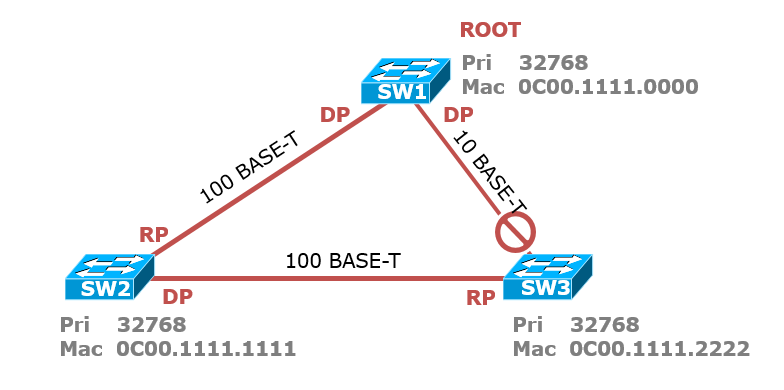
选举Root根桥:先比较优先级,优先级都是32768相同,所以比较MAC地址,从左往右一位一位的比较MAC地址,最小的0C00.1111.0000胜出,所以SW1为根桥;
选举RP根端口:所有的非根交换机上都要选择出一个根端口,根端口就是离根桥最近的开销最小的端口,用于接收BPDU信息,首先看开销,100兆链路的开销为19,10兆的开销为100,所以SW2与SW1连接的接口开销为19,而SW2和SW3连接接口的开销为19+100=119,因此SW2和SW1连接的接口为RP,因为开销最小;SW3上的RP接口为SW2和SW3连接的接口,开销为19+19=38,小于SW3和SW1接口开销的100。
选举DP指定端口:每一个网段上都有一个DP,指定端口就是cost最小,用来发送BPDU的端口,一般来说根桥的端口都是根端口,因为根桥的BPDU最优,需要往外发送自身的BPDU,所以SW1上的两个端口为DP;SW2和SW3之间的链路,左边SW2的接口为DP,因为每条链路上都要有一个DP。
选举非指定端口:SW3上和SW1相连的接口既不是DP也不是RP,所以是非指定端口,被Block掉;
结果为:
案例3
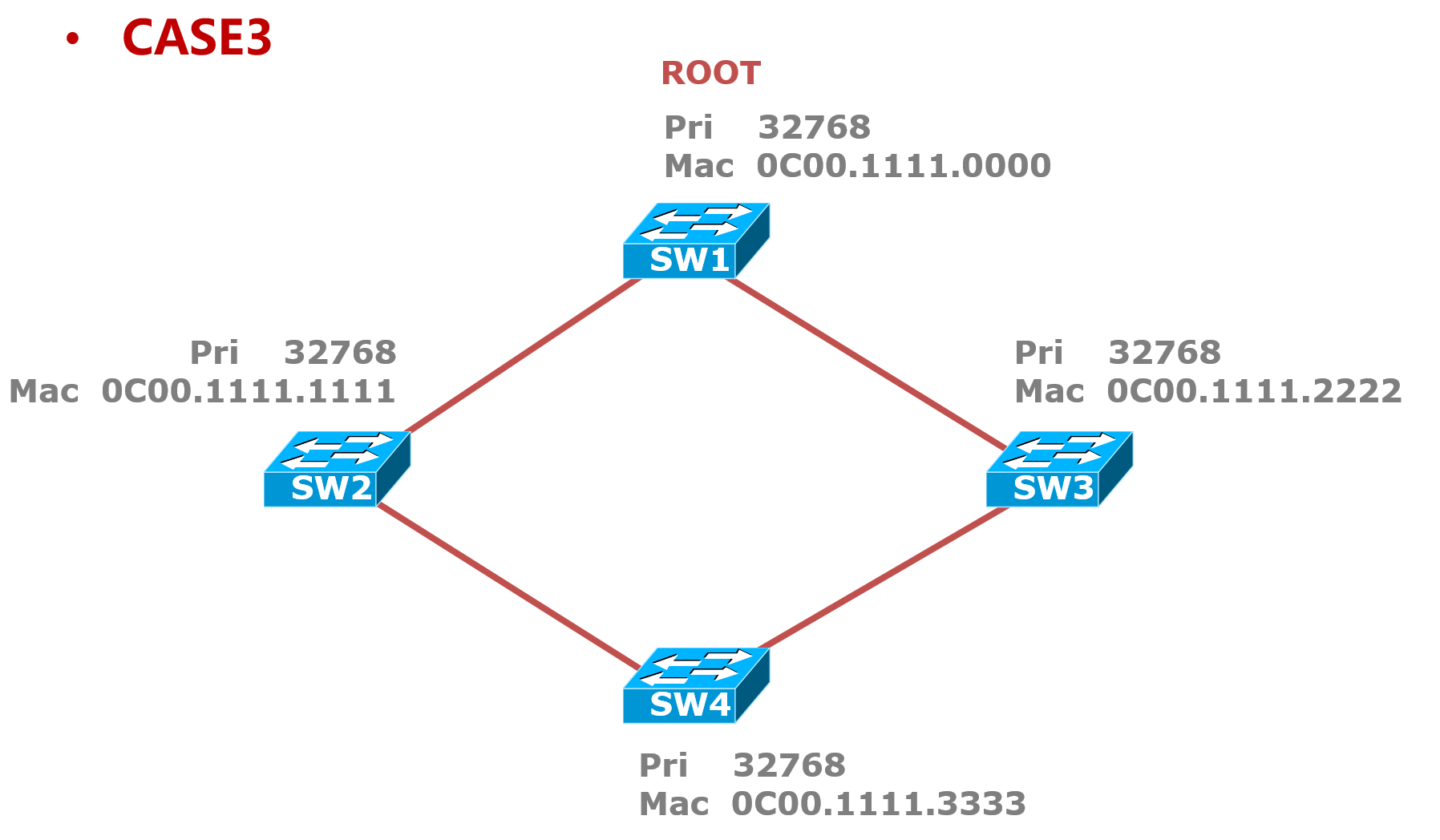
选举Root根桥:先比较优先级,优先级都是32768相同,所以比较MAC地址,从左往右一位一位的比较MAC地址,最小的0C00.1111.0000胜出,所以SW1为根桥;
选举RP根端口:所有的非根交换机上都要选择出一个根端口,根端口就是离根桥最近的开销最小的端口,用于接收BPDU信息,首先看开销,假设每条链路都是100兆开销为19,10兆的开销为100,SW2和SW1连接的端口,SW3和SW1连接的端口均为RP,因为上面的端口相比下面的端口来说离根桥最近;接下来看SW4上哪个端口是RP,SW4上两个端口的开销都是19+19=38,相同,所以比较下一个属性,发送者网桥ID,发送者网桥ID由优先级+MAC地址构成,优先级相同而SW2的MAC地址更小,所以SW4左边接口的发送者网桥ID更优,因此SW4左边的接口为RP。
选举DP指定端口:每一个网段上都有一个DP,指定端口就是cost最小,用来发送BPDU的端口,一般来说根桥的端口都是根端口,因为根桥的BPDU最优,需要往外发送自身的BPDU,所以SW1上的两个端口为DP;SW2下连SW4的接口为DP,因为每条链路上都有一个DP;SW3和SW4之间的链路谁是DP呢?首先看开销,SW4接口开销为19+19=38,而SW3和SW4相连的接口开销为19,所以SW3上的接口为DP。
选举非指定端口:SW4上和SW3相连的接口既不是DP也不是RP,所以是非指定端口,被Block掉;
结果为:
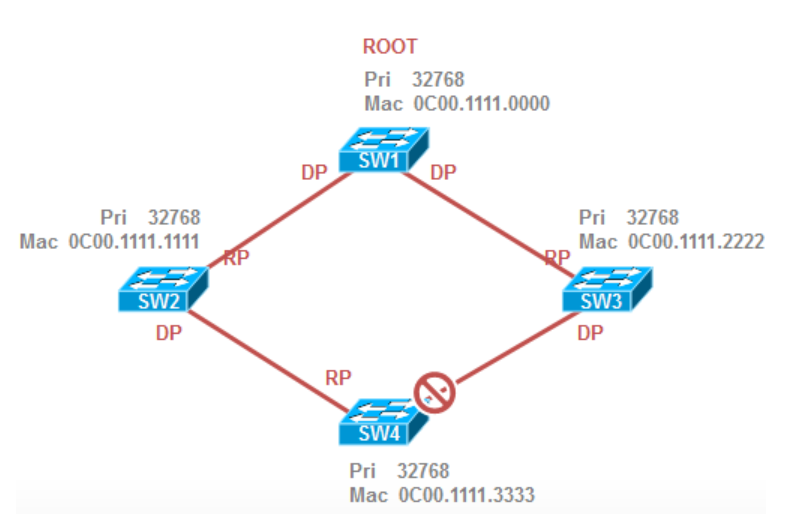
案例4
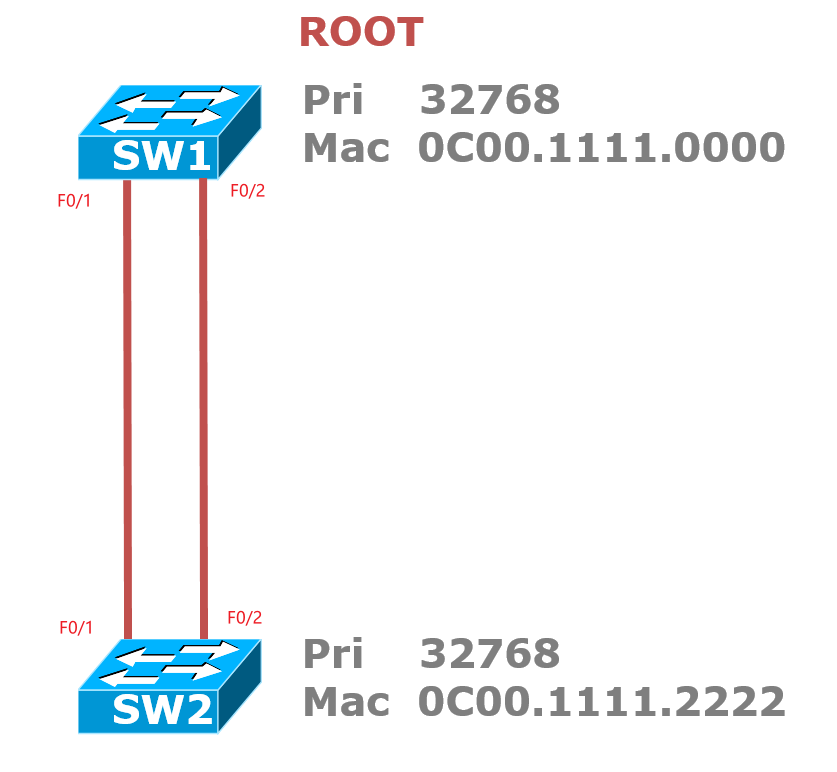
选举RP根端口:所有的非根交换机上都要选择出一个根端口,根端口就是离根桥最近的开销最小的端口,用于接收BPDU信息,首先看开销,由于两条链路到根桥的开销相同,所以比较下一项,发送者网桥ID,但由于发送者网桥ID也都是SW1的网桥ID,依旧相同,所以比较下一项,发送端口ID(由端口优先级+端口ID构成),假设两个接口优先级相同,接下来就要比较端口ID了,最终F0/1的端口ID更小,因此SW2的F0/1接口为RP。
选举DP指定端口:每一个网段上都有一个DP,指定端口就是cost最小,用来发送BPDU的端口,一般来说根桥的端口都是根端口,因为根桥的BPDU最优,需要往外发送自身的BPDU,所以SW1上的两个端口为DP。
选举非指定端口:SW2的F0/2既不是DP也不是RP,所以是非指定端口,被Block掉;
注意,此时如果试图在SW2上将F0/2的接口优先级调小并没有用,因为看的是发送者的端口ID,也就是SW1的两个端口的ID,只有在SW1上将F0/2的端口优先级调小,SW2上的F0/2才会胜出称为根端口。
结果为:
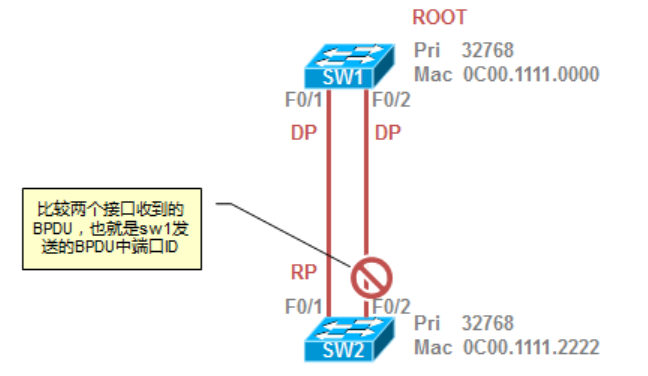
STP端口状态
由于网络设备存在固有的滞后,所以交换网络中也就存在传播延迟,基于上述原因,拓扑变更可能发生在网络中的不同时间和不同网段。如果二层接口直接从生成树的Block状态切换到转发状态,就可能会出现暂时的数据环路。为了缓解这种问题,在开始转发数据帧之前,端口应当等待新的拓扑信息传播到整个交换网络中。
接口状态

端口计时器
Hello时间:根桥发送配置BPDU的时间间隔,默认为2秒;
转发延迟时间:从侦听到学习状态或学习状态到转发状态所需要的时间,默认为15秒;
最大存活期:在丢弃BPDU之前,网桥用来存储BPDU的时间,缺省为20秒,也就是连续收不到10个BPDU,开始进入Listening状态;
网络中生成树拓扑依附于根桥的计时器,根交换机将BPDU中的计时器传递给二层所有的其他交换机。
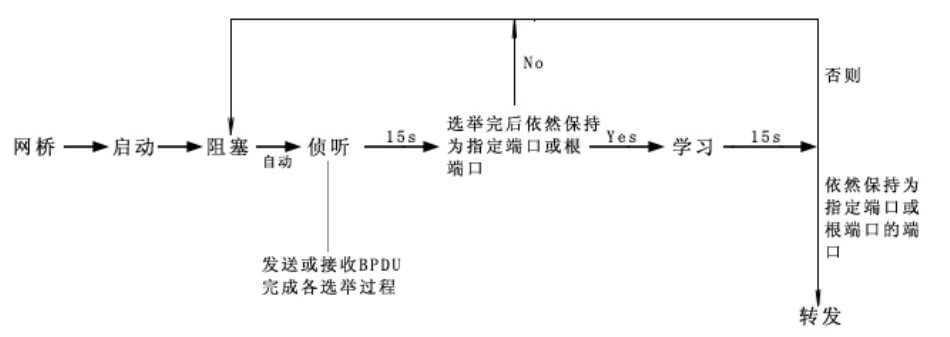
从阻塞到转发状态通常要转发状态通常要30-50秒,默认50秒,即20+15+15,也就是20秒的最大存活期内收不到BPDU,认为链路发生了问题,然后端口进入侦听状态,侦听状态15秒到学习状态,再一个15秒由学习状态到转发状态。
端口切换过程
STP拓扑变更
TCN BPDU概述
当网络拓扑出现变更的时候,最先意识到变化的交换机将发送TCN BPDU。
在发生在以下时机时,交换机发送TCN BPDU:
对于处于转发和监听状态的接口,过渡到Block状态,也就是链路发生故障的情况;
端口进入转发状态,并且网桥已经拥有指定端口;
非根桥交换机在它的指定端口(DP)收到TCN;
TCN BPDU
TCN BPDU包含3个字段,它与配置BPDU除了Type字段之外的前三个字段完全相同。
拓扑变更过程
最先意识到拓扑变更的交换机发送TCN BPDU,发送的方向是根桥方向,指定网桥收到TCN并且立刻回送一个TCA被置位的正常BPDU来确认收到了表示拓扑变化的TCN BPDU。在该网桥确认这个TCN之前,负责通知拓扑变更的网桥将持续发送TCN BPDU。
接下来该指定网桥将为自己的根端口产生另外的TCN,从RP发出给上游更靠近根交换机的其他交换机,并且这个过程一路持续发到根交换机为止。
一旦根桥意识到网络中发生拓扑变更的情况,它将发送TC被置位的BPDU,网络中每台交换机都将传递这些被置位的BPDU,进而便于每个单独的网桥都意识到拓扑变更的情况。
拓扑变更示例
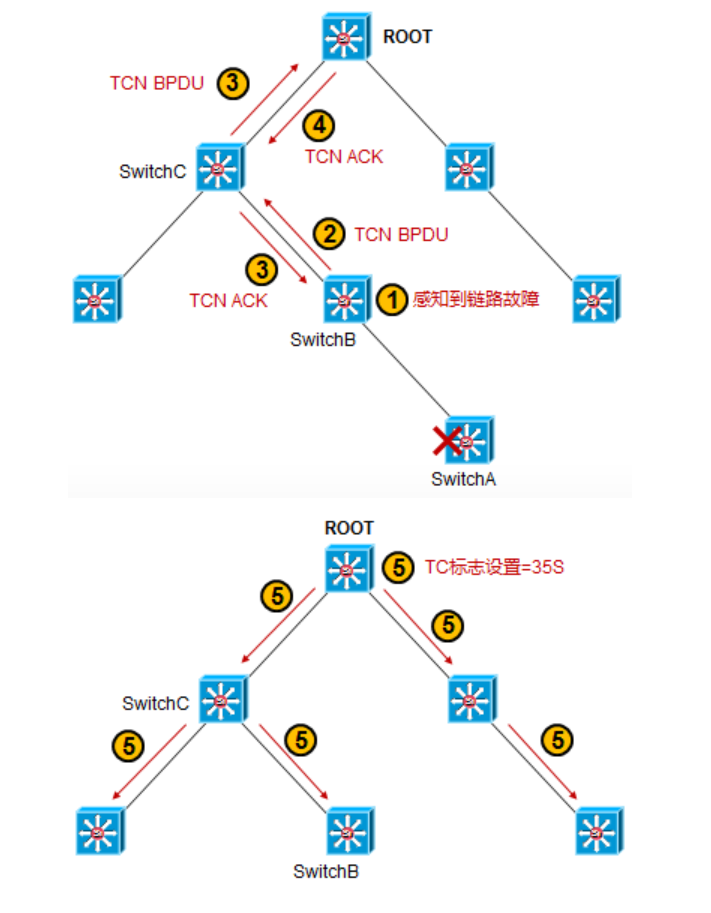
Switch A挂掉;
Switch B最先检测到拓扑变化,因为A挂掉后,SwitchB会无法接受到对方的BPDU,过20秒(Max Age)后就会知道对方挂了,于是产生TCN BPDU从根端口发送出去(因为根端口是朝向着根桥的方向),B连续发送TCN BPDU直到指定交换机C发送TCN ACK进行确认,这个TCN ACK就是一个TCA被置位的正常配置BPDU;
Switch C收到这个TCN BPDU后,回送一个TCN ACK(TCA被置位为1的正常的配置BPDU)给B表示收到了TCN BPDU,同时向自己的根端口转发这个TCN BPDU;
根桥交换机收到这个TCN BPDU,同时回送一个TCN ACK(TCA被置位为1的正常的配置BPDU)给C;
根桥交换机(Root)修改自己的配置BPDU,用修改后的BPDU来通告整个交换网络关于拓扑变更的情况。Root会在配置BPDU中设置一段时间(转发延迟+Max Age,默认时间为15+20,也就是35秒)的拓扑变更(Flags字段中的TC位置1),以此通告下游交换机,链路发生了变化,
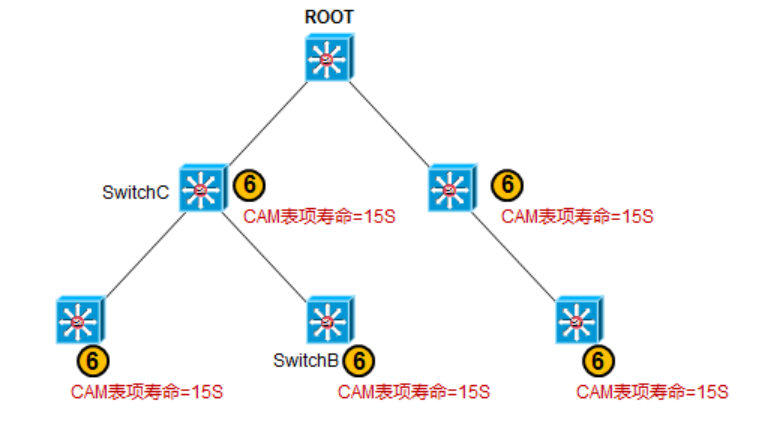
当下游交换机收到Root发出的这个TC置位的配置BPDU后,它们使用转发延迟计时器(默认15秒)来更新其MAC地址表中的条目,也就是说MAC地址条目的默认寿命由原来的300秒变为15秒,这样能保证MAC地址条目更快速的刷新。交换机将持续这个过程,直到不再从Root收到TC BPDU消息为止。
我们会发现,当拓扑变更的时候就会产生TCN BPDU,而有些情况下,TCN的过渡泛洪可能会对网络造成不必要的影响,通过在接入层交换机上,将连接PC终端设备的接口设置为Portfast可以在一定程度上优化网络,防止由于PC开关机导致的接入层交换机端口UP\DOWN而产生过多的TCN。
STP命令
1 | SW#show spanning-tree |
STP特性
Portfast
配置了Portfast特性的端口,一旦接入了设备,接口可以绕过Listening和Learning状态直接进入Forwarding状态,Portfast特性一般在连接PC或服务器的端口上配置,如果连的是交换机,这个接口仍然要接受Spanning-tree的计算结果,如果计算结果是Block,那么这个接口仍然会被Block,所以如果在Cisco IOS设备上敲入Portfast命令后,IOS会提示可能造成短暂的环路。
配置命令为:
1 | 全局配置命令会将所有非Trunk接口激活portfast特性 |
portfast 特性不嫩直接配置在Trunk模式的接口上,即使配上去了,IOS也不生效,除非该接口变为access模式,如果确实需要在Trunk上配置该特性,例如该接口连接了一台支持Trunk的服务器,那么久在Spanning-tree portfast命令上增加Trunk关键字。
1 | Switch(config-if)# switchport mode host |
上面的‘switchport mode host’命令是一条简化命令,相当于在接口上配置了下面的三条命令,也就是指定接口的mode为access模式,开启portfast特性并关闭端口汇聚。
BPDU Guard
配置命令为:
1 | 接口上配置命令: |
配置完该命令后:
该接口在收到BPDU报文后,会立刻切换到err-disable状态;
通常搭配portfast特性在接口上一起使用,用于连接主机的接口;
可在接口模式上激活,也可以在全局模式上配置,两者有所不同,在接口模式下配置,该接口收到BPDU报文后会立刻切换到err-disable状态;在全局模式下配置,该命令会在所有激活Portfast特性的接口上激活bpduguard特性;
BPDU Filter
该特性可以在全局模式下配置,也可以在接口模式下配置,区别如下:
全局配置为:spanning-tree portfast bpduguard default
启用了portfast的接口将激活bpdu filter特性;
接口在link up后瞬间会发送一些bpdu,此后不再发送任何bpdu;
接口在收到bpdu后立刻丢失portfast及bpdu filter特性,成为一个普通的spanning-tree接口;
接口配置为:spanning-tree bpdufilter enable
该接口不会发送BPDU,也忽略接收到的BPDU;
在接口上激活BPDU filter特性相当于在上面禁用了生成树,可能会造成二层环路;
在接口上配置,不一定必须和portfast特性一起使用,可独立配置。当然建议搭配portfast特性使用;
UplinkFast
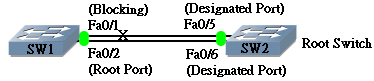
SW2为Root,SW1的F0/2是Forwarding状态,F0/1处于block状态,当F0/2的链路挂掉时,SW1会立刻进行STP计算,不过F0/1由block状态转到forwarding的状态需要30秒(15+15,端口进入侦听状态,侦听状态15秒到学习状态,再一个15秒由学习状态到转发状态),而等待30秒对于网络来说是不可接受的,因此思科提出的解决方案为uplinkfast,启动了uplinkfast的switch会选择一个Block状态的端口设置为standby状态,当RP端口挂掉时,standby的port立刻转换成Forwarding状态,节省30秒时间。
配置命令为在全局模式下:spanning-tree uplinkfast;
查看命令为:show spanning tree uplinkfast;
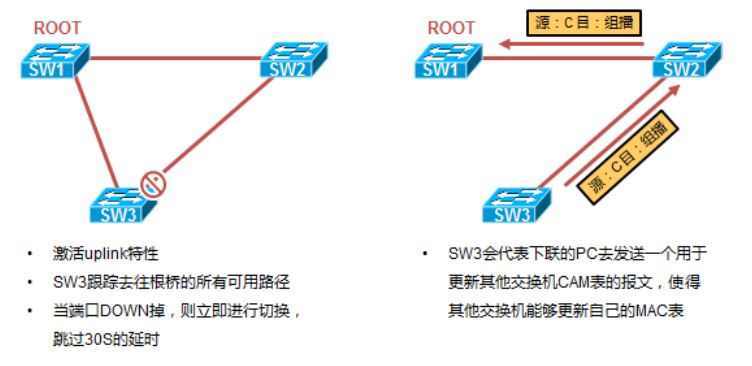
- 配置Uplink fast的交换机需为末梢交换机,或网络三层结构中的接入层交换机,不能在根桥上配置;
- 激活Uplinkfast特性后,交换机会自动调整一些参数:
交换机的默认网桥优先级会增加到一个比缺省值更高的值,使得该交换机不会成为Root根交换机;
交换机的所有端口的默认Cost值会增加3000,以使得该交换机的端口不会被选举为指定端口;
非默认的(指手工配置的)Priority与cost不变;
When the spanning tree reconfigures the new root port, other interfaces flood the network with multicast packets, one for each address that was learned on the interface. You can limit these bursts of multicast traffic by reducing the max-update-rate parameter (the default for this parameter is 150 packets per second). However, if you enter zero, station-learning frames are not generated, so the spanning-tree topology converges more slowly after a loss of connectivity.
当生成树重新设置了RP端口时,其他端口会泛洪组播数据包,每个端口上学习到的地址都有一个。可以通过降低最大更新速率来限制这些组播流量的爆发,默认速率是每秒150个包。如果将速率配置为0,那么将不会生成Learing的帧,因此在失去连接后,拓扑收敛速度会非常慢。
Backbone Fast
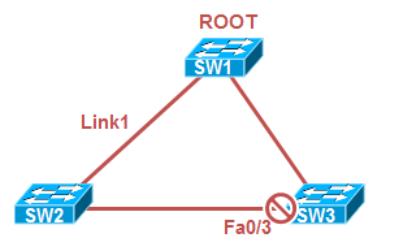
在没有Backbone Fast的情况下,SW3有一个接口被Block,这个接口将不会发送BPDU报文;
当Link 1 Down掉后,SW2将无法从ROOT收到BPDU,于是它会认为他自己就是ROOT,开始向SW3发送BPDU;
SW3收到这个BPDU后,发现SW2的BPDU不如自己本地存储的BPDU,因此忽略该BPDU;
Max age(默认20秒)计时器超时后,SW3上F0/3存储的BPDU老化,该接口进入侦听状态,并发送和接收BPDU;
SW2收到SW3发送的更优的BPDU后,停止发送它自己的BPDU;
SW3的F0/3从Listening到Forwarding,需花费20(Max age)+30(两倍的Forward delay)秒;
接下来看看有BackboneFast的特性:
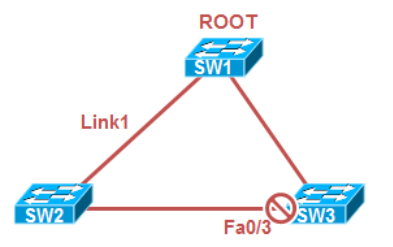
部署了Backbone Fast以后,SW3一收到SW2发来的次优BPDU,会立刻进行一系列步骤以重新计算根端口。SW3会从根端口向根桥发送RLQ请求;
Root收到RLQ请求后,立刻以RLQ相应进行回复,以告知自己仍然存活;
SW3立刻老化掉存储在F0/3上的BPDU,端口F0/3进入Listening状态并开始发送BPDU;
SW2从SW3收到BPDU,经过计算得出自己的F0/2为根端口;
配置命令为:‘spanning-tree backbonefast’
Root Guard
Root Guard可以保护STP的Root,免受Switch Priority小的交换机抢走根桥角色,因为根桥的角色是可抢占的。但如果规划好的根桥角色轻易被别的交换机抢夺走,整个网络就会和规划的有所差别,所以要杜绝这种情况。
配置命令为:SW1(config-if)#spanning-tree guard root
查看命令为:show spanning-tree inconsistentports
当配置了Root Guard的接口插入了一个优先级比Root小的交换机,这个端口会处于Root inconsistent状态,它会被Block而不会传送或接收数据,比如下图中的F0/8接口:
1 | SW1#show spanning-tree inconsistentports |
inconsistent和err-disable的区别在于,err-disable会disable掉整个接口,而inconsistent是针对特定VLAN的。
UDLD
UDLD全称为Unidirectional Link Detection,用于单向链路检测,主要用于光纤链路。需要两端设备都支持UDLD,开启UDLD以后,端口会不断向对方发出检测,如果对方有回应,表示运作正常,但如果收不到对方的回应,UDLD会认为出现了单向故障,会administratively shut down整个接口,并提示用户。单向链路会引发各种问题,其中包括spanning-tree环路。
UDLD有两种模式:normal(默认为该模式)和aggressive模式.
Normal模式配置:
1 | normal模式配置 |
Aggressive模式配置:
在aggressive模式中,端口变为err-disable
全局配置命令为:SW1(config)#udld aggressive
端口设定命令为:SW1(config-if)#udld port aggressive
1 | SW1#show udld |
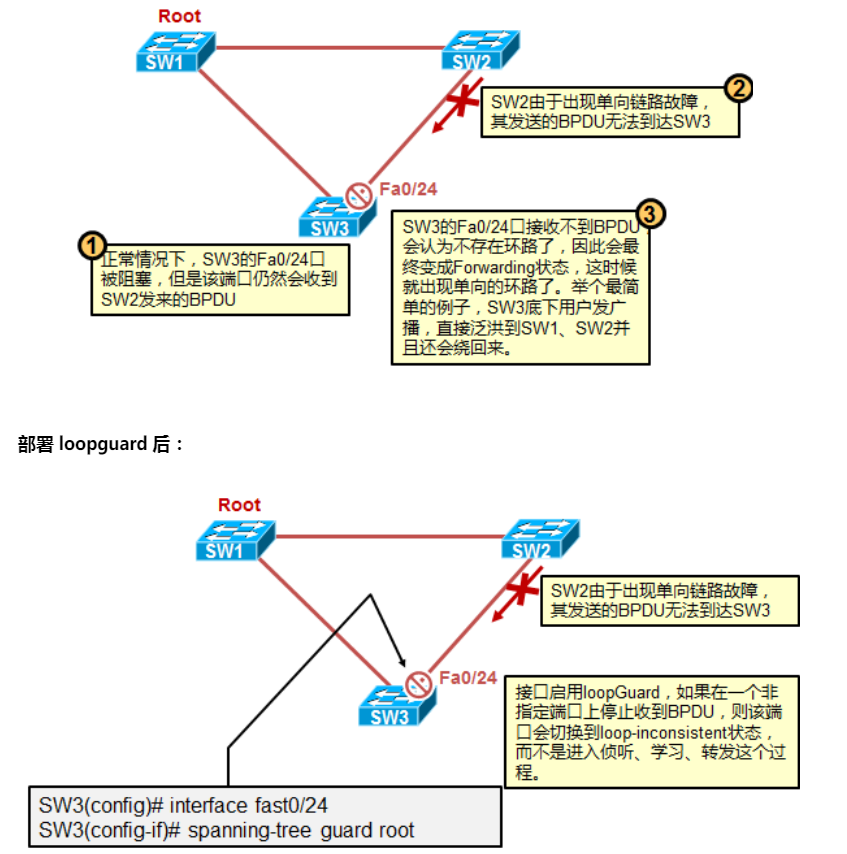
LoopGuard
UDLD只能防止光纤单向链路故障而导致的环路,但收不到BPDU也可能由其他问题引起,例如交换机的硬件问题或CPU满载而无法处理收到的BPDU,另一个办法是用Loopguard。如果端口开启了Loop Guard,当它收不到BPDU超过Max age的话会转成Loop Inconsistent状态避免发生环路。不过必须注意,LoopGuard和LoopGuard无法同时启动。
1 | 全局打开命令: |
PVST+
基本概念
传统的STP,也就是802.1D,是所有的VLAN共用一颗生成树,这样一来的好处是交换机不用耗费过多的资源去计算多颗生成树,不足是,通过Block固定的端口,导致流量只走一侧,而部分链路一点流量都没有,浪费了带宽。
PVST+在这方面做出了改进。PVST+全称为Per Vlan Spanning Tree Plus,中文是增强的按VLAN生成树,是思科的私有协议,一个VLAN对应一颗生成树,如此一来交换机将基于VLAN计算生成树,可以通过单独的VLAN生成树调节优先级等相关参数,从而影响生成树的计算,最终实现合理的链路带宽利用:
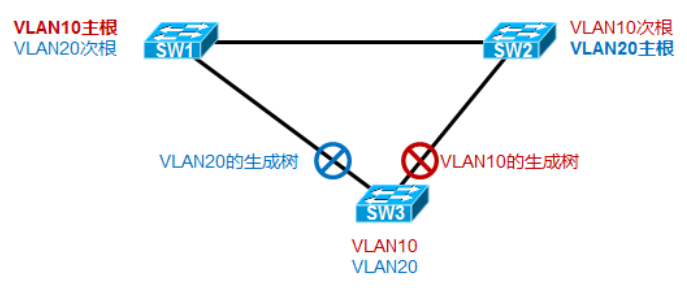
比如上图中,内网存在两个VLAN,10和20,这里让SW1成为VLAN10的主根,将它的优先级配置为最低,SW2成为VLAN10的次根,SW3优先级最高,如此一来将Block掉SW3上连接SW2的上联口,相对的VLAN20也通过参数调节,Block掉SW3连接SW1的上联接口。这样,vlan10用户出去将走左侧链路,vlan20用户走右侧用户,两边链路都得到了合理的使用,实现了负载均衡。
MAC地址
Cisco 交换机的MAC地址池最多容纳1024个地址,交换机的型号决定了可用MAC的数量,并不是所有型号的交换机都能支持这么多的MAC;
这些MAC地址作为VLAN生成树中网桥ID的MAC地址部分。不同交换机型号支持不同的可用MAC地址数目。交换机依照次序分配MAC地址;
show run interface | include bia 能看到所有的MAC地址,第一个MAC地址将被生成树所使用,也就是CPU的 MAC。接下来是每个以太网接口的MAC;
我们知道交换机能够支持的VLAN数据是很庞大的,如果开启PVST+,每个VLAN一个生成树,而每颗生成树都要有一个独立的标识,都需要消耗一个MAC地址的话,那么MAC地址池肯定是无法承受的;
因此需要使用到MAC地址缩减方案
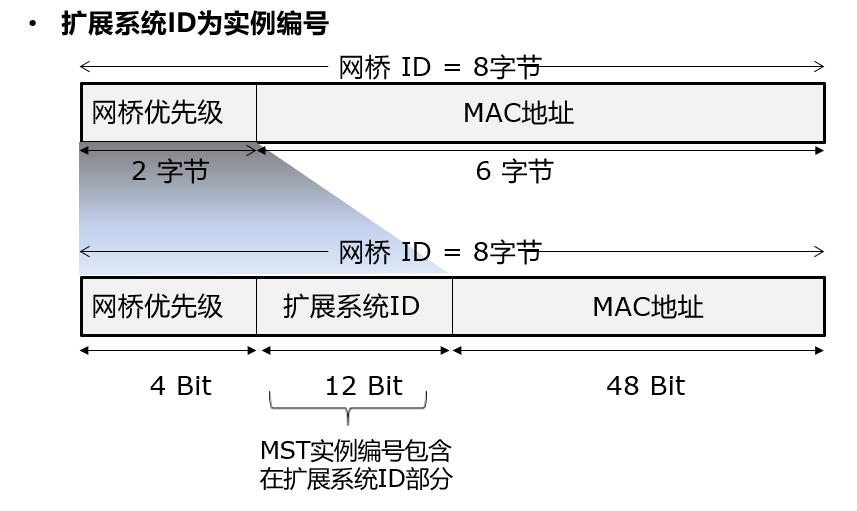
在PVST+中,一个VLAN一颗生成树,在每台交换机上,对于每一颗生成树,需要有一个唯一的标识符,也就是网桥ID要唯一,网桥ID之前说过,就是优先级和MAC地址构成的,在MAC地址缩减方案中,同一台交换机的所有生成树的根桥ID中,MAC地址都是用自己交换机CPU的MAC,同时将16bit的优先级进行扩展,变成4bit的优先级+12bit的系统ID,通过这个系统ID来标识不同的VLAN。在Cisco IOS中,这个系统ID用的就是VLAN ID。
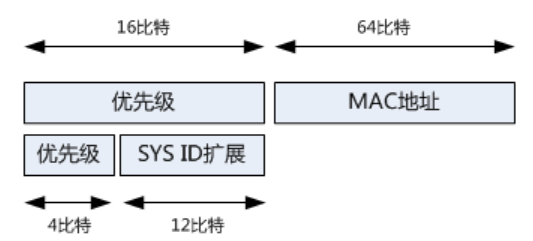
如此一来,优先级就成为了最高的4bit,系统ID取值VLAN ID,比如VLAN10的生成树,在本交换机的根桥ID就是‘4bit的优先级+12bit的sysid’,SYSID还作为VLAN或MST实例的标识。
为什么优先级必须是4096的倍数呢,因为在使用Extended System ID的情况下,每个VLAN的MAC地址可以相同,BID被要求包含VLAN ID信息,解决的办法是从优先级域的16个bit中拿出低位的12个bit,称为扩展的System ID,用来唯一标识每个VLAN号,剩下的4个bit用来表示交换机的优先级,这种情况下优先级的取值只有24=16个,2的12次方=4096,是4096的倍数。
RSTP(802.1W)
使用传统的802.1D协议时,当拓扑发生改变时,整个网络需要30秒或以上才能恢复稳定状态,这是现代网络所不能接受的,想象一下,如果证券交易服务因为生成树的30秒收敛时间而中断交易,那么将损失惨重,所以为了网络更快收敛,又开发出了RSTP协议,全称为Rapid Spanning Tree Protocol,快速生成树协议,由STP协议改进而来,主要改进了STP收敛慢的问题。
基础知识
RSTP端口状态
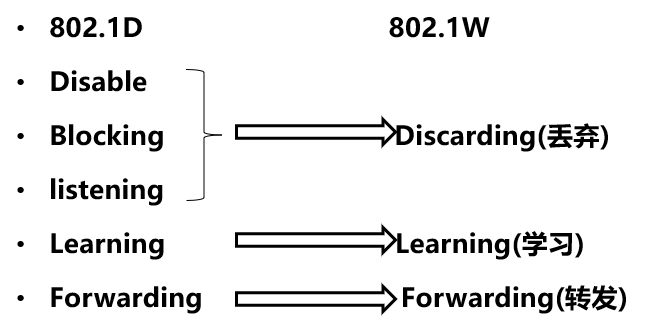
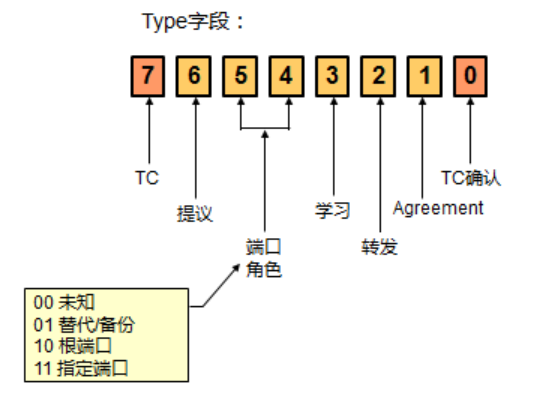
RSTP端口角色
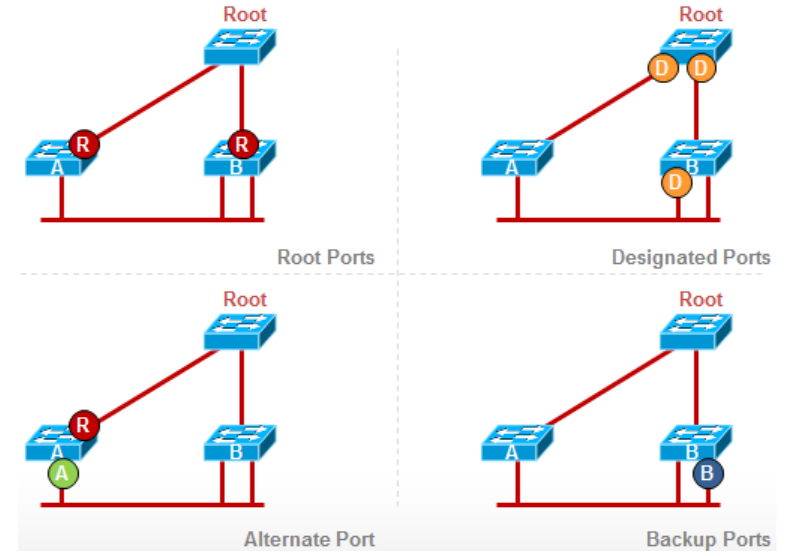
RSTP保留了Root Port和Designated的设计,选择方法与STP相同,另外增加了Alternate Port和Backup Port,以便加快收敛时间。
Root Port,根端口,交换机上最接近Root Switch的端口(即Root cost最小)成为RP根端口,每个交换机上只会有一个根端口,用来接收来自根交换机的BPDU;
Designated Port,指定端口,在没有RP的情况下,网段里****最接近根桥的端口成为根端口,用来发送BPDU,每个网段只会有一个Designated Port;
Alternate Port,替代端口,处于丢弃状态,Discarding状态,交换机除了根端口外,其他到根路径的端口,如果活跃的根端口发生故障,替代端口将成为根端口,所以替代端口也可以理解为根端口的可替代者,A是R的替代端口,5秒内完成转换;
Backup Port,备份端口,处于丢弃状态,Discarding状态,备份端口是指定端口的备份,出现在一台交换机有两个端口连接到同一个共享介质的时候,B是DP的备份端口,1秒内完成转换。
当Alternate Port和Backup Port有一天被唤醒而需要转发数据时,会先进入Learning状态(非常短时间)然后进入Forwarding状态。
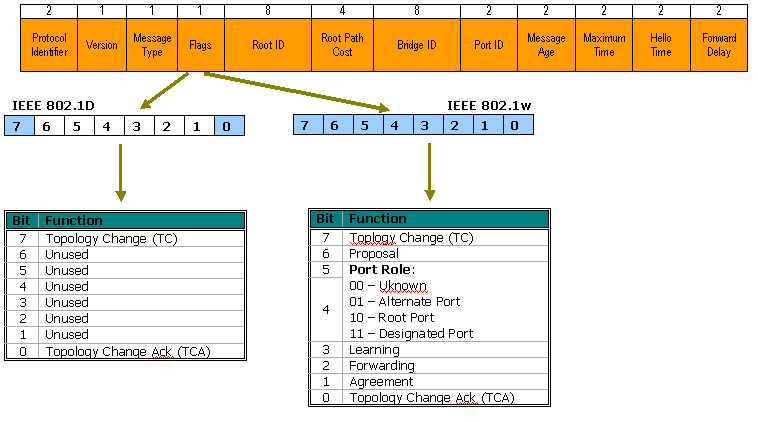
BPDU格式和操作
BPDU格式
RSTP只在802.1D的基础上对BPDU做了少量修改,RSTP的BPDU协议是2,版本是2,还有就是在802.1D中,Type字段只是用了最高位和最低位,来表示TC以及TCA,RSTP对该字段进行了扩展:
BPDU操作
在802.1D中,非根交换机只有从根端口收到根桥发送的BPDU,自己才能产生BPDU,而在RSTP中,即使非根交换机没有从根交换机收到BPDU,自己也以Hello间隔(默认为2秒)发送BPDU。
Faster Aging of information
在特定的接口,如果连续三个周期(3X2=6秒)没有收到BPDU或者Max age超时,接口上的STP协议数据将迅速老化,如此一来,BPDU又有点类似交换机之间的Keep-alive机制,这种快速老化的机制有助于对拓扑变化的快速响应。
accepts Inferior BPDUs
这个机制与思科的BackboneFast非常类似,当交换机从其他指定交换机或根桥收到次优BPDU时,802.1D遇到这种情况是首先忽略这些次优BPDU,而RSTP是立刻接收这些次优BPDU同时回传一个更优的BPDU。
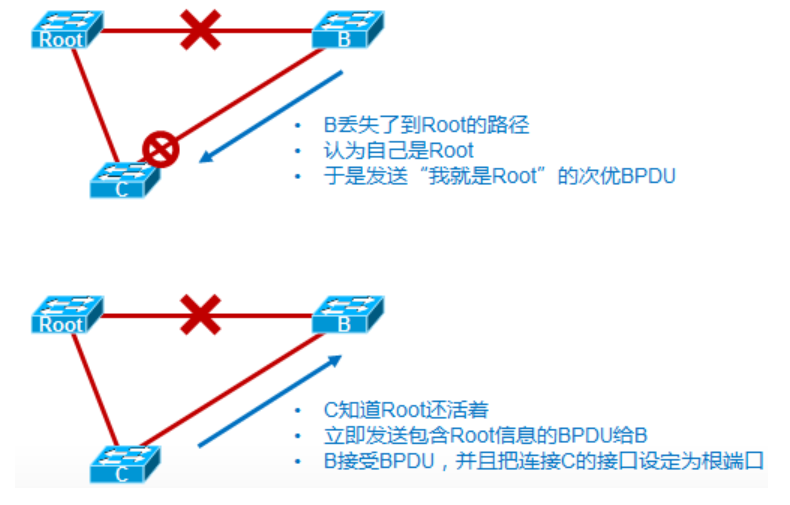
在802.1D的初始状况下,交换机C的一个接口被选举为非指定端口而被Block掉,B会从指定端口发送BPDU给C,当ROOT和B之间的链路发生故障,由于C上面链接B的端口被Block,C不会发送BPDU给B,因此B在过了Maxage以后会认为自己是Root,于是B向C发送自己为Root的BPDU,而这时由于C的接口上还存储着B的BPDU信息,而这个之前存储的BPDU信息比B现在发送给自己的BPDU更优,因此C会直接忽略掉这些次优BPDU,一直到Maxage超时以后,C接口上存储的此前B发送过来的BPDU才会老化,这时接口进入Listening状态,才会开始发送Root的最优BPDU给B,此时B收到Root的BPDU才会知道自己不是跟,将B和C连接的接口角色变为根端口。
在RSTP的情况下,C收到次优BPDU以后,会立刻回送自己存储的ROOT发来的更优的BPDU,好让B了解拓扑的情况,这个机制和BackboneFast非常类似。
Link Type
RSTP的一个重要改进就是端口的快速过渡,传统的STP算法在一个接口过渡到Forwarding状态之前,需要经过几个计时器,加起来至少要30-50秒,为了让网络快速收敛,我们可能会去调节计时器,但这么做有可能影响网络的稳定性,RSTP的设计使得可以不依赖计时器的调整并且还能让接口快速过渡到转发状态。
Link Type是RSTP新增的概念,RSTP将Link氛围Edge Port、Point-To-Point Non-edge Port以及Shared Non-edge Port三种。
Edge Port
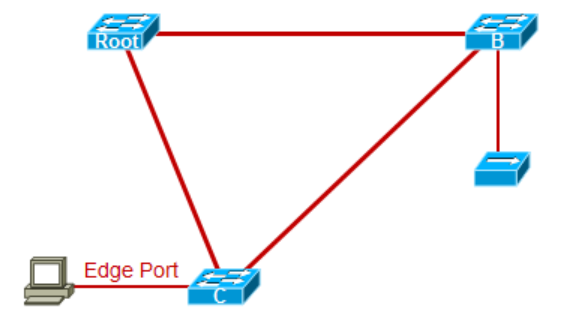
Edge Port接口的中文叫做边缘接口,RSTP定义的这种端口类型和Portfast十分类似,因为这些接口用于连接主机,所以一般不会产生环路,这些端口可以跳过Listening或Learning阶段直接进入转发状态,并且这些接口的up和down的时候都不会引起拓扑变更。另外,边缘接口一旦收到BPDU,则会立刻丢失掉边缘接口的特征,变成一个普通的Spanning-tree接口,配置命令就是在接口上输入portfast来开启。
1 | SW(config)#int fastEthernet 1/0/3 |
Point to Point Non-edge Port
RSTP会把全双工的网口定义为Point-to-Point Non-edge port,并会使用RSTP和对方进行沟通(Synchronization Process)。
Shared Non-edge Port
半双工接口会成为Shared Non-edge Port,只能用传统的STP方法进行沟通。下图中的F1/0/1是P2P non-edge port,F1/0/2是shared non-edge port:
1 | SW#show spanning-tree |
RSTP VS 802.1D
802.1D场景
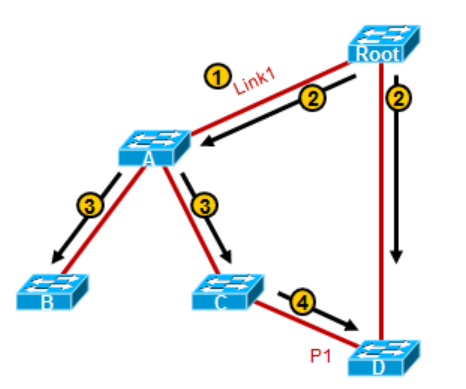
A和ROOT之间新增链路Link1;
A及Root在Link1两端的接口都进入Listening状态,A将收到Root发出来的BPDU;
A将BPDU从自己的指定端口发送出去,BPDU被泛洪到网络中;
B和C收到这个更优的BPDU,继续向网络中泛洪;
数秒后,D收到这个BPDU,Block掉端口P1;
由于缺乏Feedback机制,A连接Root的接口从Listening到Forwarding,需要经历15X2也就是30秒的延迟,此时A、B、C下联的用户流量就出现问题了,因为D在收到更优的BPDU后,P1接口就Block掉了,这时候A、B、C相当于在A的端口过渡到Forwarding之前都处于网络的‘隔离地带’
RSTP场景
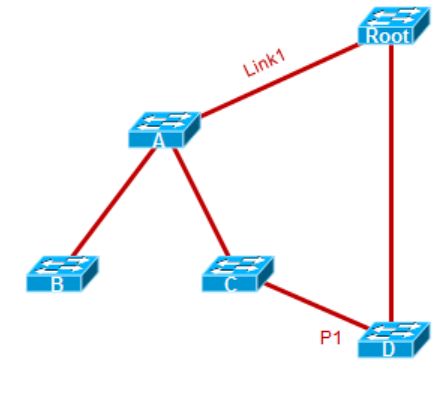
A及Root之间新增链路Link1。
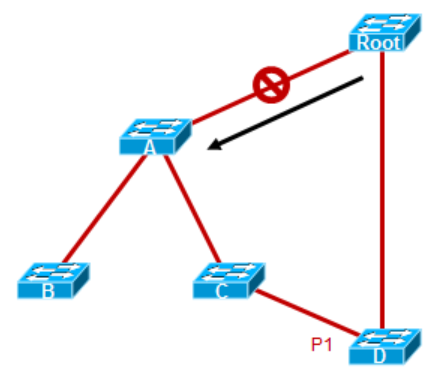
A及Root,在Link1两端口up之后进入了Designated Blocking,然后双方交互BPDU信息,这个过程实际上是一个协商的过程。
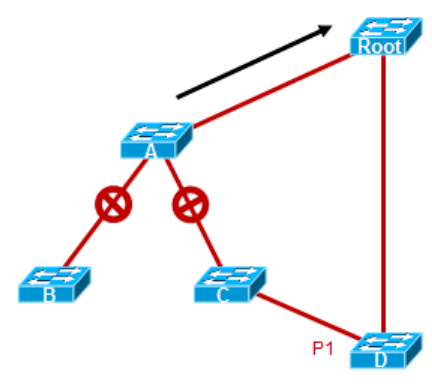
- A在收到Root发送的BPDU后,将自己的所有非边缘接口Block掉(这个过程称作同步,Synchronization mechanism),并且回送一个Agreement消息给Root;
- 在此之后,Root以及A在Link1上的端口like过渡到转发状态,而且此时网络是没有环路的,因为A的下联接口都是切断的;
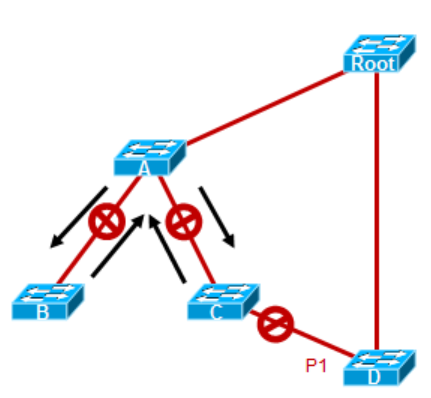
A、B、C之间,开启新一轮的协商,B、C收到A发送的BPDU后,完成同步过程,将自己的非边缘端口Block掉,然后都会向A回送Agreement消息,同时,A、B、C互相连接的接口进入转发状态,在和B、C同步操作的过程中,B下联的权势主机,所以没有被Block的接口,此时它已经完成了同步。而C要Block掉连接D的端口。
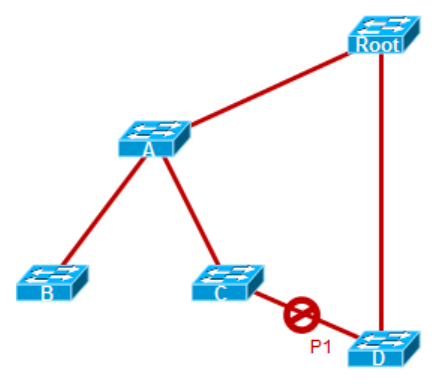
完成上一步之后,生成树状态如上图,最终BPDU到达D,D将P1接口Block掉。
总结:
在RSTP收敛过程中,RSTP用同步机制取代了基于计时器(Listening过15秒到Learning再过15秒到Forwarding)的机制,耗费的时间仅仅是BPDU从ROOT泛洪到网络末端的时间,不受到任何Timer的限制,直接绕过两个转发延迟的时间,因此收敛速度很快。

还需要注意两点:
- 交换机之间的这种协商机制只在P2P链路上执行;
- 边缘端口的配置非常重要,如果配置不当,可能会在同步过程中被Block掉;
P&A机制
全称是Proposal/Agreement Sequence,对于802.1D来说,当一个端口被选举为指定端口,它从Blocking到Forwarding至少需要30秒的时间,然而在RSTP中,Proposal & Agreement机制使得接口可以在几秒内完成迅速可靠的过渡。
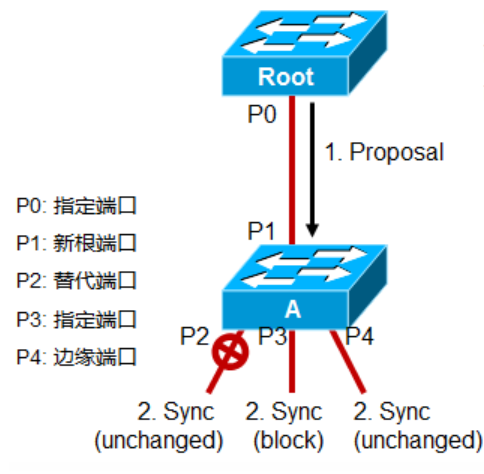
当Root和A之间新增了一跳链路,链路两端的接口在收到对方发送的BPDU之前是Designated Block状态,当一个被选举为指定端口的接口,在Discarding或Learning(在且只在这个状态),它在其发送的BPDU中进行Proposal bit置位,这就是步骤1的P0情况,也就是Proposal(When a designated port is in a discarding or learning state (and only in this case), it sets the proposal bit on the BPDUs it sends out);
A收到一个最优的BPDU,它立刻知道P1就是新的根端口,接下来A将启动一个同步进程,这个同步过程用来确定A上所有的端口,是否已经和最新收到的这个最优的BPDU了(Switch A then starts a sync to verify that all of its ports are in-sync with this new information)。
A怎么确定它的端口是否已经完成了同步呢?当端口处于Blocking状态(意味着拓扑已经稳定)或者当这个接口是一个边缘端口角色时,表示该接口已经同步完成(A port is in sync if it meets either of these criteria:The port is in the blocking state, which means discarding in a stable topology;The port is an edge port.);如果接口不满足上述两个条件,也就是说如果接口既不是边缘端口,也不处于Block状态,那么这个接口将被Block而进入Discarding状态完成同步。也就相当于A把所有接口Block掉,完成同步。
现在具体看A,它上面的三个端口其中P2是Alternated port,替代端口,是处于Discarding状态的,也就是完成了同步;P4端口时Edge port,边缘端口,符合完成同步的标准,也就是完成了同步;P3是Designated port,指定端口,不符合完成同步的标准,所以还没完成同步;为了让P3完成同步,A于是将P3端口Block掉,让该端口处于Discarding状态,这样的话,所有的端口都完成了同步,然后A会发送Agreement消息给Root,这个Agreement消息是之前Proposal BPDU消息的拷贝,但Proposal位不置1,而是agreement bit置1,这样的话P0接口就能知道该agreement回应的是哪个proposal报文了。
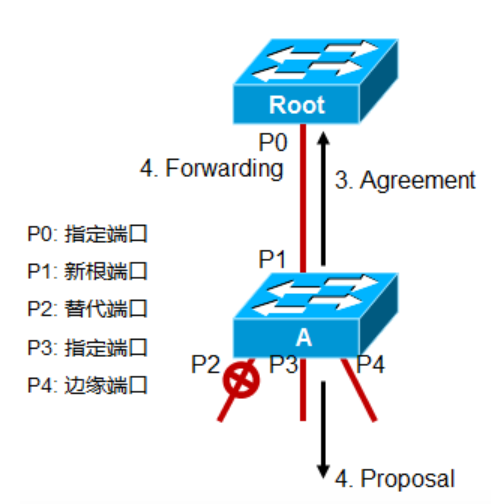
- 当Root的P0接口收到agreement报文后,它立刻进入Forwarding状态;A的P3接口之前是指定端口,在Proposal\agreement这个过程同步完成后,会执行和P0一样的Proposal\agreement步骤,开始对A的邻居发送Proposal报文,收到agreement报文后会马上进入Forwarding状态。
总结:
- Proposal\Agreement机制运行的速度非常快,它并不受限于计时器,它会非常快速的传遍整个网络,在拓扑变更后,能使网络快速收敛。
- 如果处于Discarding状态的指定端口(DP)在发送完Proposal后没有收到Agreement的回复,那么它会慢慢的过渡到Forwarding状态,‘退化’成为802.1D的listening-learning-forwarding 过程。这种情况可能出现在对端交换机不理解RSTP的BPUD时,或是对端交换机被Block掉的情况下。
拓扑变更机制
检测机制
在RSTP中,只有当非边缘端口过渡到Forwarding状态才会触发状态变更,也就是说一个端口如果丢失了连接,则不再认为是一次拓扑变更,这是与802.1D是有区别的。
当一个RSTP交换机检测到一次拓扑变更,它将:
为根端口及所有的非边缘指定端口启动一个TC While timer,该timer的值等于2倍的hello-time计时器;
向上述端口泛洪MAC表;
注意TC while timer在端口上计时,端口发送出去的BPDU就会进行TC bit置位,该BPDU也会从根端口往外发送;
传递机制
当一台RSTP交换机收到TC bit置位的BPDU,它将:
- 清除从所有交换机接口学到的MAC表项,但不清楚收到TC BPDU的那个接口。这个动作虽然有可能导致网络中存在短暂的突发性泛洪,但也有利于刷新CAM表,清除表项;
- 激活TC while timer,然后从所有的非边缘指定端口及根端口往外发送TC置位的BPDU,通过这种方式,拓扑变更信息会迅速在网络中泛洪;
通过这种方式,TC消息会被迅速的泛洪到整个网络。而不像802.1D那样需要等到消息传递到Root,然后再由Root来通知拓扑进行变更。
补充帖子
https://community.cisco.com/t5/switching/rstp-convergence-few-questions/td-p/1856300
https://community.cisco.com/t5/switching/rstp-proposal-agreement-process/td-p/2303537
https://community.cisco.com/t5/routing/rstp-proposal-agreement-sync-process/td-p/2095718
https://community.cisco.com/t5/switching/rstp-working-how-to-use-bpdu-agreement-flag/td-p/1606059
MSTP(802.1S)
从STP到RSTP,主要是速度的加快,而从RSTP到MSTP,则是硬件资源和管理层级式的进化,MSTP(又叫802.1S)继承了RSTP的Synchronization Process带来的高效率收敛,而比RSTP更优秀的是,MSTP可以把多个Spanning-tree分配给不同的实例(Instance),从而减少整个生成树系统的拓扑数量。
RSTP的问题
- 消耗硬件资源较大。思科所有支持RSTP的生成树都是Pervlan的,也就是一个VLAN一张生成树,如果有100个VLAN,那么就要维护100个生成树的拓扑,对交换机的CPU和内存都有很大影响;MSTP提出了实例(Instance)的概念,把多个VLAN分组成不同的Instance,同一组Instance的VLAN共用一组生成树,比如网络中共有VLAN101至VLAN200共100组VLAN,把VLAN101至150编入Instance1,余下的VLAN151至200编入Instance2,这样生成树拓扑的数量由100下降到2个;
- 缺乏区域概念,难于管理。MSTP把整个网络分区(Region)管理,每个Region之间不会互相干扰拓扑,每个Region会构成一个巨大的虚拟Switch,每个虚拟交换机之间会运行独立的生成树,称为Common and Internal Spanning Tree(CIST),不会影响每个Region里的拓扑。
区域(Region)
在同一个Region中的交换机只会处理相同Region中的BPDU消息,从而计算出生成树拓扑。要判断是否在同一Region,交换机会比较生成树中的三个参数,只有三个参数完全相同才算处于同一个Region:
Configuration Name:用命令‘name’设置;
Revision Number:设定的版本编号,习惯上每次更改MST设定都会把Revision Number加1,设定命令为revision;
vlan及Instance对应表:设置Instance所包含的VLAN,命令为Instance X vlan Y。要注意,思科会将Instance 0用作CIST,不能用作Region用。
扩展系统ID
实验1
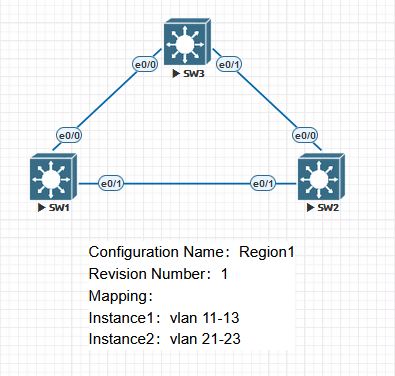
1 | SW1(config)#spanning-tree mode mst |
MSTP会把其他的VLAN放入Instance0中,一共有3个Instance在运行中,除了Instance1和2以外,还有一个预设的Instance0,用来做CIST用。
1 | SW1#show spanning-tree |
如果这里希望MST2由SW2来做Root,可以修改Priority,与STP/RSTP不同的是,MSTP要改的是Instance的参数而不是VLAN的参数:
1 | SW2(config)#spanning-tree mst 2 priority 28672 |
CIST
如果此时网络中又出现了另一个Region,MSTP会如何处理呢?MSTP会把Region当成一个大的虚拟交换机(Virtual Switch)去看待:
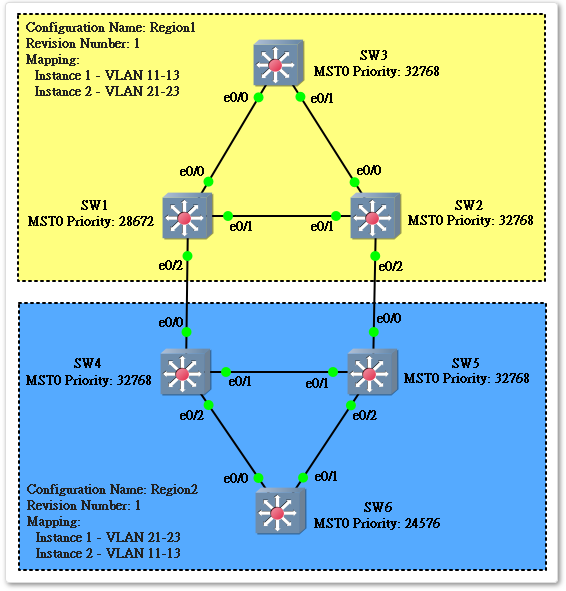
三层交换
CAM&TCAM
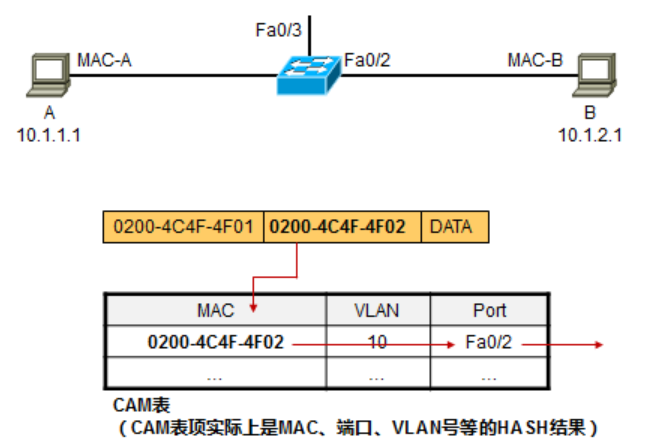
CAM
CAM是交换机用于二层交换时所查的表,Content Addressable Memory Table,内容可寻址内存,在查表时使用二进制的0、1进行匹配,并且需要严格匹配,也就是目的MAC与CAM表中的MAC需要完全匹配,查找的结果如果是完全匹配,则根据返回的端口号将数据转发出去。CAM表只能输出两种结果:0表示真,也就是匹配,1表示为假,也就是不匹配。所以CAM表在构建那些需要精确匹配的表格(比如MAC地址表)的时候就非常有用,因为MAC地址为48位,需要每位都匹配才能使得数据帧从一个接口发出去。(CAM performs quick lookup based on exact match on the given search key. In essence, a CAM looks up a single record - the one matches the search key precisely——出自这个帖子)
查看CAM表使用命令:show mac address-table dynamic [address mac-address | interface type mod/num | vlan vlan-id]
查看CAM表大小使用命令:show mac address-table count
CAM (Content Addressable Memory) is memory that can be addressed by content, rather than a numeric memory address. You can look up the interface by presenting the memory with the MAC address. This is done in a single CPU cycle vs. the traditional programming of searching through a table, which will cost many CPU cycles.
TCAM
TCAM(Ternary Content Addressable Memory)是路由模块或路由器用于三层时转发所查的表,用于ip寻址,也用在ACL、QOS等情况下使用。(TCAM performs quick lookups based on search key and a mask that identifies which bits of the search key must be matched.while a TCAM looks up an entire set of similar records that match the “interesting” bits of a search key (the “interesting” bits are identified by the mask).)因为TCAM可以提供三种结果,0,1和无所谓(don’t care)。TCAM对于构建那些需要最长匹配的东西,比如IP路由表,非常有用。
查看TCAM表占用率的命令:show tcam counts;
扩展阅读
CAM和TCAM比传统意义上的DRAM内存要贵得多,因为它们的性能更强大,在普通PC上看不到它们的身影,只在专门做数据转发的设备,比如路由器或交换机上才会有它们。
Introduction
CAM (Content Addressable Memory) VS TCAM (Ternary Content Addressable Memory)
CAM VS TCAM
Multilayer switches forward frames and packets at wire speed by using ASIC hardware. Specific Layer 2 and Layer 3 components, such as routing tables or Access Control Lists (ACLs), are cached into hardware. Routing, switching, ACL and QoS tables are stored in a high-speed table memory so that forwarding decisions and restrictions can be made in high-speed hardware. Switches perform lookups in these tables for result information, such as to determine whether a packet with a specific destination IP address is supposed to be dropped according to an ACL.
Cisco Catalyst switches deploys these memory tables using specialized memory architectures, referred to as CAM and TCAM.
CAM (Content Addressable Memory)
CAM stands for Content Addressable Memory which is a special type of memory used by Cisco switches. In the case of ordinary RAM the IOS uses a memory address to get the data stored at this memory location, while with CAM the IOS does the inverse. It uses the data and the CAM returns the address where the data is stored. Also the CAM is considered to be faster than the RAM since the CAM searches the entire memory in one operation.
CAM tables provide only two results: 0 (true) or 1 (false). CAM is most useful for building tables that search on exact matches such as MAC address tables. The CAM table is the primary table used to make Layer 2 forwarding decisions. In the case of Layer 2 switching tables, the switch must find an exact match to a destination MAC address or the switch floods the packet out all ports in the VLAN.
The table is built by recording the source address and inbound port of all frames. As frames arrive on switch ports, the source MAC addresses are learned and recorded in the CAM table. The port of arrival and the VLAN are both recorded in the table, along with a timestamp. If a MAC address learned on one switch port has moved to a different port, the MAC address and timestamp are recorded for the most recent arrival port. Then, the previous entry is deleted. If a MAC address is found already present in the table for the correct arrival port, only its timestamp is updated.
When a frame arrives at the switch with a destination MAC address of an entry in the CAM table, the frame is forwarded out through only the port that is associated with that specific MAC address. The information a switch uses to perform a lookup in a CAM table is called a key. For example, a Layer 2 lookup would use a destination MAC address and a VLAN ID as a key.
To view the contents of the CAM table, you can use the following EXEC command:
Switch# show mac address-table dynamic [address mac-address | interface type mod/num | vlan vlan-id]The entries that have been dynamically learned will be shown. You can add the address keyword to specify a single MAC address, or the interface or vlan keywords to see addresses that have been learned on a specific interface or VLAN.
To see the CAM table’s size, use the show mac address-table count command.
The problem with CAM is that it can only do exact matches on ones and zeros (binary CAMs), and here comes TCAM.
TCAM (Ternary Content Addressable Memory)
TCAM stands for Ternary Content Addressable Memory which can match a third state, which is any value. This makes TCAM a very important component of Cisco Layer 3 switches and modern routers, since they can store their routing table in the TCAMs, allowing for very fast lookups, which is considerably better than routing tables stored in ordinary RAM. TCAM is a specialized CAM designed for rapid table lookups.
TCAM provides three results: 0, 1, and “don’t care.” TCAM is most useful for building tables for searching on longest matches such as IP routing tables organized by IP prefixes. The TCAM table stores ACL, QoS and other information generally associated with upper-layer processing. As a result of using TCAM, applying ACLs does not affect the performance of the switch.
Most switches have multiple TCAMs so that both inbound and outbound security, as well as QoS ACLs, can be evaluated simultaneously or entirely in parallel with a Layer 2 or Layer 3 forwarding decision.
The term VMR (Value, Mask and Result) refers to the format of entries in TCAM. The “value” in VMR refers to the pattern that is to be matched; examples include IP addresses, protocol ports, DSCP values, and so on. The “mask” refers to the mask bits associated with the pattern and determines the prefix. The “result” refers to the result or action that occurs in the case where a lookup returns a hit for the pattern and mask.
This result might be a “permit” or “deny” in the case of a TCAM for ACLs, values for QoS policies in case of QoS or a pointer to an entry in the hardware adjacency table that contains the next-hop MAC rewrite information in the case of a TCAM used for IP routing.
To see the current TCAM resource usage, use the show tcam counts EXEC command. To see the current TCAM partitioning, you can use the show sdm prefer EXEC command.
Most of the traditional Layer 2 Cisco switches has only CAM for Layer 2 switching, while some Layer 2 Cisco switches has TCAM for QoS and not for routing, while layer 3 switches has the routing TCAM. CAM and TCAM are the most important parts of the so called ASICs that Cisco switches leverage for line-speed fast switching.
Catalyst switch architecture supports the ability to perform multiple lookups into multiple distinct CAM and TCAM regions in parallel. As a result of this ability to perform multiple lookups simultaneously, Catalyst switches do not suffer any performance degradation by enabling additional hardware-switching features such as QoS and IP ACL processing.
出自这个帖子
CAM stands for Content Addressable Memory which is a special type of memory used by Cisco switches, in the case of ordinary RAM the IOS uses a memory address to get the data stored at this memory location, while with CAM the IOS does the inverse, it uses the data and the CAM returns the address where the data is stored, also the CAM is considered to be faster than the RAM since the CAM searches the entire memory in one operation.
The problem with CAM is that it can only do exact matches on ones and zeros (binary CAMs), and here TCAM (Ternary CAM) comes, since it can match a third state which is any, this makes TCAM a very important component of Cisco layer 3 switches and modern routers, since they can store their routing table in the TCAMs, allowing for very fast lookups, which is considerably better than routing tables stored in ordinary RAM.
CAM and TCAM are the most important parts of the so called ASICs that Cisco switches leverage for line-speed fast switching.
Well to keep it simple, a multilayer switch uses sets of TCAMs, each set of TCAMs are used for a certain feature (Routing, QoS, ACLs …), and it does parallel lookups to get all the required results using the VMR combination (Value, Mask and Result), these results can be permit and deny in the case of ACLs, values for QoS policies in case of QoS or pointers to a next-hop in the routing table in case of routing, most of the traditional layer 2 Cisco switches has only CAMs for only layer 2 switching, while some layer 2 Cisco switches has TCAMs for QoS and not for routing, while layer 3 switches has the routing TCAMs.
出自这个帖子
VLAN间路由
单臂路由
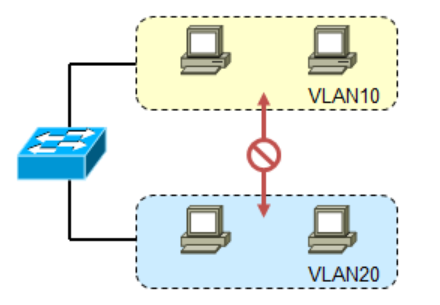
在二层环境下,一个VLAN就是一个广播,不同VLAN处于不同的广播域,一般也都是不同的逻辑子网,相互隔离无法相互访问,这样能起到隔绝广播的作用。但世纪网络中往往有VLAN之间需要相互访问的需求,例如一个公司不同的部门被划分到不同的VLAN中,这些部门之间也会有数据来往的需求,这时二层交换机就无法实现了,需要借助三层设备。最简单的办法就是使用路由器,最经典的解决方案就是单臂路由(router-on-a-stick):
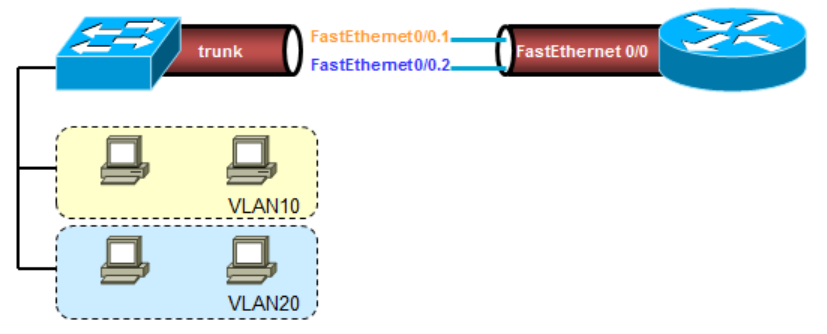
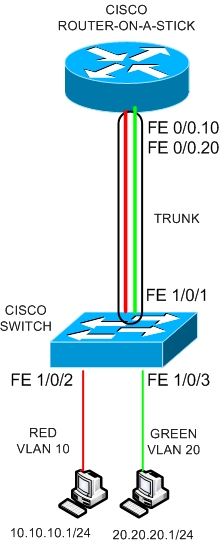
所谓的单臂路由(router-on-a-stick),就是在路由器的以太网口上(必须是百兆以上的),来承载VLAN之间的流量,让路由器和交换机之间跑一个Trunk,使用Dot1Q封装,这时候,为了让路由器的以太网口支持Dot1Q并识别承载VLAN流量,那么需要对物理接口进行子接口的划分,比如上图中划分了F0/0.1和F0/0.2两个子接口,分别承担不同VLAN的流量,并配置封装协议Dot1Q,同时为流量打上VLAN的Tag,这样一来,交换机和路由器之间起了一个Trunk,路由器的这两个子接口分别配置两个VLAN的网关IP,作为VLAN用户的网关。
配置方式如下:
1 | interface F0/0 |
encapsulate dot1Q 20表示F0/0.20属于VLAN20,encapsulate dot1Q 10表示F0/0.10属于VLAN10。
使用单臂路由能够解决VLAN数据间互访的问题,但也存在弊端,比如中间的Trunk 链路,也就是路由器和交换机这条链路,承载流量较大,因为流量需要二次进出,扩展性差,存在单点故障可能。
园区网构架
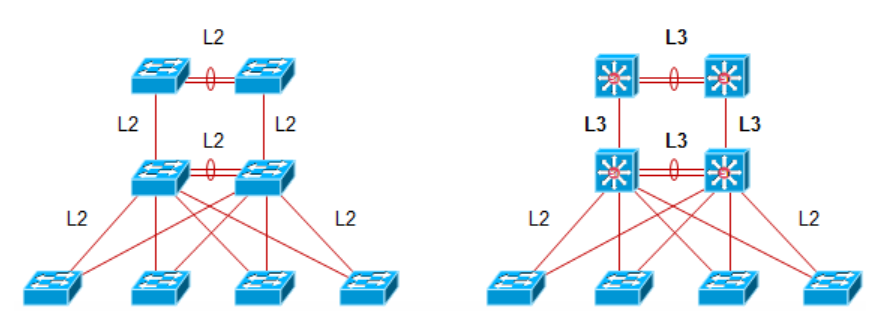
过去,交换机基于硬件转发,路由基于软件转发,因此园区网更多采用交换网络设计,比如左图中的构架设计。
现今,路由已经几乎和交换一样快速,也能够基于硬件做转发,与此同时,路由的设计很好的解决了交换网络的二层环路问题,以及vlan的隔离问题,所以现在的园区网更多采用有图的设计。
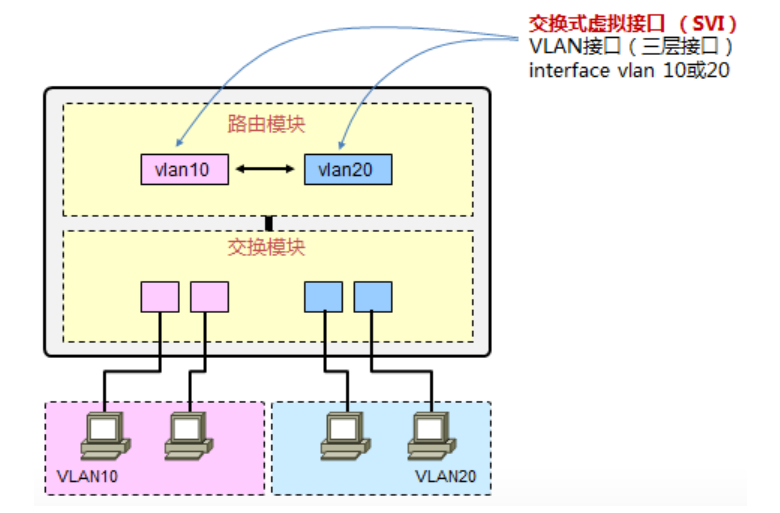
Switch Virtual Interfaces(SVI)
下面来看看三层交换机是如何实现VLAN间的数据互访的,我们从这里为切入点,开始理解并部署三层交换机。我们知道二层交换机是可以实现二层交换的,它看的是二层的数据帧,对帧头的二层信息进行读取并且根据自己的CAM表进行转发。而三层交换机相当于在二层交换机的基础上,多了个路由模块,于是它就支持路由功能了:支持路由选择协议,支持三层数据的转发,支持IP路由查找,支持三层接口等等。
先来人事一下第一种三层接口,SVI,交换式虚拟接口,SVI中的V是Virtual,也就是虚拟的意思,也就是说它不是一个物理接口,当我们在交换机上创建了一个VLAN后,紧接着就可以创建一个与这个VLAN相对应的SVI接口,例如在三层交换机上穿件了一个VLAN10,那么VLAN10所对应的SVI接口就是Interface VLAN10或者叫SVI10这个三层接口。可以为这个三层SVI借口配置IP地址,配置的地址与VLAN10内的PC用户的IP地址为同一网段,那么这样一来,VLAN10内的用户就能够将网关指向这个SVI接口,当VLAN10的PC需要访问其他网段的数据时,这些PC就会将需要跨网段的数据交给三层的SVI10这个接口,由这个SVI接口再去做路由及数据转发这种三层才能完成的工作。在这个过程中,可以用单臂路由这个模型来类比。
上图中,在三层交换机上创建了两个VLAN,VLAN10和VLAN20,同时为两个VLAN的三层SVI接口分配了地址作为各自VLAN的用户网关,这样一来,这台交换机的路由表里就有了两个VLAN网段的路由。那么当两个VLAN之间要互访时,VLAN10的用户将数据丢给自己的网关,VLAN10的SVI接口,数据到了SVI10以后,三层交换机查表,发现目的IP是VLAN20所在的网段,因此将数据从VLAN20的SVI扔出去,最终到达目的地,VLAN20的PC上。
举个不是特别恰当的例子,可以把VLAN想象成一个独立的班级,PC是学生,SVI是班主任,当班级之间的学生(PC)相互通信的时候,由于都在一个班里边(同一个VLAN中),彼此都相互认识,如果要和别的班的同学通信,也就是跨网段通信,需要经过班主任去对接其他班级的班主任,因为同学之间不认识。
三层交换机的端口
基本概念
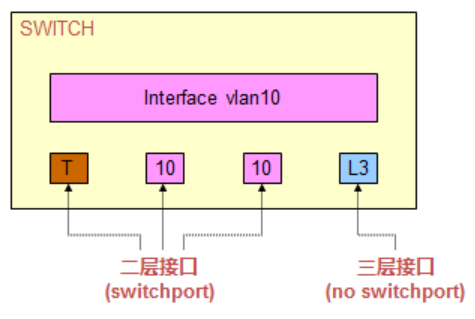
总的来说,三层交换机包括两类端口,二层接口L2和三层接口L3:
- 二层接口(Switchport):二层接口包括了常见的Access mode和Trunk Mode,交换机的所有物理接口默认是二层接口,也就是Switchport。
- 三层接口:路由接口(no switchport或叫做routed port)、SVI接口。SVI是一个虚拟接口,而routed port是一个和路由器上接口相同的物理接口。三层交换机支持将物理接口变为一个类似路由器物理接口的三层接口,具体的配置就是进入接口以后,使用‘no switchport’命令,这样该接口就变为了一个L3的路由接口,可以给该接口配置IP地址,就像操作路由器的接口一样类对待它。
基本命令
1 | 开启三层交换机的路由功能 |
实验1
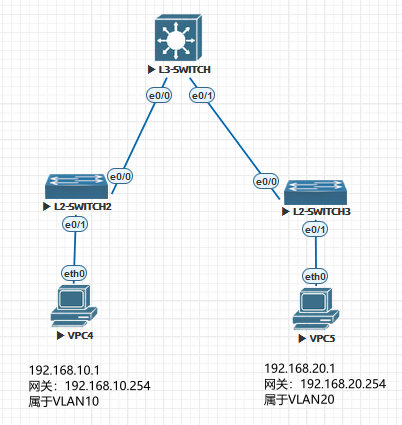
两台PC通过两台二层交换机接入网络,二层交换机上联三层交换机,这是一个在小型网络中常见的拓扑结构,二层交换机放在楼层配线间,通过光纤和担负核心职责的三层交换机相连。
1 | L2-SWITCH2: |
PC上配置好IP地址和网关;两个二层交换机上分别创建属于这个交换机的VLAN,然后就将连接PC的接口配置成access模式并将接口划入相应的VLAN,两个二层交换机不配置对方交换机的VLAN是没问题的,也就是说SWITCH2上只有VLAN10,SWTICH3上只有VLAN20不影响数据通信。上联L3交换机的接口配置成Trunk,使得可以通行多VLAN;三层交换机上创建VLAN10和20,然后进入这两个VLAN的SVI接口配置IP地址(interface VLAN10,ip address X.X.X.X),并将下联到L2交换机的接口配置成Trunk以便通行多VLAN。
从L3交换机的路由表中可以看出,配置完毕以后它已经有了10.0和20.0网段的路由,因此可以转发二层交换机无法转发的数据。从192.168.10.1这台PC的Traceroute中也能看出,发往192.168.20.1的数据先发给了所在的10.0网段的网关192.168.10.254,这个10.254就是L3交换机上VLAN10的SVI这个三层接口,然后发给了目的地址,所以整体的数据走向是:
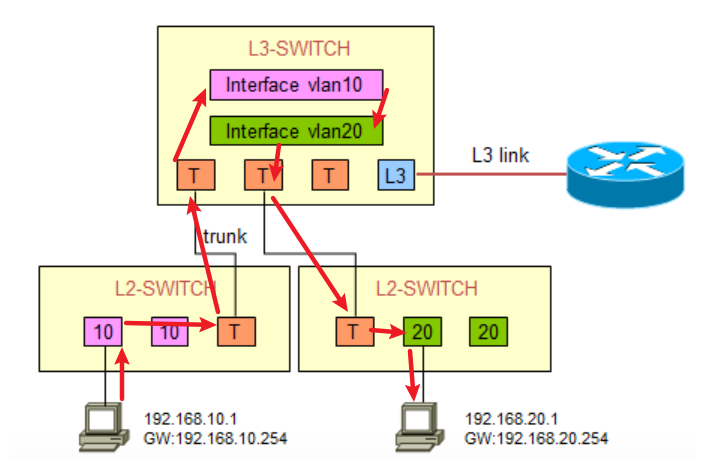
假设所有设备中的MAC地址表都为空,PC1的数据通过Access接口发送到上联的二层交换机以后,会打上Access端口的PVID也就是VLAN10的TAG,然后交换机对数据解封装,将PC1的MAC地址和接口的对应信息放入CAM表中,根据数据帧中的目的MAC地址,查询本地MAC地址表,由于MAC地址表为空,所以会发送ARP广播来查找网关的MAC地址,这个广播会经过Trunk链路打上VLAN10的TAG,然后发送给L3交换机。L3交换机收到带VLAN10TAG的广播以后,会回复interface VLAN10的MAC地址给L2交换机,然后L2交换机将发送到20.1的数据帧重新封装二层地址(源地址为连接PC端口的MAC地址,目的为网关的MAC地址):
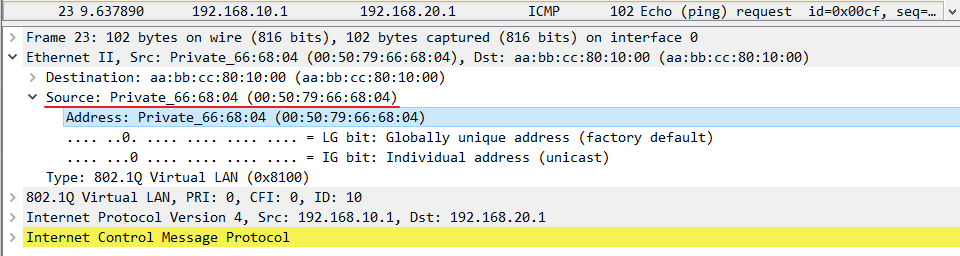
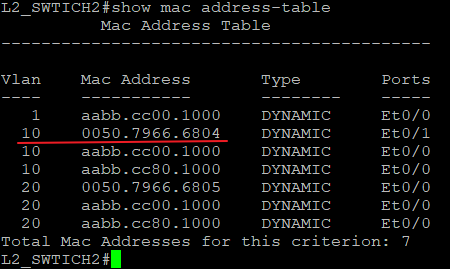
L2交换机将重新封装好的数据发送给L3交换机(此时数据之前在进入Access口时打上了VLAN10的TAG所以Trunk不需要重新打标签),L3交换机收到数据后解封装二层,发现是发给自己VLAN10的SVI接口的,于是继续将数据解封装至三层,发现目标IP地址为192.168.20.1,在自己的VLAN20的Interface接口上,接下来发送ARP查找对应的MAC地址,发送给右边的L2交换机,然后L2-SWTICH3将它的E0/1口的MAC地址回复给广播ARP,L3Switch获知MAC地址后重新封装数据包,交给L2-SWTICH3。
这里注意,L3的access口并不会发送ARP的广播,但Trunk口会。
补充帖子:
https://community.cisco.com/t5/switching/switch-svi/td-p/2386970
https://community.cisco.com/t5/switching/l2-l3-vlan/td-p/990201
交换机的管理
二层交换机的管理
理论知识
在一个园区网中,数量最多的设备一般是交换机,其中二层交换机的数量居多,二层交换机在典型的三层网络构架中属于“接入层”主要任务是为终端的PC和用户提供接入,同时划分VLAN隔离广播域,再或者运行STP来提供二层的放环机制。一个中小型的园区网,二层交换机一般都有几十上百台,这些设备在客户现场被拆箱后,一般是由工程师现场用Console线缆一台台的调试,这些交换机在调试好之后,会被安装到客户现场的各个机房或弱电配线间去,一切妥当后就正式上线运行了。在设备上线后,如果需要变更设备的配置,管理这些就交换机怎么办?不可能拿着笔记本一个配线间一个配线间的去跑,可以通过Telnet或者其他方式来远程管理,只要三层可达,就能Telnet到设备。
二层交换机无法识别三层报文,它根本不会去看三层的报头,但这并不影响二层交换机自己拥有一个IP地址。在路由器上,我们始终是给路由器的物理接口配置IP地址,而二层交换机,是在Interface VLAN口上配置IP地址,也就是SVI虚拟接口,跟VLAN对应的一个逻辑的虚拟的接口。一台二层交换机只能给一个VLAN接口分配IP地址,但二层交换机的‘SVI’地址并不是一个完全意义上的SVI地址,完全意义上的SVI接口要能执行三层策略,比如路由、ACL等,而二层交换机的‘SVI’只是个管理接口,没有那些功能。
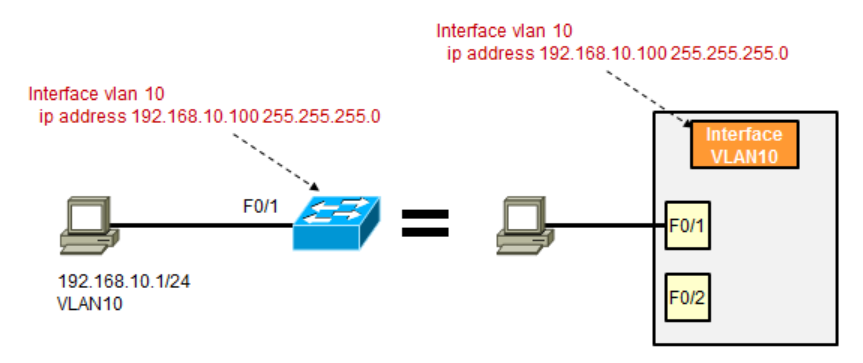
如上图左侧,PC想要Telnet交换机,首先PC要能PING通交换机,其次交换机上要激活VTP并配置密码。那么我们在二层交换机上创建一个VLAN10,将F0/1接口划入VLAN10,同时给二层交换机的VLAN10逻辑接口配置一个IP地址,与PC在同一网段。这样一来PC就能访问到交换机了,可问题来了,这样一来,PC与交换机就在同一网段同一个VLAN了,万一下面有PC配置的IP地址与交换机配置的管理地址有冲突就麻烦了,因此我们可以考虑给交换机划分一个单独的VLAN用于管理这些交换机,这个VLAN适用于整个交换网络,统一的VLAN统一的IP规划,它就是管理VLAN,因此管理VLAN并不是一个特定的VLAN,更不是VLAN1,这是很多人的误解,一般情况下,我们会使用一个较为‘生僻的’VLAN ID和IP编制,例如VLAN255,以及网段192.168.255.0/24。
问题来了,给交换机单独一个管理VLAN固然可以起到与用户VLAN隔离的作用,但这样一来,用户就无法访问到交换机了,因为同一交换机上不同的VLAN之间是隔绝广播域无法访问的,就需要借助三层设备,比如路由器或三层交换机了,与此同时,由于二层交换机没有路由功能,无法像路由器那样拥有一个IP路由表,因此还需要给交换机配置一个默认网关,就像用路由器模拟PC那样。
实验说明
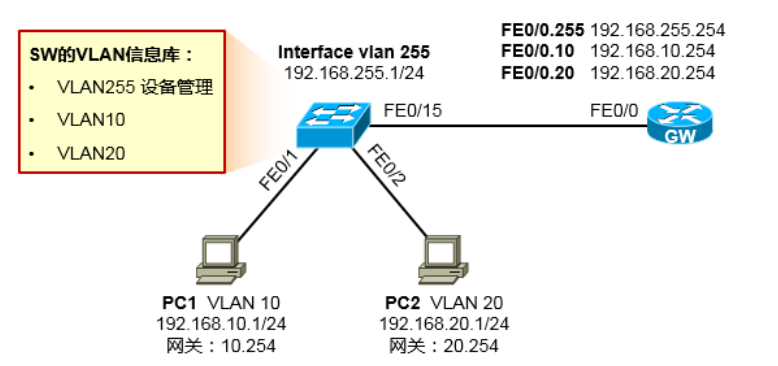
交换机下联 2 台 PC,又连接了一台路由器。路由器作为内网 VLAN10、VLAN20 用户的网关。交换机增加一个 VLAN255用于其自身的设备管理,交换机的管理 IP 为 192.168.255.1,网关在路由器上; 交换机创建 VLAN10、VLAN20,这是用户 VLAN,是 PC 用户的 VLAN;路由器 FE0/0 口划分子接口做单臂,作为 VLAN10、VLAN20 及 VLAN255 的网关;要求 VLAN10、VLAN20 之间的用户能够互访,同时只允许 VLAN10 的用户 Telnet 交换机进 行设备的管理。
1 | Switch(config)#no ip routing |
由于EVE的交换机都是三层,所以这里用no ip routing将三层交换机的路由功能关闭,变为二层交换机,如果不配置该命令,ip default-gateway指定的缺省网关是无效的,此时也可以使用ip route 0.0.0.0 0.0.0.0 的方式来代替ip default-gateway这条命令,但必须注意,ip default-gateway,是给交换机自己用的,不是为了底下接入的PC配置的网关。接下来看路由器的配置
1 | interface Ethernet0/0 |
GW的E0/0接口一定要配置no shutdown命令否则子接口也无法打开。E0/0.10是VLAN10的网关,E0/0.20是VLAN20的网关,E0/0.255是VLAN255的网关。在实际部署中,如果直接将交换机暴露在网络中,所有内网PC都能随意登陆是有风险的,我们还可以在交换机上增加如下配置,来限制交换机管理的网段,例如只为让192.168.10.0/24网段的用户登陆管理交换机:
1 | Switch(router)# access-list 1 permit 192.168.10.0 0.0.0.255 |
三层交换机的管理
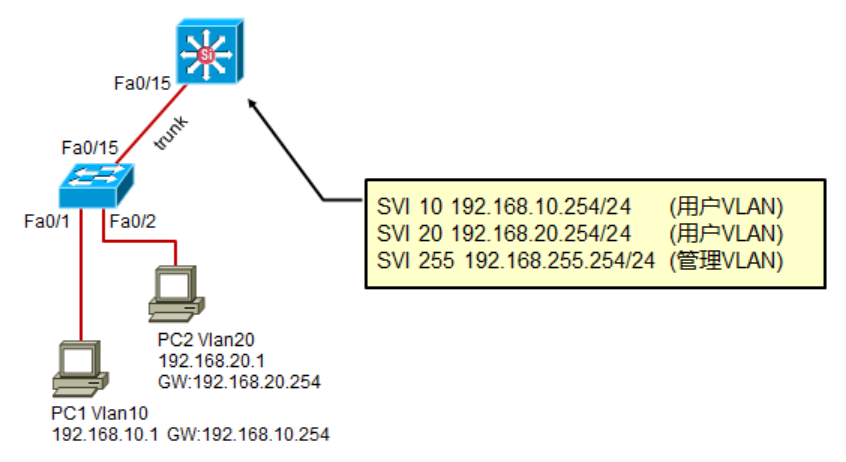
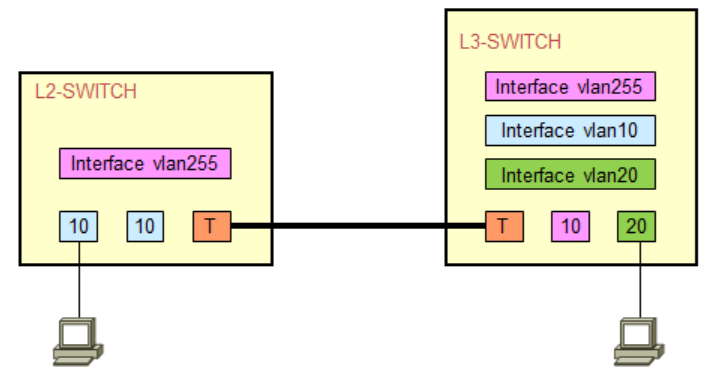
二层交换机配置:
1 | Switch(config)# vlan 10,20,255 |
核心交换机配置:
1 | Switch(config)# vlan 10,20,255 |
冗余网关技术
一旦网关或关键节点出现故障,将对业务造成灾难性的故障,因此应运而生了首跳网关冗余技术,常见的有HSRP、VRRP和GLBP,相互之间的区别如下:
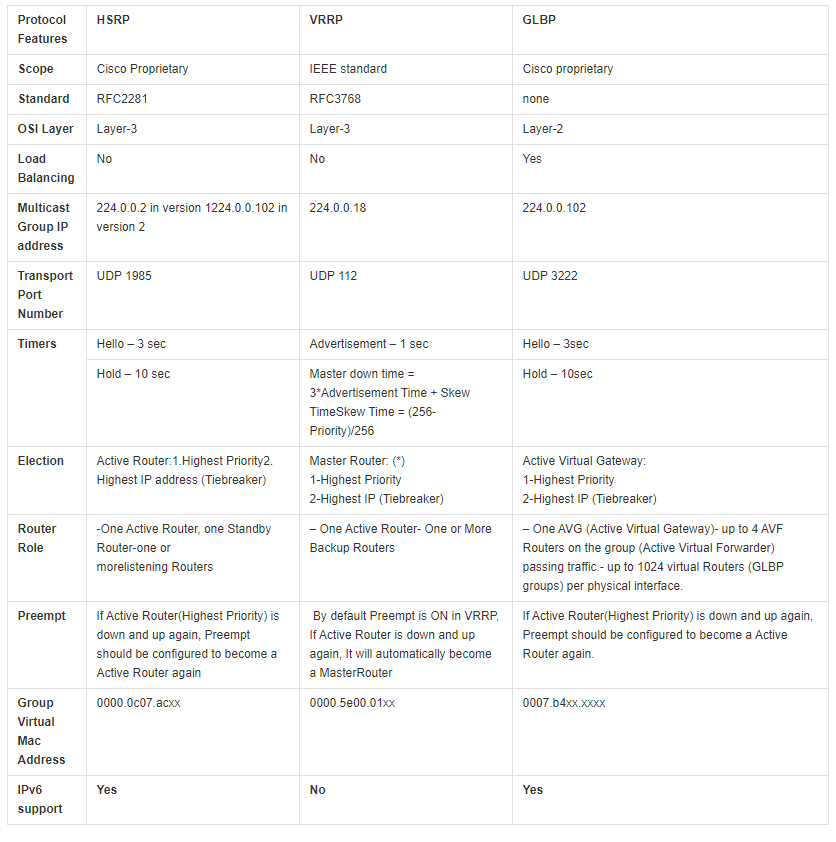

基本概念
由于HSRP和GLBP都是思科私有技术,这里只写VRRP这种公有技术。
利用VRRP(Virtual Router Redundancy Protocol,虚拟路由冗余协议)协议,一组路由器可以协同工作,但只有一个处于激活状态,在一个VRRP组内的多个路由器公用一个虚拟IP地址,该地址被作为局域网内所有主机的缺省网关地址,VRRP协议决定哪个路由器被激活,被激活的路由器负责收发过来的数据包并进行路由。
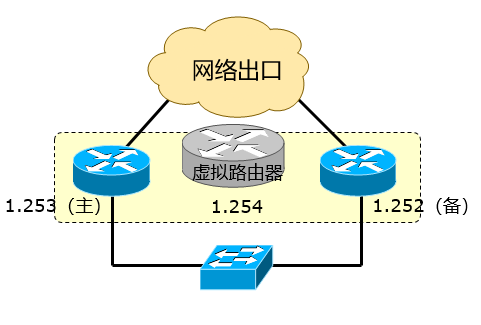
VRRP路由器:运行VRRP协议的路由器,一台VRRP路由器可以同时参与到多个VRRP组中,在不同的组中,一台VRRP路由器可以充当不同的角色;
VRRP组(VRID):由多个路由器组成,属于同一个VRRP组的VRRP路由器相互交换信息,每一组由一个VRID标识;
虚拟路由器:对每一个VRRP组,抽象出来的一个逻辑路由,该路由器充当网络用户的网关;
虚拟IP、MAC地址:用于标识虚拟的路由器,该地址实际上是用户的默认网关,两个地址都是虚拟的;
Master路由器:在VRRP组中实际转发数据包的路由器,在每一个VRRP组中,仅有Master响应对虚拟IP地址的ARP请求;
Backup路由器:在VRRP组中处于监听状态的路由器,一旦Master路由器出现故障,Backup路由器就开始接替所有的工作;
初始状态(Initialize):路由器杠杠启动时进入此状态,通过VRRP报文交互数据后进入其他状态;
活动状态(Master):VRRP组中的路由器通过VRRP报文交换后确定的当前转发数据包的一种状态;
备份状态(Backup):VRRP组中的路由器通过VRRP报文交换后确定的处于监听的一种状态;
报文
VRRP路由器之间使用组播进行消息传输。报文使用的组播地址是224.0.0.18,VRRP报文承载在IP报文之上,使用协议号112。

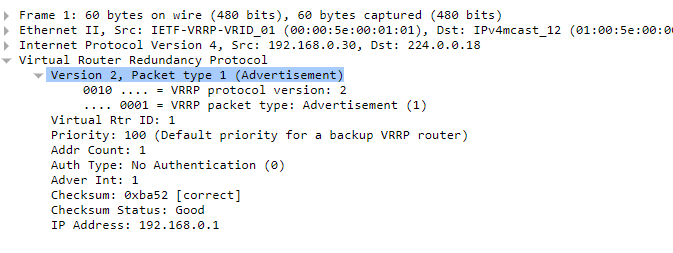
计时器
- Advertisement Interval:主路由器按照Advertisement Interval定义的时间间隔来发送VRRP通告报文,默认为1秒,在备份路由器上可以手动配置,但必须与主路由器相同,也可以从主路由器学习到这个时间间隔;
- Master Down Timer:Backup路由器认为Master路由器Down掉的时间间隔,默认情况下为3*Hello+Skew time【skew time=((256-pri)/256)ms】,这个时间确保优先级更好的备份路由器成为新的Master路由器;
工作原理
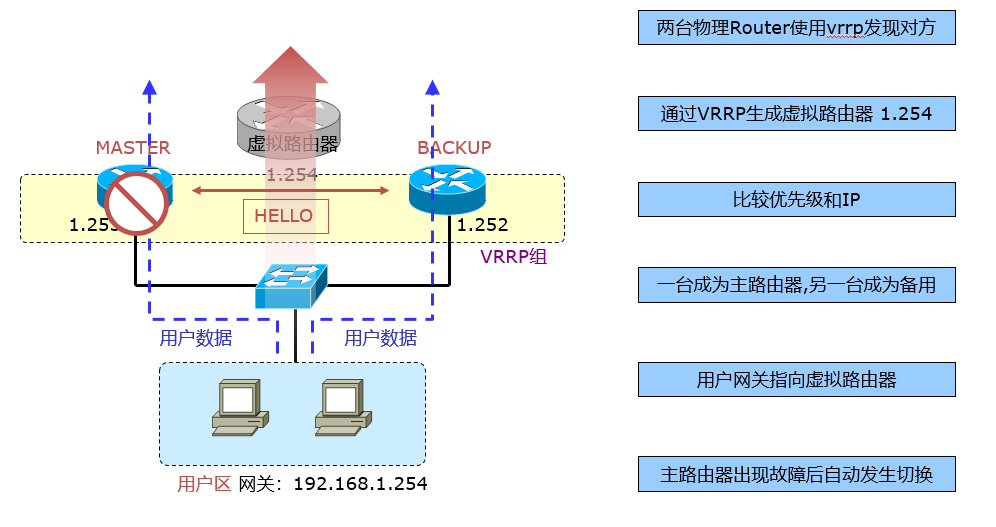
- Preempt抢占模式,主要用于保证更高优先级的路由器在接入网络时成为活动路由器;如果关闭抢占模式,高优先级的备份路由器不会主动成为活动路由器,即使活动路由器优先级较低,只有当活动路由器实效时,备份路由器才会成为主路由器;默认情况下,VRRP抢占模式都是开启的;
- Track:监视某个接口,并根据所监视接口的状态动态的调整本地路由器的优先级。
配置命令
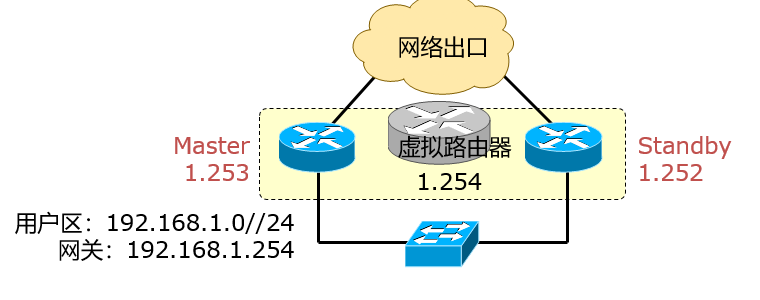
1 | R1(config)#interface F1/0 |
vrrp ip:用于激活VRRP协议,如果配置的VRRP组地址与接口的实际地址相同,那么该路由器将具有最高优先级,成为Master;
vrrp priority:用于设定端口的VRRP优先级,具有最高优先级的成员将成为激活的路由器(假设设置为优先级的方式);
vrrp timers:用预设定Hello包之间的时间间隔(Hello time)以及路由器在多长的一个时间段内没有从VRRP邻居收到Hello包就判定该邻居已经关闭(Hold time);
vrrp preempt:表明当本地路由器的备份优先级超过当前激活路由器时,他就将接管控制权,成为激活路由器;
vrrp track:用于设置允许路由器端口根据另一端口的可用性修改自己的VRRP优先级;
EtherChannel
协议概述
为了适应园区网业务的发展,速率的提高,我们可以采用多种方式提高园区网络中的数据传输速度:
能够提供更多带宽;
将相同的链路逻辑上聚合到一起;
逻辑上聚合到一起的端口看起来像是一个逻辑上的端口;
可以提供冗余和负载均衡;
三层接口和二层接口均可以捆绑;
Port-channel接口一旦建立完毕后,就形成了一个逻辑的接口,后续针对该接口的配置在Port-channel中完成;
Port-channel不能称为SPAN的目的接口;
隶属于同一个Port-channel的物理接口要有相同的speed、duplex、接口模式(access、trunk),如果是trunk模式那么Native vlan和allowed vlan需相同,如果是access模式那么所属vlan需相同;
有PAgP和LACP两种协议,其中PAgP是思科私有协议,LACP是公有协议;
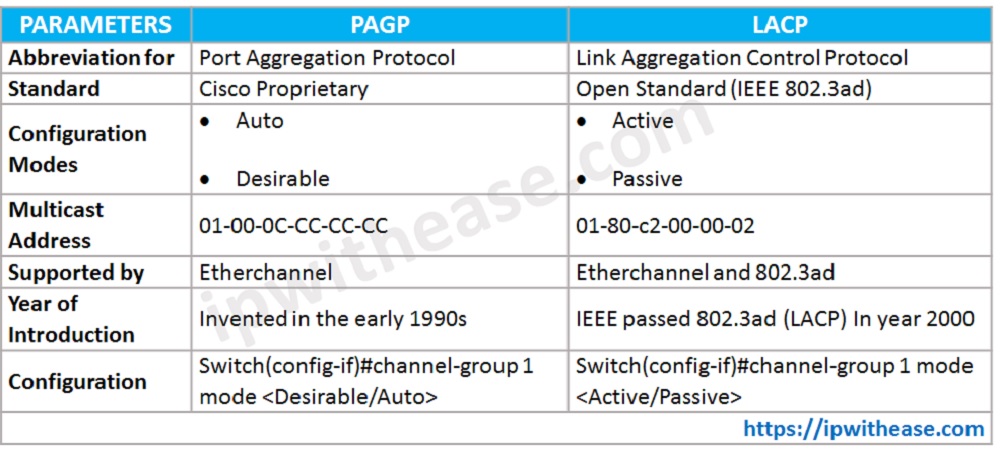
PAgP相关知识
模式:


LACP相关知识

二层捆绑配置
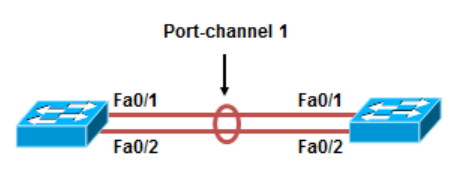
1 | Sw1(config)#interface range F0/1-2 |
三层捆绑配置
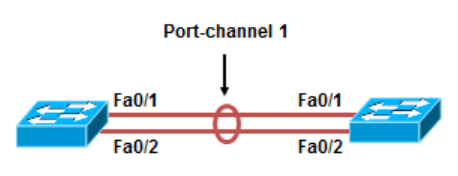
1 | Sw1(config)#interface range F0/1-2 |
负载均衡配置
1 | Sw1(config)#Port-channel load-balance XX |
Etherchannel支持在同一个port-channel的链路中执行负载均衡,负载均衡动作可以基于MAC、端口、IP(源IP,目的IP或两者),默认的负载均衡行为是源目ip地址(src-dst-ip)
二层安全
引用文章
Spanning Tree Protocol (STP) 生成树协定
Rapid Spanning Tree Protocol (RSTP) 快速生成树协定
Multiple Spanning Tree Protocol (MSTP) 多重生成树协定
 wechat
wechat alipay
alipay